この記事では、Azure Data Factory (ADF) でのマッピング データ フローのためのコネクタと形式に関するトラブルシューティング方法について説明します。
Azure Blob Storage (アジュール・ブロブ・ストレージ)
アカウント ストレージの種類 (汎用 v1) で、サービス プリンシパルと MI 認証がサポートされていない
現象
データ フローで、サービス プリンシパルまたは MI 認証で Azure Blob Storage (汎用 v1) を使用すると、次のエラー メッセージが表示される場合があります。
com.microsoft.dataflow.broker.InvalidOperationException: ServicePrincipal and MI auth are not supported if blob storage kind is Storage (general purpose v1)
原因
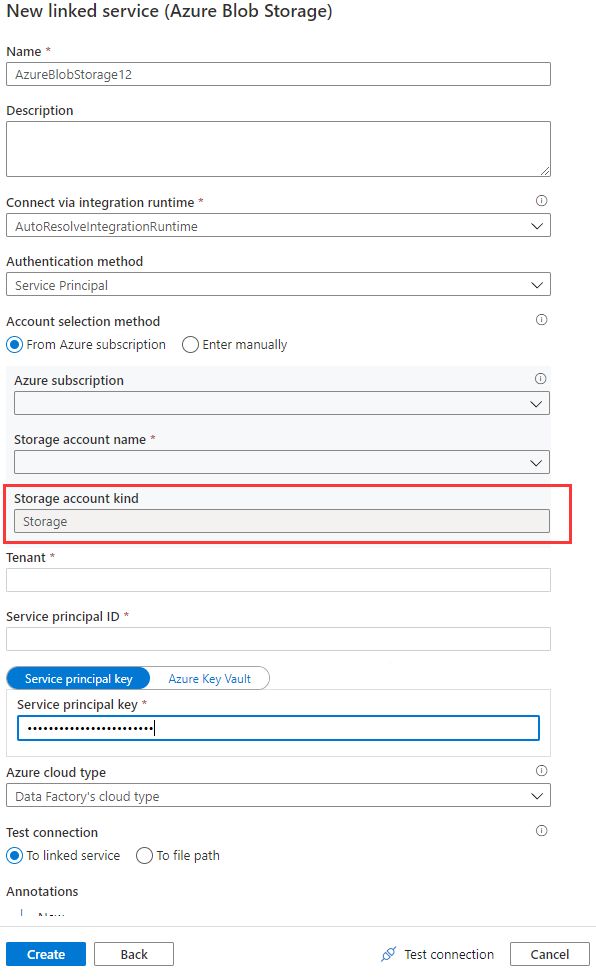
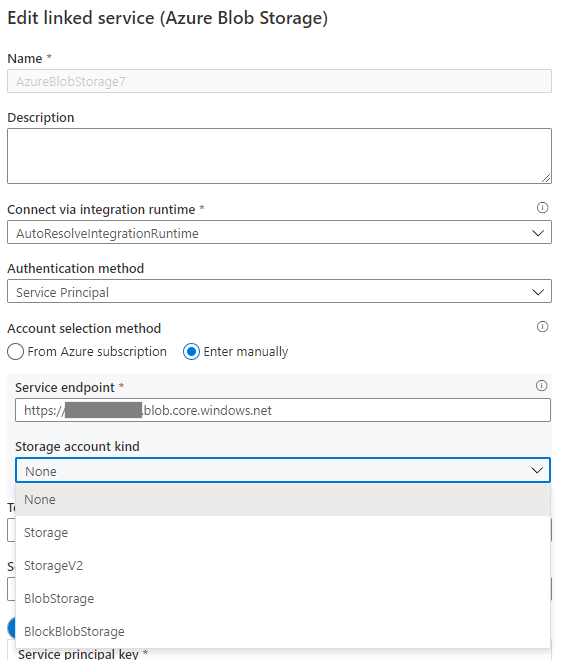
データ フローで Azure Blob のリンク サービスを使用する際に、アカウントの種類が空または Storage の場合、マネージド ID またはサービス プリンシパルの認証はサポートされません。 この状況を、次の画像 1 と画像 2 に示します。
画像 1: Azure Blob Storage のリンク サービスのアカウントの種類
画像 2: ストレージ アカウントのページ

推奨
この問題を解決するには、以下の推奨事項を参照してください。
Azure Blob のリンク サービスでストレージ アカウントの種類が None の場合は、適切なアカウントの種類を指定します。次の画像 3 を参照してください。 さらに、画像 2 を参照してストレージ アカウントの種類を取得し、アカウントの種類が Storage (汎用 v1) ではないことを確認します。
画像 3: Azure Blob Storage のリンク サービスでストレージ アカウントの種類を指定する
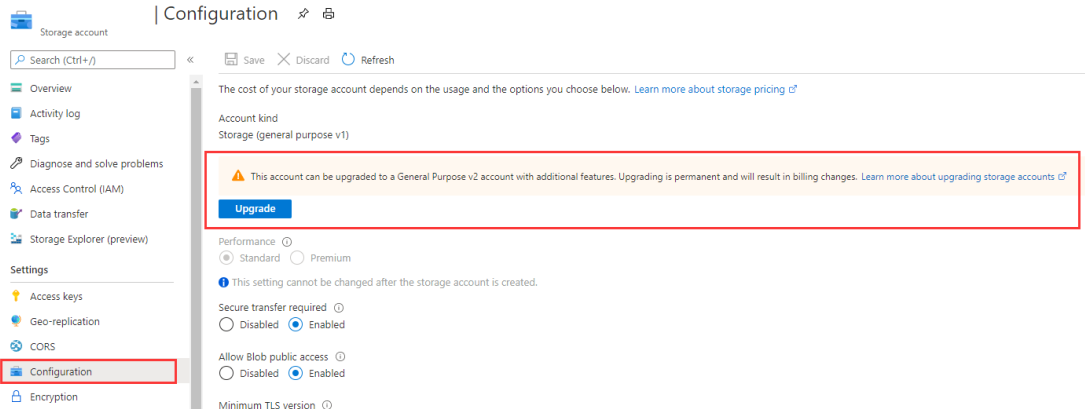
アカウントの種類が "Storage" (汎用 v1) の場合は、ストレージ アカウントを 汎用 v2 にアップグレードするか、別の認証を選択します。
画像 4: ストレージ アカウントを汎用 v2 にアップグレードする

Azure Cosmos DB と JSON 形式
ソースでのカスタマイズされたスキーマをサポートする
現象
ADF データ フローを使用して Azure Cosmos DB または JSON から他のデータ ストアにデータを移動または転送するとき、ソース データの一部の列が失われる場合があります。
原因
スキーマフリー コネクタの場合 (各行の列番号、列名、および列データ型は、他の行と比較したとき異なる場合があります)、既定では、ADF はサンプル行 (上位 100 行や 1000 行のデータなど) を使用してスキーマを推論し、推論された結果はデータを読み取るスキーマとして使用されます。 そのため、サンプル行に登場しない余分な列がデータ ストアに含まれている場合、これらの余分な列のデータは、読み取られたり、移動されたり、シンク データ ストアに転送されたりすることはありません。
推奨
既定の動作を上書きし、追加のフィールドを取り込むために、ADF ではソース スキーマをカスタマイズするためのオプションが提供されています。 データを読み取るためのデータ フロー ソース プロジェクションで、スキーマ推論結果において欠落する可能性のある追加/欠落列を指定できます。また、次のオプションのいずれかを適用して、カスタマイズされたスキーマを設定できます。 通常の場合、オプション 1 を使用することをお勧めします。
オプション 1: 複雑なスキーマを持つ数百万行を含む 1 つの大きなファイル、テーブル、またはコンテナーである可能性がある元のソース データと比較して、読み取り対象のすべての列を含む数行の行を含む一時テーブル/コンテナーを作成し、次の操作に進むことができます。
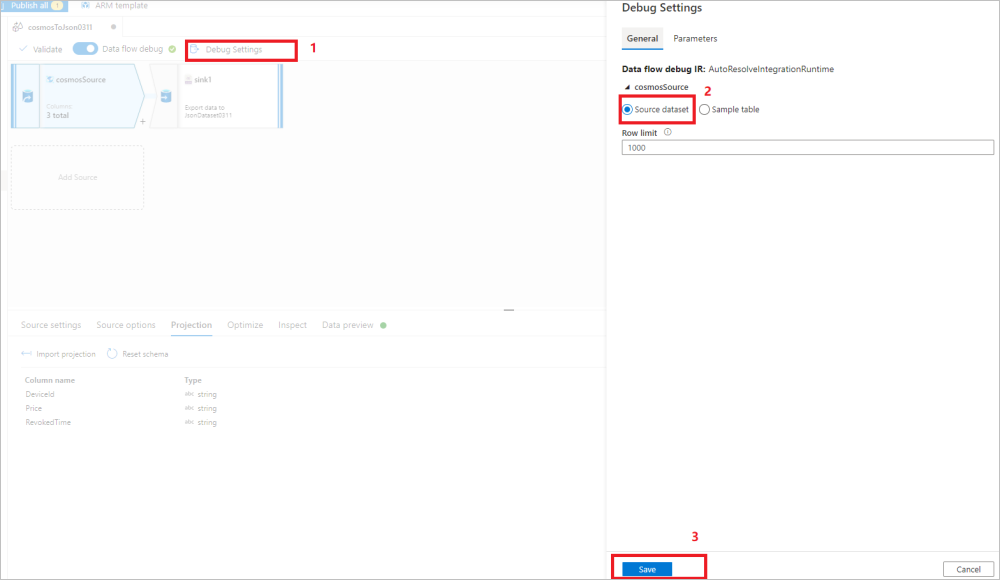
データ フロー ソースの [デバッグ設定] を使用して、 [Import projection](プロジェクションのインポート) で、完全なスキーマを取得するためにサンプルのファイル/テーブルを使用します。 次の図の手順に従うことができます。
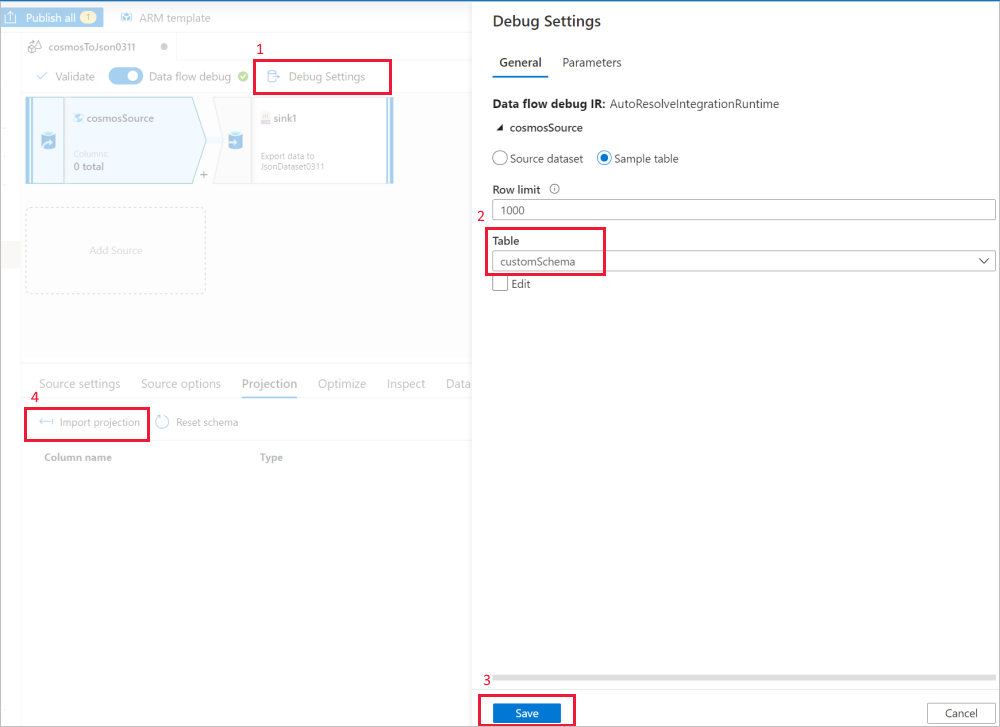
- データ フロー キャンバスで [デバッグ設定] を選択します。
- ポップアップ ウィンドウで、 [cosmosSource] タブの下にある [サンプル テーブル] を選択し、 [テーブル] ブロックにテーブルの名前を入力します。
- [Save](保存) を選択して設定を保存します。
-
[Import projection](プロジェクションのインポート) を選択します。
残りのデータ移動/変換用にソース データセットを使用するように、 [デバッグ設定] を戻します。 次の図の手順に進むことができます。
- データ フロー キャンバスで [デバッグ設定] を選択します。
- ポップアップ ウィンドウで、 [cosmosSource] タブの下にある [ソース データセット] を選択します。
-
[Save](保存) を選択して設定を保存します。
その後、ADF データ フロー ランタイムでは、カスタマイズされたスキーマを優先して使用し、元のデータ ストアからデータを読み取ります。
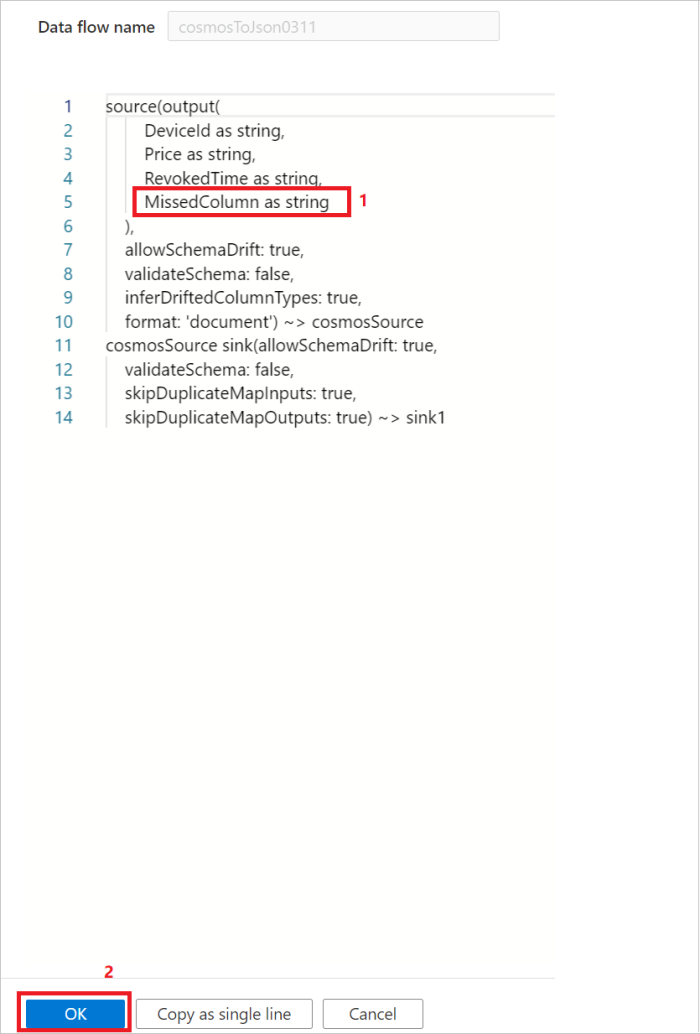
オプション 2: ソース データのスキーマと DSL 言語を使い慣れている場合は、データ フローのソース スクリプトを手動で更新して、データを読み取るための追加/欠落列を追加することができます。 例を次の図に示します。
ソースでの map 型のサポート
現象
ADF データ フローでは、Azure Cosmos DB または JSON ソースでマップ データ型を直接サポートすることはできません。そのため、"インポートプロジェクション" でマップ データ型を取得することはできません。
原因
Azure Cosmos DB と JSON では、これらはスキーマ フリー接続です。関連する Spark コネクタではサンプル データを使用してスキーマが推論され、そのスキーマが Azure Cosmos DB または JSON 送信元スキーマとして使用されます。 スキーマを推論するとき、Azure Cosmos DB または JSON Spark コネクタでは、オブジェクト データはマップ データ型ではなく構造体としてのみ推論できます。そのため、マップ型を直接サポートすることはできません。
推奨
この問題を解決するには、次の例と手順を参照して、Azure Cosmos DB または JSON ソースのスクリプト (DSL) を手動で更新し、マップ データ型がサポートされるようにします。
例:

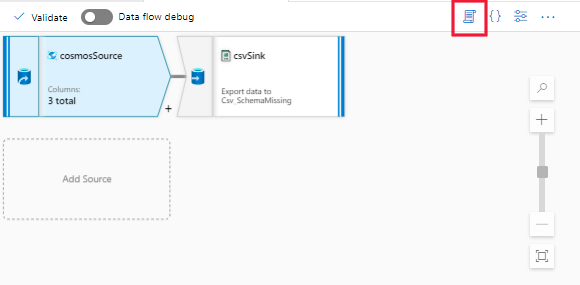
手順 1: データフロー アクティビティのスクリプトを開きます。
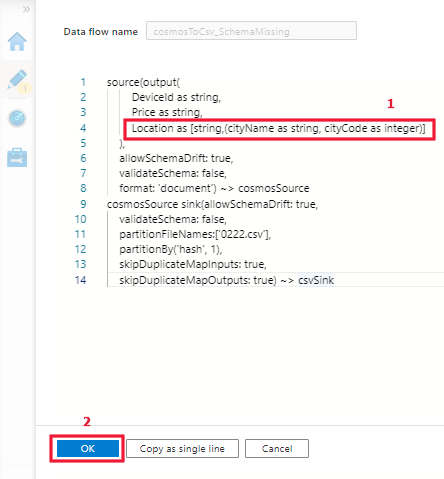
手順 2: DSL を更新し、上記の例を参照して map 型がサポートされるようにします。
map 型のサポート:
| タイプ | map 型のサポートの有無 | コメント |
|---|---|---|
| Excel、CSV | いいえ | どちらも、プリミティブ型の表形式データ ソースであるため、マップ型をサポートする必要はありません。 |
| Orc、Avro | はい | [なし] : |
| JSON(ジェイソン) | はい | マップ型を直接サポートすることはできません。 このセクションの推奨事項に従って、ソース プロジェクションでスクリプト (DSL) を更新してください。 |
| Azure Cosmos DB (アジュール コスモス データベース) | はい | マップ型を直接サポートすることはできません。 このセクションの推奨事項に従って、ソース プロジェクションでスクリプト (DSL) を更新してください。 |
| パーケット | はい | 現在、Parquet データセットでは複合データ型がサポートされていないため、マップ型を取得するには、データ フロー Parquet ソースの下にある "インポート プロジェクション" を使用する必要があります。 |
| XML | いいえ | [なし] : |
コピー アクティビティによって生成された JSON ファイルを使用する
現象
コピー アクティビティを使用していくつかの JSON ファイルを生成し、それらのファイルをデータ フローで読み取ろうとすると、次のエラー メッセージが表示されて失敗します。 JSON parsing error, unsupported encoding or multiline
原因
JSON には、コピーとデータ フローに対してそれぞれ次の制限があります。
Unicode エンコード (utf-8、utf-16、utf-32) JSON ファイルの場合、コピー アクティビティでは常に BOM を使用して JSON ファイルが生成されます。
[1 つのドキュメント] が有効になっているデー タフロー JSON ソースでは、BOM を使用した Unicode エンコードはサポートされていません。
![[1 つのドキュメント] が有効になっている画面のスクリーンショット。](media/data-flow-troubleshoot-connector-format/enabled-single-document.png)
そのため、次の条件が満たされると、問題が発生する可能性があります。
コピー アクティビティで使用されるシンク データセットが、Unicode エンコード (uutf-8、utf-16、utf-16be、utf-32、utf-32be) に設定されているか、既定値が使用されている。
デー タフロー JSON ソースで [1 つのドキュメント] が有効になっているかどうかに関係なく、次の図に示すように、コピー シンクが [オブジェクトの配列] ファイル パターンを使用するように設定されている。
![[オブジェクトの配列] パターンが設定されている画面のスクリーンショット。](media/data-flow-troubleshoot-connector-format/array-of-objects-pattern.png)
推奨
- 生成されたファイルがデータ フローで使用される場合、コピー シンクでは常に既定のファイル パターンまたは明示的な "オブジェクトのセット" パターンを使用します。
- データ フロー JSON ソースで [1 つのドキュメント] オプションを無効にします。
注意
"オブジェクトのセット" を使用することは、パフォーマンスの観点からも推奨される方法です。 データ フローの "1 つのドキュメント" JSON では、1 つの大きなファイルの並列読み取りを有効にできないため、この推奨事項による悪影響はありません。
パラメーターを含むクエリが機能しない
現象
Azure Data Factory のマッピング データ フローでは、パラメーターの使用がサポートされています。 パラメーター値は、Data Flow の実行アクティビティを通じて呼び出しパイプラインによって設定されます。パラメーターの使用は、データ フローの汎用化、柔軟性の向上、再利用に適した方法です。 データ フローの設定と式は、「マッピング データ フローをパラメーター化する」に記載されているパラメーターを使用してパラメーター化できます。
パラメーターを設定して、それらをデータ フロー ソースのクエリで使用すると、有効になりません。
原因
このエラーは、構成が間違っていることが原因で発生します。
推奨
次のルールを使用してクエリのパラメーターを設定します。詳細については、「マッピング データ フローで式を構築する」を参照してください。
- SQL ステートメントの先頭に二重引用符を付けます。
- 単一引用符を使用してパラメーターを囲みます。
- すべての CLAUSE ステートメントに小文字を使用します。
次に例を示します。
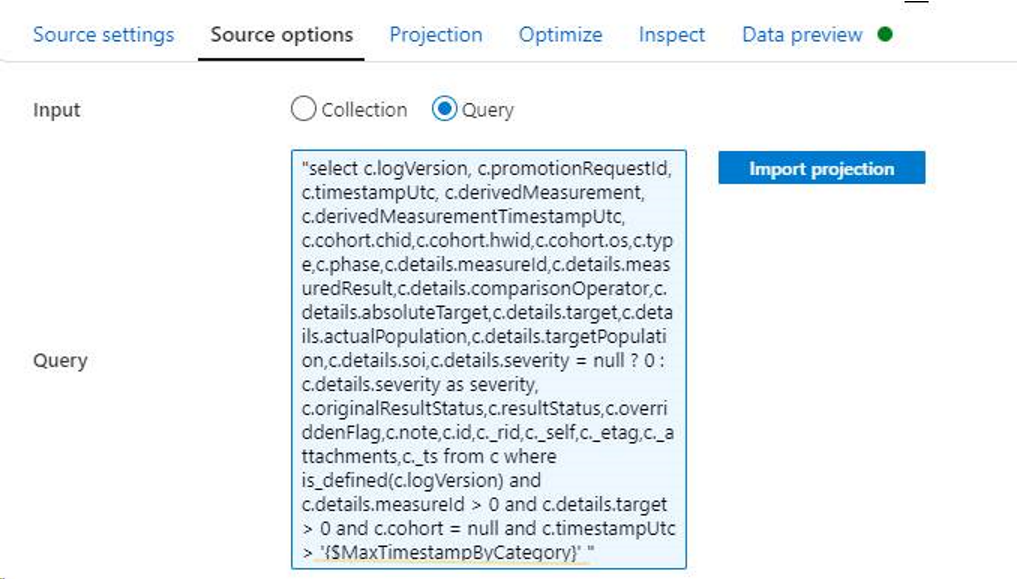
Azure Data Lake Storage Gen1
サービス プリンシパル認証を使用したファイルの作成に失敗する
現象
別のソースから ADLS Gen1 シンクにデータを移動または転送しようとすると、リンク サービスの認証方法がサービス プリンシパル認証の場合、次のエラー メッセージが表示されてジョブが失敗することがあります。
org.apache.hadoop.security.AccessControlException: CREATE failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.). [2b5e5d92-xxxx-xxxx-xxxx-db4ce6fa0487] failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.)
原因
RWX のアクセス許可またはデータセットのプロパティが正しく設定されていません。
推奨
ターゲット フォルダーに適切なアクセス許可がない場合は、「サービス プリンシパル認証を使用する」のドキュメントを参照して、Gen1 で適切なアクセス許可を割り当てます。
ターゲット フォルダーに適切なアクセス許可があり、データ フローのファイル名プロパティを使用して適切なフォルダーとファイル名をターゲットにしているが、データセットのファイル パスのプロパティがターゲット ファイル パスに設定されていない場合 (通常は設定しません)、次の図に示す例のように、バックエンド システムがデータセットのファイル パスに基づいてファイルを作成しようとし、データセットのファイル パスに正しいアクセス許可がないため、このエラーが発生します。
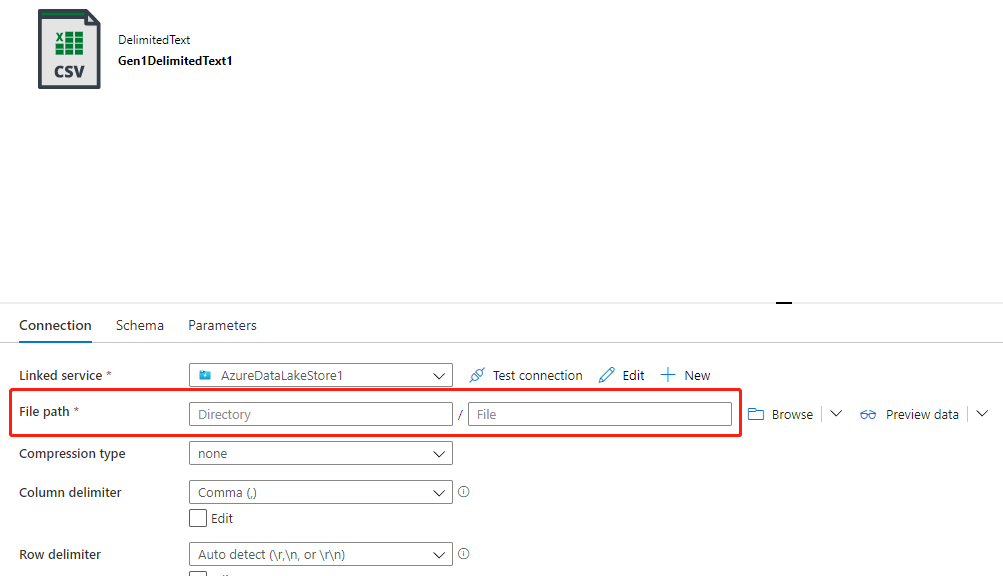
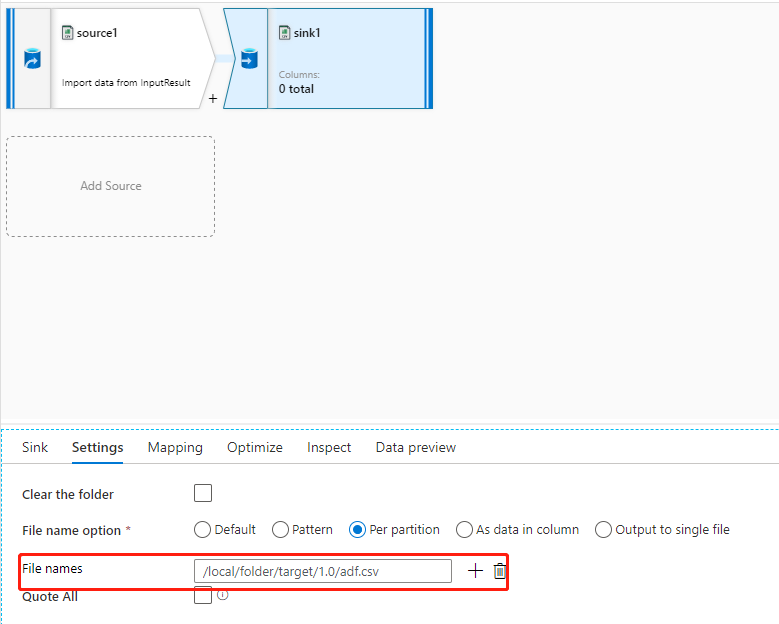
この問題を解決するには、2 つの方法があります。
- WX アクセス許可をデータセットのファイル パスに割り当てます。
- データセットのファイル パスを、WX アクセス許可を持つフォルダーとして設定し、残りのフォルダー パスとファイル名をデータ フローに設定します。
Azure Data Lake Storage Gen2
エラー: "Error while reading file XXX. (ファイル XXX の読み取り中にエラーが発生しました。) 基になるファイルが更新されている可能性があります。
現象
ADLS Gen2 をデータ フローのシンクとして使用し (データのプレビュー、デバッグまたはトリガーの実行などを行い)、シンク ステージの [最適化] タブのパーティション設定が既定ではない場合、次のエラー メッセージが表示されてジョブが失敗する可能性があります。
Job failed due to reason: Error while reading file abfss:REDACTED_LOCAL_PART@prod.dfs.core.windows.net/import/data/e3342084-930c-4f08-9975-558a3116a1a9/part-00000-tid-7848242374008877624-aaaabbbb-0000-cccc-1111-dddd2222eeee-1-1-c000.csv. It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved.
原因
- MI または SP の認証に適切なアクセス許可を割り当てていません。
- 不要なファイルを処理するためのカスタマイズされたジョブがある可能性があります。これはデータ フローの中間出力に影響します。
推奨
- リンク サービスに Gen2 に対する R/W/E アクセス許可があるかどうかを確認します。 MI 認証または SP 認証を使用する場合は、アクセス制御 (IAM) で少なくともストレージ BLOB データ共同作成者ロールを付与します。
- 名前が規則と一致しない別の場所にファイルを移動するまたはファイルを削除する特定のジョブがあるかどうかを確認します。 データ フローでは、最初にパーティション ファイルをターゲット フォルダーに書き込んでから、マージおよび名前変更操作が実行されるため、中間ファイルの名前が規則と一致しない場合があります。
Azure Database for PostgreSQL(PostgreSQL用Azureデータベース)
エラー: 次の例外で失敗しました: handshake_failure が発生する
現象
データのプレビューやデバッグまたはトリガーの実行などのデータ フローでソースまたはシンクとして Azure PostgreSQL を使用すると、次のエラー メッセージが表示されてジョブが失敗する場合があります。
PSQLException: SSL error: Received fatal alert: handshake_failure
Caused by: SSLHandshakeException: Received fatal alert: handshake_failure.
原因
Azure PostgreSQL サーバーにフレキシブル サーバーまたは Hyperscale (Citus) を使用する場合、システムは Azure Databricks クラスターで Spark を介して構築されるため、Azure Databricks には、システムがフレキシブル サーバーまたは Hyperscale (Citus) に接続するのをブロックするという制限があります。 参照用に次の 2 つのリンクを確認できます。
Azure Databricks から SSL を使用して Azure PostgreSQL に接続しようとするとハンドシェイクが失敗する
MCW-Real-Time-data-with-Azure-Database-for-PostgreSQL-Hyperscale
この記事の次の図の内容を参照してください。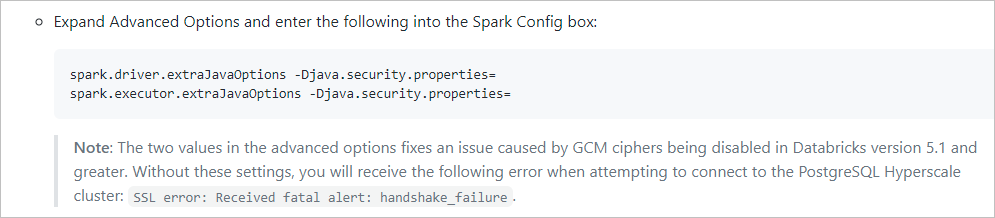
推奨
コピー アクティビティを使用して、この問題のブロック解除を試すことができます。
Azure SQL データベース
SQL Database に接続できない
現象
Azure SQL Database は、リンク サービスのデータ コピー、データセットのプレビュー データ、およびテスト接続で適切に機能しますが、同じ Azure SQL Database がデータ フローでソースまたはシンクとして使用されると、Cannot connect to SQL database: 'jdbc:sqlserver://powerbasenz.database.windows.net;..., Please check the linked service configuration is correct, and make sure the SQL database firewall allows the integration runtime to access.' のようなエラーが表示されて失敗します。
原因
Azure SQL Database サーバーのファイアウォール設定が間違っているため、データ フロー ランタイムで接続できません。 現時点では、データ フローを使用して Azure SQL Database の読み取り/書き込みを行おうとすると、ジョブを実行する Spark クラスターを構築するために Azure Databricks が使用されますが、これは固定 IP 範囲をサポートしていません。 詳細については、「Azure Integration Runtime の IP アドレス」を参照してください。
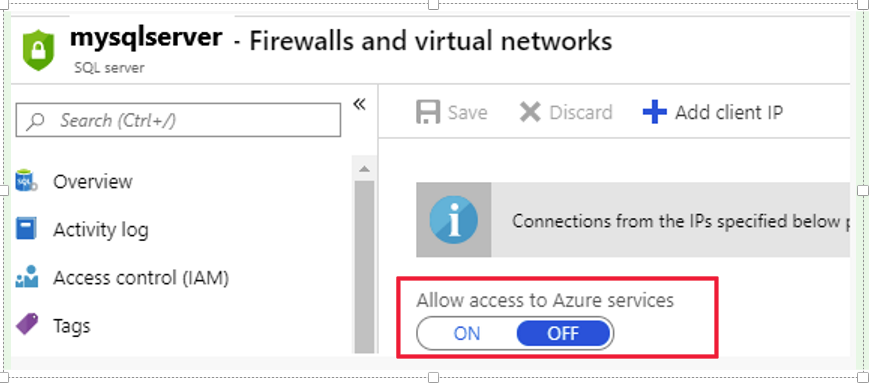
推奨
Azure SQL Database のファイアウォール設定を確認し、固定 IP の範囲を設定するのではなく、[Azure サービスへのアクセスを許可] に設定します。
入力としてクエリを使用すると構文エラーが発生する
現象
Azure SQL でデータ フロー ソースの入力としてクエリを使用すると、次のエラー メッセージが表示されて失敗します。
at Source 'source1': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax XXXXXXXX.
原因
データ フロー ソースで使用されるクエリは、サブクエリとして実行できる必要があります。 このエラーの原因は、クエリ構文が正しくないか、サブクエリとして実行できないことです。 SSMS で次のクエリを実行して、検証することができます。
SELECT top(0) * from ($yourQuery) as T_TEMP
推奨
適切なクエリを指定し、最初に SSMS でテストします。
"SQLServerException: 111212; トランザクション内で操作を実行できません" というエラーが出て失敗しました。
現象
Azure SQL Database をデータ フローのシンクとして使用して、データのプレビュー、デバッグまたはトリガーの実行、およびその他アクティビティを実行すると、次のエラー メッセージが表示されてジョブが失敗することがあります。
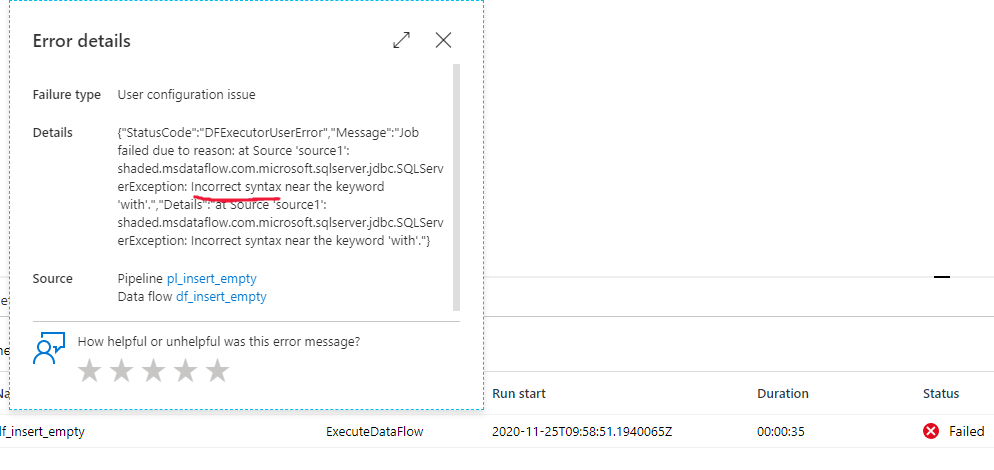
{"StatusCode":"DFExecutorUserError","Message":"Job failed due to reason: at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction.","Details":"at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction."}
原因
エラー "111212;Operation cannot be performed within a transaction." は、Synapse 専用 SQL プールでのみ発生します。 しかし、代わりに Azure SQL Database をコネクタとして誤って使用しています。
推奨
SQL Database が Synapse 専用 SQL プールであるかどうかを確認します。 その場合は、次の図に示すように、Azure Synapse Analytics をコネクタとして使用してください。
10 進型のデータが null になる
現象
SQL データベースのテーブルにデータを挿入するとします。 データに 10 進型が含まれていて、SQL データベースの 10 進型の列に挿入する必要がある場合は、データ値が null に変更される場合があります。
プレビューを実行すると、前のステージで、次の図のような値が表示されます。

シンク ステージでは、次の図に示すように null になります。

原因
10 進型には、小数点以下桁数と有効桁数のプロパティがあります。 データ型がシンク テーブル内のデータ型と一致しない場合、ターゲットの 10 進数が元の 10 進数よりも大きいかどうかがシステムによって検証されます。元の値はターゲットの 10 進数でオーバーフローしません。 そのため、値は null にキャストされます。
推奨
SQL データベースのデータとテーブルの間の 10 進型を確認して比較し、小数点以下桁数と有効桁数が同じになるように変更します。
toDecimal (IDecimal、小数点以下桁数、有効桁数) を使用して、元のデータをターゲットの小数点以下桁数と有効桁数にキャストできるかどうかを判断できます。 null が返された場合は、挿入時にデータをキャストして進めることができないことを意味します。
Azure Synapse Analytics
サーバーレス プール (SQL オンデマンド) 関連の問題
現象
Azure Synapse Analytics を使用すると、リンク サービスが実際には Synapse サーバーレス プールです。 以前は、SQL オンデマンド プールという名称でした。これは ondemand を含むサーバー名 (例: space-ondemand.sql.azuresynapse.net) を探すことで区別できます。 次のように、固有のエラーがいくつか発生する可能性があります。
- Synapse サーバーレス プールをシンクとして使用すると、次のエラーが発生します。
Sink results in 0 output columns. Please ensure at least one column is mapped - ソースで [Enable staging](ステージングの有効化) を選択すると、次のエラーが表示されます。
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax near 'IDENTITY'. - 外部テーブルからデータをフェッチすると、次のエラーが発生します。
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External table 'dbo' is not accessible because location does not exist or it is used by another process. - クエリを使用して、またはビューからサーバーレス プールを介して Azure Cosmos DB からデータをフェッチする場合、次のエラーが発生します:
Job failed due to reason: Connection reset. - ビューからデータをフェッチする場合は、異なるエラーが発生する可能性があります。
原因
現象の原因をそれぞれ以下に示します。
- サーバーレス プールをシンクとして使用することはできません。 データベースへのデータの書き込みはサポートされていません。
- サーバーレス プールでは、ステージング データの読み込みがサポートされていないため、"ステージングの有効化" はサポートされていません。
- 使用している認証方法に、外部テーブルが参照している外部データ ソースに対する適切なアクセス許可がありません。
- Synapse サーバーレス プールには、データ フローから Azure Cosmos DB データをフェッチすることをブロックする既知の制限があります。
- ビューは、SQL ステートメントに基づく仮想テーブルです。 根本原因は、ビューのステートメントの内部にあります。
推奨
次の手順を適用して、それぞれ問題を解決することができます。
サーバーレス プールをシンクとして使用しないようにします。
サーバーレス プールのソースで "ステージングの有効化" は使用しないでください。
外部テーブル データへのアクセス許可を持つサービス プリンシパルまたはマネージド ID のみがクエリを実行できます。 ADF 内で使用する認証方法の外部データ ソースに "ストレージ BLOB データ共同作成者" のアクセス許可を付与します。
注意
ユーザー パスワード認証では、外部テーブルに対してクエリを実行できません。 詳細については、「セキュリティ モデル」を参照してください。
コピー アクティビティを使用して、サーバーレス プールから Azure Cosmos DB データをフェッチできます。
ビューを作成する SQL ステートメントをエンジニアリング サポート チームに提供できます。これはステートメントが認証の問題などに直面しているかどうかを分析するのに役立ちます。
ステージングしないと Data Warehouse への小さいサイズのデータの読み込みが遅くなる
現象
ステージングせずに Data Warehouse に小さなデータを読み込むと、完了までに時間がかかります。 たとえば、2 MB サイズのデータでも、完了するまでに 1 時間以上かかります。
原因
この問題は、サイズではなく行数が原因で発生します。 行数が数千ある場合、独立した要求にパッケージ化し、制御ノードに移動して、新しいトランザクションを開始し、ロックを取得して、配布ノードに移動することを、挿入ごとに繰り返し行う必要があります。 一括読み込みによって一度ロックを取得すると、各配布ノードでは、メモリに効率的にバッチ処理することで挿入が実行されます。
2 MB がほんの数レコードとして挿入されている場合は、高速になります。 たとえば、各レコードが 500 kb * 4 行の場合、高速になります。
推奨
パフォーマンスを向上させるには、ステージングを有効にする必要があります。
ステージングを有効にすると、空の文字列値 ("") が NULL として読み取られる
現象
データのプレビューやデバッグまたはトリガーの実行など、データ フローのソースとして Synapse を使用し、ステージングを有効にして PolyBase を使用する場合、列の値に空の文字列値 ("") が含まれていると、null に変更されます。
原因
データ フロー バックエンドでは、Parquet が PolyBase 形式として使用されます。 Synapse SQL プール Gen2 には、空の文字列値が null に自動的に変更されるという既知の制限があります。
推奨
この問題を解決するには、次の方法を試してください。
- データ サイズが大きくない場合は、ソースで [ステージングの有効化] を無効にすることができますが、パフォーマンスに影響が出ます。
- ステージングを有効にする必要がある場合は、iifNull() 関数を使用して、特定の列を null から空の文字列値に手動で変更できます。
マネージド サービス ID のエラー
現象
Synapse をデータ フローのソースまたはシンクとして使用して、データのプレビュー、デバッグまたはトリガーの実行などを行い、ステージングで PolyBase を使用できるようにすると、マネージド ID (MI) 認証を使用するためにステージング ストアのリンク サービス (BLOB、Gen2 など) が作成されます。ジョブは、次の図に示されているエラーで失敗する場合があります。
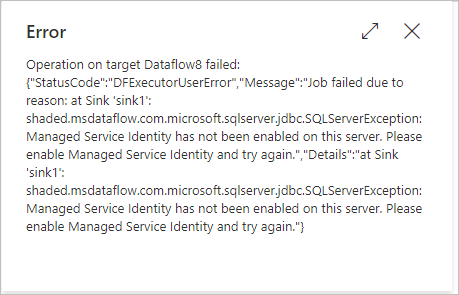
エラー メッセージ
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Managed Service Identity has not been enabled on this server. Please enable Managed Service Identity and try again.
原因
- SQL プールが Synapse ワークスペースから作成されている場合、PolyBase を使用したステージング ストアでの MI 認証は、古い SQL プールではサポートされません。
- SQL プールが古い Data Warehouse (DWH) バージョンの場合、SQL Server の MI はステージング ストアに割り当てられません。
推奨
SQL プールが Azure Synapse ワークスペースから作成されたことを確認します。
- SQL プールが Azure Synapse ワークスペースから作成された場合、追加の手順は必要ありません。 ワークスペースのマネージド ID (MI) を再登録する必要がなくなりました。 ワークスペースのシステム割り当てマネージド ID (SA-MI) は、Synapse 管理者ロールのメンバーであるため、ワークスペースの専用 SQL プールに対する昇格された特権を持っています。
- SQL プールが、Azure Synapse よりも前から存在する専用 SQL プール (旧称 SQL DW) である場合は、お使いの SQL サーバーに対して MI を有効にして、ステージング ストアのアクセス許可をご自身の SQL Server の MI に割り当てるだけです。 例として、「Azure SQL Database のサーバー用の仮想ネットワーク サービス エンドポイントと規則の使用」の「手順」を参照してください。
エラー: "SQLServerException: Not able to validate external location because the remote server returned an error: (403)" (SQLServerException: リモート サーバーからエラーが返されたため、外部の場所を検証できません: (403)) で失敗する
現象
SQLDW をシンクとして使用し、データ フロー アクティビティをトリガーして実行すると、アクティビティが次のようなエラーで失敗する場合があります: "SQLServerException: Not able to validate external location because the remote server returned an error: (403)"
原因
- ADLS Gen2 アカウントの認証方法でマネージド ID をステージングとして使用すると、認証構成を正しく設定できない場合があります。
- 仮想ネットワーク統合ランタイムでは、ADLS Gen2 アカウントの認証方法でマネージド ID をステージングとして使用する必要があります。 ステージング Azure Storage が仮想ネットワーク サービス エンドポイントで構成されている場合は、ストレージ アカウントで "信頼された Microsoft サービスを許可する" を有効にしたマネージド ID 認証を使用する必要があります。
- フォルダー名に空白文字またはその他の特殊文字が含まれているかどうかを確認します (例:
Space " < > # % |)。 現在、特定の特殊文字を含むフォルダー名は、Data Warehouse のコピー コマンドではサポートされていません。
推奨
原因 1 については、「Azure SQL Database のサーバー用の仮想ネットワーク サービス エンドポイントと規則の使用」ドキュメントの「手順」を参照して、この問題を解決できます。
原因 2 については、次のいずれかのオプションを使用して回避することができます。
オプション 1: 仮想ネットワーク統合ランタイムを使用する場合は、ADLS GEN 2 アカウントの認証方法でマネージド ID をステージングとして使用する必要があります。
オプション 2: ステージング Azure Storage が仮想ネットワーク サービス エンドポイントで構成されている場合は、ストレージ アカウントで "信頼された Microsoft サービスを許可する" を有効にしたマネージド ID 認証を使用する必要があります。 詳細については、「PolyBase を使用したステージング コピー」のドキュメントを参照してください。
原因 3 については、次のいずれかのオプションを使用して回避することができます。
オプション-1: フォルダーの名前を変更し、フォルダー名に特殊文字を使用しないようにします。
オプション-2: データ フロー スクリプトのプロパティ
allowCopyCommand:trueを削除します。次に例を示します。
"shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: ユーザーにこのアクションを実行するアクセス許可はありません" というエラーで失敗しました。
現象
ソース/シンクとして Azure Synapse Analytics を使用し、データ フローで PolyBase ステージングを使用すると、次のエラーが発生します。
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action.
原因
PolyBase を使用するには、Synapse SQL サーバーで特定のアクセス許可が必要です。
推奨
PolyBase を使用する場合は、Synapse SQL サーバーに次のアクセス許可を付与します。
ALTER ANY SCHEMA
外部データ ソースを変更する
任意の外部ファイル形式を変更する
コントロールデータベース
Common Data Model 形式
特殊文字を含む Model.Json ファイル
現象
model.Json ファイルの最終的な名前に特殊文字が含まれているという問題が発生することがあります。
エラー メッセージ
at Source 'source1': java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: PPDFTable1.csv@snapshot=2020-10-21T18:00:36.9469086Z.
推奨
ファイル名に含まれる特殊文字を置き換えます。これは Synapse では機能しますが、ADF では機能しません。
データのプレビューまたはパイプラインの実行後にデータが出力されない
現象
CDM に manifest.json を使用すると、データ プレビューに、またはパイプラインの実行後にデータが表示されません。 ヘッダーのみが表示されます。 この問題は、次の図で確認できます。
原因
マニフェスト ドキュメントに、CDM フォルダーが記述されています。たとえば、フォルダー内にあるエンティティ、それらのエンティティの参照、およびこのインスタンスに対応するデータなどです。 マニフェスト ドキュメントには、データの読み取り先を ADF に示す dataPartitions 情報がありません。この情報が空であるため、データが返されません。
推奨
dataPartitions 情報を含めるようにマニフェスト ドキュメントを更新します。ドキュメントを更新するには、Common Data Model メタデータ: マニフェストの概要 - サンプル マニフェスト ドキュメントのサンプル マニフェスト ドキュメントを参照してください。
JSON 配列属性が個別の列として推論される
現象
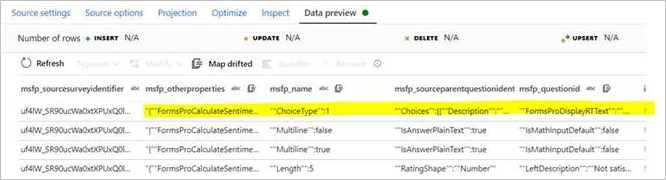
CDM エンティティの 1 つの属性 (文字列型) にデータとして JSON 配列があるという問題が発生する場合があります。 このデータが検出されると、ADF によってデータが個別の列として誤って推論されます。 次の図からわかるように、ソースに示される 1 つの属性 (msfp_otherproperties) は、CDM コネクタのプレビューでは個別の列として推論されます。
CSV ソース データ (2 番目の列を参照):

CDM ソース データ プレビュー:
また、誤差の列をマップし、データ フロー式を使用して、この属性を配列として変換することもできます。 ただし、この属性は読み取り時に別の列として読み取られるため、配列への変換は機能しません。
原因
この問題は、その列の JSON オブジェクト値内のコンマが原因である可能性があります。 データ ファイルは CSV ファイルであることが想定されているため、コンマは列の値の末尾を示します。
推奨
この問題を解決するには、JSON 列を二重引用符で囲み、円記号 (\) を使用して内側の引用符を回避する必要があります。 こうすることで、その列の値の内容を 1 つの列として完全に読み込むことができます。
注意
CDM から、列の値のデータ型が JSON であることは通知されませんが、文字列であり、そのように解析されることが通知されます。
データ フロー プレビューでデータをフェッチできない
現象
Power BI によって生成された model.json で CDM を使用します。 データ フロー プレビューを使用して CDM データをプレビューすると、次のエラーが発生します。 No output data.
原因
次のコードが、Power BI データ フローによって生成される model.json ファイルのパーティションに存在しています。
"partitions": [
{
"name": "Part001",
"refreshTime": "2020-10-02T13:26:10.7624605+00:00",
"location": "https://datalakegen2.dfs.core.windows.net/powerbi/salesEntities/salesPerfByYear.csv @snapshot=2020-10-02T13:26:10.6681248Z"
}
この model.json ファイルの場合、問題は、データ パーティション ファイルの名前付けスキーマに特殊文字が含まれていて、'@' を含むサポート ファイル パスが現在存在していないことです。
推奨
データ パーティションのファイル名と model.json ファイルから @snapshot=2020-10-02T13:26:10.6681248Z の部分を削除し、操作をやり直してください。
コーパスのパスが null または空である
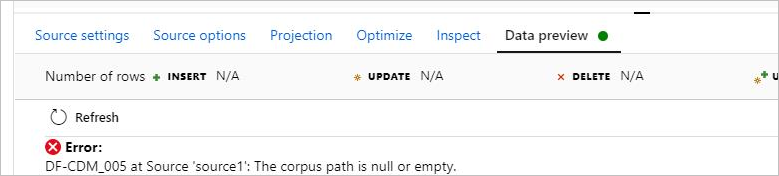
現象
モデル形式のデータ フローで CDM を使用すると、データをプレビューできず、次のエラーが発生します: DF-CDM_005 The corpus path is null or empty。 エラーを次の図に示します。
原因
model.json のデータ パーティション パスが、データ レイクではなく BLOB ストレージの場所を指しています。 この場所には、ADLS Gen2 の dfs.core.windows.net のベース URL を指定する必要があります。
推奨
この問題を解決するには、「ADF によりインライン データセットと Common Data Model のサポートがデータ フローに追加される」を参照してください。次の図は、この記事のコーパス パス エラーを修正する方法を示しています。
CSV データ ファイルが読み取れない
現象
マニフェストをソースとして持つ共通データ モデルとしてインライン データセットを使用し、エントリ マニフェスト ファイル、ルート パス、エンティティ名、およびパスを指定しました。 マニフェストには、CSV ファイルの場所を含むデータ パーティションがあります。 一方、エンティティ スキーマと csv スキーマは同一で、すべての検証は成功しました。 ただし、データ プレビューでは、データではなくスキーマのみが読み込まれ、データは非表示になります。これを次の図に示します。
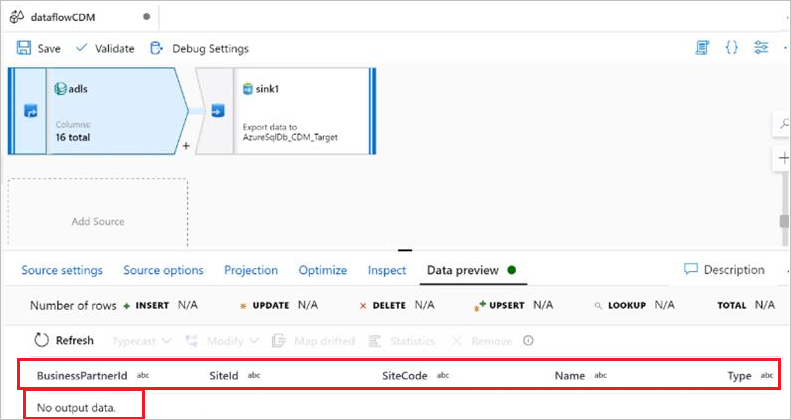
原因
CDM フォルダーは論理モデルと物理モデルに分離されていないため、CDM フォルダーには物理モデルのみが存在します。 「論理定義」と「論理エンティティ定義の解決」の 2 つの記事でその違いを説明しています。
推奨
ソースとして CDM を使用するデータ フローの場合、エンティティ参照として論理モデルを使用し、物理的に解決されたエンティティの場所とデータ パーティションの場所を記述するマニフェストを使用してみてください。 パブリック CDM GitHub リポジトリ (CDM-schemaDocuments) 内で、論理エンティティ定義のサンプルをいくつか見ることができます
コーパスを作成するには、最初にスキーマ ドキュメント フォルダー (GitHub リポジトリ内のそのレベル) 内のファイルをコピーし、それらのファイルをフォルダーに配置することをお勧めします。 その後、リポジトリ内の定義済みの論理エンティティの 1 つを (開始点または参照ポイントとして) 使用して、論理モデルを作成できます。
コーパスを設定したら、データ フロー内でシンクとして CDM を使用することをお勧めします。これにより、整形式の CDM フォルダーを適切に作成できます。 CSV データセットをソースとして使用して、作成した CDM モデルにシンクできます。
CSV と Excel 形式
CSV で、引用符文字を 'no quote char' に設定することがサポートされていない
現象
引用符文字が 'no quote char' に設定されていると、CSV ではサポートされない問題がいくつかあります。
- 引用符文字が 'no quote char' に設定されている場合、複数文字の列区切り記号の先頭と末尾を同じ文字にすることはできません。
- 引用符文字が 'no quote char' に設定されている場合、複数文字の列区切り記号にエスケープ文字 (
\) を含めることはできません。 - 引用符文字が 'no quote char' に設定されている場合、列の値に行の区切り記号を含めることはできません。
- 列の値に列の区切り記号が含まれている場合、引用符文字とエスケープ文字の両方を空 (no quote および no escape) にすることはできません。
原因
この現象の原因を、それぞれ例とともに以下に示します。
先頭と末尾に同じ文字を使用している。
column delimiter: $*^$*
column value: abc$*^ def
csv sink: abc$*^$*^$*def
will be read as "abc" and "^&*def"複数文字の区切り記号にエスケープ文字が含まれている。
column delimiter: \x
escape char:\
column value: "abc\\xdef"
エスケープ文字は、列区切り記号または文字のいずれかをエスケープします。列の値に行区切り記号が含まれている。
We need quote character to tell if row delimiter is inside column value or not.引用符文字とエスケープ文字の両方が空で、列の値に列の区切り記号が含まれている。
Column delimiter: \t
column value: 111\t222\t33\t3
It will be ambiguous if it contains 3 columns 111,222,33\t3 or 4 columns 111,222,33,3.
推奨
1 番目の現象と 2 番目の現象は現在解決できません。 3 番目と 4 番目の現象には、次の方法を適用できます。
- 現象 3 の場合、複数行の csv ファイルに 'no quote char' を使用しないでください。
- 現象 4 の場合、引用符文字またはエスケープ文字のいずれかを空以外に設定するか、データ内のすべての列区切り記号を削除します。
スキーマが異なるファイルの読み取りエラー
現象
データ フローを使用して、スキーマが異なる CSV や Excel などのファイルを読み取ると、データ フローのデバッグ、サンドボックス、またはアクティビティの実行が失敗します。
CSV の場合、ファイルのスキーマが異なると、データの不整合が発生します。
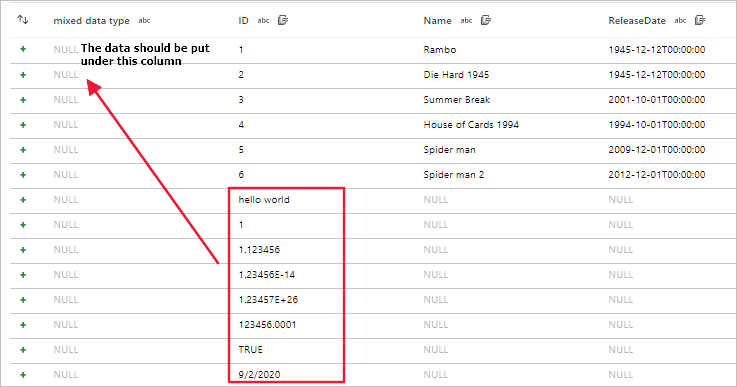
Excel の場合、ファイルのスキーマが異なるとエラーが発生します。

原因
データ フローでスキーマが異なるファイルを読み取ることはサポートされていません。
推奨
それでもデータ フローで CSV や Excel ファイルなどのスキーマが異なるファイルを転送する必要がある場合は、次の方法を使用して対処できます。
CSV の場合、スキーマ全体を取得するには、異なるファイルのスキーマを手動でマージする必要があります。 たとえば、file_1 には列
c_1、c_2、c_3があり、file_2 には列c_3、c_4、...c_10があるため、マージされた完全なスキーマはc_1、c_2、...c_10になります。 データがない場合でも、他のファイルにも同じ完全なスキーマが含まれるようにします。たとえば、file_x には列c_1、c_2、c_3、c_4しかないので、ファイルに列c_5、c_6、...c_10を追加して、他のファイルと一致させます。Excel の場合は、次のいずれかのオプションを適用することで、この問題を解決できます。
-
オプション-1: スキーマ全体を取得するには、異なるファイルのスキーマを手動でマージする必要があります。 たとえば、file_1 には列
c_1、c_2、c_3があり、file_2 には列c_3、c_4、...c_10があるため、マージされた完全なスキーマはc_1、c_2、...c_10になります。 データがない場合でも、他のファイルにも同じスキーマが含まれるようにします。たとえば、file_x の "SHEET_1" には列c_1、c_2、c_3、c_4しかないので、シートに列c_5、c_6、...c_10も追加すると、機能するようになります。 - オプション-2: range (例: A1:G100) + firstRowAsHeader = false を使用すると、列名と数が異なっていても、すべての Excel ファイルからデータを読み込むことができます。
-
オプション-1: スキーマ全体を取得するには、異なるファイルのスキーマを手動でマージする必要があります。 たとえば、file_1 には列
雪片
Snowflake のリンク サービスに接続できない
現象
公衆ネットワークで Snowflake のリンク サービスを作成し、自動解決統合ランタイムを使用すると、次のエラーが発生します。
ERROR [HY000] [Microsoft][Snowflake] (4) REST request for URL https://XXXXXXXX.east-us- 2.azure.snowflakecomputing.com.snowflakecomputing.com:443/session/v1/login-request?requestId=XXXXXXXXXXXXXXXXXXXXXXXXX&request_guid=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
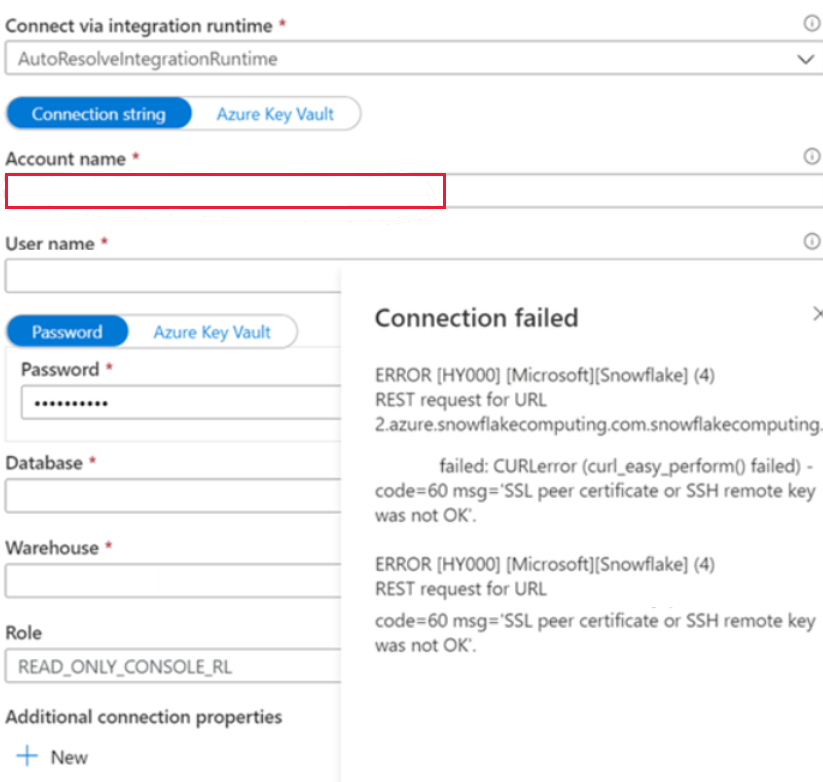
原因
Snowflake アカウントのドキュメントに記載されている形式 (リージョンとクラウド プラットフォームを識別する追加のセグメントを含む) (例: XXXXXXXX.east-us-2.azure) で アカウント名を適用していません。 詳細については、「リンク サービスのプロパティ」のドキュメントを参照してください。
推奨
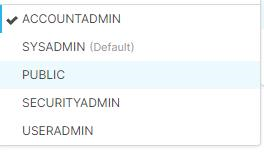
この問題を解決するには、アカウント名の形式を変更します。 ロールは次の図に示すロールのいずれかにする必要がありますが、既定のロールは Public です。
SQL アクセス制御エラー: "Insufficient privileges to operate on schema" (スキーマを操作するための十分な特権がありません)
現象
データ フローの Snowflake ソースで [Import projection](プロジェクションのインポート)、[Data Preview](データのプレビュー) などを使用しようとすると、次のようなエラーが発生します。net.snowflake.client.jdbc.SnowflakeSQLException: SQL access control error: Insufficient privileges to operate on schema
原因
このエラーは、構成が間違っていることが原因で発生します。 データ フローを使用して Snowflake データを読み取ると、ランタイム Azure Databricks (ADB) で、Snowflake へのクエリが直接選択されません。 代わりに、一時的なステージが作成され、データはテーブルからステージにプルされてから、ADB によって圧縮およびプルされます。 このプロセスを次の図に示します。
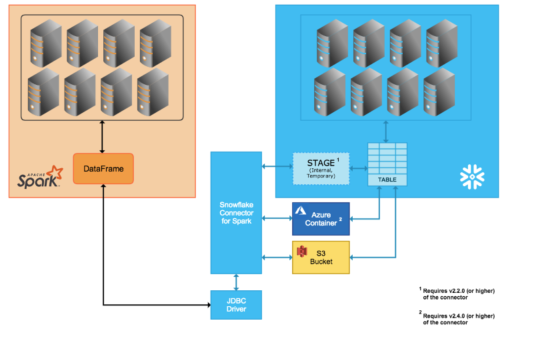
そのため、ADB で使用されるユーザーまたはロールには、Snowflake でこれを行うための権限が必要です。 ただし、データベースは共有に作成されるため、通常、ユーザーまたはロールには権限がありません。
推奨
この問題を解決するには、別のデータベースを作成し、共有 DB の一番上にビューを作成して、ADB からアクセスできるようにします。 詳細については、Snowflake を参照してください。
"SnowflakeSQLException: IP x.x.x.x は、Snowflake へのアクセスを許可されていません" というエラーが出て失敗しました。 Contact your local security administrator" (ローカル セキュリティ管理者に問い合わせてください) で失敗する
現象
Azure Data Factory で Snowflake を使用すると、Snowflake のリンク サービスでテスト接続を正常に使用することができ、Snowflake データセットでデータのプレビューまたはスキーマのインポートをしたり、メタデータやその他のアクティビティのコピー、検索、取得を実行したりすることができます。 しかし、データ フロー アクティビティで Snowflake を使用すると、次のようなエラーが発生する可能性があります: SnowflakeSQLException: IP 13.66.58.164 is not allowed to access Snowflake. Contact your local security administrator.
原因
Azure Data Factory データ フローでは、固定 IP 範囲の使用はサポートされていません。 詳細については、「Azure Integration Runtime の IP アドレス」を参照してください。
推奨
この問題を解決するには、次の手順に従って、Snowflake アカウントのファイアウォール設定を変更します。
サービス タグの IP 範囲の一覧は、「ダウンロード可能な JSON ファイルを使用してサービス タグを検出する」のサービス タグの IP 範囲のダウンロード リンクから取得できます。
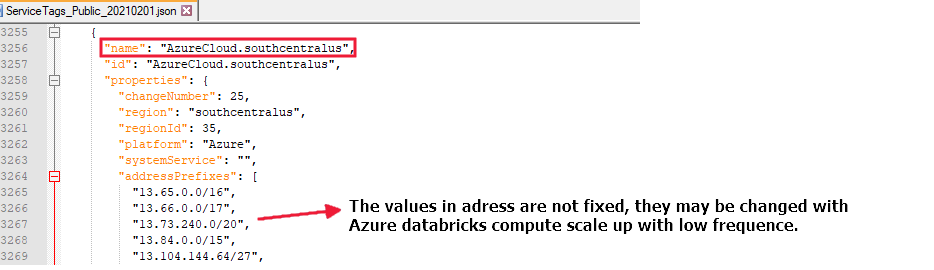
"southcentralus" リージョンでデータ フローを実行する場合は、"AzureCloud.southcentralus" という名前のすべてのアドレスからのアクセスを許可する必要があります。次に例を示します。
ソース内のクエリが機能しない
現象
クエリを使用して Snowflake からデータを読み取ろうとすると、次のようなエラーが発生することがあります。
SQL compilation error: error line 1 at position 7 invalid identifier 'xxx'SQL compilation error: Object 'xxx' does not exist or not authorized.
原因
このエラーは、構成が間違っていることが原因で発生します。
推奨
Snowflake の場合、作成時または定義時に識別子を格納し、クエリやその他の SQL ステートメントでそれらを解決するために、次の規則が適用されます。
識別子 (テーブル名、スキーマ名、列名など) が引用符で囲まれていない場合、既定では大文字で格納および解決され、大文字と小文字は区別されません。 次に例を示します。

大文字と小文字が区別されないため、次のクエリを使用して Snowflake データを読み取ると、同じ結果になります。
Select MovieID, title from Public.TestQuotedTable2Select movieId, title from Public.TESTQUOTEDTABLE2Select movieID, TITLE from PUBLIC.TESTQUOTEDTABLE2
識別子 (テーブル名、スキーマ名、列名など) が二重引用符で囲まれている場合は、大文字と小文字が区別される場合と同様、入力したとおりに格納および解決されます。次の図に例を示します。 詳細については、「識別子の要件」を参照してください。

大文字と小文字を区別する識別子 (テーブル名、スキーマ名、列名など) には小文字が含まれているため、クエリを使用してデータを読み取るときに識別子を引用符で囲む必要があります。次に例を示します。
- Public. "testQuotedTable2" から "movieId" 、 "title" を選択します
Snowflake のクエリでエラーが発生した場合は、次の手順に従って、一部の識別子 (テーブル名、スキーマ名、列名など) で大文字と小文字が区別されているかどうかを確認します。
Snowflake サーバー (
https://{accountName}.azure.snowflakecomputing.com/、{accountName} を自分のアカウント名に置き換える) にサインインして、識別子 (テーブル名、スキーマ名、列名など) を確認します。クエリをテストして検証するためのワークシートを作成します。
-
Use database {databaseName}を実行します。{databaseName} は実際のデータベース名に置き換えます。 - テーブルを使用してクエリを実行します。例:
select "movieId", "title" from Public."testQuotedTable2"
-
Snowflake の SQL クエリは、テストと検証が終了したら、データ フローの Snowflake ソースで直接使用することができます。
式の型が列のデータ型と一致しません。VARIANT が必要ですが、VARCHAR が取得されました
現象
Snowflake テーブルにデータを書き込もうとすると、次のエラーが発生する場合があります。
java.sql.BatchUpdateException: SQL compilation error: Expression type does not match column data type, expecting VARIANT but got VARCHAR
原因
入力データの列の型は文字列ですが、これは Snowflake シンクの関連する列の VARIANT 型と異なります。
複雑なスキーマ (配列/マップ/構造体) のデータを新しい Snowflake テーブルに格納すると、データ フローの型は、その物理的な型である VARIANT に自動的に変換されます。

次の図に示すように、関連する値は JSON 文字列として格納されます。

推奨
Snowflake VARIANT は、構造体、マップ、配列のいずれかの型のデータ フロー値のみを受け取ります。 入力データ列の値が JSON、XML、その他の文字列の場合は、次のいずれかのオプションを使用してこの問題を解決します。
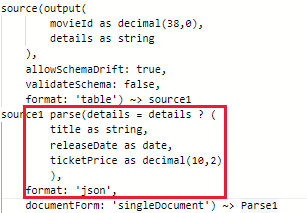
オプション-1: 入力データ列の値を構造体、マップ、または配列型に変換するために、Snowflake をシンクとして使用する前に、解析変換を使用します。次に例を示します。
注意
VARIANT 型の Snowflake 列の値は、Spark では既定で文字列として読み取られます。
オプション-2: Snowflake サーバー (
https://{accountName}.azure.snowflakecomputing.com/、{accountName} を自分のアカウント名に置き換える) にサインインして、Snowflake ターゲット テーブルのスキーマを変更します。 各手順でクエリを実行して、次の手順を適用します。VARCHAR を含む新しい列を 1 つ作成して、値を格納します。
alter table tablename add newcolumnname varchar;VARIANT の値を新しい列にコピーします。
update tablename t1 set newcolumnname = t1."details"使用していない VARIANT 列を削除します。
alter table tablename drop column "details";新しい列の名前を古い名前に変更します。
alter table tablename rename column newcolumnname to "details";
関連するコンテンツ
トラブルシューティングの詳細について、次のリソースを参照してください。