適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
この記事では、Azure Data FactoryパイプラインとAzure Synapse パイプラインのCopy アクティビティを使用して Snowflake との間でデータをコピーし、Data Flowを使用して Snowflake のデータを変換する方法について説明します。 詳細については、Data Factory または Azure Synapse Analytics の入門記事を参照してください。
Important
Snowflake V1 コネクタは 取り外し段階にあります。 Snowflake コネクタを V1 から V2 にアップグレードすることをお勧めします。
サポートされる機能
この Snowflake コネクタは、次の機能でサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/シンク) | (1) (2) |
| マッピング データ フロー (ソース/シンク) | ① |
| Lookup アクティビティ | (1) (2) |
| スクリプト アクティビティ (スクリプト パラメーターを使用する場合はバージョン 1.1 を適用する) | (1) (2) |
(1) Azure統合ランタイム (2) セルフホステッド統合ランタイム
Copy アクティビティの場合、この Snowflake コネクタは次の機能をサポートします。
- Snowflake からのデータのコピー。Snowflake の COPY into [location] コマンドを利用して、最適なパフォーマンスを実現します。
- Snowflake へのデータのコピー。Snowflake の COPY into [table] コマンドを利用して、最適なパフォーマンスを実現します。 Azureで Snowflake をサポートしています。
- セルフホステッド Integration Runtimeから Snowflake に接続するためにプロキシが必要な場合は、Integration Runtime ホストでHTTP_PROXYとHTTPS_PROXYの環境変数を構成する必要があります。
Prerequisites
データ ストアがオンプレミス ネットワーク、Azure仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、自身がホストする統合ランタイム を構成して接続する必要があります。 セルフホステッド統合ランタイムが使用する IP アドレスを許可リストに追加する必要があります。
データ ストアがマネージド クラウド データ サービスの場合は、Azure Integration Runtimeを使用できます。 アクセスがファイアウォール規則で承認されている IP に制限されている場合は、許可リストに Azure Integration Runtime IP を追加できます。
ソースまたはシンクに使用される Snowflake アカウントには、データベースに対する必要な USAGE アクセス権と、スキーマおよびその下のテーブル/ビューに対する読み取り/書き込みアクセス権が必要です。 さらに、SAS URI を使用して外部ステージを作成できるように、スキーマ上に CREATE STAGE も存在する必要があります。
次のアカウント プロパティの値を設定する必要があります
| Property | Description | Required | Default |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | プライベート クラウド ストレージの場所にアクセスするために (CREATE STAGE を使用して) 名前付き外部ステージを作成するときに、ストレージ統合オブジェクトをクラウド資格情報として要求するかどうかを指定します。 | FALSE | FALSE |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | プライベート クラウド ストレージの場所へのデータの読み込みまたはアンロードを行うときに、ストレージ統合オブジェクトをクラウド資格情報として参照する名前付き外部ステージの使用を要求するかどうかを指定します。 | FALSE | FALSE |
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
概要
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用できます。
- データのコピー ツール
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager テンプレート
UI を使用して Snowflake のリンク サービスを作成する
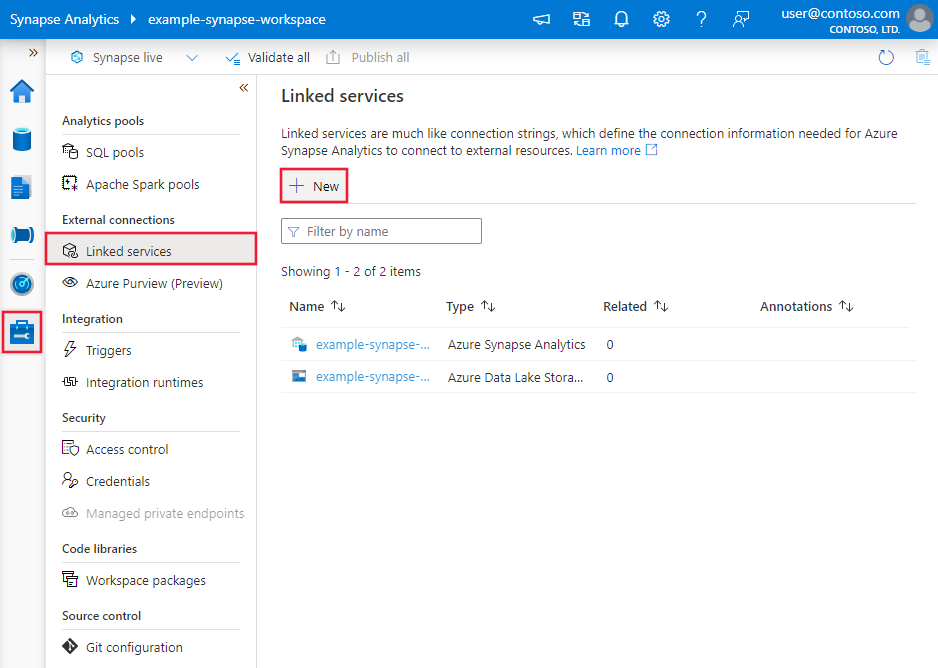
Azure ポータル UI で Snowflake へのリンクされたサービスを作成するには、次の手順に従います。
Azure Data Factoryまたは Synapse ワークスペースの [管理] タブを参照し、[リンクされたサービス] を選択し、[新規] をクリックします。
- Azureデータファクトリー
- Azure Synapse
Azure Data Factory UI を使用した新しいリンク サービスの作成のスクリーンショット Snowflake を検索し、Snowflake コネクタを選択します。

サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
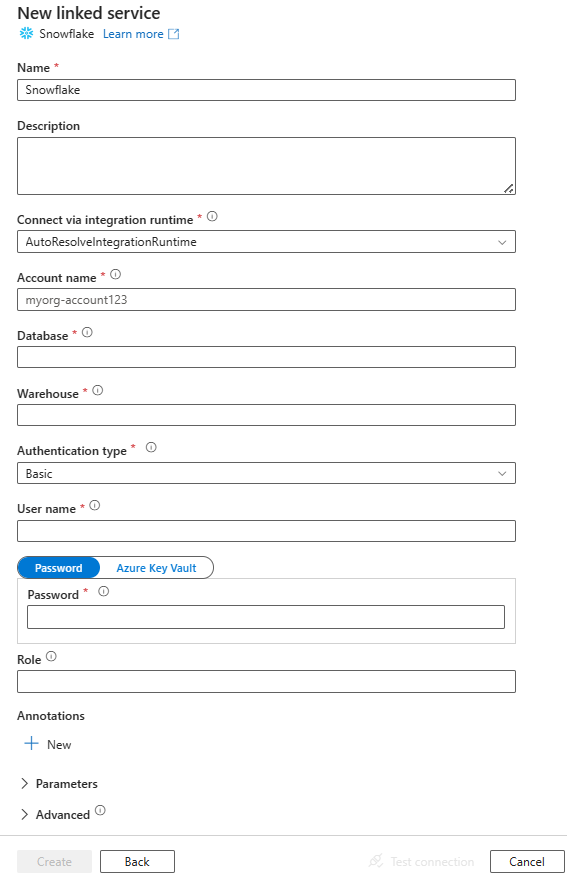
コネクタの構成の詳細
次のセクションでは、Snowflake コネクタに固有のエンティティを定義するプロパティについて詳しく説明します。
リンクされたサービス プロパティ
Snowflake のリンク サービスでは、次の汎用プロパティがサポートされます。
| Property | Description | Required |
|---|---|---|
| 型 | type プロパティは SnowflakeV2 に設定する必要があります。 | Yes |
| バージョン | 指定するバージョン。 最新の拡張機能を利用するには、最新バージョンにアップグレードすることをお勧めします。 | はい (バージョン 1.1 の場合) |
| accountIdentifier | その組織とアカウントの名前。 たとえば、myorg-account123。 | Yes |
| データベース | 接続後にセッションで使用される既定のデータベース。 | Yes |
| warehouse | 接続後にセッションで使用される既定の仮想ウェアハウス。 | Yes |
| authenticationType | Snowflake サービスへの接続に使用される認証の種類。 使用することができる値は、Basic (既定値) と KeyPair です。 それぞれのプロパティとサンプルについては、以下の対応するセクションを参照してください。 | No |
| ロール | 接続後にセッションで使用される既定のセキュリティ ロール。 | No |
| ホスティング | Snowflake アカウントのホスト名。 (例: contoso.snowflakecomputing.com)。
.cn もサポートされています。 |
No |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 Azure統合ランタイムまたはセルフホステッド統合ランタイムを使用できます (データ ストアがプライベート ネットワークにある場合)。 指定しない場合は、既定のAzure統合ランタイムが使用されます。 | No |
リンクされたサービスでは、ケースに応じて、次の追加の接続プロパティを設定できます。
| Property | Description | Required | 既定値 |
|---|---|---|---|
| UseUtcTimestamps |
false を指定して、正しいタイムゾーンにおける TIMESTAMP_LTZ 型と TIMESTAMP_TZ 型を返し、タイムゾーン情報を含まない TIMESTAMP_NTZ 型を返します。 すべての Snowflake タイムスタンプ型を UTC で返す true に指定します。 |
No | false |
| スキーマ | 接続後のクエリ セッションのスキーマを指定します。 | No | / |
この Snowflake コネクタでは、次の認証の種類がサポートされています。 詳細については、対応するセクションをご覧ください。
基本認証
前のセクションで説明した汎用的なプロパティに加えて、基本認証を使用するには、次のプロパティを指定します。
| Property | Description | Required |
|---|---|---|
| ユーザー | Snowflake ユーザーのログイン名。 | Yes |
| パスワード | Snowflake ユーザーのパスワード。 安全に保存するには、このフィールドを SecureString 型としてマークします。 Azure Key Vaultに格納されているシークレットを |
Yes |
Example:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Azure Key Vault のパスワード:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
キー ペア認証
キー ペア認証を使用するには、「キー ペア認証とキー ペア ローテーション」を参照して、Snowflake 内にキー ペア認証ユーザーを構成および作成する必要があります。 その後、秘密キーとパスフレーズ (省略可能) を書き留めます (リンク サービスを定義するために使用します)。
前のセクションで説明した汎用的なプロパティに加えて、次のプロパティを指定します。
| Property | Description | Required |
|---|---|---|
| ユーザー | Snowflake ユーザーのログイン名。 | Yes |
| privateKey | キー ペア認証に使用される秘密キー。 秘密キーがAzure Data Factoryに送信されるときに有効であることを確認し、privateKey ファイルに改行文字 (\n) が含まれていることを考慮するには、privateKey コンテンツを文字列リテラル形式で正しく書式設定することが不可欠です。 このプロセスでは、各改行に「\n」を明示的に追加します。 |
Yes |
| privateKeyPassphrase | 秘密キーの暗号化解除に使用されるパスフレーズ (暗号化されている場合)。 | No |
Example:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Note
マッピング データ フローでは、PEM 形式 (.p8 ファイル) の PKCS#8 標準を使用して新しい RSA 秘密キーを生成することをお勧めします。
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。
Snowflake データセットでは、次のプロパティがサポートされます。
| Property | Description | Required |
|---|---|---|
| 型 | データセットの type プロパティは SnowflakeV2Table に設定する必要があります。 | Yes |
| スキーマ | スキーマの名前。 スキーマ名は、大文字と小文字が区別されることに注意してください。 | ソースの場合はいいえ、シンクの場合ははい |
| テーブル | テーブル/ビューの名前。 テーブル名は、大文字と小文字が区別されることに注意してください。 | ソースの場合はいいえ、シンクの場合ははい |
Example:
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Copy アクティビティ のプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、Snowflake のソースとシンクでサポートされるプロパティの一覧を示します。
ソースとしての Snowflake
Snowflake コネクタは、Snowflake の COPY into [location] コマンドを利用して、最適なパフォーマンスを実現します。
シンク データ ストアと形式が Snowflake COPY コマンドでネイティブにサポートされている場合は、Copy アクティビティを使用して Snowflake からシンクに直接コピーできます。 詳しくは、「Snowflake から直接コピーする」をご覧ください。 それ以外の場合は、組み込みの Snowflake からのステージング コピーを使用します。
Snowflake からデータをコピーするには、Copy アクティビティ source セクションで次のプロパティがサポートされています。
| Property | Description | Required |
|---|---|---|
| 型 | Copy アクティビティ ソースの type プロパティは、SnowflakeV2Source に設定する必要があります。 | Yes |
| クエリ | Snowflake からデータを読み取る SQL クエリを指定します。 スキーマ、テーブル、および列の名前に小文字が含まれている場合は、クエリでオブジェクト識別子を引用符で囲みます (例: select * from "schema"."myTable")。ストアド プロシージャの実行はサポートされていません。 |
No |
| exportSettings | Snowflake からデータを取得するために使用される詳細設定。 COPY into コマンドでサポートされるものを構成することができ、ステートメントを呼び出す際にサービスが処理します。 | Yes |
| treatDecimalAsString | 検索およびスクリプト アクティビティで、10 進型を文字列型として扱うように指定します。 既定値は false です。このプロパティは、バージョン 1.1 でのみサポートされています。 |
No |
exportSettings の下: |
||
| 型 | エクスポート コマンドの type を SnowflakeExportCopyCommand に設定します。 | Yes |
| storageIntegration | Snowflake で作成したストレージ統合の名前を指定します。 ストレージ統合を使用するための前提となる手順については、「Snowflake ストレージ統合の構成」を参照してください。 | No |
| additionalCopyOptions | 追加のコピー オプション。キーと値のペアのディクショナリとして指定されます。 例 :MAX_FILE_SIZE、OVERWRITE。 詳細については、「Snowflake コピー オプション」を参照してください。 | No |
| additionalFormatOptions | キーと値のペアのディクショナリとして COPY コマンドに指定される、追加のファイル形式オプション。 例: DATE_FORMAT、TIME_FORMAT、TIMESTAMP_FORMAT、NULL_IF。 詳細については、「Snowflake 形式の種類のオプション」を参照してください。 NULL_IF を使用する場合、Snowflake の NULL 値は、ステージング ストレージ内の区切りテキスト ファイルに書き込むときに、指定された値 (単一引用符で囲む必要があります) に変換されます。 この指定された値は、ステージング ファイルからシンク ストレージに読み取るときに NULL として扱われます。 既定値は 'NULL' です。 |
No |
Note
次のコマンドを実行し、INFORMATION_SCHEMA スキーマと COLUMNS テーブルにアクセスするアクセス許可があることを確認します。
COPY INTO <location>
Snowflake から直接コピーする
シンク データ ストアと形式がこのセクションで説明されている条件を満たしている場合は、Copy アクティビティを使用して Snowflake からシンクに直接コピーできます。 サービスは設定をチェックし、次の条件が満たされていない場合、Copy アクティビティの実行に失敗します。
ソースに
storageIntegrationを指定する場合:シンク データ ストアは、Snowflake の外部ステージで参照したAzure Blob Storageです。 データをコピーする前に、次の手順を完了する必要があります。
サポートされているいずれかの種類の認証を使用して、シンク Azure Blob Storage 用の Azure Blob Storage リンク サービスを作成します。
少なくとも Storage Blob Data Contributor ロールをシンク先 Azure Blob Storage の Access Control (IAM) 内の Snowflake サービス プリンシパルに付与します。
ソースに
storageIntegrationを指定しない場合:シンクリンクサービスはAzure BLOB ストレージと共有アクセス署名認証で構成されています。 次のサポートされている形式でデータをAzure Data Lake Storage Gen2に直接コピーしたい場合は、Azure Data Lake Storage Gen2アカウントに対してSAS認証を利用するAzure Blob Storageのリンクされたサービスを作成することで、Snowflakeからの段階的コピーを回避できます。
シンク データ形式が、次のように構成された Parquet、区切りテキスト、または JSON です。
- Parquet 形式の場合は、圧縮コーデックが None、Snappy、または Lzo です。
-
区切りテキスト形式の場合:
-
rowDelimiterが \r\n または任意の 1 文字です。 -
compressionが、no compression、gzip、bzip2、または deflate です。 -
encodingNameが既定値のままか、utf-8 に設定されている。 -
quoteCharが、double quote、single quote、または empty string (引用符なし) です。
-
-
JSON 形式の場合、直接コピーでは、ソースの Snowflake テーブルまたはクエリ結果に 1 つの列しかなく、この列のデータ型が VARIANT、OBJECT、または ARRAY であるケースのみがサポートされます。
-
compressionが、no compression、gzip、bzip2、または deflate です。 -
encodingNameが既定値のままか、utf-8 に設定されている。 - コピー アクティビティのシンクでは、
filePatternは既定値のままにするか、setOfObjects に設定します。
-
Copy アクティビティのソース内で、
additionalColumnsが指定されていません。列マッピングが指定されていません。
Example:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Snowflakeからステージングされたコピー
前のセクションで説明したように、シンク データ ストアまたは形式が Snowflake COPY コマンドとネイティブに互換性がない場合は、中間Azure BLOB ストレージ インスタンスを使用して、組み込みのステージング コピーを有効にします。 ステージング コピー機能はスループットも優れています。 Snowflake のデータをステージング ストレージにエクスポートしてから、データをシンクにコピーし、最後にステージング ストレージの一時データをクリーンアップします。 ステージングを使用したデータのコピーの詳細は、「ステージング コピー」を参照してください。
この機能を使用するには、Azure ストレージ アカウントを中間ステージングとして参照する Azure Blob Storage のリンクされたサービス を作成します。 次に、Copy アクティビティで enableStaging プロパティと stagingSettings プロパティを指定します。
ソースで
storageIntegrationを指定する場合、Snowflakeの外部ステージで参照する、中間ステージングとしてのAzure Blob Storageを選択する必要があります。 Azure統合ランタイムを使用する場合は、サポートされている認証を使用してAzure Blob Storageリンクされたサービスを作成するか、セルフホステッド統合ランタイムを使用する場合は匿名のアカウント キー、共有アクセス署名、またはサービス プリンシパル認証を使用してください。 さらに、少なくとも Storage Blob Data Contributor ロールを Azure Blob Storage のステージング Access Control (IAM) の Snowflake サービス プリンシパルに付与します。ソースで
storageIntegrationを指定しない場合、Azure Blob Storageステージングのリンクされたサービスは、Snowflake COPYコマンドの要件に従って、共有アクセスシグニチャ認証を使用する必要があります。 ステージング Azure Blob Storageで Snowflake に適切なアクセス許可を付与していることを確認します。 この詳細については、こちらの記事を参照してください。
Example:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Snowflake からステージング コピーを実行するときは、シンク コピーの動作をファイルのマージに設定することが重要です。 この設定により、パーティション分割されたすべてのファイルが正しく処理およびマージされるため、最後にパーティション分割されたファイルのみがコピーされる問題を回避できます。
構成の例
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Note
シンク コピーの動作をファイルのマージに設定しないと、最後にパーティション分割されたファイルのみがコピーされる場合があります。
シンクとしての Snowflake
Snowflake コネクタは、Snowflake の COPY into [table] コマンドを利用して、最適なパフォーマンスを実現します。 Azureの Snowflake へのデータの書き込みをサポートしています。
ソース データ ストアと形式が Snowflake COPY コマンドでネイティブにサポートされている場合は、Copy アクティビティを使用してソースから Snowflake に直接コピーできます。 詳しくは、「Snowflake に直接コピーする」をご覧ください。 それ以外の場合は、組み込みのSnowflakeへのステージドコピーを使用します。
Snowflake にデータをコピーするには、Copy アクティビティ sink セクションで次のプロパティがサポートされています。
| Property | Description | Required |
|---|---|---|
| 型 | Copy アクティビティ シンクの type プロパティは、SnowflakeV2Sink として設定されます。 | Yes |
| preCopyScript | 各実行で Snowflake にデータを書き込む前に、実行するCopy アクティビティの SQL クエリを指定します。 前に読み込まれたデータをクリーンアップするには、このプロパティを使います。 | No |
| importSettings | Snowflake にデータを書き込むために使用される詳細設定。 COPY into コマンドでサポートされるものを構成することができ、ステートメントを呼び出す際にサービスが処理します。 | Yes |
importSettings の下: |
||
| 型 | インポート コマンドの type を SnowflakeImportCopyCommand に設定します。 | Yes |
| storageIntegration | Snowflake で作成したストレージ統合の名前を指定します。 ストレージ統合を使用するための前提となる手順については、「Snowflake ストレージ統合の構成」を参照してください。 | No |
| additionalCopyOptions | 追加のコピー オプション。キーと値のペアのディクショナリとして指定されます。 例: ON_ERROR、FORCE、LOAD_UNCERTAIN_FILES。 詳細については、「Snowflake コピー オプション」を参照してください。 | No |
| additionalFormatOptions | COPYコマンドに指定される追加のファイルフォーマットオプションは、キーと値のペアのディクショナリとして提供されます。 例 :DATE_FORMAT、TIME_FORMAT、TIMESTAMP_FORMAT。 詳細については、「Snowflake 形式の種類のオプション」を参照してください。 | No |
Note
次のコマンドを実行し、INFORMATION_SCHEMA スキーマと COLUMNS テーブルにアクセスするアクセス許可があることを確認します。
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Snowflake に直接コピーする
ソース データ ストアと形式がこのセクションで説明されている条件を満たしている場合は、Copy アクティビティを使用してソースから Snowflake に直接コピーできます。 サービスは設定をチェックし、次の条件が満たされていない場合、Copy アクティビティの実行に失敗します。
シンクに
storageIntegrationを指定する場合:ソース データ ストアは、Snowflake の外部ステージで参照したAzure Blob Storageです。 データをコピーする前に、次の手順を完了する必要があります。
サポートされているいずれかの種類の認証を使用して、ソース Azure Blob Storage 用の Azure Blob Storage リンク サービスを作成します。
少なくとも Storage Blob Data Reader ロールをソース Azure Blob Storage Access Control (IAM) の Snowflake サービス プリンシパルに付与します。
シンクに
storageIntegrationを指定しない場合:source のリンクされたサービスは、Azure blob storageと共有アクセス署名認証です。 Azure Data Lake Storage Gen2からサポートされている次の形式でデータを直接コピーしたい場合、Azure Data Lake Storage Gen2アカウントに対してSAS認証を使用してAzure Blob Storageのリンクサービスを作成し、Snowflakeへのステージングコピーを避けることができます。
ソース データ形式が、次のように構成された Parquet、区切りテキスト、または JSON です。
Parquet 形式の場合は、圧縮コーデックが None またはSnappyです。
区切りテキスト形式の場合:
-
rowDelimiterが \r\n または任意の 1 文字です。 行区切り記号が “\r\n” ではない場合は、firstRowAsHeaderを false にする必要があり、skipLineCountが指定されていません。 -
compressionが、no compression、gzip、bzip2、または deflate です。 -
encodingNameが既定値のままになっているか、"UTF-8"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB18030"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255" に設定されています。 -
quoteCharが、double quote、single quote、または empty string (引用符なし) です。
-
JSON 形式の場合、直接コピーでは、シンクの Snowflake テーブルに 1 つの列しかなく、この列のデータ型が VARIANT、OBJECT、または ARRAY であるケースのみがサポートされます。
-
compressionが、no compression、gzip、bzip2、または deflate です。 -
encodingNameが既定値のままか、utf-8 に設定されている。 - 列マッピングが指定されていません。
-
Copy アクティビティ ソースで次の手順を実行します。
-
additionalColumnsが指定されていません。 - ソースがフォルダーの場合、
recursiveが true に設定されています。 -
prefix、modifiedDateTimeStart、modifiedDateTimeEnd、およびenablePartitionDiscoveryが指定されていない。
-
Example:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Snowflake へのステージング コピー
前のセクションで説明したように、ソース データ ストアまたは形式が Snowflake COPY コマンドとネイティブに互換性がない場合は、中間Azure BLOB ストレージ インスタンスを使用して組み込みのステージング コピーを有効にします。 ステージング コピー機能はスループットも優れています。 Snowflake のデータ形式要件を満たすようにデータを自動的に変換します。 次に、COPY コマンドを呼び出して、Snowflake にデータを読み込みます。 最後に、BLOB ストレージから一時データをクリーンアップします。 ステージングを使用したデータのコピーの詳細は、「ステージング コピー」を参照してください。
この機能を使用するには、Azure ストレージ アカウントを中間ステージングとして参照する Azure Blob Storage のリンクされたサービス を作成します。 次に、Copy アクティビティで enableStaging プロパティと stagingSettings プロパティを指定します。
シンクで
storageIntegrationを指定する場合、その中間ステージング用の Azure Blob Storage は、Snowflake の外部ステージで参照したものと同じである必要があります。 Azure統合ランタイムを使用する場合は、サポートされている認証を使用してAzure Blob Storageリンクされたサービスを作成するか、セルフホステッド統合ランタイムを使用する場合は匿名のアカウント キー、共有アクセス署名、またはサービス プリンシパル認証を使用してください。 さらに、Azure Blob Storage のステージングの Storage Blob データ リーダー ロールを、Access Control (IAM) の Snowflake サービス プリンシパルに少なくとも付与します。シンクで
storageIntegrationを指定しない場合、リンクされたサービス Azure Blob Storage のステージングでは、Snowflake COPY コマンドに必要な Shared Access Signature 認証を使用する必要があります。
Example:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
マッピングデータフローのプロパティ
マッピング データ フローでデータを変換する場合、Snowflake のテーブルから読み書きすることができます。 詳細については、マッピング データ フローのソース変換とシンク変換に関する記事をご覧ください。 ソースとシンクの種類として、Snowflake データセットまたはインライン データセットを使用することができます。
ソース変換
次の表に、Snowflake ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。コネクタは、Snowflake 内部データ転送を利用します。
| Name | Description | Required | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| Table | 入力として [テーブル] を選択した場合、データ フローは、Snowflake データセットで指定された、またはインライン データセットを使用するときにソース オプションで指定されたテーブルからすべてのデータをフェッチします。 | No | String |
(インライン データセットのみ) tableName schemaName |
| Query | 入力として [クエリ] を選択した場合は、Snowflake からデータをフェッチするクエリを入力します。 この設定により、データセットで選択したすべてのテーブルがオーバーライドされます。 スキーマ、テーブル、および列の名前に小文字が含まれている場合は、クエリでオブジェクト識別子を引用符で囲みます (例: select * from "schema"."myTable")。 |
No | String | クエリ |
| 増分抽出を有効にする (プレビュー) | このオプションを使用して、パイプラインが前回実行されてから変更された行のみを処理するように ADF に指示します。 | No | ブール値 | enableCdc |
| 増分列 | 増分抽出機能を使用する場合は、ソース テーブルのウォーターマークとして使用する日時または数値列を選択する必要があります。 | No | String | waterMarkColumn |
| Snowflake の変更追跡を有効にする (プレビュー) | このオプションを使用すると、ADF が Snowflake 変更データ キャプチャ テクノロジを利用して、前回のパイプライン実行以降の差分データのみを処理できるようになります。 このオプションは、増分列を必要とせずに、行の挿入、更新、削除の操作による差分データを自動的に読み込みます。 | No | ブール値 | enableNativeCdc |
| 純変化 | Snowflake の変更追跡を使用する場合は、このオプションを使用して、重複除去された変更行または完全な変更を取得できます。 重複除去された変更行には、特定の時点以降に変更された行の最新バージョンのみが表示されますが、完全な変更では、削除または更新された行を含め、変更された各行のすべてのバージョンが表示されます。 たとえば、行を更新すると、完全な変更では削除バージョンと挿入バージョンが表示されますが、重複除去された変更行では挿入バージョンのみが表示されます。 ユース ケースに応じて、自分のニーズに合ったオプションを選択できます。 既定のオプションは false です。これは、完全な変更を意味します。 | No | ブール値 | netChanges |
| システム列を含める | Snowflake の変更追跡を使用するときに、systemColumns オプションを使用して、Snowflake によって提供されるメタデータ ストリーム列を変更追跡の出力に含めるか除外するかを制御できます。 既定では、systemColumns は true に設定されています。つまり、メタデータ ストリーム列が含まれます。 除外する場合は、systemColumns を false に設定できます。 | No | ブール値 | systemColumns |
| 最初から読み取りを開始する | 増分抽出と変更追跡でこのオプションを設定すると、増分抽出が有効になっているパイプラインの最初の実行時にすべての行を読み取るよう ADF に指示します。 | No | ブール値 | skipInitialLoad |
Snowflake のソース スクリプトの例
ソースの種類として Snowflake データセットを使用すると、関連付けられているデータ フロー スクリプトは次のようになります。
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
インライン データセットを使用する場合、関連付けられているデータ フロー スクリプトは次のようになります。
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
ネイティブの変更追跡
Azure Data Factoryでは、変更の追跡と呼ばれる Snowflake のネイティブ機能がサポートされるようになりました。これには、ログの形式での変更の追跡が含まれます。 Snowflake のこの機能を使用すると、時間の経過に伴うデータの変更を追跡できるため、増分データの読み込みと監査に役立ちます。 この機能を利用するために、変更データ キャプチャを有効にして Snowflake の変更追跡を選択すると、ソース テーブルの Stream オブジェクトが作成され、ソースの Snowflake テーブルでの変更追跡が可能になります。 その後、クエリを使って CHANGES 句を使用し、ソーステーブルから新規の、または更新されたデータのみを取得します。 また、Snowflake のソース テーブルに設定されたデータ保持時間の間隔内に変更が消費されるようにパイプラインをスケジュールすることもお勧めします。そうしなければ、キャプチャされた変更の動作に一貫性がなくなる可能性があります。
シンク変換
次の表に、Snowflake シンクでサポートされるプロパティの一覧を示します。 これらのプロパティは、[設定] タブで編集できます。インライン データセットを使用する場合、「データセットのプロパティ」セクションで説明されているプロパティと同じ追加の設定が表示されます。 コネクタは、Snowflake 内部データ転送を利用します。
| Name | Description | Required | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| 更新方法 | 対象となる Snowflake に対して許可される操作を指定します。 行を更新、アップサート、または削除するには、それらのアクションに対して行をタグ付けするために行の変更変換が必要になります。 |
Yes |
true または false |
deletable insertable updateable upsertable |
| [キー列] | 更新、アップサート、削除の場合、1 つまたは複数のキー列を設定して、変更する行を決定する必要があります。 | No | Array | keys |
| テーブル アクション | 書き込み前に変換先テーブルのすべての行を再作成するか削除するかを指定します。 - なし: テーブルに対してアクションは実行されません。 - Recreate:テーブルが削除され、再作成されます。 新しいテーブルを動的に作成する場合に必要です。 - Truncate:ターゲット テーブルのすべての行が削除されます。 |
No |
true または false |
recreate 切り詰める |
Snowflake シンク スクリプトの例
シンクの種類として Snowflake データセットを使用する際、関連付けられているデータ フロー スクリプトは次のようになります。
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
インライン データセットを使用する場合、関連付けられているデータ フロー スクリプトは次のようになります。
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
クエリ プッシュダウンの最適化
パイプライン ログ レベルを None に設定することで、中間変換メトリックの送信を除外して Spark 最適化に対する潜在的な障害を防ぎ、Snowflake によって提供されるクエリ プッシュダウンの最適化を有効にします。 このプッシュダウンの最適化により、大量のデータセットを含む大規模な Snowflake テーブルのパフォーマンスが大幅に向上します。
Note
一時テーブルはセッションに対してローカルであり、作成したユーザーが他のセッションにアクセスすることができなくなり、Snowflake によって通常のテーブルとして上書きされる傾向があるため、Snowflake ではサポートされていません。 Snowflake はグローバルにアクセス可能な、一時的なテーブルを代替として提供しますが、これには手動削除が必要になるため、ソース スキーマでの削除操作を回避するという一時テーブルの使用の主目的とは矛盾しています。
Snowflake V2 のデータ型マッピング
Snowflake からデータをコピーする場合、Snowflake データ型からサービス内の中間データ型への次のマッピングが内部的に使用されます。 コピー アクティビティでソースのスキーマとデータ型がシンクにマッピングされるしくみについては、スキーマとデータ型のマッピングに関する記事を参照してください。
| Snowflake のデータ型 | サービスの中間データ型 |
|---|---|
| NUMBER (p,0) | Decimal |
| NUMBER (p, s ここで s>0) | Decimal |
| FLOAT | Double |
| VARCHAR | String |
| CHAR | String |
| BINARY | Byte[] |
| BOOLEAN | ブール値 |
| DATE | DateTime |
| TIME | TimeSpan |
| TIMESTAMP_LTZ | DateTimeOffset |
| TIMESTAMP_NTZ | DateTimeOffset |
| TIMESTAMP_TZ | DateTimeOffset |
| VARIANT | String |
| OBJECT | String |
| ARRAY | String |
Lookup アクティビティのプロパティ
プロパティの詳細については、ルックアップ アクティビティに関する記事を参照してください。
Snowflake コネクタのライフサイクルとアップグレード
次の表は、Snowflake コネクタのさまざまなバージョンのリリース ステージと変更ログを示しています。
| Version | リリース ステージ | ログの変更 |
|---|---|---|
| Snowflake V1 | Removed | 適用されません。 |
| Snowflake V2 (バージョン 1.0) | GA バージョンあり | • キー ペア認証のサポートを追加します。 • Copy アクティビティで storageIntegration のサポートを追加します。 • accountIdentifier、 warehouse、 database、 schema 、 role のプロパティは、 connectionstring プロパティの代わりに接続を確立するために使用されます。• 検索アクティビティで Decimal のサポートを追加します。 Snowflake で定義されている NUMBER 型は、検索アクティビティで文字列として表示されます。 V2 で数値型に変換する場合は、 int 関数 または float 関数でパイプライン パラメーターを使用できます。 たとえば、 int(activity('lookup').output.firstRow.VALUE)、float(activity('lookup').output.firstRow.VALUE) など• Snowflake のタイムスタンプ データ型は、Lookup および Script アクティビティで DateTimeOffset データ型として読み取られます。 V2 にアップグレードした後も、パイプラインで Datetime 値をパラメーターとして使用する必要がある場合は、 formatDateTime 関数 (推奨) または concat 関数を使用して DateTimeOffset 型を DateTime 型に変換できます。 例: formatDateTime(activity('lookup').output.firstRow.DATETIMETYPE)、concat(substring(activity('lookup').output.firstRow.DATETIMETYPE, 0, 19), 'Z') • NUMBER (p,0) は 10 進データ型として読み取られます。 • TIMESTAMP_LTZ、TIMESTAMP_NTZ、およびTIMESTAMP_TZは DateTimeOffset データ型として読み取られます。 • スクリプト のパラメーターは、スクリプト アクティビティではサポートされていません。 代わりに、動的な式をスクリプト パラメーターに使用します。 詳細については、「 • スクリプト アクティビティでの複数の SQL ステートメントの実行はサポートされていません。 |
| Snowflake V2 (バージョン 1.1) | GA バージョンあり | • スクリプト パラメーターのサポートを追加します。 • スクリプト アクティビティでの複数のステートメント実行のサポートを追加します。 • ルックアップおよびスクリプト アクティビティ treatDecimalAsString プロパティを追加します。 • 接続プロパティ UseUtcTimestampsを追加します。 |
Snowflake コネクタを V1 から V2 にアップグレードする
Snowflake コネクタを V1 から V2 にアップグレードするには、サイド バイ サイド アップグレードまたはインプレース アップグレードを実行します。
サイド バイ サイド アップグレード
サイド バイ サイド アップグレードを実行するには、以下の手順を実行します。
- 新しい Snowflake リンク サービスを作成し、V2 リンク サービスのプロパティを参照して構成します。
- 新しく作成した Snowflake のリンク サービスに基づいてデータセットを作成します。
- V1 オブジェクトをターゲットとするパイプライン内の既存のリンク サービスとデータセットを、新しいものに置き換えます。
一括アップグレード
インプレース アップグレードを実行するには、既存のリンク サービス ペイロードを編集し、新しいリンク サービスを使用するようにデータ セットを更新する必要があります。
type を Snowflake から SnowflakeV2 に更新します。
リンク サービス ペイロードを V1 形式から V2 に変更します。 上記の type を変更した後、ユーザー インターフェイスから各フィールドに入力するか、JSON エディターを通じてペイロードを直接更新することができます。 サポートされている接続プロパティについては、この記事の「リンク サービスのプロパティ」セクションを参照してください。 次の例は、V1 と V2 Snowflake のリンク サービスのペイロードの違いを示しています:
Snowflake V1 接続サービスのJSONペイロード:
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Snowflake V2 のリンク サービス JSON ペイロード:
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }新しいリンク サービスを使用するようにデータセットを更新します。 新しく作成されたリンク サービスに基づいて新しいデータセットを作成するか、既存のデータセットの type プロパティを SnowflakeTable から SnowflakeV2Table に更新することができます。
Note
リンクされたサービスを切り替えるとき、オーバーライド テンプレート パラメーター セクションにはデータベース プロパティのみが表示される場合があります。 これを解決するには、パラメーターを手動で編集します。 その後、[ テンプレート パラメーターのオーバーライド ] セクションに接続文字列が表示されます。
Snowflake V2 コネクタをバージョン 1.0 からバージョン 1.1 にアップグレードする
[ リンクされたサービスの編集] ページで、バージョンとして 1.1 を選択します。 詳細については、「リンク サービスのプロパティ」を参照してください。
関連コンテンツ
Copy アクティビティによってソースとシンクとしてサポートされるデータ ストアの一覧については、「サポートされているデータ ストアと形式を参照してください。