適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
重要
Azure Machine Learning スタジオ (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えることをおすすめします。
2021 年 12 月 1 日の時点で、新しい Machine Learning Studio (クラシック) リソース (ワークスペースと Web サービス プラン) を作成することはできません。 2024 年 8 月 31 日まで、既存の Machine Learning スタジオ (クラシック) の実験と Web サービスを引き続き使用できます。 詳細については、以下を参照してください:
Machine Learning Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
この記事では、Azure Data Factory と Azure Synapse Analytics のパイプラインとアクティビティの概要、およびそれらを利用して、データ移動シナリオやデータ処理シナリオ用のエンド ツー エンドのデータ主導ワークフローを作成する方法について説明します。
概要
Data Factory または Synapse ワークスペースには、1 つ以上のパイプラインを設定できます。 パイプラインは、1 つのタスクを連携して実行するアクティビティの論理的なグループです。 たとえば、ログ データを取り込んでクリーニングしてから、マッピング データ フローを開始してそのログ データを分析するアクティビティのセットをパイプラインに組み込むこともできます。 パイプラインを使用すると、各アクティビティを個別に管理するのではなく、セットとして管理できます。 デプロイとスケジュール設定を、アクティビティごとではなく、パイプライン単位で行うことができます。
パイプライン内の複数のアクティビティは、データに対して実行するアクションを定義します。 たとえば、Copy アクティビティを使用すると、SQL Server から Azure BLOB ストレージにデータをコピーできます。 次に、データ フロー アクティビティまたは Databricks Notebook アクティビティを使用して、BLOB ストレージから、ビジネス インテリジェンス レポート ソリューションが構築された Azure Synapse Analytics プールにデータを処理して変換します。
Azure Data Factory と Azure Synapse Analytics には、データ移動アクティビティ、データ変換アクティビティ、制御アクティビティの 3 種類のアクティビティ グループがあります。 アクティビティは 0 個以上の入力データセットを受け取り、1 個以上の出力データセットを生成できます。 次の図は、パイプライン、アクティビティ、データセットの関係を示しています。

入力データセットはパイプライン内のアクティビティに対する入力を表し、出力データセットはアクティビティの出力を表します。 データセットは、テーブル、ファイル、フォルダー、ドキュメントなど、さまざまなデータ ストア内のデータを示します。 作成したデータセットは、パイプライン内のアクティビティで使用できます。 たとえば、データセットはコピー アクティビティまたは HDInsightHive アクティビティの入力/出力データセットとして使用できます。 データセットの詳細については、「Azure Data Factory のデータセット」の記事を参照してください。
Note
パイプラインごとに最大 80 個のアクティビティの既定のソフト制限があります。これには、コンテナーの内部アクティビティが含まれます。
データ移動アクティビティ
Data Factory のコピー アクティビティは、ソース データ ストアからシンク データ ストアにデータをコピーします。 Data Factory は、このセクションの表に挙げられているデータ ストアをサポートしています。 また、任意のソースのデータを任意のシンクに書き込むことができます。
詳細については、「Copy Activity - Overview (コピー アクティビティの概要)」を参照してください。
データ ストアを選択すると、そのストアとの間でデータをコピーする方法がわかります。
注意
"プレビュー" と記載されたコネクタは試用版です。フィードバックをお寄せください。 ソリューションでプレビュー版コネクタの依存関係を取得したい場合、Azure サポートにお問い合わせください。
データ変換アクティビティ
Azure Data Factory と Azure Synapse Analytics では、次の変換アクティビティがサポートされています。これらは、個別または他のアクティビティと連結した状態で追加できます。
詳細については、データ変換アクティビティに関する記事を参照してください。
| データ変換アクティビティ | Compute 環境 |
|---|---|
| データ フロー | Azure Data Factory によって管理される Apache Spark クラスター |
| Azure 関数 | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop ストリーミング | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| ML Studio (クラシック) のアクティビティ: Batch Execution と更新リソース | Azure VM |
| ストアド プロシージャ | Azure SQL、Azure Synapse Analytics、または SQL Server |
| U-SQL | Azure Data Lake Analytics |
| カスタム アクティビティ | Azure Batch |
| Databricks Notebook | Azure Databricks |
| Databricks Jar アクティビティ | Azure Databricks |
| Databricks Python アクティビティ | Azure Databricks |
| Synapse Notebook アクティビティ | Azure Synapse Analytics |
制御フロー アクティビティ
次の制御フロー アクティビティがサポートされています。
| 制御アクティビティ | 説明 |
|---|---|
| 変数の追加 | 既存の配列変数に値を追加します。 |
| パイプラインの実行 | Execute Pipeline アクティビティを使用すると、Data Factory または Synapse の 1 つのパイプラインから別のパイプラインを呼び出すことができます。 |
| Assert | 入力配列にフィルター式を適用します |
| For Each | ForEach アクティビティは、パイプライン内の繰り返し制御フローを定義します。 このアクティビティは、コレクションを反復処理するために使用され、指定されたアクティビティをループで実行します。 このアクティビティのループの実装は、プログラミング言語の Foreach ループ構造に似ています。 |
| メタデータの取得 | GetMetadata アクティビティを使用すると、Data Factory または Synapse のパイプラインで任意のデータのメタデータを取得できます。 |
| If Condition アクティビティ | If Condition は、true または false として評価される条件に基づき分岐を行うために使用できます。 If Condition アクティビティは、プログラミング言語における if ステートメントと同じ働きを持ちます。 条件が true に評価されたときの一連のアクティビティと false. に評価されたときの一連のアクティビティが評価されます |
| ルックアップ アクティビティ | ルックアップ アクティビティを使用して、任意の外部ソースからレコード/テーブル名/値を読み取ったり検索したりできます。 この出力は、後続のアクティビティによってさらに参照できます。 |
| 変数の設定 | 既存の変数の値を設定します。 |
| Until アクティビティ | プログラミング言語の Do-Until ループ構造に似た Do-Until ループを実装します。 Until アクティビティでは、そこに関連付けられている条件が true に評価されるまで、一連のアクティビティがループ実行されます。 Until アクティビティにはタイムアウト値を指定できます。 |
| 検証アクティビティ | 参照データセットが存在する、指定された条件を満たす、またはタイムアウトに達した場合にのみ、パイプラインが実行を継続するようにします。 |
| Wait アクティビティ | パイプラインで Wait アクティビティを使用すると、パイプラインは、指定した期間待った後、後続のアクティビティの実行を続行します。 |
| Web アクティビティ | Web アクティビティを使用すると、パイプラインからカスタム REST エンドポイントを呼び出すことができます。 このアクティビティで使用したり、アクセスしたりするデータセットやリンクされたサービスを渡すことができます。 |
| Webhook アクティビティ | Webhook アクティビティを使用すると、エンドポイントを呼び出し、コールバック URL を渡すことができます。 パイプラインの実行は、コールバックが呼び出されるのを待ってから、次のアクティビティに進みます。 |
UI によるパイプラインの作成
新しいパイプラインを作成するには、Data Factory Studio の [作成者] タブ (鉛筆アイコンで表されます) に移動し、プラス記号を選択し、メニューから [パイプライン] を選択して、サブメニューから再度 [パイプライン] を選択します。
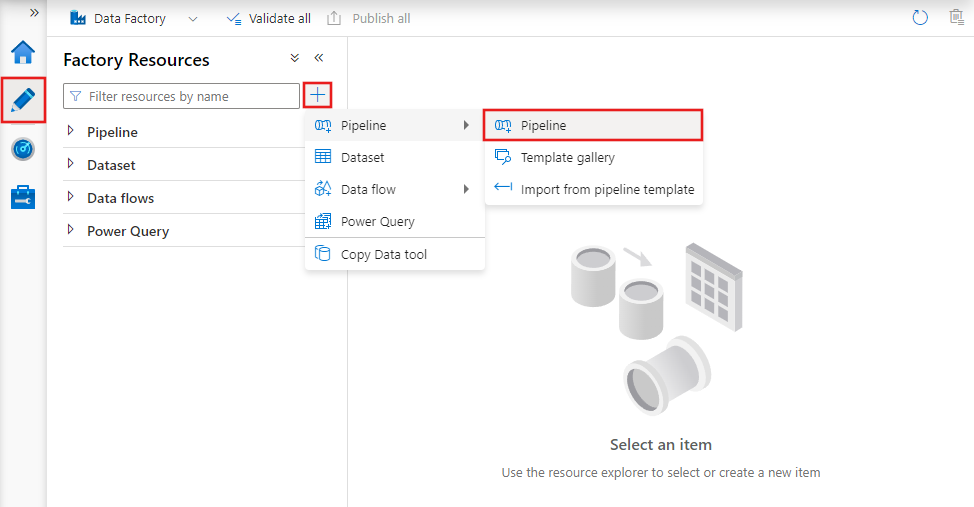
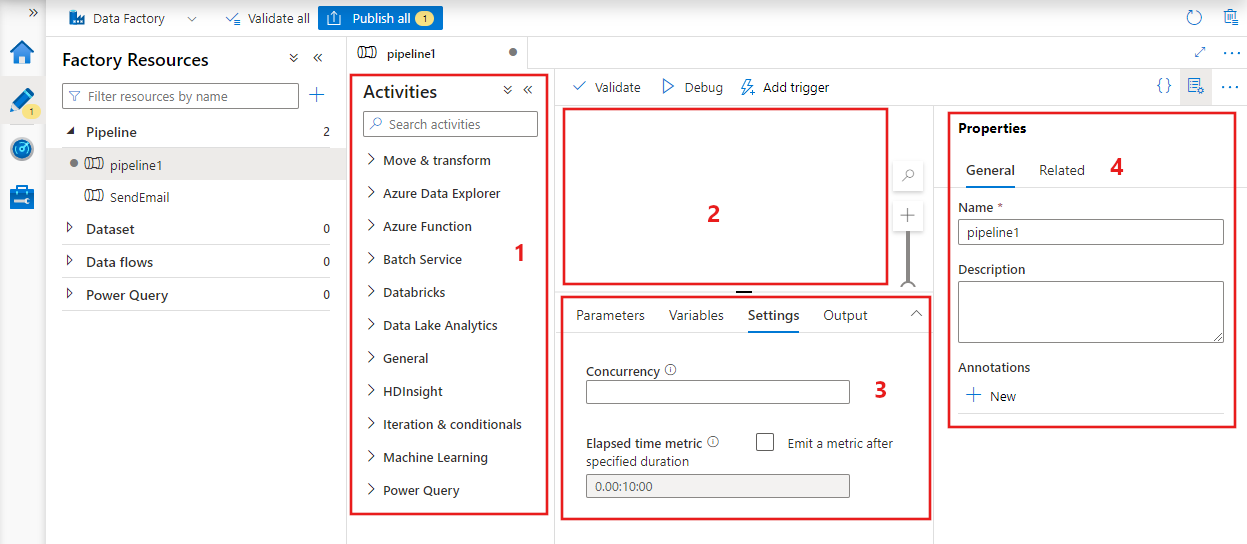
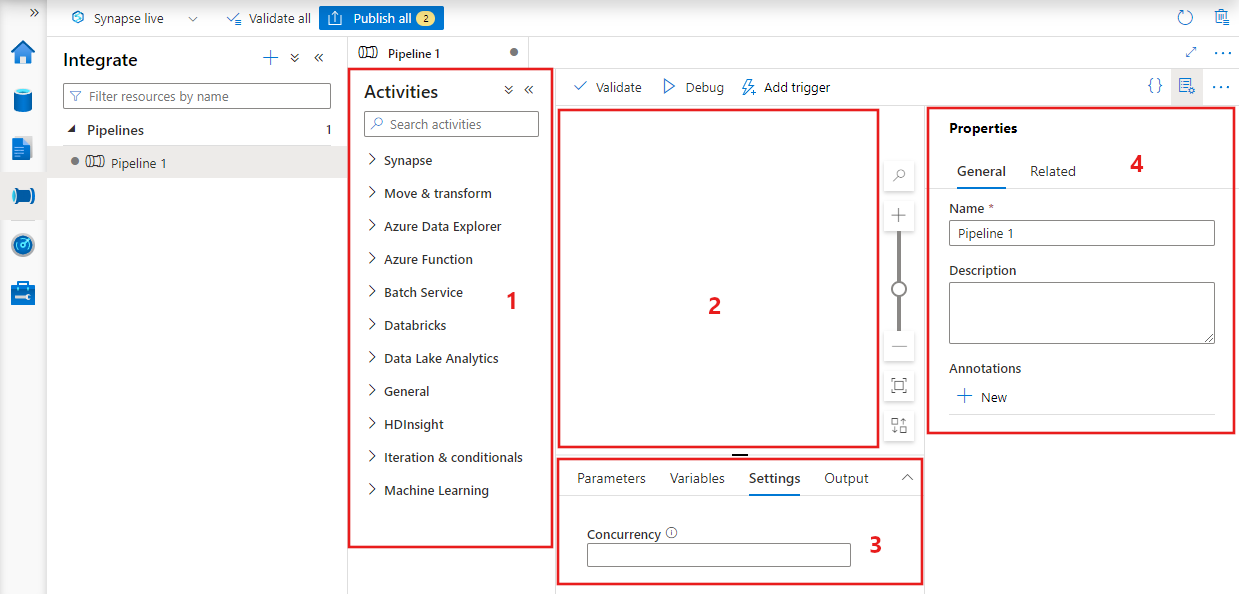
データ ファクトリにパイプライン エディターが表示され、ここで次の情報を確認できます:
- パイプライン内で使用できるすべてのアクティビティ。
- パイプライン エディター キャンバス。アクティビティがパイプラインに追加されたときにここに表示されます。
- パラメーター、変数、全般設定、出力などのパイプライン構成ウィンドウ。
- パイプラインのプロパティ ウィンドウ。パイプライン名、省略可能な説明、注釈を構成できます。 このペインには、データ ファクトリ内のパイプラインの関連アイテムも表示されます。
パイプライン JSON
パイプラインを JSON 形式で定義する方法を示します:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| タグ | 説明 | タイプ | 必要な領域 |
|---|---|---|---|
| name | パイプラインの名前。 パイプラインが実行するアクションを表す名前を指定します。
|
String | はい |
| description | パイプラインの用途を説明するテキストを指定します。 | String | いいえ |
| activities | activities セクションでは、1 つまたは複数のアクティビティを定義できます。 activities JSON 要素の詳細については、「アクティビティ JSON」のセクションを参照してください。 | Array | はい |
| parameters | parameters セクションでは、パイプライン内に 1 つ以上のパラメーターを定義できるので、パイプラインの再利用に柔軟性を持たせることができます。 | List | いいえ |
| concurrency | パイプラインで可能な同時実行の最大数。 既定では、最大値はありません。 コンカレンシーの制限に達した場合、前の実行が完了するまで追加のパイプライン実行がキューに追加されます | 数値 | いいえ |
| annotations | パイプラインに関連付けられているタグの一覧 | Array | いいえ |
アクティビティ JSON
activities セクションでは、1 つまたは複数のアクティビティを定義できます。 アクティビティには、主に次の 2 種類があります:実行アクティビティと制御アクティビティ。
実行アクティビティ
実行アクティビティには、データ移動アクティビティとデータ変換アクティビティが含まれます。 これらのアクティビティには、次のような最上位構造があります。
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
アクティビティの JSON 定義内のプロパティを次の表で説明します。
| タグ | 説明 | 必須 |
|---|---|---|
| name | アクティビティの名前。 アクティビティが実行するアクションを表す名前を指定します。
|
はい |
| description | アクティビティの用途を説明するテキスト。 | はい |
| type | アクティビティの種類。 各種のアクティビティについては、データ移動アクティビティ、データ変換アクティビティ、制御アクティビティに関するセクションを参照してください。 | はい |
| linkedServiceName | アクティビティで使用される、リンクされたサービスの名前。 アクティビティでは、必要なコンピューティング環境にリンクする、リンクされたサービスの指定が必要な場合があります。 |
HDInsight アクティビティ、ML スタジオ (クラシック) バッチ スコアリング アクティビティ、ストアド プロシージャ アクティビティの場合は "はい"。 それ以外の場合は "いいえ" |
| typeProperties | typeProperties セクションのプロパティは、アクティビティの種類に応じて異なります。 アクティビティの typeProperties を確認するには、前のセクションでアクティビティのリンクを選択します。 | いいえ |
| policy | アクティビティの実行時の動作に影響するポリシーです。 このプロパティには、タイムアウトと再試行の動作が含まれます。 指定されていない場合は、既定値が使用されます。 詳細については、「アクティビティ ポリシー」のセクションを参照してください。 | いいえ |
| dependsOn | このプロパティを使用して、アクティビティの依存関係と、後続のアクティビティが前のアクティビティにどのように依存するかを定義します。 詳細については、「アクティビティの依存関係」を参照してください | いいえ |
アクティビティ ポリシー
ポリシーはアクティビティの実行時の動作に影響し、構成のオプションが得られます。 アクティビティ ポリシーは実行アクティビティ専用です。
アクティビティ ポリシー JSON 定義
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| JSON での名前 | 説明 | 使用できる値 | 必須 |
|---|---|---|---|
| タイムアウト | アクティビティの実行に関するタイムアウトを指定します。 | Timespan | いいえ。 既定のタイムアウトは 12 時間 (最短で 10 分) です。 |
| retry | 最大再試行回数 | Integer | いいえ。 既定値は 0 です |
| retryIntervalInSeconds | 再試行の間の遅延 (秒単位) | Integer | いいえ。 既定値は 30 秒です |
| secureOutput | true に設定すると、アクティビティからの出力が安全と見なされ、監視用にログが記録されません。 | Boolean | いいえ。 既定値は false です。 |
制御アクティビティ
制御アクティビティには、次のような最上位構造があります。
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| タグ | 説明 | 必須 |
|---|---|---|
| name | アクティビティの名前。 アクティビティが実行するアクションを表す名前を指定します。
|
はい |
| description | アクティビティの用途を説明するテキスト。 | はい |
| type | アクティビティの種類。 各種のアクティビティについては、データ移動アクティビティ、データ変換アクティビティ、制御アクティビティに関するセクションを参照してください。 | はい |
| typeProperties | typeProperties セクションのプロパティは、アクティビティの種類に応じて異なります。 アクティビティの typeProperties を確認するには、前のセクションでアクティビティのリンクを選択します。 | いいえ |
| dependsOn | このプロパティを使用して、アクティビティの依存関係と、後続のアクティビティが前のアクティビティにどのように依存するかを定義します。 詳細については、「アクティビティの依存関係」を参照してください。 | いいえ |
アクティビティの依存関係
アクティビティの依存関係では、後続のアクティビティが前のアクティビティにどのように依存するかを定義するので、次のタスクの実行を続行するかどうかの条件を決めることができます。 さまざまな依存関係の条件を使用して、1 つのアクティビティを 1 つ以上の前のアクティビティに依存させることができます。
依存関係の条件には次のものがあります:Succeeded、Failed、Skipped、Completed。
たとえば、パイプラインに Activity A -> Activity B がある場合、次のようなさまざまなシナリオが考えられます。
- Activity B が Activity A に対する succeeded の依存関係の条件を持つ場合:Activity A の最終的な状態が succeeded の場合にのみ Activity B が実行されます
- Activity B が Activity A に対する failed の依存関係の条件を持つ場合:Activity A の最終的な状態が failed の場合にのみ Activity B が実行されます
- Activity B が Activity A に対する completed の依存関係の条件を持つ場合:Activity A の最終的な状態が succeeded か failed の場合に Activity B が実行されます
- Activity B が Activity A に対する skipped の依存関係の条件を持つ場合:Activity A の最終的な状態が skipped の場合に Activity B が実行されます。 Activity X -> Activity Y -> Activity Z のシナリオで、各アクティビティが前のアクティビティが成功した場合のみ実行される場合、skipped が発生します。 Activity X が失敗した場合、Activity Y が実行されることはないので、Activity Y の状態は "Skipped" になります。 同様に、Activity Z の状態も "Skipped" になります。
例:Activity 2 は Activity 1 の成功に依存している
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
コピー パイプラインのサンプル
次のサンプル パイプラインでは、[アクティビティ] セクションに、Copy 種類のアクティビティが 1 つあります。 このサンプルでは、コピー アクティビティによって、Azure BLOB Storage から Azure SQL Database 内のデータベースにデータをコピーします。
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
以下の点に注意してください。
- [アクティビティ] セクションに、種類 が Copy に設定されたアクティビティが 1 つだけあります。
- アクティビティの入力を InputDataset に設定し、出力を OutputDataset に設定します。 JSON でのデータセットの定義の詳細については、データセットに関する記事を参照してください。
- typeProperties セクションでは、ソースの種類として BlobSource が指定され、シンクの種類として SqlSink が指定されています。 データ ストアとの間でのデータの移動については、[データ移動アクティビティ] セクションで、ソースまたはシンクとして使用するデータ ストアを選択します。
このパイプラインの作成に関する完全なチュートリアルについては、クイックスタート: データ ファクトリの作成に関するページを参照してください。
変換パイプラインのサンプル
次のサンプル パイプラインでは、[アクティビティ] セクションに、HDInsightHive 種類のアクティビティが 1 つあります。 このサンプルでは、 HDInsight Hive アクティビティ が、Azure HDInsight Hadoop クラスターで Hive スクリプト ファイルを実行して、Azure BLOB ストレージからデータを変換します。
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
以下の点に注意してください。
- [アクティビティ] セクションに、種類 が HDInsightHive に設定されたアクティビティが 1 つだけあります。
- Hive スクリプト ファイル partitionweblogs.hql は、Azure Storage アカウント (scriptLinkedService によって指定され、AzureStorageLinkedService という名前) と
adfgetstartedコンテナーの script フォルダーに格納されます。 -
definesセクションは、Hive 構成値 (例: ${hiveconf:inputtable},${hiveconf:partitionedtable}) として Hive スクリプトに渡される実行時設定を指定するために使用されます。
typeProperties セクションは、変換アクティビティごとに異なります。 変換アクティビティでサポートされる typeProperties については、データ変換アクティビティで変換アクティビティを選択します。
このパイプライン作成の完全なチュートリアルについては、「Tutorial: transform data using Spark (チュートリアル: Spark を使用してデータを変換する)」を参照してください。
パイプライン内の複数アクティビティ
前の 2 つのサンプル パプラインには 1 つのアクティビティしか含まれていません。 パイプラインに複数のアクティビティを含めることができます。 1 つのパイプラインに複数のアクティビティがあり、後続のアクティビティが前のアクティビティに依存していない場合、これらのアクティビティは並列に実行されることもあります。
アクティビティの依存関係を使用して、2 つのアクティビティを連鎖させることができます。アクティビティの依存関係は、後続のアクティビティが前のアクティビティにどのように依存するかを定義するので、次のタスクの実行を続行するかどうかの条件を決めることができます。 さまざまな依存関係の条件を使用して、1 つのアクティビティを 1 つ以上の前のアクティビティに依存させることができます。
パイプラインのスケジュール設定
パイプラインは、トリガーによってスケジュール設定されます。 さまざまな種類のトリガーがあります (実時間のスケジュールでパイプラインをトリガーできるスケジューラ トリガーや、オンデマンドでパイプラインをトリガーする手動トリガー)。 トリガーの詳細については、パイプラインの実行とトリガーに関する記事を参照してください。
トリガーにパイプライン実行を開始させるには、特定のパイプラインのパイプライン参照をトリガー定義に組み込む必要があります。 パイプラインとトリガーには n-m の関係があります。 複数のトリガーで 1 つのパイプラインを開始したり、1 つのトリガーで複数のパイプラインを開始したりできます。 トリガーを定義し終えたらそのトリガーを開始して、パイプラインのトリガーを開始させる必要があります。 トリガーの詳細については、パイプラインの実行とトリガーに関する記事を参照してください。
たとえば、スケジューラ トリガー "Trigger A" があり、それによってパイプライン "MyCopyPipeline" を開始させるとします。次の例のようにこのトリガーを定義します。
Trigger A の定義
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}