series_mv_ee_anomalies_fl()
関数series_mv_ee_anomalies_fl()は、scikit-learn から省略記号エンベロープ モデルを適用することで、系列内の多変量異常を検出するユーザー定義関数 (UDF) です。 このモデルは、多変量データのソースが多次元正規分布であることを前提としています。 関数は、系列のセットを数値動的配列、特徴列の名前、および系列全体の異常の予想される割合として受け入れます。 関数は、系列ごとに多次元楕円エンベロープを作成し、この通常のエンベロープの外側にある点を異常としてマークします。
前提条件
- クラスターで Python プラグインを有効にする必要があります。 これは、 関数で使用されるインライン Python に必要です。
- データベースで Python プラグイン を有効にする必要があります。 これは、 関数で使用されるインライン Python に必要です。
構文
T | invoke series_mv_ee_anomalies_fl(, features_colsanomaly_col [,score_col [,anomalies_pct]])
構文規則について詳しく知る。
パラメーター
| 名前 | 型 | 必須 | 説明 |
|---|---|---|---|
| features_cols | dynamic |
✔️ | 多変量異常検出モデルに使用される列の名前を含む配列。 |
| anomaly_col | string |
✔️ | 検出された異常を格納する列の名前。 |
| score_col | string |
異常のスコアを格納する列の名前。 | |
| anomalies_pct | real |
データ内の異常の予想される割合を指定する [0 から 50] の範囲内の実数。 既定値: 4% |
関数の定義
関数を定義するには、次のようにコードをクエリ定義関数として埋め込むか、データベースに格納された関数として作成します。
次の let ステートメントを使用して関数を定義します。 権限は必要ありません。
重要
let ステートメントを単独で実行することはできません。 その後に 表形式の式ステートメントを指定する必要があります。 の動作例 series_mv_ee_anomalies_fl()を実行するには、「 例」を参照してください。
// Define function
let series_mv_ee_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.covariance import EllipticEnvelope
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
ellipsoid = EllipticEnvelope(contamination=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
ellipsoid.fit(dffe)
df.loc[i, anomaly_col] = (ellipsoid.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = ellipsoid.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function here.
例
次の例では、 invoke 演算子 を使用して関数を実行します。
クエリ定義関数を使用するには、埋め込み関数定義の後で呼び出します。
// Define function
let series_mv_ee_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.covariance import EllipticEnvelope
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
ellipsoid = EllipticEnvelope(contamination=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
ellipsoid.fit(dffe)
df.loc[i, anomaly_col] = (ellipsoid.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = ellipsoid.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_ee_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores')
| extend anomalies=series_multiply(80, anomalies)
| render timechart
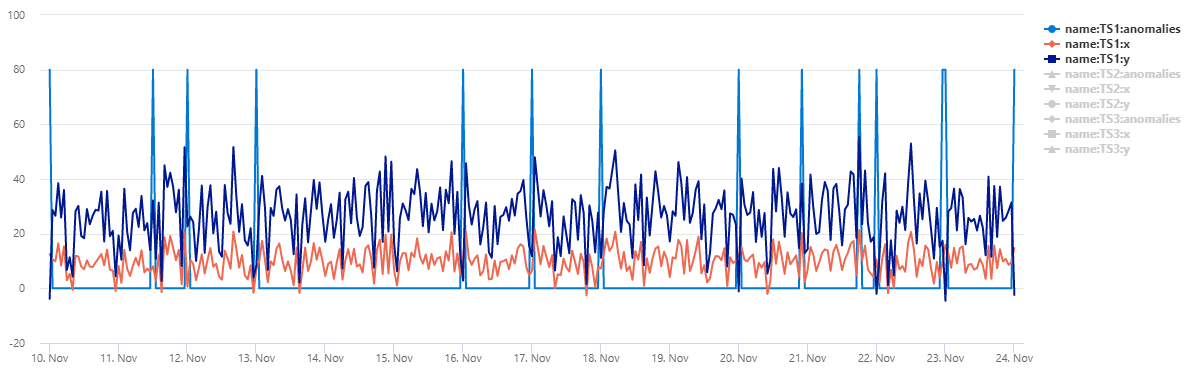
出力
テーブル normal_2d_with_anomaliesには、3 つの時系列のセットが含まれています。 各時系列には 2 次元正規分布があり、毎日の異常が午前 0 時、午前 8 時、午後 4 時に追加されます。 このサンプル データセットは、 クエリの例を使用して作成できます。
散布図としてデータを表示するには、使用状況コードを次のように置き換えます。
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_ee_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
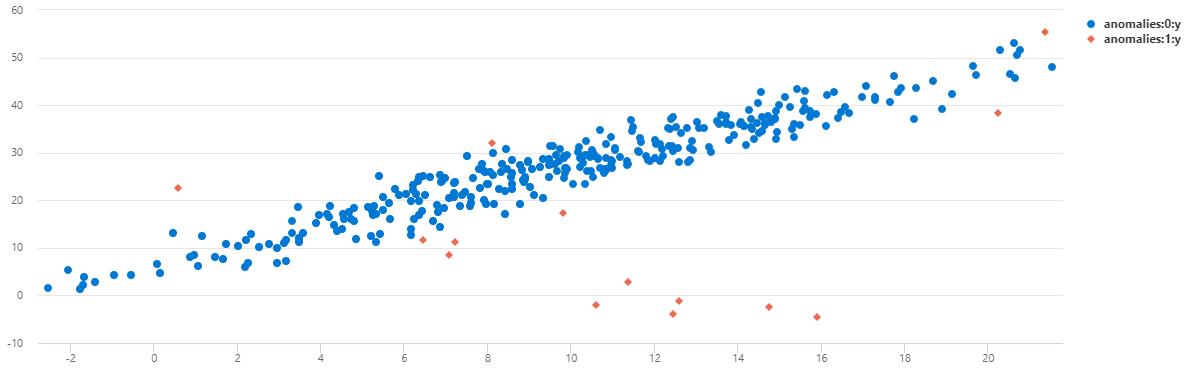
TS1 では、午前 0 時の異常のほとんどは、この多変量モデルを使用して検出されたことがわかります。
サンプル データセットを作成する
.set normal_2d_with_anomalies <|
//
let window=14d;
let dt=1h;
let n=toint(window/dt);
let rand_normal_fl=(avg:real=0.0, stdv:real=1.0)
{
let x =rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand();
(x - 6)*stdv + avg
};
union
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(10, 5)
| extend y=iff(hourofday(t) == 0, 2*(10-x)+7+rand_normal_fl(0, 3), 2*x+7+rand_normal_fl(0, 3)) // anomalies every midnight
| extend name='TS1'),
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(15, 3)
| extend y=iff(hourofday(t) == 8, (15-x)+10+rand_normal_fl(0, 2), x-7+rand_normal_fl(0, 1)) // anomalies every 8am
| extend name='TS2'),
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(8, 6)
| extend y=iff(hourofday(t) == 16, x+5+rand_normal_fl(0, 4), (12-x)+rand_normal_fl(0, 4)) // anomalies every 4pm
| extend name='TS3')
| summarize t=make_list(t), x=make_list(x), y=make_list(y) by name
この機能はサポートされていません。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示