適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory と Azure Synapse パイプラインの Copy アクティビティを使用して、Azure Blob Storage 間でデータをコピーする方法について説明します。 Data Flow アクティビティを使用して Azure Blob Storage 内のデータを変換する方法についても説明します。 詳細については、Azure Data Factory および Azure Synapse Analytics の概要記事を参照してください。
ヒント
データ レイクまたはデータ ウェアハウスの移行シナリオについては、データ レイクまたはデータ ウェアハウスから Azure にデータを移行することに関するページを参照してください。
サポートされる機能
この Azure Blob Storage コネクタは、次の機能でサポートされます。
| サポートされる機能 | IR | マネージド プライベート エンドポイント |
|---|---|---|
| Copy アクティビティ (ソース/シンク) | ① ② | ✓ ストレージ アカウント V1 を除く |
| マッピング データ フロー (ソース/シンク) | ① | ✓ ストレージ アカウント V1 を除く |
| Lookup アクティビティ | ① ② | ✓ ストレージ アカウント V1 を除く |
| GetMetadata アクティビティ | ① ② | ✓ ストレージ アカウント V1 を除く |
| アクティビティを削除する | ① ② | ✓ ストレージ アカウント V1 を除く |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
コピー アクティビティの場合、この BLOB ストレージ コネクタは、以下をサポートします。
- 汎用 Azure Storage アカウントとホット/クール Blob Storage との間での BLOB のコピー。
- アカウント キー、サービスの Shared Access Signature (SAS)、サービス プリンシパル、Azure リソースのマネージド ID のいずれかの認証を使用した BLOB のコピー。
- ブロック BLOB、アペンド BLOB、またはページ BLOB からの BLOB のコピーと、ブロック BLOB だけへのデータのコピー。
- そのままの BLOB のコピー、またはサポートされているファイル形式と圧縮コーデックを使用した BLOB の解析/生成。
- コピー中のファイル メタデータの保持。
はじめに
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して Azure Blob Storage のリンク サービスを作成する
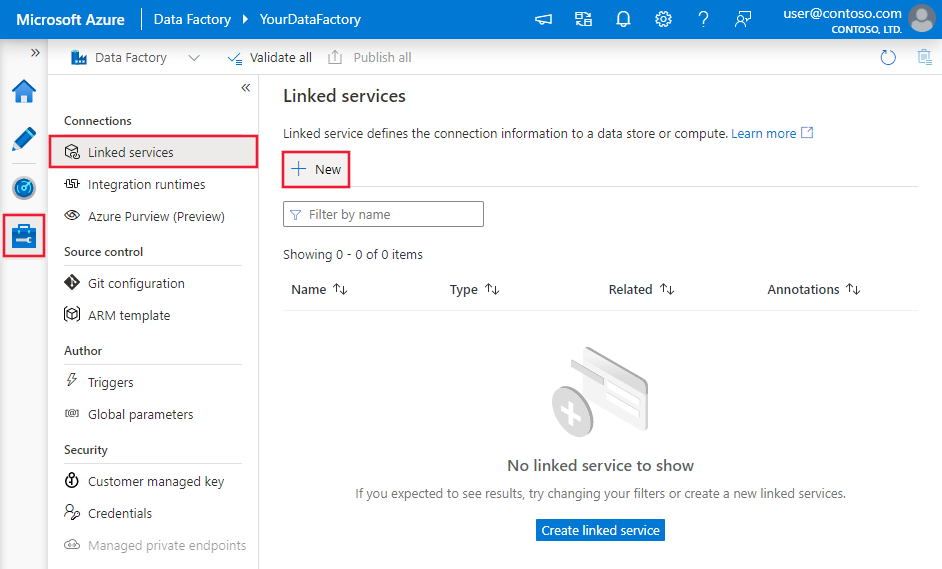
Azure portal UI で、以下の手順を使用して Azure Blob Storage のリンク サービスを作成します。
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンク サービス] を選択して、[新規] を選択します。
BLOB を検索して、Azure Blob Storage コネクタを選択します。
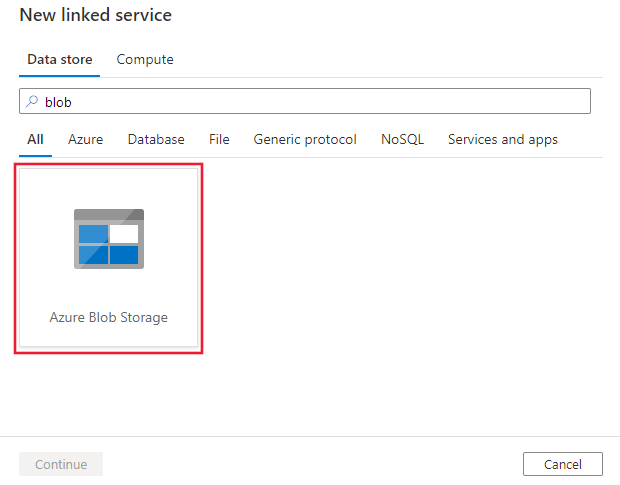
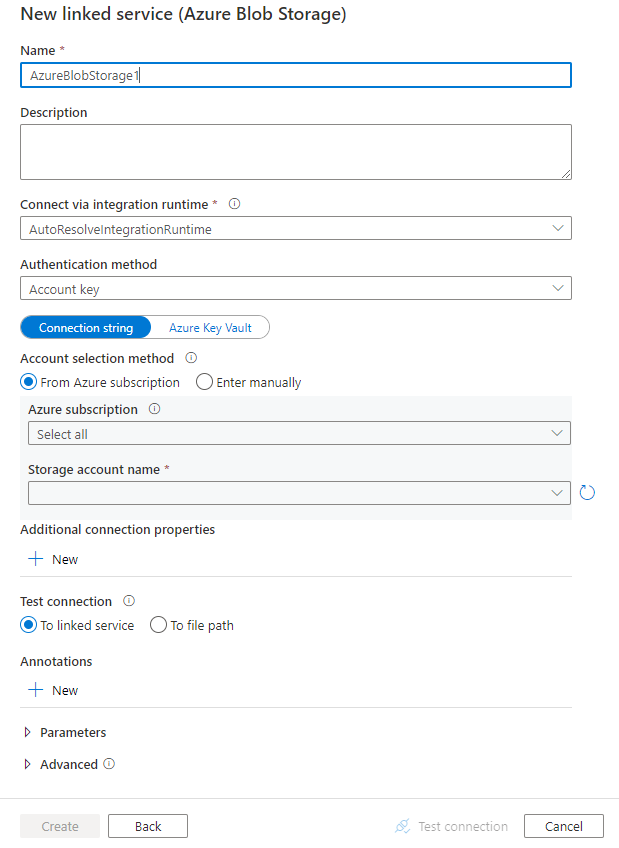
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
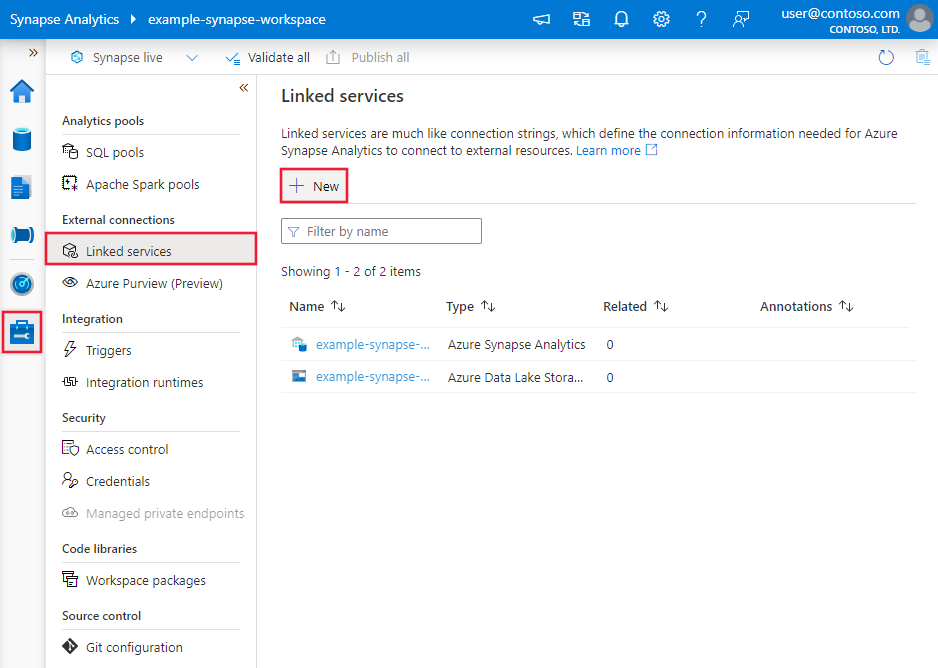
コネクタの構成の詳細
以下のセクションでは、BLOB ストレージに固有の Data Factory および Synapse パイプライン エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
この BLOB ストレージ コネクタでは、次の認証の種類がサポートされています。 詳細については、対応するセクションをご覧ください。
注意
- Azure Storage ファイアウォールで有効にした [信頼された Microsoft サービスによるこのストレージ アカウントに対するアクセスを許可します] オプションを利用することで、パブリック Azure 統合ランタイムを使用して BLOB ストレージに接続する場合は、マネージド ID 認証を使用する必要があります。 Azure Storage ファイアウォール設定の詳細については、「Azure Storage ファイアウォールおよび仮想ネットワークを構成する」を参照してください。
- PolyBase または COPY ステートメントを使用して Azure Synapse Analytics にデータを読み込むときに、ソースまたはステージング BLOB ストレージが Azure Virtual Network エンドポイントで構成されている場合は、Azure Synapse の要求に従ってマネージド ID 認証を使用する必要があります。 構成の前提条件の詳細については、「マネージド ID の認証」を参照してください。
注意
Azure HDInsight および Azure Machine Learning のアクティビティは、Azure Blob Storage アカウント キーを使用する認証のみをサポートしています。
匿名認証
以下のプロパティは、Azure Data Factory または Synapse パイプラインのストレージ アカウント キー認証でサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureBlobStorage (推奨) または AzureStorage (下記の注を参照) に設定する必要があります。 |
はい |
| containerUri | 形式 https://<AccountName>.blob.core.windows.net/<ContainerName> を使用して匿名読み取りアクセスを有効にした Azure BLOB コンテナー URI を指定し、コンテナーと BLOB の匿名パブリック読み取りアクセスを構成します |
はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 このプロパティが指定されていない場合は、サービスでは、既定の Azure Integration Runtime が使用されます。 | いいえ |
例:
{
"name": "AzureBlobStorageAnonymous",
"properties": {
"annotations": [],
"type": "AzureBlobStorage",
"typeProperties": {
"containerUri": "https:// <accountname>.blob.core.windows.net/ <containername>",
"authenticationType": "Anonymous"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
UI 例:
UI エクスペリエンスは、次の図で説明されているとおりです。 このサンプルでは、Azure オープン データセットをソースとして使用します。 オープン データセット bing_covid-19_data.csv を取得する場合は、[認証の種類] に [匿名] を選択し、コンテナー URI に https://pandemicdatalake.blob.core.windows.net/public を入力するのみです。
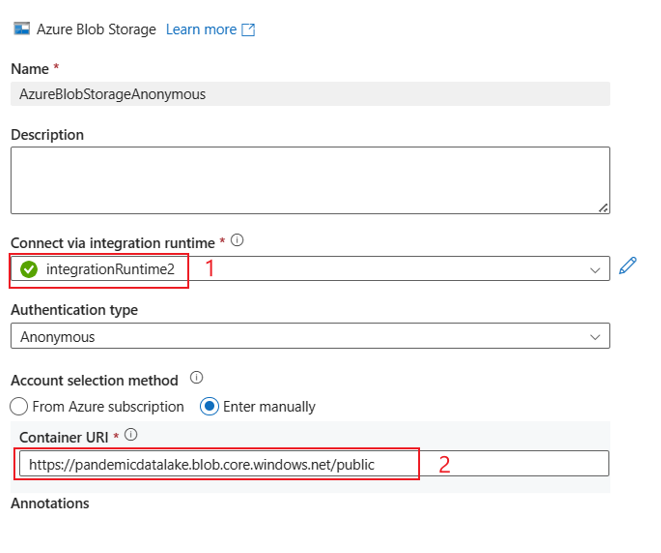
アカウント キー認証
以下のプロパティは、Azure Data Factory または Synapse パイプラインのストレージ アカウント キー認証でサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureBlobStorage (推奨) または AzureStorage (下記の注を参照) に設定する必要があります。 |
はい |
| connectionString | connectionString プロパティには、Storage に接続するために必要な情報を指定します。 アカウント キーを Azure Key Vault に格納して、接続文字列から accountKey 構成をプルすることもできます。 詳細については、下記の例と、「Azure Key Vault への資格情報の格納」の記事を参照してください。 |
はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 このプロパティが指定されていない場合は、サービスでは、既定の Azure Integration Runtime が使用されます。 | いいえ |
Note
アカウント キー認証を使用する場合、セカンダリ Blob service エンドポイントはサポートされません。 ほかの認証の種類を使用できます。
注意
AzureStorage タイプのリンクされたサービスを使用している場合、そのままでも引き続きサポートされます。 ただし今後は、新しい AzureBlobStorage タイプのリンクされたサービスを使用することをお勧めします。
例:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: アカウント キーを Azure Key Vault に格納する
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Shared Access Signature 認証
Shared Access Signature を使用すると、ストレージ アカウント内のリソースへの委任アクセスが可能になります。 Shared Access Signature を使用して、ストレージ アカウントのオブジェクトへの制限付きアクセス許可を、期間を指定してクライアントに付与できます。
アカウントのアクセス キーを共有する必要はありません。 Shared Access Signature とは、ストレージ リソースへの認証アクセスに必要なすべての情報をクエリ パラメーター内に含む URI です。 クライアントは、Shared Access Signature 内で適切なコンストラクターまたはメソッドに渡すだけで、Shared Access Signature でストレージ リソースにアクセスできます。
Shared Access Signature について詳しくは、Shared Access Signature のモデルの概要に関するページをご覧ください。
注意
- サービスでは、サービスの Shared Access Signature とアカウントの Shared Access Signature がサポートされるようになりました。 Shared Access Signature の詳細については、「Shared Access Signatures (SAS) を使用して Azure Storage リソースへの制限付きアクセスを許可する」を参照してください。
- 後のデータセットの構成では、フォルダーのパスはコンテナー レベルから始まる絶対パスです。 SAS URI のパスに揃えて構成する必要があります。
Shared Access Signature 認証を使用する場合には、以下のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureBlobStorage (推奨) または AzureStorage (下記の注を参照) に設定する必要があります。 |
はい |
| sasUri | BLOB、コンテナーなどの Storage リソースへの Shared Access Signature URI を指定します。 安全に格納するため、このフィールドを SecureString としてマークします。 自動ローテーションを使用してトークン部分を削除するために、SAS トークンを Azure Key Vault に配置することもできます。 詳細については、下記の例と、「Azure Key Vault への資格情報の格納」を参照してください。 |
はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 このプロパティが指定されていない場合は、サービスでは、既定の Azure Integration Runtime が使用されます。 | いいえ |
注意
AzureStorage タイプのリンクされたサービスを使用している場合、そのままでも引き続きサポートされます。 ただし今後は、新しい AzureBlobStorage タイプのリンクされたサービスを使用することをお勧めします。
例:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: アカウント キーを Azure Key Vault に格納する
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Shared Access Signature の URI を作成する際は、次の点に注意してください。
- リンク サービス (読み取り、書き込み、読み取り/書き込み) がどのように使用されているかに応じて、オブジェクトに対する適切な読み取り/書き込みアクセス許可を設定します。
- 有効期限を適切に設定します。 Storage オブジェクトへのアクセスがパイプラインのアクティブな期間内に期限切れにならないことを確認します。
- URI は、必要に応じて、適切なコンテナーまたは BLOB で作成する必要があります。 BLOB への Shared Access Signature URI を使用して、データ ファクトリまたは Synapse パイプラインから、その特定の BLOB へのアクセスを許可します。 BLOB ストレージ コンテナーへの Shared Access Signature URI を使用して、データ ファクトリまたは Synapse パイプラインで、そのコンテナー内の BLOB を反復処理できるようにします。 アクセスするオブジェクトの数を後で変更する場合、または Shared Access Signature URI を更新する場合は必ず、リンクされたサービスを新しい URI で更新してください。
サービス プリンシパルの認証
Azure Storage サービス プリンシパル認証の全般的な情報については、Microsoft Entra ID を使用して Azure Storage へのアクセスを認証することに関する記事をご覧ください。
サービス プリンシパル認証を使用するには、次の手順のようにします。
Microsoft ID プラットフォームにアプリケーションを登録する。 方法については、「クイック スタート: Microsoft ID プラットフォームにアプリケーションを登録する」を参照してください。 これらの値を記録しておきます。リンクされたサービスを定義するときに使います。
- アプリケーション ID
- アプリケーション キー
- テナント ID
Azure Blob Storage でサービス プリンシパルに適切なアクセス許可を付与します。 ロールの詳細については、「Azure portal を使用して BLOB とキュー データへのアクセスのための Azure ロールを割り当てる」を参照してください。
- ソースとして、アクセス制御 (IAM) で、少なくともストレージ BLOB データ閲覧者のロールを付与します。
- シンクとして、アクセス制御 (IAM) で、少なくともストレージ BLOB データ共同作成者のロールを付与します。
Azure Blob Storage のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureBlobStorage に設定する必要があります。 | はい |
| serviceEndpoint | https://<accountName>.blob.core.windows.net/ のパターンで、Azure Blob Storage サービス エンドポイントを指定します。 |
はい |
| accountKind | ストレージ アカウントの種類を指定します。 使用できる値は、以下のとおりです。Storage (汎用 v1)、StorageV2 (汎用 v2)、BlobStorage、または BlockBlobStorage。 データ フローで Azure Blob リンク サービスを使用する場合、アカウントの種類が空または "Storage" のとき、マネージド ID またはサービス プリンシパルの認証はサポートされません。 適切なアカウントの種類を指定するか、別の認証を選択するか、ストレージ アカウントを汎用 v2 にアップグレードします。 |
いいえ |
| servicePrincipalId | アプリケーションのクライアント ID を取得します。 | はい |
| servicePrincipalCredentialType | サービス プリンシパル認証に使用する資格情報の種類。 使用できる値は ServicePrincipalKey と ServicePrincipalCert です。 | Yes |
| servicePrincipalCredential | サービス プリンシパルの資格情報。 資格情報の種類として ServicePrincipalKey を使用する場合は、アプリケーションのキーを指定します。 このフィールドを SecureString とマークして安全に保存するか、Azure Key Vault に保存されているシークレットを参照します。 資格情報として ServicePrincipalCert を使用する場合は、Azure Key Vault 内の証明書を参照し、証明書のコンテンツ タイプが PKCS #12 であることを確認します。 |
はい |
| tenant | アプリケーションが存在するテナントの情報 (ドメイン名またはテナント ID) を指定します。 これは、Azure portal の右上隅にマウス ポインターを合わせると取得できます。 | はい |
| azureCloudType | サービス プリンシパル認証用に、Microsoft Entra アプリケーションが登録されている Azure クラウド環境の種類を指定します。 指定できる値は、AzurePublic、AzureChina、AzureUsGovernment、および AzureGermany です。 既定では、データ ファクトリまたは Synapse パイプラインのクラウド環境が使用されます。 |
いいえ |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 このプロパティが指定されていない場合は、サービスでは、既定の Azure Integration Runtime が使用されます。 | いいえ |
Note
- BLOB アカウントで論理的な削除が有効な場合、Data Flow では、サービス プリンシパル認証はサポートされません。
- Data Flow を使用してプライベート エンドポイント経由で BLOB ストレージにアクセスする場合、サービス プリンシパル認証が使用されていると、Data Flow は BLOB エンドポイントではなく ADLS Gen2 エンドポイントに接続することに注意してください。 アクセスを有効にするには、データ ファクトリまたは Synapse ワークスペースで、対応するプライベート エンドポイントを作成してください。
注意
サービス プリンシパル認証は、"AzureBlobStorage" タイプのリンクされたサービスのみでサポートされており、以前の "AzureStorage" タイプのリンクされたサービスではサポートされていません。
例:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
システム割り当てマネージド ID 認証
データ ファクトリや Synapse パイプラインは、Azure リソースのシステム割り当てマネージド ID に関連付けできます。これは、他の Azure サービスに対する認証のためのリソースを表します。 独自のサービス プリンシパルを使用するのと同様に、BLOB ストレージ認証のために、このシステム割り当てマネージド ID を直接使用できます。 これにより、この指定されたリソースは、BLOB ストレージにアクセスし、その BLOB ストレージとの間でデータをコピーできます。 Azure リソース用マネージド ID の詳細については、Azure リソース用マネージド ID に関するページを参照してください
Azure Storage の認証に関する全般的な情報については、Microsoft Entra ID を使用して Azure Storage へのアクセスを認証することに関するページを参照してください。 Azure リソースのマネージド ID 認証を使用するには、次の手順に従います。
ファクトリまたは Synapse ワークスペースと共に生成されたシステム割り当てマネージド ID のオブジェクト ID の値をコピーして、システム割り当てマネージド ID 情報を取得します。
Azure Blob Storage でマネージド ID にアクセス許可を付与します。 ロールの詳細については、「Azure portal を使用して BLOB とキュー データへのアクセスのための Azure ロールを割り当てる」を参照してください。
- ソースとして、アクセス制御 (IAM) で、少なくともストレージ BLOB データ閲覧者のロールを付与します。
- シンクとして、アクセス制御 (IAM) で、少なくともストレージ BLOB データ共同作成者のロールを付与します。
Azure Blob Storage のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureBlobStorage に設定する必要があります。 | はい |
| serviceEndpoint | https://<accountName>.blob.core.windows.net/ のパターンで、Azure Blob Storage サービス エンドポイントを指定します。 |
はい |
| accountKind | ストレージ アカウントの種類を指定します。 使用できる値は、以下のとおりです。Storage (汎用 v1)、StorageV2 (汎用 v2)、BlobStorage、または BlockBlobStorage。 データ フローで Azure Blob リンク サービスを使用する場合、アカウントの種類が空または "Storage" のとき、マネージド ID またはサービス プリンシパルの認証はサポートされません。 適切なアカウントの種類を指定するか、別の認証を選択するか、ストレージ アカウントを汎用 v2 にアップグレードします。 |
いいえ |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 このプロパティが指定されていない場合は、サービスでは、既定の Azure Integration Runtime が使用されます。 | いいえ |
例:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
ユーザー割り当てマネージド ID 認証
データ ファクトリは、1 つ以上のユーザー割り当てマネージド ID に割り当てることができます。 このユーザー割り当てマネージド ID を BLOB ストレージ認証に使用できます。これにより、BLOB ストレージ間でのデータのアクセスとコピーが可能になります。 Azure リソース用マネージド ID の詳細については、Azure リソース用マネージド ID に関するページを参照してください
Azure Storage の認証に関する全般的な情報については、Microsoft Entra ID を使用して Azure Storage へのアクセスを認証することに関するページを参照してください。 ユーザー割り当てマネージド ID 認証を使用するには、次の手順に従います。
1 つ以上のユーザー割り当てマネージド ID を作成して、Azure Blob Storage でアクセス許可を付与します。 ロールの詳細については、「Azure portal を使用して BLOB とキュー データへのアクセスのための Azure ロールを割り当てる」を参照してください。
- ソースとして、アクセス制御 (IAM) で、少なくともストレージ BLOB データ閲覧者のロールを付与します。
- シンクとして、アクセス制御 (IAM) で、少なくともストレージ BLOB データ共同作成者のロールを付与します。
1 つ以上のユーザー割り当てマネージド ID をデータ ファクトリに割り当てて、ユーザー割り当てマネージド ID ごとに資格情報を作成します。
Azure Blob Storage のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureBlobStorage に設定する必要があります。 | はい |
| serviceEndpoint | https://<accountName>.blob.core.windows.net/ のパターンで、Azure Blob Storage サービス エンドポイントを指定します。 |
はい |
| accountKind | ストレージ アカウントの種類を指定します。 使用できる値は、以下のとおりです。Storage (汎用 v1)、StorageV2 (汎用 v2)、BlobStorage、または BlockBlobStorage。 データ フローで Azure Blob リンク サービスを使用する場合、アカウントの種類が空または "Storage" のとき、マネージド ID またはサービス プリンシパルの認証はサポートされません。 適切なアカウントの種類を指定するか、別の認証を選択するか、ストレージ アカウントを汎用 v2 にアップグレードします。 |
いいえ |
| 資格情報 | ユーザー割り当てマネージド ID を資格情報オブジェクトとして指定します。 | はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 このプロパティが指定されていない場合は、サービスでは、既定の Azure Integration Runtime が使用されます。 | いいえ |
例:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
重要
PolyBase または COPY ステートメントを使用して (ソースまたはステージングとしての) BLOB ストレージから Azure Synapse Analytics にデータを読み込む場合に、BLOB ストレージに対してマネージド ID 認証を使用するときは、必ずこちらのガイダンスの手順 1 から 3 にも従ってください。 これらの手順により、サーバーが Microsoft Entra ID に登録され、Storage Blob データ共同作成者のロールがサーバーに割り当てられます。 残りの処理は Data Factory によって行われます。 Azure Virtual Network エンドポイントを使用して BLOB ストレージを構成する場合は、さらに Azure Synapse の要求に従って、Azure Storage アカウントで、 [ファイアウォールと仮想ネットワーク] 設定メニューの [信頼された Microsoft サービスによるこのストレージ アカウントに対するアクセスを許可します] をオンにする必要があります。
Note
- BLOB アカウントで論理的な削除が有効な場合、Data Flow では、システム割り当ておよびユーザー割り当てのマネージド ID 認証はサポートされません。
- Data Flow を使用してプライベート エンドポイント経由で BLOB ストレージにアクセスする場合、システム割り当てまたはユーザー割り当てのマネージド ID 認証が使用されていると、Data Flow は BLOB エンドポイントではなく、ADLS Gen2 エンドポイントに接続することに注意してください。 アクセスを有効にするには、ADF で対応するプライベート エンドポイントを作成してください。
注意
システム割り当ておよびユーザー割り当てのマネージド ID 認証は、種類が "AzureBlobStorage" のリンク サービスでのみサポートされており、以前の、種類が "AzureStorage" のリンク サービスではサポートされていません。
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
Azure Blob Storage では、形式ベースのデータセットの location 設定において、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセット内の location の type プロパティは、AzureBlobStorageLocation に設定する必要があります。 | はい |
| container | BLOB コンテナー。 | はい |
| folderPath | 特定のコンテナーの下のフォルダーへのパス。 ワイルドカードを使用してフォルダーをフィルター処理する場合は、この設定をスキップし、アクティビティのソース設定でこれを指定します。 | いいえ |
| fileName | 特定のコンテナーおよびフォルダー パスの下のファイル名。 ファイルをフィルター処理するためにワイルドカードを使用する場合は、この設定をスキップし、アクティビティのソースの設定でこれを指定します。 | いいえ |
例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、BLOB ストレージのソースとシンクでサポートされるプロパティの一覧を示します。
ソースの種類として Blob Storage を設定する
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
Azure Blob Storage では、形式ベースのコピー ソースの storeSettings 設定において、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | storeSettings の type プロパティは AzureBlobStorageReadSettings に設定する必要があります。 |
はい |
| コピーするファイルを特定する: | ||
| オプション 1: 静的パス |
データセットに指定されている所定のコンテナーまたはフォルダー/ファイル パスからコピーします。 コンテナーまたはフォルダーからすべての BLOB をコピーする場合は、さらに wildcardFileName を * として指定します。 |
|
| オプション 2: BLOB プレフィックス - prefix |
ソース オブジェクトをフィルター処理するためにデータセット内に構成されている、特定のコンテナー下の BLOB 名のプレフィックス。 名前が container_in_dataset/this_prefix で始まる BLOB が選択されます。 ワイルドカード フィルターより優れたパフォーマンスを提供する、BLOB ストレージ用のサービス側フィルターを利用します。プレフィックスを使用し、階層を保持した状態でファイルベースのシンクにコピーする場合は、プレフィックスの最後の "/" の後のサブパスが保持されることに注意してください。 たとえば、ソース container/folder/subfolder/file.txt があり、プレフィックスを folder/sub で構成した場合、保持されるファイル パスは subfolder/file.txt です。 |
いいえ |
| オプション 3: ワイルドカード - wildcardFolderPath |
ソース フォルダーをフィルター処理するためにデータセットで構成されている、特定のコンテナーの下のワイルドカード文字を含むフォルダーのパス。 使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。 フォルダー名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
いいえ |
| オプション 3: ワイルドカード - wildcardFileName |
ソース ファイルをフィルター処理するための、特定のコンテナーおよびフォルダー パス (またはワイルドカード フォルダー パス) の下のワイルドカード文字を含むファイル名。 使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。 ファイル名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
はい |
| オプション 4: ファイルの一覧 - fileListPath |
指定されたファイル セットをコピーすることを示します。 コピーするファイルの一覧を含むテキスト ファイルをポイントします。データセットで構成されているパスへの相対パスであるファイルを 1 行につき 1 つずつ指定します。 このオプションを使用している場合は、データ セットにファイル名を指定しないでください。 その他の例については、ファイル リストの例を参照してください。 |
いいえ |
| 追加の設定: | ||
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。 recursive が true に設定され、シンクがファイル ベースのストアである場合、空のフォルダーおよびサブフォルダーはシンクでコピーも作成もされないことに注意してください。 使用可能な値: true (既定値) および false。 fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| deleteFilesAfterCompletion | 宛先ストアに正常に移動した後、バイナリ ファイルをソース ストアから削除するかどうかを示します。 ファイルの削除はファイルごとに行われます。 このため、コピー アクティビティが失敗した場合、一部のファイルが既に宛先にコピーされ、ソースから削除されていますが、その他のものはまだソース ストアに残っています。 このプロパティは、バイナリ ファイルのコピー シナリオでのみ有効です。 既定値: false。 |
いいえ |
| modifiedDatetimeStart | ファイルは、属性 (最終変更日時) に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 プロパティは、ファイル属性フィルターをデータセットに適用しないことを意味する NULL にすることができます。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。 modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値未満であるファイルが選択されます。fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| modifiedDatetimeEnd | 前のプロパティと同じです。 | いいえ |
| enablePartitionDiscovery | パーティション分割されているファイルの場合、ファイル パスのパーティションを解析し、それを追加のソース列として追加するかどうかを指定します。 指定できる値は false (既定値) と true です。 |
いいえ |
| partitionRootPath | パーティション検出が有効になっている場合は、パーティション分割されたフォルダーをデータ列として読み取るための絶対ルート パスを指定します。 指定しない場合の既定は、以下のようになります。 - ソース上のデータセットまたはファイルの一覧内のファイル パスを使用する場合、パーティションのルート パスはそのデータセットで構成されているパスです。 - ワイルドカード フォルダー フィルターを使用する場合、パーティションのルート パスは最初のワイルドカードの前のサブパスです。 - プレフィックスを使用する場合、パーティションのルート パスは最後の "/" の前のサブパスです。 たとえば、データセット内のパスを "root/folder/year=2020/month=08/day=27" として構成するとします。 - パーティションのルート パスを "root/folder/year=2020" として指定した場合は、コピー アクティビティによって、ファイル内の列とは別に、それぞれ "08" と "27" の値を持つ month と day という 2 つの追加の列が生成されます。- パーティションのルート パスが指定されない場合、追加の列は生成されません。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
注意
Parquet や区切りテキスト形式の場合、次のセクションで説明するコピー アクティビティ ソース用の BlobSource 型は、下位互換性のために引き続きそのままサポートされます。 作成 UI がこれらの新しい種類の生成に切り替わるまでは、新しいモデルを使用することをお勧めします。
例:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
注意
$logs コンテナーは、あるストレージ アカウントに対して Storage Analytics が有効にされたときに自動的に作成されますが、UI でコンテナーの一覧表示操作を実行したときには表示されません。 $logs コンテナーにあるファイルを使用するには、ファクトリまたは Synapse パイプラインにファイル パスを直接指定する必要があります。
シンクの種類として Blob Storage を設定する
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
Azure Blob Storage では、形式ベースのコピー シンクの storeSettings 設定において、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | storeSettings の type プロパティは AzureBlobStorageWriteSettings に設定する必要があります。 |
はい |
| copyBehavior | ソースがファイル ベースのデータ ストアのファイルの場合は、コピー動作を定義します。 使用できる値は、以下のとおりです。 - PreserveHierarchy (既定値):ターゲット フォルダー内でファイル階層を保持します。 ソース フォルダーへのソース ファイルの相対パスはターゲット フォルダーへのターゲット ファイルの相対パスと同じになります。 - FlattenHierarchy:ソース フォルダーのすべてのファイルをターゲット フォルダーの第一レベルに配置します。 ターゲット ファイルは、自動生成された名前になります。 - MergeFiles:ソース フォルダーのすべてのファイルを 1 つのファイルにマージします。 ファイルまたは BLOB の名前を指定した場合、マージされたファイル名は指定した名前になります。 それ以外は自動生成されたファイル名になります。 |
いいえ |
| blockSizeInMB | ブロック BLOB にデータを書き込むために使用されるブロック サイズを MB 単位で指定します。 詳細は、ブロック BLOB に関するページを参照してください。 指定できる値は、4 MB から 100 MB です。 既定では、ソース ストアの種類とデータに基づいて、サービスによってブロック サイズが自動的に決定されます。 BLOB ストレージへの非バイナリ コピーの場合、既定のブロック サイズは 100 MB なので、(最大) 4.95 TB のデータに収めることができます。 データが大きくない場合、特に操作のタイムアウトやパフォーマンスの問題を引き起こす貧弱なネットワーク接続でセルフホステッド統合ランタイムを使用する場合、これは最適ではない可能性があります。 blockSizeInMB*50000 がデータを格納するのに十分な大きさであることを保証しつつ、ブロック サイズを明示的に指定できます。 そのようにしないと、コピー アクティビティの実行に失敗します。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
| metadata | シンクにコピーするときにカスタム メタデータを設定します。 metadata 配列の各オブジェクトは追加列を表します。 name ではメタデータ キー名を定義し、value では、そのキーのデータ値を指定します。 属性の保持機能が使用されている場合は、ソース ファイルのメタデータを使用して、指定されたメタデータの和集合の作成や上書きが行われます。使用できるデータ値: - $$LASTMODIFIED: 予約済みの変数によって、ソース ファイルの最終更新時刻を格納することを指定します。 バイナリ形式のファイルベースのソースにのみ適用されます。- 式 - 静的な値 |
いいえ |
例:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobStorageWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
フォルダーとファイル フィルターの例
このセクションでは、ワイルドカード フィルターを使用した結果のフォルダーのパスとファイル名の動作について説明します。
| folderPath | fileName | recursive | ソースのフォルダー構造とフィルターの結果 (太字のファイルが取得されます) |
|---|---|---|---|
container/Folder* |
(空、既定値を使用) | false | container FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
(空、既定値を使用) | true | container FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
*.csv |
false | container FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
*.csv |
true | container FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
ファイル リストの例
このセクションでは、コピー アクティビティのソースでファイル リスト パスを使用した結果の動作について説明します。
次のソース フォルダー構造があり、太字のファイルをコピーするとします。
| サンプルのソース構造 | FileListToCopy.txt のコンテンツ | 構成 |
|---|---|---|
| container FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv メタデータ FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
データセット内: - コンテナー: container- フォルダー パス: FolderAコピー アクティビティ ソース内: - ファイル リストのパス: container/Metadata/FileListToCopy.txt ファイル リストのパスは、コピーするファイル リストを含む同じデータ ストア内のテキスト ファイルをポイントします。 データセットで構成されたパスへの相対パスで、1 行に 1 つのファイルが含まれます。 |
recursive と copyBehavior の例
このセクションでは、recursive 値と copyBehavior 値のさまざまな組み合わせでのコピー操作の動作について説明します。
| recursive | copyBehavior | ソースのフォルダー構造 | ターゲットの結果 |
|---|---|---|---|
| true | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、ソースと同じ構造で作成されます。 Folder1 File1 File2 Subfolder1 File3 File4 File5 |
| true | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1 の自動生成された名前 File2 の自動生成された名前 File3 の自動生成された名前 File4 の自動生成された名前 File5 の自動生成された名前 |
| true | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1、File2、File3、File4、File5 の内容は 1 つのファイルにマージされて、自動生成されたファイル名が付けられます。 |
| false | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1 File2 File3、File4、File5 を含む Subfolder1 は取得されません。 |
| false | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1 の自動生成された名前 File2 の自動生成された名前 File3、File4、File5 を含む Subfolder1 は取得されません。 |
| false | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1、File2 の内容は 1 つのファイルにマージされ、自動生成されたファイル名が付けられます。 File1 の自動生成された名前 File3、File4、File5 を含む Subfolder1 は取得されません。 |
コピー中のメタデータの保持
Amazon S3、Azure Blob Storage、または Azure Data Lake Storage Gen2 から Azure Data Lake Storage Gen2 または Azure Blob Storage にファイルをコピーする場合、ファイルのメタデータをデータと共に保持することもできます。 詳細については、メタデータの保存に関する記事を参照してください。
Mapping Data Flow のプロパティ
マッピング データ フローでデータを変換するときに、次の形式で Azure Blob Storage のファイルの読み取りと書き込みができます。
形式固有の設定は、各形式のドキュメントに記載されています。 詳細については、「マッピング データ フローのソース変換」および「マッピング データ フローでのシンク変換」を参照してください。
ソース変換
ソース変換では、Azure Blob Storage 内のコンテナー、フォルダー、または個々のファイルから読み取ることができます。 ファイルの読み取り方法を管理するには、 [ソース オプション] タブを使用します。
![マッピング データ フロー ソース変換の [ソース オプション] タブのスクリーンショット。](media/data-flow/source-options-1.png)
ワイルドカード パス: ワイルドカード パターンを使用して、1 回のソース変換で、一致するフォルダーとファイルをそれぞれループ処理するようサービスに指示します。 これは、単一のフロー内の複数のファイルを処理するのに効果的な方法です。 既存のワイルドカード パターンにマウス ポインターを合わせると表示されるプラス記号を使って、複数のワイルドカード一致パターンを追加します。
ソース コンテナーから、パターンに一致する一連のファイルを選択します。 データセット内で指定できるのはコンテナーのみです。 そのため、ワイルドカード パスには、ルート フォルダーからのフォルダー パスも含める必要があります。
ワイルドカードの例:
*- 任意の文字セットを表します。**- ディレクトリの再帰的な入れ子を表します。?- 1 文字を置き換えます。[]- 角カッコ内の 1 文字以上に一致します。/data/sales/**/*.csv- /data/sales の下のすべての .csv ファイルを取得します。/data/sales/20??/**/- 20 世紀のすべてのファイルを取得します。/data/sales/*/*/*.csv- /data/sales の 2 レベル下の .csv ファイルを取得します。/data/sales/2004/*/12/[XY]1?.csv- 前に 2 桁の数字が付いた X または Y で始まる、2004 年 12 月のすべての .csv ファイルを取得します。
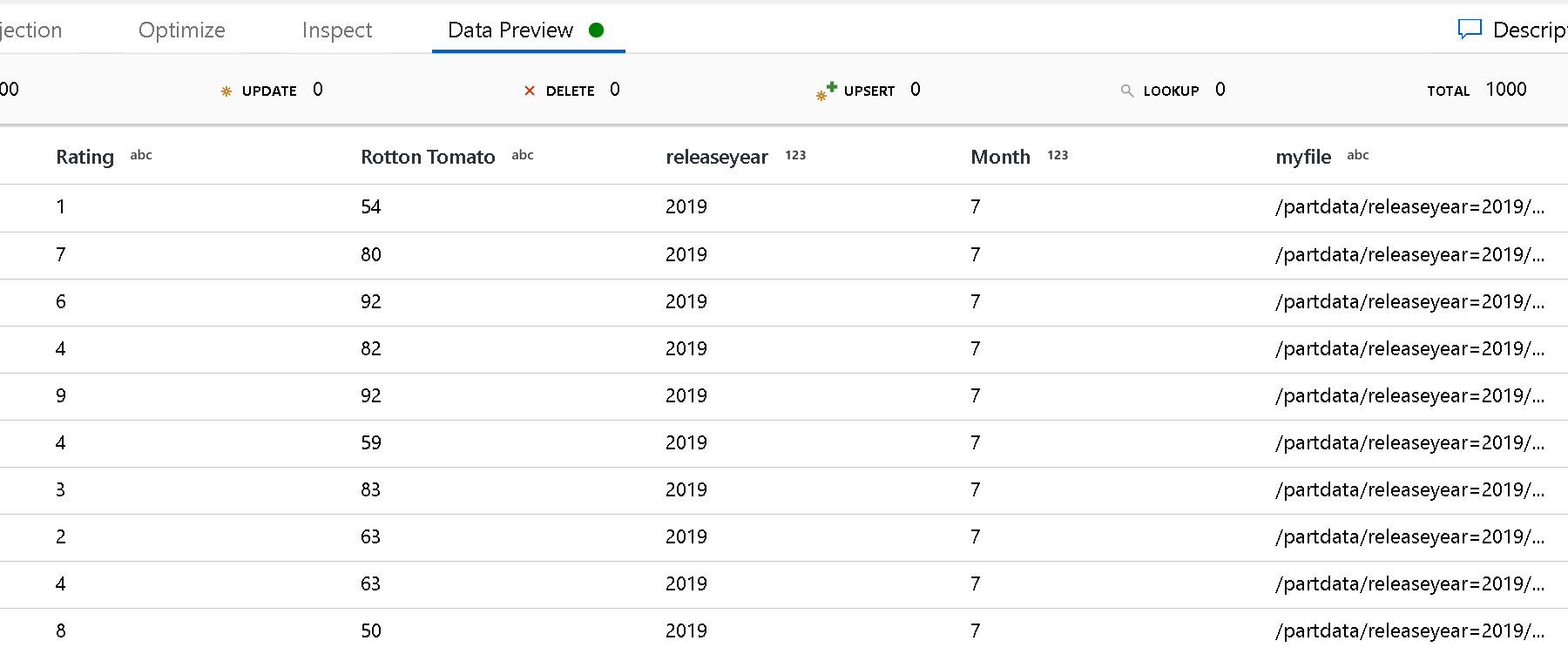
Partition root path: ファイル ソース内のフォルダーを key=value 形式 (例えば year=2019) で分割している場合、その分割フォルダー ツリーの最上位をデータ フローのデータ ストリームの列名に割り当てることができます。
最初に、ワイルドカードを設定して、パーティション分割されたフォルダーと読み取るリーフ ファイルのすべてのパスを含めます。
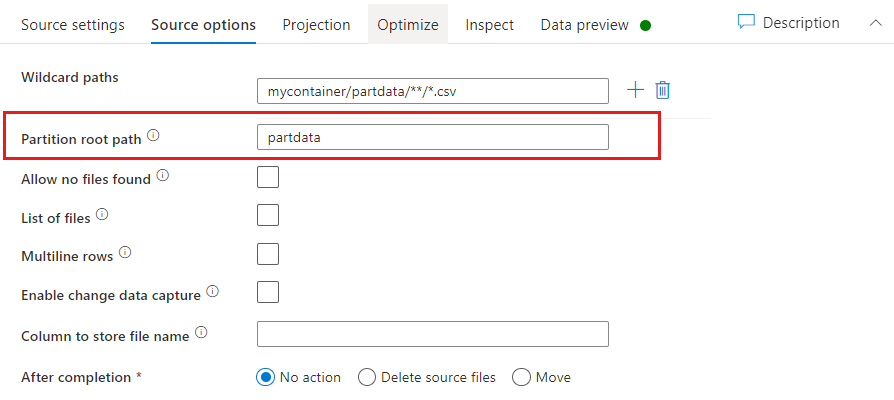
[Partition root path](パーティションのルート パス) 設定を使用して、フォルダー構造の最上位レベルを定義します。 データ プレビューでデータの内容を表示すると、各フォルダー レベルで見つかった解決済みのパーティションがサービスによって追加されることがわかります。
[List of files]: これはファイル セットです。 処理する相対パス ファイルの一覧を含むテキスト ファイルを作成します。 このテキスト ファイルをポイントします。
[Column to store file name](ファイル名を格納する列): ソース ファイルの名前をデータの列に格納します。 ファイル名文字列を格納するための新しい列名をここに入力します。
[After completion](完了後): データ フローの実行後にソース ファイルに何もしないか、ソース ファイルを削除するか、またはソース ファイルを移動することを選択します。 移動のパスは相対パスです。
後処理でソース ファイルを別の場所に移動するには、まず、ファイル操作の "移動" を選択します。 次に、"移動元" ディレクトリを設定します。 パスにワイルドカードを使用していない場合、"移動元" 設定はソース フォルダーと同じフォルダーになります。
ワイルドカードを含むソース パスがある場合、構文は次のようになります。
/data/sales/20??/**/*.csv
"移動元" は次のように指定できます。
/data/sales
"移動先" は次のように指定できます。
/backup/priorSales
この場合、ソースとして指定された /data/sales の下のすべてのファイルは /backup/priorSales に移動されます。
注意
ファイル操作は、パイプライン内のデータ フローの実行アクティビティを使用するパイプライン実行 (パイプラインのデバッグまたは実行) からデータ フローを開始する場合にのみ実行されます。 Data Flow デバッグ モードでは、ファイル操作は実行されません。
最終更新日でフィルター処理: 最終更新日の期間を指定すると、処理するファイルをフィルター処理できます。 日時はすべて UTC 形式です。
変更データ キャプチャを有効にする: これが trueの場合、最後に実行したファイルからのみ新規または変更されたファイルを取得します。 最初の実行時には必ず完全なスナップショット データが読み込まれ、次の実行時には新規または変更されたファイルのみが読み込まれます。
![[変更データのキャプチャを有効にする] を示すスクリーンショット。](media/data-flow/enable-change-data-capture.png)
シンクのプロパティ
シンク変換では、Azure Blob Storage 内のコンテナーまたはフォルダーに書き込むことができます。 ファイルへの書き込み方法を管理するには、 [設定] タブを使用します。
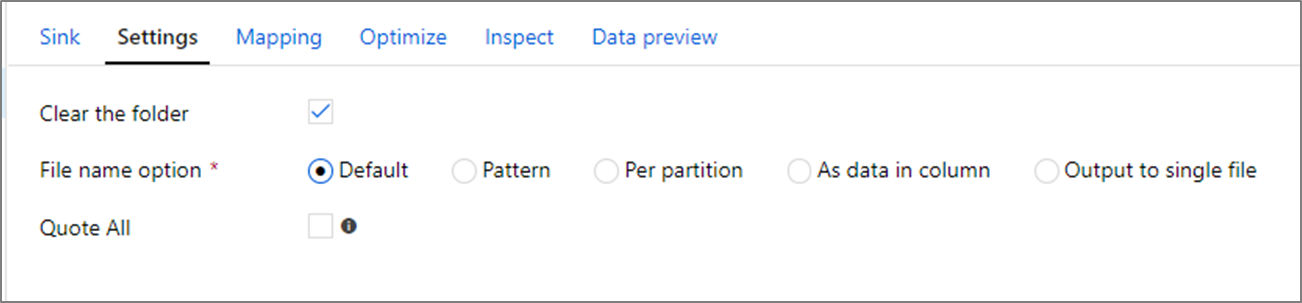
Clear the folder(フォルダーのクリア):データが書き込まれる前に、書き込み先のフォルダーをクリアするかどうかを決定します。
File name option(ファイル名のオプション):書き込み先のフォルダー内の書き込み先ファイルの命名方法を決定します。 ファイル名のオプションを次に示します。
- 既定:Spark は PART の既定値に基づいて、ファイルに名前を付けることができます。
- パターン:パーティションごとに出力ファイルを列挙するパターンを入力します。 たとえば、
loans[n].csvと指定すると、loans1.csv、loans2.csvというように作成されます。 - Per partition(パーティションあたり):パーティションごとに 1 つのファイル名を入力します。
- As data in column(列内のデータとして):出力ファイルを列の値に設定します。 パスは、書き込み先フォルダーではなく、データセット コンテナーからの相対パスです。 データセット内にフォルダー パスがある場合は、オーバーライドされます。
- Output to a single file(1 つのファイルに出力する):パーティション分割された出力ファイルを単一の名前付きファイルに結合します。 パスは、データセット フォルダーからの相対パスです。 マージ操作は、ノード サイズによっては失敗する可能性があることに注意してください。 このオプションは、大きなデータセットには推奨されません。
Quote all(すべてを引用符で囲む):すべての値を引用符で囲むかどうかを決定します
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
GetMetadata アクティビティのプロパティ
プロパティの詳細については、GetMetadata アクティビティに関するページを参照してください。
Delete アクティビティのプロパティ
プロパティの詳細については、Delete アクティビティに関するページを参照してください。
レガシ モデル
注意
次のモデルは、下位互換性のために引き続きそのままサポートされます。 前述の新しいモデルを使用することをお勧めします。 作成 UI は、新しいモデルの生成に切り替えられました。
レガシ データセット モデル
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、AzureBlob に設定する必要があります。 |
はい |
| folderPath | BLOB ストレージのコンテナーとフォルダーのパス。 ワイルドカード フィルターは、コンテナー名を除くパスに対してサポートされます。 使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。 フォルダー名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 (例: myblobcontainer/myblobfolder/)。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
はい (Copy または Lookup アクティビティの場合)、いいえ (GetMetadata アクティビティの場合) |
| fileName | 指定された folderPath 値の下にある BLOB の名前またはワイルドカード フィルター。 このプロパティの値を指定しない場合、データセットはフォルダー内のすべての BLOB をポイントします。 フィルターに使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。- 例 1: "fileName": "*.csv"- 例 2: "fileName": "???20180427.txt"ファイル名にワイルドカードまたはこのエスケープ文字が含まれている場合は、 ^ を使用してエスケープします。出力データセットに fileName の指定がなく、アクティビティ シンクに preserveHierarchy の指定がない場合、コピー アクティビティによって自動的に生成される BLOB 名のパターンは次のようになります: "Data.[activity run ID GUID].[GUID if FlattenHierarchy].[format if configured].[compression if configured] ". 次に例を示します。"Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz" クエリの代わりにテーブル名を使用して表形式のソースからコピーする場合、名前のパターンは [table name].[format].[compression if configured] となります。 次に例を示します。"MyTable.csv" です。 |
いいえ |
| modifiedDatetimeStart | ファイルは、属性 (最終変更日時) に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 この設定を有効にすると、大量のファイルのフィルター処理を実行する場合にデータ移動の全体的なパフォーマンスに影響することに注意してください。 プロパティは、ファイル属性フィルターをデータセットに適用しないことを意味する NULL にすることができます。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。 modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値未満であるファイルが選択されます。 |
いいえ |
| modifiedDatetimeEnd | ファイルは、属性 (最終変更日時) に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 この設定を有効にすると、大量のファイルのフィルター処理を実行する場合にデータ移動の全体的なパフォーマンスに影響することに注意してください。 プロパティは、ファイル属性フィルターをデータセットに適用しないことを意味する NULL にすることができます。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。 modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値未満であるファイルが選択されます。 |
いいえ |
| format | ファイルベースのストア間でファイルをそのままコピー (バイナリ コピー) する場合は、入力と出力の両方のデータセット定義で format セクションをスキップします。 特定の形式のファイルを解析または生成する場合、サポートされるファイル形式の種類は、TextFormat、JsonFormat、AvroFormat、OrcFormat、ParquetFormat。 format の type プロパティをいずれかの値に設定します。 詳細については、Text 形式、Json 形式、Avro 形式、Orc 形式、Parquet 形式 の各セクションを参照してください。 |
いいえ (バイナリ コピー シナリオのみ) |
| compression | データの圧縮の種類とレベルを指定します。 詳細については、サポートされるファイル形式と圧縮コーデックに関する記事を参照してください。 サポートされる種類は、GZip、Deflate、BZip2、および ZipDeflate です。 サポートされるレベルは、Optimal と Fastest です。 |
いいえ |
ヒント
フォルダーの下のすべての BLOB をコピーするには、folderPath のみを指定します。
特定の名前の単一の BLOB をコピーするには、フォルダー部分に folderPath、ファイル名に fileName を指定します。
フォルダーの下の BLOB のサブセットをコピーするには、フォルダー部分に folderPath、ワイルドカード フィルターで fileName を指定します。
例:
{
"name": "AzureBlobDataset",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
コピー アクティビティのレガシ ソース モデル
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは、BlobSource に設定する必要があります。 |
はい |
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。 recursive が true に設定されており、シンクがファイル ベースのストアである場合、シンクでは、空のフォルダーまたはサブフォルダーはコピーされず、作成もされません。使用できる値は、 true (既定値) と false です。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Blob input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
コピー アクティビティのレガシ シンク モデル
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのシンクの type プロパティは、BlobSink に設定する必要があります。 |
はい |
| copyBehavior | ソースがファイル ベースのデータ ストアのファイルの場合は、コピー動作を定義します。 使用できる値は、以下のとおりです。 - PreserveHierarchy (既定値):ターゲット フォルダー内でファイル階層を保持します。 ソース フォルダーに対するソース ファイルの相対パスと、ターゲット フォルダーに対するターゲット ファイルの相対パスが一致します。 - FlattenHierarchy:ソース フォルダーのすべてのファイルをターゲット フォルダーの第一レベルに配置します。 ターゲット ファイルは、自動生成された名前になります。 - MergeFiles:ソース フォルダーのすべてのファイルを 1 つのファイルにマージします。 ファイルまたは BLOB の名前を指定した場合、マージされたファイル名は指定した名前になります。 それ以外は自動生成されたファイル名になります。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyToBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Blob output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
変更データ キャプチャ
Azure Data Factory は、マッピング データ フローのソース変換で ** 変更データ キャプチャを有効にする ** を有効にすることで、Azure Blob Storage からのみ新規または変更されたファイルを取得できます。 このコネクタ オプションを使用すると、変換されたデータを選択した変換先データセットに読み込む前に、新しいファイルまたは更新されたファイルのみを読み取り、変換を適用できます。 詳細については、「変更データ キャプチャ」を参照してください。
関連するコンテンツ
Copy アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するページを参照してください。