適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory または Synapse Analytics パイプラインでコピー アクティビティを使用して、Azure Data Explorer をコピー先またはコピー元としてデータをコピーする方法について説明します。 この記事は、コピー アクティビティの概要を示しているコピー アクティビティの概要に関する記事に基づいています。
ヒント
Azure Data Explorer のサービスとの統合の詳細については、「Azure Data Explorer の統合」を参照してください。
サポートされる機能
この Azure Data Explorer コネクタは、次の機能についてサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/シンク) | (1) (2) |
| マッピング データ フロー (ソース/シンク) | (1) |
| Lookup アクティビティ | (1) (2) |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
Azure Data Explorer には、サポートされているソース データ ストアからデータをコピーすることができます。 また、Azure Data Explorer のデータを、サポートされているシンク データ ストアにコピーできます。 コピー アクティビティによってソースまたはシンクとしてサポートされているデータ ストアの一覧については、サポートされているデータ ストアに関するページの表をご覧ください。
注意
セルフホステッド統合ランタイムを使用して、Azure Data Explorer との間でオンプレミス データ ストアから双方向にデータをコピーすることは、バージョン 3.14 以降からサポートされています。
Azure Data Explorer コネクタを使用すると、次のことができます。
- Microsoft Entra アプリケーション トークン認証とサービス プリンシパルを使用して、データをコピーする。
- ソースとして、KQL (Kusto) クエリを使用してデータを取得する。
- シンクとして、コピー先テーブルにデータを追加する。
作業の開始
ヒント
Azure Data Explorer コネクタのチュートリアルについては、「Azure Data Explorer との間でデータをコピーする」と、データベースから Azure Data Explorer への一括コピーに関するページを参照してください。
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して Azure Data Explorer のリンク サービスを作成する
次の手順を使用して、Azure portal UI で Azure Data Explorer のリンク サービスを作成します。
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンク サービス] を選択して、[新規] をクリックします。
- Azureデータファクトリー
- Azure Synapse
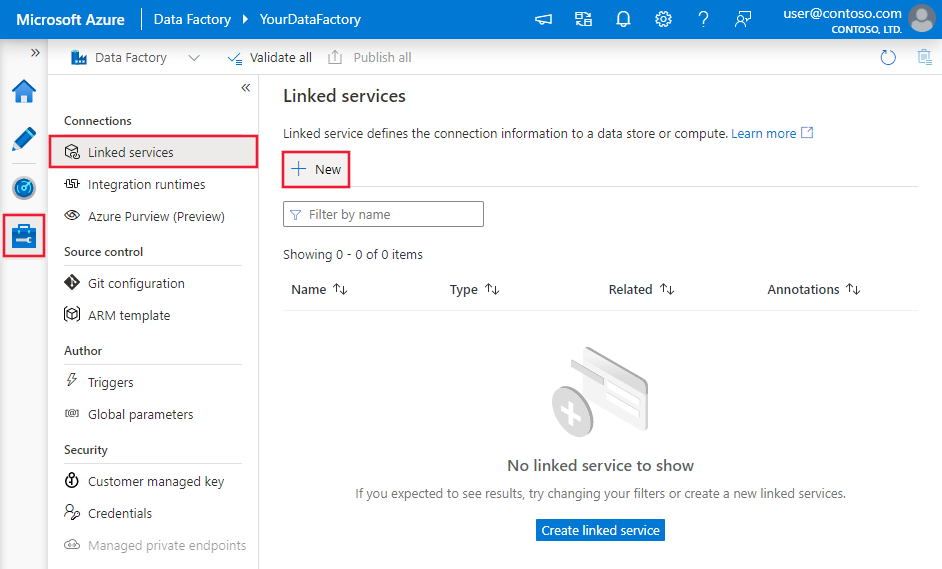
Explorer を検索し、Azure Data Explorer (Kusto) コネクタを選択します。
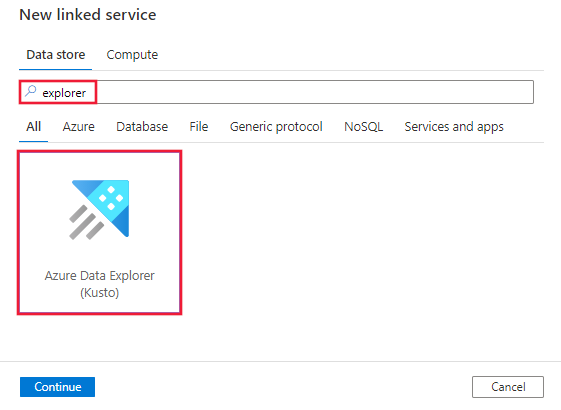
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
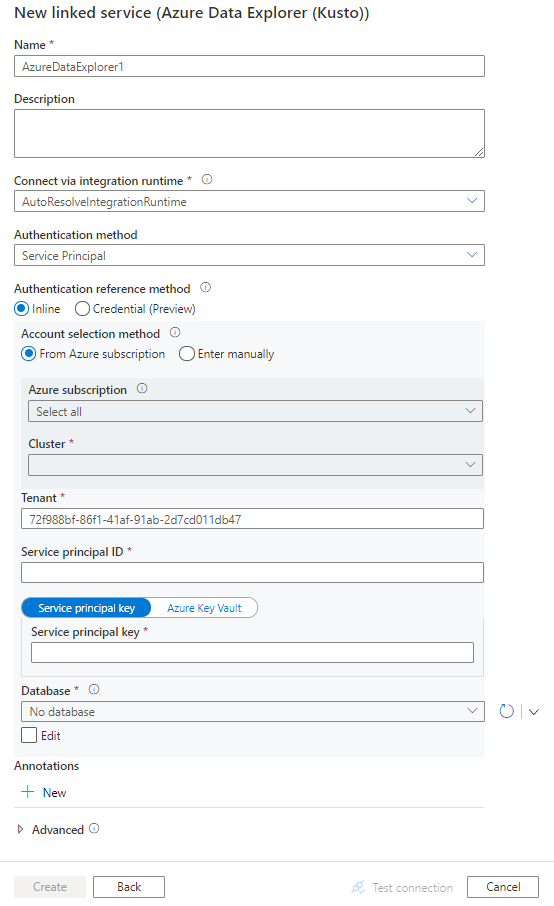
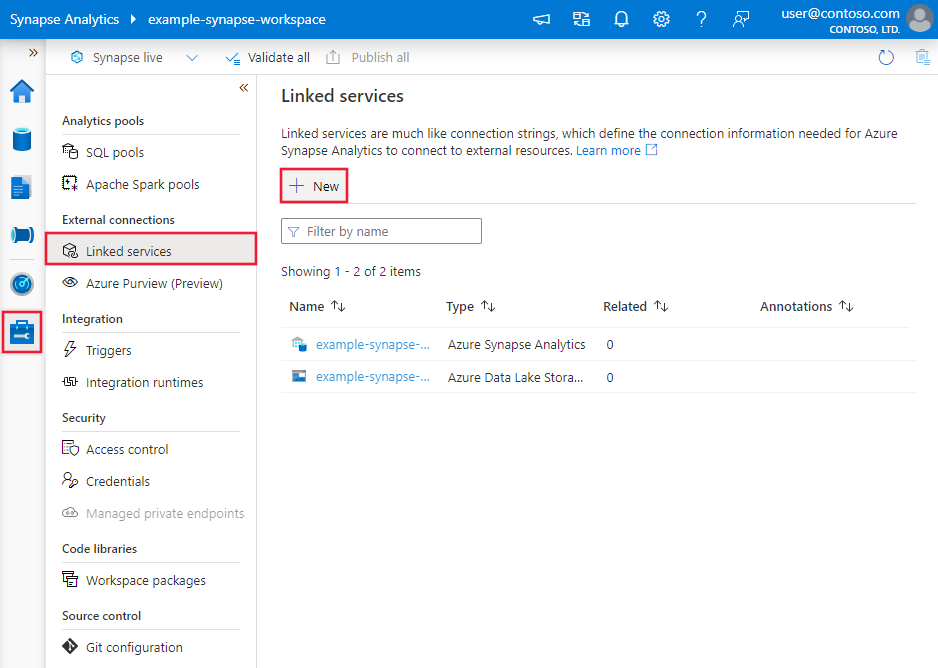
コネクタの構成の詳細
以下のセクションでは、Azure Data Explorer コネクタに固有のエンティティを定義するために使用されるプロパティの詳細を説明します。
リンクされたサービスのプロパティ
Azure Data Explorer コネクタでは、次の認証の種類がサポートされています。 詳細については、対応するセクションをご覧ください。
サービス プリンシパルの認証
サービス プリンシパルの認証を使用するには、次の手順に従ってサービス プリンシパルを取得し、アクセス許可を付与します。
Microsoft ID プラットフォームにアプリケーションを登録する。 方法については、「クイック スタート: Microsoft ID プラットフォームにアプリケーションを登録する」を参照してください。 これらの値を記録しておきます。リンクされたサービスを定義するときに使います。
- アプリケーション ID
- アプリケーション キー
- テナント ID
Azure Data Explorer でサービス プリンシパルに適切なアクセス許可を付与します。 ロールおよびアクセス許可の詳細について、またアクセス許可の管理方法の詳細については、「Azure Data Explorer のデータベース アクセス許可を管理する」を参照してください。 一般的に、次のことを行う必要があります。
- ソースとして、少なくともデータベース ビューアー ロールをデータベースに付与します。
- シンクとして、少なくともデータベース ユーザー ロールをデータベースに付与します。
注意
UI を使用して作成する場合、既定では、Azure Data Explorer クラスター、データベース、およびテーブルを一覧表示するために、ログイン ユーザー アカウントが使用されます。 サービス プリンシパルを使用してオブジェクトを一覧表示するには、更新ボタンの横にあるドロップダウンをクリックします。これらの操作に対するアクセス許可がない場合は、名前を手動で入力します。
Azure Data Explorer のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 種類 | type プロパティは、AzureDataExplorer に設定する必要があります。 | はい |
| エンドポイント | Azure Data Explorer クラスターのエンドポイント URL。形式は https://<clusterName>.<regionName>.kusto.windows.net です。 |
はい |
| データベース | データベースの名前。 | はい |
| テナント | アプリケーションが存在するテナントの情報 (ドメイン名またはテナント ID) を指定します。 これは、Kusto 接続文字列の "機関 ID" として知られています。 これは、Azure portal の右上隅にマウス ポインターを合わせることで取得できます。 | はい |
| サービスプリンシパルID (servicePrincipalId) | アプリケーションのクライアント ID を取得します。 これは、Kusto 接続文字列の "Microsoft Entra アプリケーション クライアント ID" として知られています。 | はい |
| servicePrincipalKey(サービスプリンシパルキー) | アプリケーションのキーを取得します。 これは、Kusto 接続文字列の "Microsoft Entra アプリケーション キー" として知られています。 このフィールドを SecureString とマークして安全に保存するか、Azure Key Vault に格納されている安全なデータを参照します。 | はい |
| connectVia (接続ビア) | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
例: サービス プリンシパル キー認証の使用
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
システム割り当てマネージド ID 認証
Azure リソース用マネージド ID の詳細については、Azure リソース用マネージド ID に関するページを参照してください。
システム割り当てマネージド ID 認証を使用するには、次の手順に従ってアクセス許可を付与します。
ファクトリまたは Synapse ワークスペースと共に生成されたマネージド ID オブジェクト ID の値をコピーして、マネージド ID 情報を取得します。
Azure Data Explorer でマネージド ID に適切なアクセス許可を付与します。 ロールおよびアクセス許可の詳細について、またアクセス許可の管理方法の詳細については、「Azure Data Explorer のデータベース アクセス許可を管理する」を参照してください。 一般的に、次のことを行う必要があります。
- ソースとして、データベース ビューアー ロールをデータベースに付与する。
- シンクとして、データベース インジェスター ロールおよびデータベース ビューアー ロールをデータベースに付与する。
注意
UI を使用して作成する場合、Azure Data Explorer クラスター、データベース、およびテーブルを一覧表示するために、ログイン ユーザー アカウントが使用されます。 これらの操作のためのアクセス許可がない場合は、名前を手動で入力します。
Azure Data Explorer のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 種類 | type プロパティは、AzureDataExplorer に設定する必要があります。 | はい |
| エンドポイント | Azure Data Explorer クラスターのエンドポイント URL。形式は https://<clusterName>.<regionName>.kusto.windows.net です。 |
はい |
| データベース | データベースの名前。 | はい |
| connectVia (接続ビア) | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
例: システム割り当てマネージド ID 認証を使用する
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
ユーザー割り当てマネージド ID 認証
Azure リソース用マネージド ID の詳細については、Azure リソース用マネージド ID に関するページを参照してください
ユーザー割り当てマネージド ID 認証を使用するには、次の手順に従います。
1 つ以上のユーザー割り当てマネージド ID を作成して、Azure Data Explorer でアクセス許可を付与します。 ロールおよびアクセス許可の詳細について、またアクセス許可の管理方法の詳細については、「Azure Data Explorer のデータベース アクセス許可を管理する」を参照してください。 一般的に、次のことを行う必要があります。
- ソースとして、少なくともデータベース ビューアー ロールをデータベースに付与します。
- シンクとして、少なくともデータベースのデータ取り込みロールをデータベースに付与します。
1 つ以上のユーザー割り当てマネージド ID をデータ ファクトリまたは Synapse ワークスペースに割り当て、ユーザー割り当てマネージド ID ごとに資格情報を作成します。
Azure Data Explorer のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 種類 | type プロパティは、AzureDataExplorer に設定する必要があります。 | はい |
| エンドポイント | Azure Data Explorer クラスターのエンドポイント URL。形式は https://<clusterName>.<regionName>.kusto.windows.net です。 |
はい |
| データベース | データベースの名前。 | はい |
| 資格情報 | ユーザー割り当てマネージド ID を資格情報オブジェクトとして指定します。 | はい |
| connectVia (接続ビア) | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
例: ユーザー割り当てマネージド ID 認証を使用する
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
データセットのプロパティ
データセットの定義に使用できるセクションとプロパティの一覧については、データセットに関する記事をご覧ください。 このセクションでは、Azure Data Explorer データセットでサポートされるプロパティの一覧を示します。
Azure Data Explorer にデータをコピーするには、データセットの type プロパティを AzureDataExplorerTable に設定します。
次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 種類 | type プロパティは、AzureDataExplorerTable に設定する必要があります。 | はい |
| テーブル / 表 | リンクされたサービスが参照するテーブルの名前。 | シンクの場合は Yes、ソースの場合は No |
データセットのプロパティの例:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインとアクティビティに関するページを参照してください。 このセクションでは、Azure Data Explorer のソースとシンクでサポートされるプロパティの一覧を示します。
ソースとしての Azure Data Explorer
Azure Data Explorer からデータをコピーするには、コピー アクティビティ ソースの type プロパティを AzureDataExplorerSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 種類 | コピー アクティビティのソースの type プロパティを、次の値に設定する必要があります:AzureDataExplorerSource | はい |
| 問い合わせ | KQL 形式で指定された読み取り専用要求。 参照としてカスタム KQL クエリを使用します。 | はい |
| queryTimeout | クエリ要求がタイムアウトするまでの待機時間。既定値は 10 分 (00:10:00)、許容される最大値は 1 時間 (01:00:00) です。 | いいえ |
| noTruncation | 返される結果セットを切り詰めるかどうかを示します。 既定では、結果は 500,000 件のレコードまたは 64 メガバイト (MB) の後に切り詰められます。 アクティビティの正常な動作のためには、切り詰めを強くお勧めします。 | いいえ |
注意
既定では、Azure Data Explorer ソースには、500,000 レコードまたは 64 MB のサイズ制限があります。 切り捨てることなくすべてのレコードを取得するには、クエリの先頭に set notruncation; を指定します。 詳細については、「クエリの制限」を参照してください。
例:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
シンクとしての Azure Data Explorer
Azure Data Explorer にデータをコピーするには、コピー アクティビティ シンクの type プロパティを AzureDataExplorerSink に設定します。 コピー アクティビティの sink セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 種類 | コピー アクティビティのシンクの type プロパティは、次のように設定する必要があります:AzureDataExplorerSink | はい |
| ingestionMappingName | Kusto テーブルで事前作成済みのマッピングの名前。 ソースから Azure Data Explorer に列をマッピングするには (CSV/JSON/Avro 形式など、サポートされているすべてのソース ストアや形式に適用されます)、コピー アクティビティの列マッピング (名前で暗黙的に、または構成で明示的に) や Azure Data Explorer のマッピングを使用できます。 | いいえ |
| additionalプロパティ | まだ Azure Data Explorer シンクによって設定されていないインジェストのプロパティを指定するために使用できるプロパティ バッグ。 具体的には、インジェスト タグの指定に便利です。 詳細については Azure Data Explore データ インジェスト ドキュメントでご覧ください。 | いいえ |
例:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Mapping Data Flow のプロパティ
マッピング データ フローでデータを変換するときに、Azure Data Explorer のテーブルに対する読み取りと書き込みを実行できます。 詳細については、マッピング データ フローのソース変換とシンク変換に関する記事をご覧ください。 ソースとシンクの種類として、Azure Data Explorer データセットまたはインライン データセットを使用できます。
ソース変換
次の表に、Azure Data Explorer ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。
| 名前 | 内容 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| テーブル | 入力として [テーブル] を選択した場合、データ フローでは、Azure Data Explorer データセットで指定された、またはインライン データセットを使用するときにソース オプションで指定されたテーブルからすべてのデータがフェッチされます。 | いいえ | 糸 |
(インライン データセットのみ) テーブル名 |
| クエリ | KQL 形式で指定された読み取り専用要求。 参照としてカスタム KQL クエリを使用します。 | いいえ | 糸 | 問い合わせ |
| タイムアウト | クエリ要求がタイムアウトするまでの待機時間。既定値は '172000' (2 日間) です。 | いいえ | 整数 | タイムアウト |
Azure Data Explorer ソース スクリプトの例
ソースの種類として Azure Data Explorer データセットを使用する場合、関連付けられるデータ フロー スクリプトは次のようになります。
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
インライン データセットを使用する場合、関連付けられているデータ フロー スクリプトは次のようになります。
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
シンク変換
次の表に、Azure Data Explorer シンクでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [設定] タブで編集できます。インライン データセットを使用する場合、「データセットのプロパティ」セクションで説明されているプロパティと同じ追加の設定が表示されます。
| 名前 | 内容 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| テーブル アクション | 書き込み前に変換先テーブルのすべての行を再作成するか削除するかを指定します。 - なし: テーブルに対してアクションは実行されません。 - Recreate:テーブルが削除され、再作成されます。 新しいテーブルを動的に作成する場合に必要です。 - Truncate:ターゲット テーブルのすべての行が削除されます。 |
いいえ |
true または false |
再現 切り捨てる |
| 事前および事後の SQL スクリプト | データがシンク データベースに書き込まれる前 (前処理) と書き込まれた後 (後処理) に実行される複数の Kusto 管理コマンドを指定します。 | いいえ | 糸 | preSQL; postSQL |
| タイムアウト | クエリ要求がタイムアウトするまでの待機時間。既定値は '172000' (2 日間) です。 | いいえ | 整数 | タイムアウト |
Azure Data Explorer シンク スクリプトの例
シンクの種類として Azure Data Explorer データセットを使用する場合、関連付けられているデータ フロー スクリプトは次のようになります。
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
インライン データセットを使用する場合、関連付けられているデータ フロー スクリプトは次のようになります。
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Lookup アクティビティのプロパティ
プロパティの詳細については、ルックアップ アクティビティに関する記事を参照してください。
関連するコンテンツ
コピー アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するページを参照してください。
Azure Data Factory と Synapse Analytics から Azure Data Explorer にデータをコピーする方法を参照してください。