適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
Azure Data Factoryおよび Synapse Analytics では、パイプラインの反復的な開発とデバッグがサポートされています。 これらの機能を使用すると、行った変更をテストした後で、pull request を作成したり、変更をサービスに公開したりできます。
この機能の概要とデモンストレーションについては、以下の 8 分間の動画を視聴してください。
パイプラインのデバッグ
パイプライン キャンバスを使用して作成するときは、デバッグ機能を使用してアクティビティをテストできます。 テストの実行を行うときは、 [デバッグ] を選択する前に、サービスに変更を発行する必要はありません。 この機能は、ワークフローを更新する前に、変更が期待どおりに動作することを確認する場合に便利です。

パイプラインが実行中の間は、パイプライン キャンバスの [出力] タブで各アクティビティの結果を確認できます。
テストの実行結果は、パイプライン キャンバスの出力ウィンドウに表示されます。
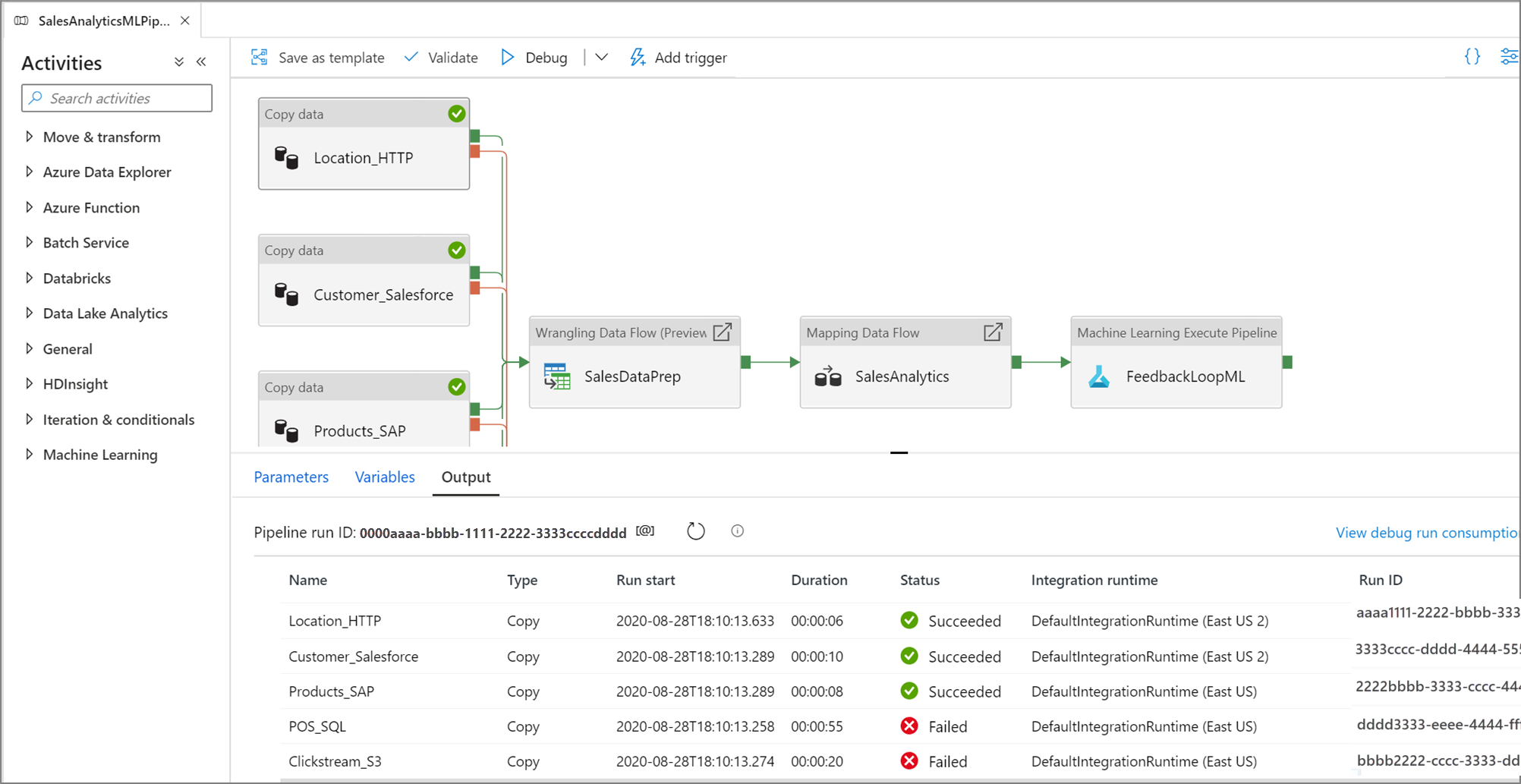
テストの実行が成功したら、パイプラインにさらにアクティビティを追加し、反復的な方法でデバッグを続行します。 テストの実行中に、実行を [キャンセル] することもできます。
重要
[デバッグ] を選択すると、パイプラインが実際に実行されます。 たとえばパイプラインにコピー アクティビティが含まれていれば、テストの実行では、データがコピー元からコピー先にコピーされます。 その結果、デバッグ時のコピー アクティビティとその他のアクティビティでは、テスト フォルダーを使用することをお勧めします。 パイプラインのデバッグが終わったら、通常の操作で使用する実際のフォルダーに切り替えます。
ブレークポイントの設定
このサービスを使用すると、パイプライン キャンバスの特定のアクティビティに到達するまで、パイプラインをデバッグできます。 アクティビティにテストの終了点となるブレークポイントを設定し、 [デバッグ] を選択します。 このサービスは、パイプライン キャンバスでブレークポイント アクティビティまでのみ、テストの実行を保証します。 この特定の場所までデバッグする機能は、パイプライン全体ではなく、パイプライン内のアクティビティのサブセットのみをテストする場合に便利です。

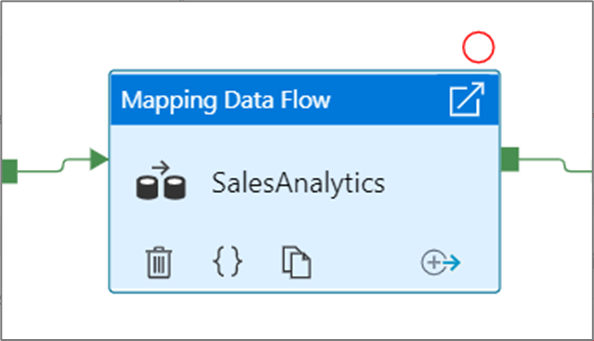
ブレークポイントを設定するには、パイプライン キャンバス上で要素を選択します。 Debug Until オプションは、要素の右上隅に空の赤い円として表示されます。
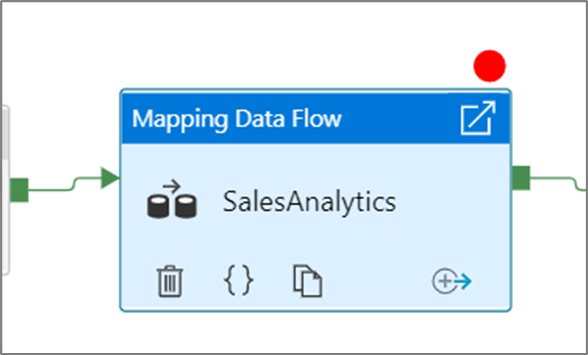
Debug Until オプションを選択した後、赤い円で示されているようにブレークポイントが有効になります。
デバッグ実行の監視
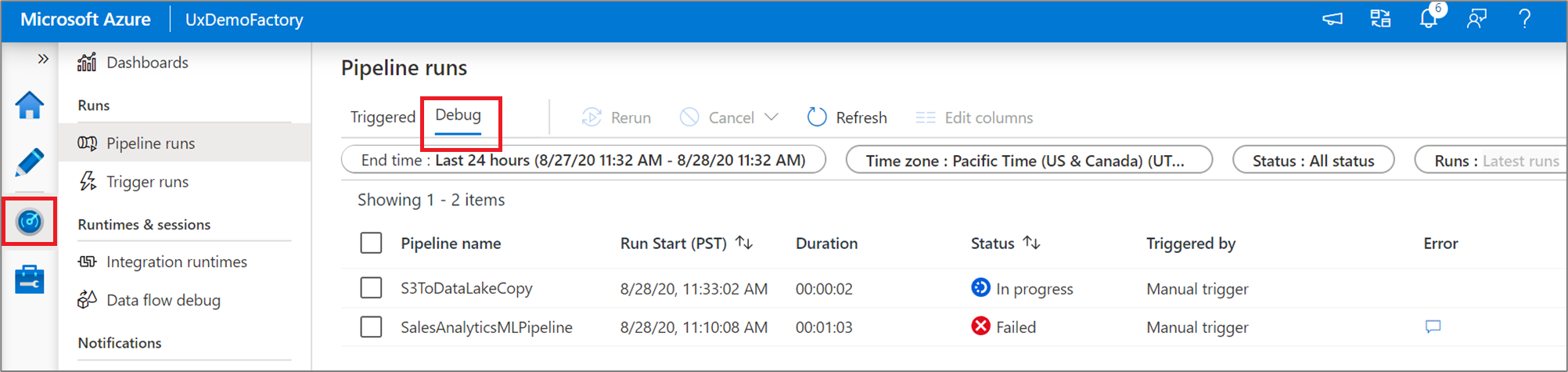
パイプラインのデバッグ実行を実行すると、パイプライン キャンバスの [出力] ウィンドウに結果が表示されます。 出力タブには、現在のブラウザー セッション中に行われた最新の実行のみが含まれます。
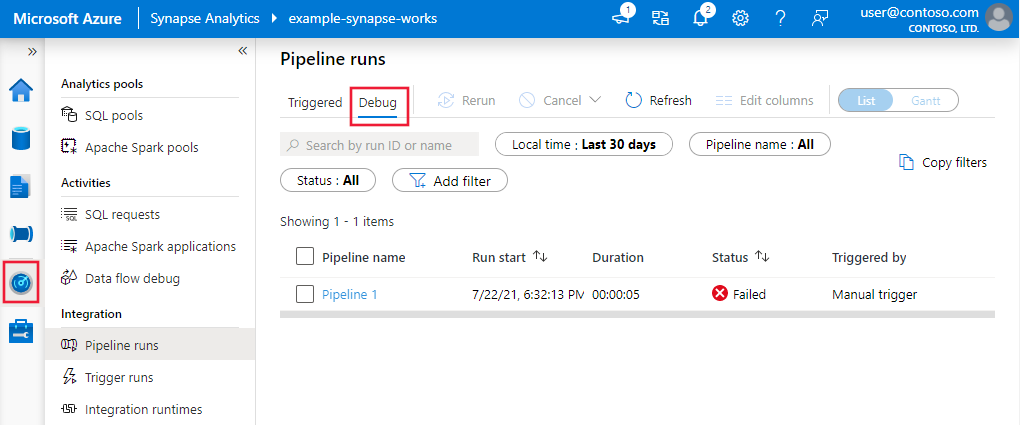
デバッグ実行の履歴ビューを表示したり、すべてのアクティブなデバッグ実行の一覧を表示したりするには、 [監視] エクスペリエンスにアクセスします。
- Azureデータファクトリー
- Synapse Analytics
注意
このサービスでは、デバッグの実行履歴は 15 日間のみ保持されます
マッピング データ フローのデバッグ
マッピング データ フローを使用すると、大規模に実行されるコーディング不要のデータ変換ロジックを作成できます。 ロジックを構築する際に、デバッグ セッションをオンにして、ライブ Spark クラスターを使用してインタラクティブにデータを操作することができます。 詳細については、「マッピング データ フローのデバッグ モード」を参照してください。
[監視] エクスペリエンスで、アクティブなデータ フロー デバッグ セッションを監視できます。
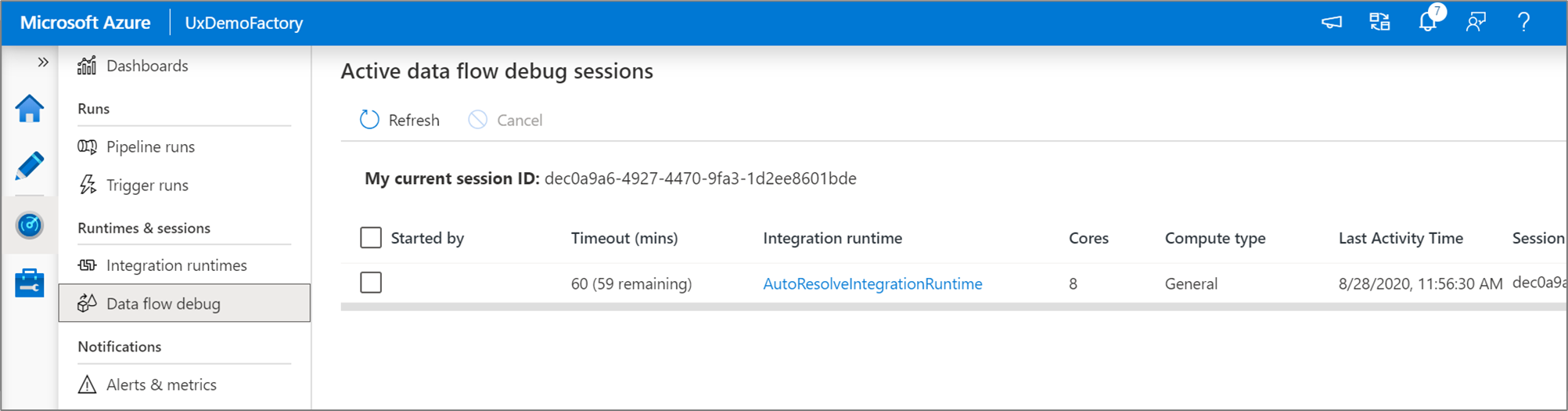
データ フロー デザイナーのデータ プレビューとデータ フローのパイプライン デバッグは、小規模なデータ サンプルを使った場合に最適に機能するよう設計されています。 ただし、パイプラインまたはデータ フロー内のロジックを大量のデータに対してテストする必要がある場合は、デバッグ セッションで使用されるAzure Integration Runtimeのサイズを増やし、コア数を増やし、汎用コンピューティングを最小限に抑えます。
データ フロー アクティビティが含まれるパイプラインのデバッグ
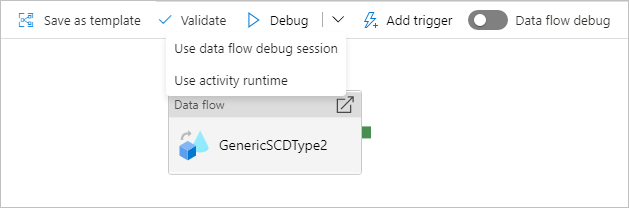
データ フローが含まれるパイプライン実行のデバッグを行うときに使用するコンピューティングには、2 つのオプションがあります。 既存のデバッグ クラスターを使用することも、データ フローに対して新しい Just-In-Time クラスターを作成することもできます。
既存のデバッグ セッションを使用すると、クラスターが既に稼働中であるためデータ フローの起動時間が大幅に短縮されますが、複数のジョブを一度に実行するときに失敗する場合があるため、複雑なワークロードや並列ワークロードには推奨されません。
アクティビティ ランタイムを使用すると、各データ フロー アクティビティの統合ランタイムで指定された設定を使用して新しいクラスターが作成されます。 これにより、各ジョブを分離することができるため、複雑なワークロードやパフォーマンス テストにはこれを使用する必要があります。 また、Azure IR の TTL を制御して、デバッグに使用されるクラスター リソースをその期間引き続き使用して、追加のジョブ要求を処理できるようにすることもできます。
注意
データ フローが並列で実行されているパイプラインや、大規模なデータセットでテストする必要があるデータ フローがある場合は、[Use Activity Runtime]\(アクティビティ ランタイムの使用\) を選択して、データ フロー アクティビティで選択したIntegration Runtimeをサービスが使用できるようにします。 これで、データ フローを複数のクラスターで実行できるようになり、データ フローの並列実行に対応できます。
関連するコンテンツ
変更をテストした後、継続的なインテグレーションとデプロイを使用して、より上位の環境に昇格させます。