適用対象:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory には、オンプレミスの Netezza サーバーから Azure のストレージ アカウントまたは Azure Synapse Analytics データベースに大量のデータを移行することができる、パフォーマンスと信頼性が高くコスト効率に優れたメカニズムが用意されています。
この記事では、データ エンジニアと開発者向けに次の情報を提供します。
- パフォーマンス
- 回復性のコピー
- ネットワークのセキュリティ
- 概要ソリューション アーキテクチャ
- 実装のベスト プラクティス
パフォーマンス
Azure Data Factory は、さまざまなレベルで並列処理を可能にするサーバーレス アーキテクチャを提供します。 開発者は、パイプラインを構築することでネットワークとデータベースの両方の帯域幅を余すことなく使用し、環境内でのデータ移動のスループットを最大化することができます。
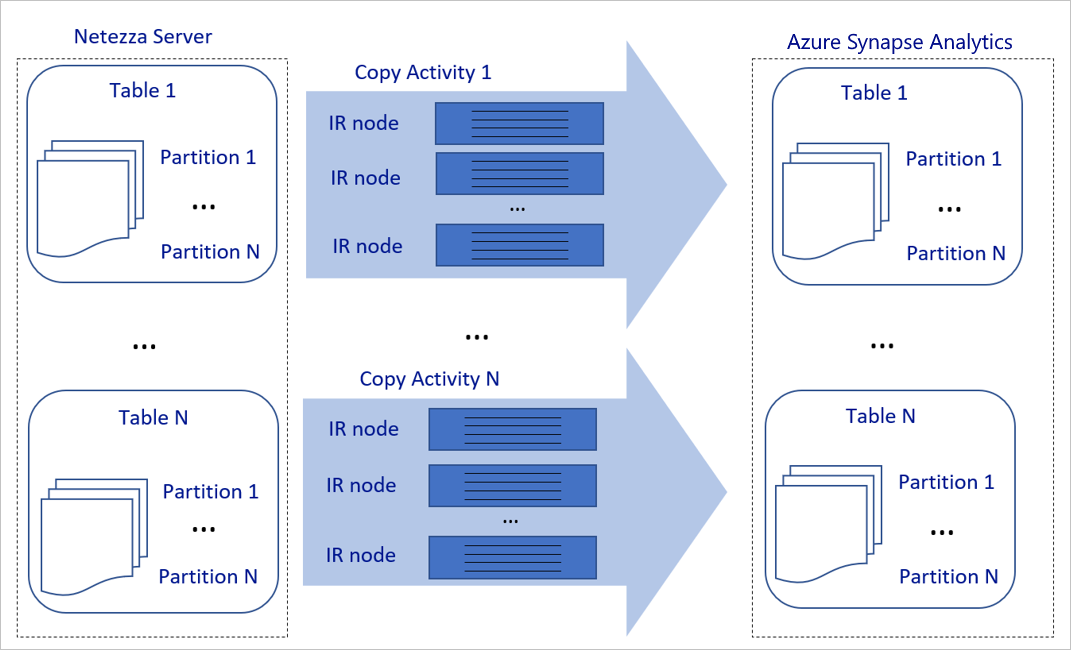
上の図は、次のように解釈できます。
1 回のコピー アクティビティで、スケーラブルなコンピューティング リソースを利用できます。 Azure Integration Runtime を使用する場合は、各コピー アクティビティに対して最大 256 DIU をサーバーレス方式で指定できます。 セルフホステッド統合ランタイム (セルフホステッド IR) では、マシンを手動でスケールアップしたり、複数のマシン (最大 4 台のノード) にスケールアウトしたりすることができます。また、1 回のコピー アクティビティにより、すべてのノードでアクティビティがパーティションを配布されます。
1 回のコピー アクティビティで、複数のスレッドを使用したデータ ストアの読み取りと書き込みが行われます。
Azure Data Factory 制御フローでは、複数のコピー アクティビティを並列して開始できます。 たとえば、For Each ループを使用して開始できます。
詳細については、コピー アクティビティのパフォーマンスとスケーラビリティに関するガイドを参照してください。
回復力
Azure Data Factory には組み込みの再試行メカニズムがあるため、1 回のコピー アクティビティの実行で、データ ストアまたは基になるネットワークの特定のレベルの一時的なエラーを処理できます。
Azure Data Factory のコピー アクティビティでは、ソースとシンク データ ストアの間でデータをコピーする場合、2 つの方法で互換性のない行を取り扱うことができます。 コピー アクティビティを中止して失敗とするか、互換性のないデータ行をスキップして残りのデータのコピーを続行できます。 さらに、エラーの原因を把握するために互換性のない行を Azure BLOB ストレージまたは Azure Data Lake Store のログに記録し、データ ソースのデータを修正してから、コピーアクティビティを再試行できます。
ネットワークのセキュリティ
既定では、Azure Data Factory は、ハイパーテキスト転送プロトコル セキュア (HTTPS) プロトコル経由の暗号化された接続を使用して、オンプレミスの Netezza サーバーから Azure ストレージ アカウントまたは Azure Synapse Analytics データベースにデータを転送します。 HTTPS によって転送中のデータが暗号化され、盗聴や中間者攻撃が防止されます。
また、パブリック インターネット経由でデータを転送しない場合は、Azure ExpressRoute を介してプライベート ピアリング リンク経由でデータを転送することで、より高いセキュリティを実現できます。
次のセクションでは、より強固なセキュリティを実現する方法について説明します。
ソリューションのアーキテクチャ
このセクションでは、データを移行する 2 つの方法について説明します。
パブリック インターネット経由でデータを移行する
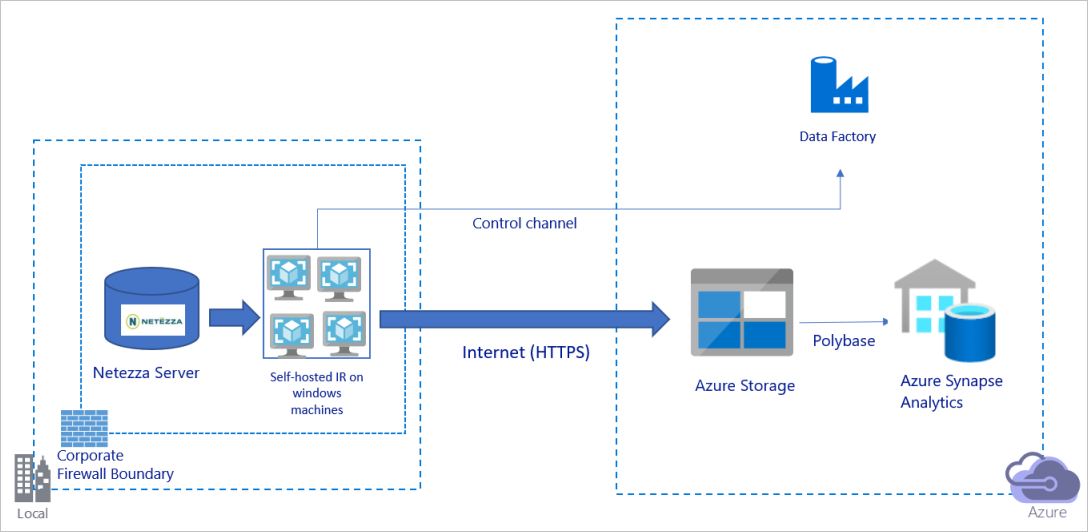
上の図は、次のように解釈できます。
このアーキテクチャでは、パブリック インターネット経由で HTTPS を使用してデータを安全に転送します。
このアーキテクチャを実現するには、企業ファイアウォールの内側にある Windows マシンに、Azure Data Factory 統合ランタイム (セルフホステッド) をインストールする必要があります。 この統合ランタイムから Netezza サーバーに直接アクセスできることを確認します。 ネットワークとデータ ストアの帯域幅を完全に活用してデータをコピーするには、マシンを手動でスケールアップするか、複数のマシンにスケールアウトします。
このアーキテクチャを使用すると、初期スナップショット データと差分データの両方を移行できます。
プライベート ネットワーク経由でデータを移行する
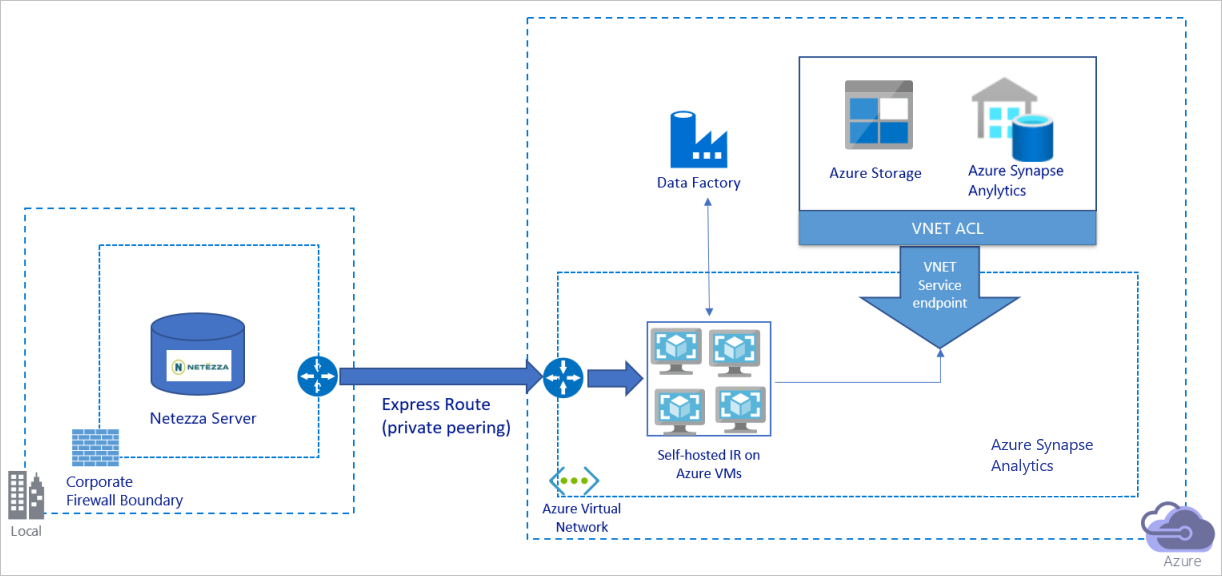
上の図は、次のように解釈できます。
このアーキテクチャでは、データの移行は Azure ExpressRoute を介してプライベート ピアリング リンク経由で行われ、データがパブリック インターネット経由で転送されることはありません。
このアーキテクチャを実現するには、Azure 仮想ネットワーク内の Windows 仮想マシン (VM) に Azure Data Factory 統合ランタイム (セルフホステッド) をインストールする必要があります。 ネットワークとデータ ストアの帯域幅を完全に活用してデータをコピーするには、VM を手動でスケールアップするか、複数の VM にスケールアウトします。
このアーキテクチャを使用すると、初期スナップショット データと差分データの両方を移行できます。
ベスト プラクティスを実装する
認証情報と資格情報の管理
Netezza に対して認証を行うために、接続文字列を介した ODBC 認証を使用できます。
Azure BLOB ストレージに対して認証するには:
Azure リソースのマネージド ID を使用することを強くお勧めします。 マネージド ID は Microsoft Entra ID で自動的に管理される Azure Data Factory ID をベースに構築されており、リンクされたサービス定義で資格情報を指定せずにパイプラインを構成できます。
また、サービス プリンシパル、共有アクセス署名、またはストレージ アカウント キーを使用して Azure BLOB ストレージに対する認証を行うこともできます。
Data Lake Storage Gen2 に対して認証するには:
Azure リソースのマネージド ID を使用することを強くお勧めします。
また、サービス プリンシパルまたはストレージ アカウント キーを使用することもできます。
Azure Synapse Analytics に対して認証するには:
Azure リソースのマネージド ID を使用することを強くお勧めします。
また、サービス プリンシパルまたは SQL 認証を使用することもできます。
Azure リソースのマネージド ID を使用しない場合は、簡単にするために、Azure Key Vault に資格情報を格納して、Azure Data Factory のリンクされたサービスを変更せずに、キーを一元的に管理およびローテーションすることを強くお勧めします。 これは、CI/CD のベスト プラクティスの1 つでもあります。
初回のスナップショット データ移行
小さいテーブル (ボリューム サイズが 100 GB より小さい、または 2 時間以内に Azure に移行できる) の場合は、各コピー ジョブでテーブルごとにデータを読み込むよう設定できます。 スループットを向上させるには、複数の Azure Data Factory コピー ジョブを実行して、異なるテーブルを同時に読み込むことができます。
各コピー ジョブ内では、並列クエリを実行してデータをパーティションでコピーするには、以下のいずれかのデータ パーティションのオプションでparallelCopiesプロパティ設定を使用することで、ある程度の水準の並列処理を達成することもできます。
効率を高めるために、データ スライスから始めることをお勧めします。
parallelCopies設定の値が、Netezza サーバー上のテーブル内のデータ スライス パーティションの合計数より小さいことを確認します。各データ スライス パーティションのボリューム サイズが依然として大きい場合 (たとえば、10 GB を超える場合) は、動的範囲パーティションに切り替えることをお勧めします。 このオプションを使用すると、パーティションの数と各パーティションのパーティション列ごとのボリュームのサイズやその上限と下限を柔軟に定義できます。
大きなテーブル (つまり、ボリューム サイズが 100 GB より大きい、または 2 時間以内に Azure に移行できないテーブル) では、データをカスタム クエリを使用してパーティション分割し、各コピー ジョブでパーティションを 1 つづつコピーすることをお勧めします。 スループットを向上させるには、複数の Azure Data Factory コピー ジョブを同時に実行することができます。 カスタム クエリにより各コピー ジョブで 1 つのパーティションを読み込むよう設定している場合でも、データ スライスまたは動的範囲を介して並列処理を有効にすることで、スループットを向上させることができます。
ネットワークまたはデータ ストアの一時的な問題によってコピー ジョブが失敗した場合は、失敗したコピー ジョブを再実行して、そのテーブルから特定のパーティションを再度読み込むことができます。 読み込むパーティションが異なるその他のコピー ジョブは影響を受けません。
Azure Synapse Analytics データベースにデータを読み込む際は、Azure BLOB ストレージをステージングとして、コピー ジョブ内で PolyBase を有効にすることをお勧めします。
差分データの移行
テーブルから新規の行または更新された行を識別するには、スキーマのタイムスタンプ列か増分キーを使用します。 その後、最新の値を高基準値として外部テーブルに格納し、次にデータを読み込むときにその値を使用して差分データをフィルター処理できます。
テーブルごとに異なる基準値列を使用して、新しい行や更新された行を識別できます。 Microsoft では、外部制御テーブルを作成することをお勧めします。 このテーブルで、各行は特定の基準値列名と高基準値を持つ Netezza サーバー上の 1 つのテーブルを表します。
セルフホステッド統合ランタイムを構成する
Netezza サーバーから Azure にデータを移行する場合、サーバーが企業ファイアウォールの内側にあるか仮想ネットワーク環境内にあるかに関係なく、データを移動するエンジンとして、セルフホステッド IR を Windows マシンまたは VM にインストール必要があります。 セルフホステッド IR をインストールする際は、次のアプローチをお勧めします。
各 Windows マシンまたは VM で、32 vCPU と 128 GB のメモリの構成を開始します。 データ移行中に IR マシンの CPU とメモリの使用状況を監視して、パフォーマンスを向上させるためにマシンをさらにスケールアップする必要があるか、コストを節約するためにマシンをスケールダウンする必要があるかを確認できます。
また、1 つのセルフホステッド IR に最大 4 つのノードを関連付けてスケールアウトすることもできます。 セルフホステッド IR に対して実行される 1 回のコピー ジョブで、すべての VM ノードが自動的に適用されてデータが並列してコピーされます。 高可用性を実現するには、データ移行中の単一障害点を回避するために、2 台の VM ノードから始めます。
パーティションを制限する
ベスト プラクティスとして、代表的なサンプル データセットを使用してパフォーマンスの概念実証 (POC) を実施し、各コピー アクティビティにおける適切なパーティションのサイズを決定できるようにします。 2 時間以内に各パーティションを Azure に読み込むことをお勧めします。
テーブルをコピーするには、まず 1 台のセルフホステッド IR マシンで 1 回のコピー アクティビティを行います。 テーブル内のデータ スライス パーティションの数に基づいて parallelCopies 設定を徐々に増やします。 コピー ジョブのスループットに基づき、Azure にテーブル全体を 2 時間以内に読み込むことができるかどうかを確認します。
Azure にテーブルを 2 時間以内に読み込むことができず、かつセルフホステッド IR ノードとデータ ストアの容量が完全に使用されていない場合は、ネットワークの制限またはデータ ストアの帯域幅制限に達するまで、同時コピー アクティビティの数を徐々に増やします。
引き続きセルフホステッド IR マシンの CPU およびメモリ使用率を監視し、CPU およびメモリが完全に使用されていることが確認されたときに、マシンをスケールアップするか複数のコンピューターにスケールアウトできるよう準備しておきます。
Azure Data Factory のコピー アクティビティによって報告された調整エラーが発生した場合は、Azure Data Factory の同時実行数または parallelCopies の設定値を減らすか、ネットワークとデータ ストアの帯域幅または 1 秒あたりの最大 I/O 操作 (IOPS) の制限値を大きくすることを検討してください。
価格のお見積り
オンプレミスの Netezza サーバーから Azure Synapse Analytics データベースにデータを移行するために構築されている、次のパイプラインについて検討します。
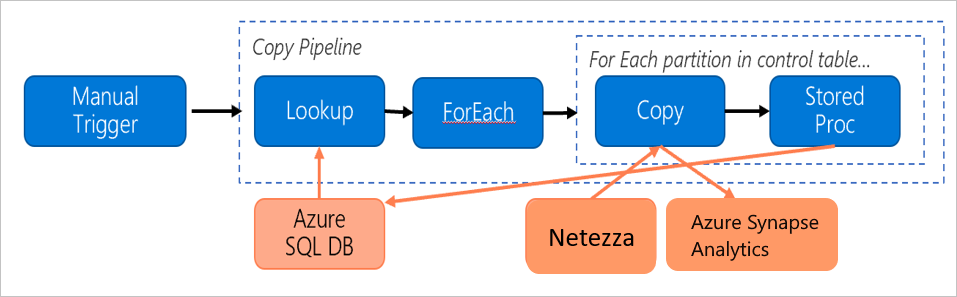
以下のことがわかると仮定します。
データ ボリュームの合計は 50 テラバイト (TB)。
最初のソリューション アーキテクチャを使用してデータを移行する (Netezza サーバーはファイアウォールの内側に設置されている)。
50 TB 分のデータ ボリュームが 500 のパーティションに分割され、各コピー アクティビティで 1 つのパーティションが移行される。
各コピー アクティビティは 4 台のマシンに対して 1 つのセルフホステッド IR を使用して構成され、20 メガバイト/秒 (Mbps) のスループットを実現する。 (コピー アクティビティ内では、
parallelCopiesが 4 に設定され、テーブルからデータを読み込む各スレッドが 5 MBps のスループットを実現する)。ForEach の同時実行数は 3 に設定され、合計スループットは 60 MBps である。
合計では、移行が完了するまでに 243 時間かかる。
上記の前提条件に基づき、見積もり価格は次のようになります。
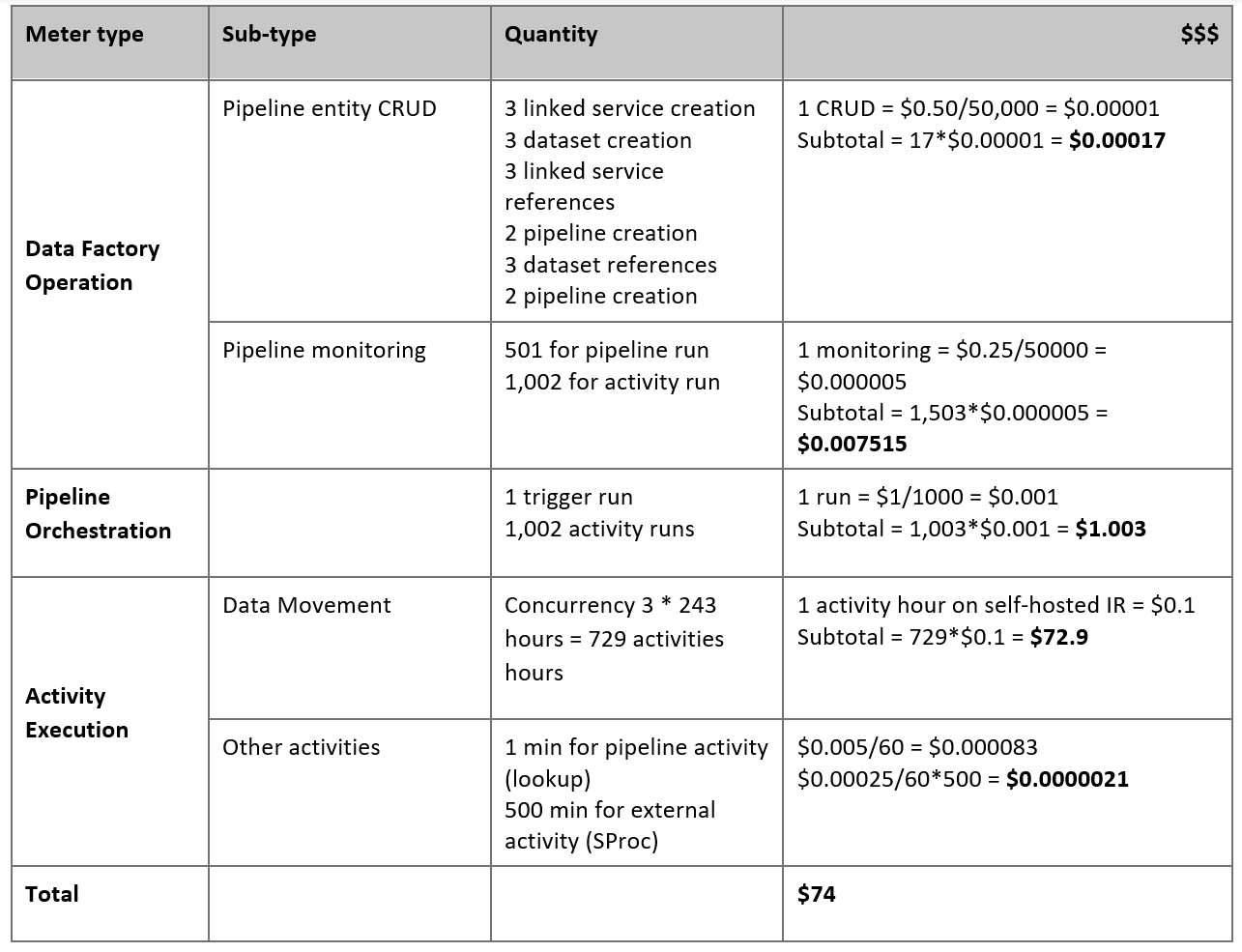
Note
上記の価格は仮定です。 実際の料金は、環境の実際のスループットによって変わります。 (セルフホステッド IR がインストールされている) Windows マシンの料金は含まれていません。
その他のリファレンス
詳細については、次の記事とガイドを参照してください。
- Netezza コネクタ
- ODBC コネクタ
- Azure BLOB ストレージ コネクタ
- Azure Data Lake Storage Gen2 コネクタ
- Azure Synapse Analytics コネクタ
- コピー アクティビティのパフォーマンスとチューニングに関するガイド
- セルフホステッド統合ランタイムを作成して構成する
- セルフホステッド統合ランタイム HA とスケーラビリティ
- データ移動のセキュリティに関する考慮事項
- Azure Key Vault への資格情報の格納
- 1 つのテーブルからデータを増分コピーする
- 複数のテーブルからデータを増分コピーする
- Azure Data Factory の価格ページ