適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
pipeline の Azure Databricks Jar アクティビティは、Azure Databricks クラスターで Spark Jar を実行します。 この記事は、データ変換とサポートされる変換アクティビティの概要を説明する、 データ変換アクティビティ に関する記事に基づいています。 Azure Databricksは、Apache Spark を実行するためのマネージド プラットフォームです。
この機能の概要とデモンストレーションについては、以下の 11 分間の動画を視聴してください。
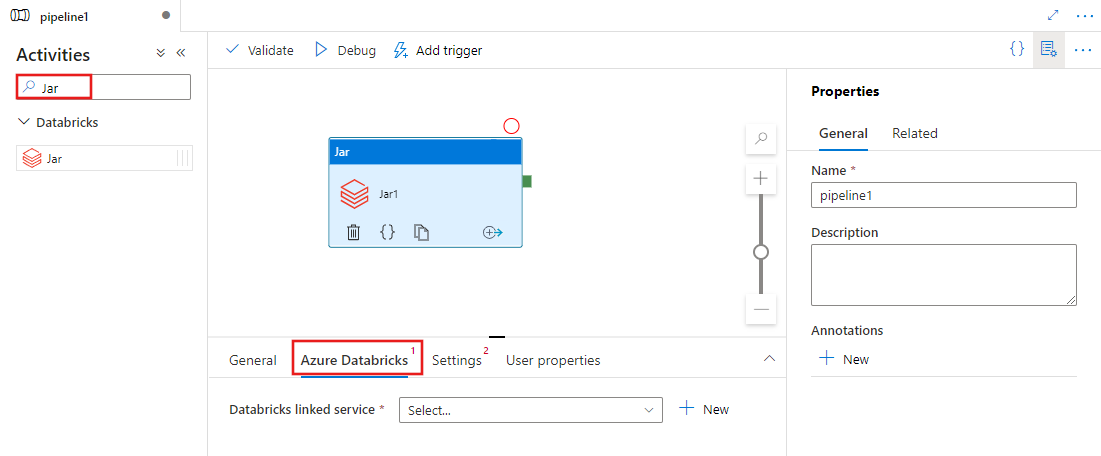
UI を使用してパイプラインにAzure Databricksの Jar アクティビティを追加する
パイプライン内のAzure Databricksに Jar アクティビティを使用するには、次の手順を実行します。
パイプラインの [アクティビティ] ペイン内で Jar を検索し、Jar アクティビティをパイプライン キャンバスにドラッグします。
まだ選択されていない場合は、キャンバスで新しい Jar アクティビティを選択します。
Azure Databricks タブを選択して、Jar アクティビティを実行する新しいAzure Databricksリンクされたサービスを選択または作成します。
Settings タブを選択し、Azure Databricksで実行するクラス名、Jar に渡す省略可能なパラメーター、およびジョブを実行するためにクラスターにインストールするライブラリを指定します。
![Jar アクティビティの [設定] タブの UI を示している。](media/transform-data-databricks-jar/jar-settings.png)
Databricks Jar アクティビティの定義
Databricks Jar アクティビティのサンプルの JSON 定義を次に示します。
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Databricks Jar アクティビティのプロパティ
次の表で、JSON 定義で使用される JSON プロパティについて説明します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 名前 | パイプラインのアクティビティの名前。 | はい |
| 説明 | アクティビティの動作を説明するテキスト。 | いいえ |
| 型 | Databricks Jar アクティビティでは、アクティビティの種類は DatabricksSparkJar です。 | はい |
| linkedServiceName | Jar アクティビティが実行されている Databricks リンク サービスの名前です。 このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。 | はい |
| mainClassName | 実行される main メソッドを含むクラスのフル ネーム。 このクラスは、ライブラリとして提供される JAR に含まれている必要があります。 1 つの JAR ファイルに複数のクラスを含めることができます。 各クラスには、main メソッドを含めることができます。 | はい |
| パラメータ | main メソッドに渡されるパラメーター。 このプロパティは文字列の配列です。 | いいえ |
| ライブラリ | ジョブを実行するクラスターにインストールされるライブラリのリスト。 <文字列, オブジェクト> の配列を指定できます。 | はい (mainClassName メソッドを少なくとも 1 つ含む) |
注意
既知の問題 - 同時 Databricks Jar アクティビティの実行に同じ対話型クラスターを使用する場合 (クラスターの再起動なし)、Databricks には、最初のアクティビティのパラメーターが、次のアクティビティでも使用されるという既知の問題があります。 そのため、後続のジョブに渡されるパラメーターが正しくありません。 これを回避するには、代わりにジョブ クラスターを使用します。
databricks アクティビティでサポートされるライブラリ
前の Databricks アクティビティ定義では、jar、egg、maven、pypi、cran というライブラリの種類を指定しました。
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
ライブラリの種類の詳細については、Databricks のドキュメントを参照してください。
Databricks でライブラリをアップロードする方法
ワークスペース UI を使用できます。
UI を使用して追加されたライブラリの dbfs パスを取得するには、Databricks CLI を使用します。
UI を使用する場合、通常、Jar ライブラリは dbfs:/FileStore/jars に保存されます。 CLI databricks fs ls dbfs:/FileStore/job-jars を使用してすべてを一覧表示することができます
または、Databricks CLI を使用できます。
Databricks CLI を使用します (インストール手順)。
たとえば、JAR を dbfs にコピーする場合:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
関連するコンテンツ
この機能の 11 分間の概要とデモについては、video をご覧ください。