Delta Live Tables のパイプライン設定を構成する
この記事では、Delta Live Tables のパイプライン設定の構成について詳しくご説明します。 Delta Live Tables には、パイプライン設定を構成および編集するためのユーザー インターフェイスが用意されています。 UI には、JSON で設定を表示および編集するためのオプションも用意されています。
Note
ほとんどの設定は、UI または JSON 仕様を使用して構成できます。 一部の詳細オプションは、JSON 構成を使用してのみ使用できます。
Databricks では、UI を使用して Delta Live Tables の設定について理解することをお勧めします。 必要に応じて、ワークスペースで JSON 構成を直接編集できます。 JSON 構成ファイルは、新しい環境にパイプラインをデプロイする場合や、CLI または REST API を使用する場合にも役立ちます。
Delta Live Tables JSON 構成設定の完全なリファレンスについては、「Delta Live Tables パイプラインの構成」をご覧ください。
Note
- サーバーレス DLT パイプライン(パブリック プレビュー) の場合、コンピューティング リソースはフル マネージドであるため、パイプラインに対して [サーバーレス] (パブリック プレビュー) を選択した場合、拡張自動スケール、クラスター ポリシー、インスタンスの種類、クラスター タグなどのコンピューティング設定は使用できません。
- パイプラインの JSON 構成内の
clustersオブジェクトにコンピューティング設定を手動で追加することはできません。これを試みるとエラーが発生します。
サーバーレス DLT パイプラインを有効にする方法については、Azure Databricks アカウント チームにお問い合わせください。
製品エディションの選択
お客様のパイプライン要件に最適な機能を備えた Delta Live Tables 製品エディションを選択してください。 次の製品エディションを利用できます。
Coreストリーミング取り込みワークロードを実行します。 変更データ キャプチャ (CDC) や Delta Live Tables の期待値などの高度な機能がパイプラインに必要ない場合は、Coreエディションを選択します。Proストリーミング取り込みと CDC のワークロードを実行します。Pro製品エディションでは、すべてのCore機能がサポートされているほか、ソース データの変更に基づいてテーブルを更新する必要があるワークロードもサポートされています。Advancedを使用して、ストリーミング取り込みワークロード、CDC ワークロード、期待値を必要とするワークロードを実行できます。Advanced製品エディションでは、CoreとProのエディションの機能がサポートされていて、Delta Live Tables の期待値を使用したデータ品質制約の適用もサポートされています。
パイプラインを作成または編集する場合は、製品エディションを選択できます。 パイプラインごとに異なるエディションを選択できます。 Delta Live Tables 製品ページをご覧ください。
注意: 選択した製品エディションでサポートされていない機能 (期待値など) がパイプラインに含まれている場合は、エラーの理由を説明するエラー メッセージが表示されます。 その後、パイプラインを編集して、適切なエディションを選択できます。
パイプライン モードを選択する
パイプラインは、継続的に更新することも、パイプライン モードに基づいて手動トリガーを使用して更新することもできます。 「継続的なパイプライン実行とトリガーされたパイプラインの実行」をご覧ください。
クラスター ポリシーの選択
Delta Live Tables パイプラインを構成および更新するには、コンピューティングをデプロイするためのアクセス許可がユーザーに必要です。 ワークスペース管理者は、Delta Live Tables のコンピューティング リソースへのアクセス権をユーザーに提供するようにクラスター ポリシーを構成できます。 「Delta Live Tables パイプライン コンピューティングの制限を定義する」をご覧ください。
Note
クラスター ポリシーは省略可能です。 Delta Live Tables に必要なコンピューティング特権がない場合は、ワークスペース管理者に確認してください。
クラスター ポリシーの既定値が正しく適用されるようにするには、パイプライン構成のクラスター構成で
apply_policy_default_values値をtrueに設定 します。{ "clusters": [ { "label": "default", "policy_id": "<policy-id>", "apply_policy_default_values": true } ] }
ソース コード ライブラリを構成する
Delta Live Tables UI のファイル セレクターを使用して、パイプラインを定義するソース コードを構成できます。 パイプライン ソース コードは、Databricks ノートブック、またはワークスペース ファイルに格納されている SQL または Python スクリプトで定義されます。 パイプラインを作成または編集するときに、1 つ以上のノートブックまたはワークスペース ファイル、またはノートブックとワークスペース ファイルの組み合わせを追加できます。
Delta Live Tables ではデータセットの依存関係が自動的に分析され、パイプラインの処理グラフが作成されます。このため、ソース コード ライブラリは任意の順序で追加できます。
また、JSON ファイルを変更して、ワークスペース ファイルに格納されている SQL および Python スクリプトで定義されている Delta Live Tables ソース コードを含めることもできます。 次の例には、ノートブックとワークスペース ファイルが含まれています。
{
"name": "Example pipeline 3",
"storage": "dbfs:/pipeline-examples/storage-location/example3",
"libraries": [
{ "notebook": { "path": "/example-notebook_1" } },
{ "notebook": { "path": "/example-notebook_2" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.sql" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.py" } }
]
}
ストレージの場所を指定する
Hive メタストアに発行するパイプラインのストレージの場所を指定できます。 場所を指定する主な動機は、パイプラインによって書き込まれるデータのオブジェクトストレージの場所を制御することです。
Delta Live Tables パイプラインのすべてのテーブル、データ、チェックポイント、メタデータは Delta Live Tables によって完全に管理されるため、Delta Live Tables データセットとのほとんどの対話は、Hive メタストアまたは Unity カタログに登録されたテーブルを介して行われます。
パイプライン出力テーブルのターゲット スキーマを指定する
省略可能ですが、新しいパイプラインの開発とテスト以外に移動するたびに、パイプラインによって作成されたテーブルを発行するターゲットを指定する必要があります。 パイプラインをターゲットに発行すると、Azure Databricks 環境の他の場所でクエリを実行するためにデータセットを使用できるようになります。 Delta Live Tables から Hive メタストアへのデータの発行に関する記事、または「Unity Catalog を Delta Live Tables パイプラインで使う」を参照してください。
コンピューティング設定を構成する
Note
サーバーレス DLT パイプライン (パブリック プレビュー) の場合、コンピューティング リソースはフル マネージドであるため、パイプラインに対して [サーバーレス] を選択した場合、コンピューティング設定は使用できません。
各 Delta Live Tables パイプラインには、次の 2 つのクラスターが関連付けられています:
updatesクラスターはパイプラインの 更新を処理します。maintenanceクラスターは毎日のメンテナンス タスクを実行します。
これらのクラスターで使用される構成は、パイプライン設定で指定された clusters 属性によって決まります。
クラスター ラベルを使用して、特定の種類のクラスターにのみ適用されるコンピューティング設定を追加できます。 パイプライン クラスターを構成するときに使用できるラベルは 3 つあります:
Note
クラスター構成を 1 つだけ定義する場合は、クラスター ラベルの設定を省略できます。 ラベルの設定が指定されていない場合、default ラベルはクラスター構成に適用されます。 クラスター ラベルの設定は、さまざまなクラスターの種類の設定をカスタマイズする必要がある場合にのみ必要です。
defaultラベルは、updatesとmaintenanceクラスターの両方に適用するコンピューティング設定を定義します。 両方のクラスターに同じ設定を適用すると、必要な構成 (ストレージの場所のデータ アクセス資格情報など) がメンテナンス クラスターに確実に適用されるため、メンテナンス実行の信頼性が向上します。maintenanceラベルは、maintenanceクラスターだけに適用するコンピューティング設定を定義します。maintenanceラベルを使用して、defaultラベルによって構成された設定をオーバーライドすることもできます。updatesラベルは、updatesクラスターだけに適用する設定を定義します。updatesラベルを使用して、maintenanceクラスターに適用すべきではない設定を構成します。
default と updates ラベルを使用して定義された設定がマージされ、updates クラスターの最終的な構成が作成されます。 default と updates ラベルの両方を使用して同じ設定が定義されている場合、updates ラベルで定義された設定は default ラベルで定義された設定よりも優先されます。
次の例では、updates クラスターの構成にのみ追加される Spark 構成パラメーターを 定義します:
{
"clusters": [
{
"label": "default",
"autoscale": {
"min_workers": 1,
"max_workers": 5,
"mode": "ENHANCED"
}
},
{
"label": "updates",
"spark_conf": {
"key": "value"
}
}
]
}
Delta Live Tables には、Azure Databricks の他のコンピューティングと同様のクラスター設定オプションが用意されています。 他のパイプライン設定と同様に、クラスターの JSON 構成を変更して、UI に存在しないオプションを指定できます。 「コンピューティング」を参照してください。
Note
- Delta Live Tables ランタイムはパイプライン クラスターのライフサイクルを管理し、Databricks Runtime のカスタム バージョンを実行するため、Spark のバージョンやクラスター名など、パイプライン構成で一部のクラスター設定を手動で設定することはできません。 「ユーザーが設定できないクラスター属性」をご覧ください。
- Photon を利用するように Delta Live Tables パイプラインを構成できます。 「Photon とは」を参照してください。
パイプラインを実行するインスタンスの種類を選択する
既定では、Delta Live Tables では、パイプラインを実行するドライバー ノードとワーカー ノードのインスタンスの種類が選択されますが、インスタンスの種類を手動で構成することもできます。 たとえば、インスタンスの種類を選択してパイプラインのパフォーマンスを向上させたり、パイプラインの実行時にメモリの問題に対処したりできます。 REST API を使用して、または Delta Live Tables UI でパイプラインを 作成 または 編集 するとき、インスタンスの種類を設定できます。
Delta Live Tables UI でパイプラインを作成または編集するとき、インスタンスの種類を設定できます:
- [Settings] をクリックします。
- パイプライン設定の [詳細] セクションの [Worker の種類] と [ドライバーの種類] ドロップダウン メニューで、パイプラインのインスタンスの種類を選択します。
パイプラインの JSON 設定でインスタンスの種類を構成するには、[JSON] ボタンをクリックし、クラスター構成にインスタンスの種類の構成を入力します。
Note
不要なリソースを maintenance クラスターに割り当てないように、この例では updates ラベルを使用して、updates クラスターのみのインスタンスの種類を設定します。 インスタンスの種類を updates クラスターと maintenance クラスターの両方に割り当てるには、default ラベルを使用するか、ラベルの設定を省略します。 ラベルの設定が指定されていない場合、default ラベルはパイプライン クラスター構成に適用されます。 「コンピューティング設定を構成する」をご覧ください。
{
"clusters": [
{
"label": "updates",
"node_type_id": "Standard_D12_v2",
"driver_node_type_id": "Standard_D3_v2",
"..." : "..."
}
]
}
自動スケーリングを使用して効率を高め、リソースの使用量を削減する
拡張自動スケーリングを使用して、パイプラインのクラスター使用率を最適化します。 拡張自動スケーリングでさらなるリソースが追加されるのは、これらのリソースによってパイプラインの処理速度が向上するとシステムが判断した場合のみです。 リソースは不要になると解放され、すべてのパイプライン更新が完了するとすぐにクラスターがシャットダウンされます。
構成の詳細を含む拡張自動スケールについて詳しくは、「拡張自動スケールを使用して Delta Live Tables パイプラインのクラスター使用率を最適化する」を参照してください。
コンピューティングのシャットダウンを遅延する
Delta Live Tables クラスターは使用されていないときに自動的にシャットダウンするため、クラスター構成で autotermination_minutes を設定するクラスター ポリシーを参照するとエラーが発生します。 クラスターのシャットダウン動作を制御するには、開発または運用モードを使用するか、パイプライン構成で pipelines.clusterShutdown.delay 設定を使用できます。 次の例では、pipelines.clusterShutdown.delay 値を 60 秒に設定します。
{
"configuration": {
"pipelines.clusterShutdown.delay": "60s"
}
}
production モードが有効な場合、pipelines.clusterShutdown.delay の規定値は 0 seconds です。 development モードが有効な場合、規定値は 2 hours です。
単一ノード クラスターを作成する
クラスター設定で num_workers を 0 に設定した場合は、クラスターが単一ノード クラスターとして作成されます。 自動スケール クラスターを構成し、min_workers と max_workers をともに 0 に設定した場合も、単一ノード クラスターが作成されます。
自動スケール クラスターを構成し、min_workers のみを 0 に設定した場合は、クラスターが単一ノード クラスターとして作成されません。 このクラスターには、終了するまで常に 1 つ以上のアクティブなワーカーがあります。
Delta Live Tables で単一ノード クラスターを作成するクラスター構成の例を次に示します。
{
"clusters": [
{
"num_workers": 0
}
]
}
クラスター タグの構成
クラスター タグを使用して、パイプライン クラスターの使用状況を監視できます。 パイプラインを作成または編集するとき、またはパイプライン クラスターの JSON 設定を編集して、Delta Live Tables UI にクラスター タグを追加します。
クラウド ストレージの構成
Azure ストレージにアクセスするには、クラスター構成の spark.conf 設定を使用して、アクセス トークンなどの必要なパラメーターを構成する必要があります。 Azure Data Lake Storage Gen2 (ADLS Gen2) ストレージ アカウントへのアクセスを構成する例については、「パイプラインでシークレットを使用してストレージの資格情報に安全にアクセスする」をご覧ください。
Python または SQL でデータセット宣言をパラメーター化する
データセットを定義する Python と SQL コードは、パイプラインの設定によってパラメーター化できます。 パラメーター化により、次のユース ケースが可能になります。
- コードから長いパスや他の変数を分離します。
- テストを高速化するために、開発またはステージング環境で処理されるデータの量を減らします。
- 同じ変換ロジックを再利用して、複数のデータ ソースから処理します。
次の例では、構成値 startDate を使用して、開発パイプラインを入力データのサブセットに制限します。
CREATE OR REFRESH LIVE TABLE customer_events
AS SELECT * FROM sourceTable WHERE date > '${mypipeline.startDate}';
@dlt.table
def customer_events():
start_date = spark.conf.get("mypipeline.startDate")
return read("sourceTable").where(col("date") > start_date)
{
"name": "Data Ingest - DEV",
"configuration": {
"mypipeline.startDate": "2021-01-02"
}
}
{
"name": "Data Ingest - PROD",
"configuration": {
"mypipeline.startDate": "2010-01-02"
}
}
パイプライン トリガーの間隔
pipelines.trigger.interval を使用してテーブルまたはパイプライン全体を更新するフローのトリガー間隔を制御できます。 トリガーされたパイプラインは各テーブルを 1 回だけ処理するため、pipelines.trigger.interval は連続パイプラインでのみ使用されます。
Databricks では、ストリーミング クエリとバッチ クエリの既定値が異なるため、個々のテーブルに pipelines.trigger.interval を設定することをお勧めします。 処理でパイプライングラフ全体の更新を制御する必要がある場合にのみ、パイプラインに値を設定します。
Python で spark_conf または SQL で SET を使用してテーブルに pipelines.trigger.interval を設定します。
@dlt.table(
spark_conf={"pipelines.trigger.interval" : "10 seconds"}
)
def <function-name>():
return (<query>)
SET pipelines.trigger.interval=10 seconds;
CREATE OR REFRESH LIVE TABLE TABLE_NAME
AS SELECT ...
パイプラインに pipelines.trigger.interval を設定するには、パイプライン設定でそれを configuration オブジェクトに追加します。
{
"configuration": {
"pipelines.trigger.interval": "10 seconds"
}
}
管理者以外のユーザーが Unity Catalog 対応パイプラインからドライバー ログを表示できるようにする
既定では、Unity Catalog 対応パイプラインを実行するクラスターからのドライバー ログを表示するアクセス許可を持つのは、パイプライン所有者とワークスペース管理者だけです。 パイプライン設定の configuration オブジェクトに次の Spark 構成パラメーターを追加することで、管理可能、表示可能、または実行可能のアクセス許可を持つユーザーのドライバー ログへのアクセスを有効にすることができます。
{
"configuration": {
"spark.databricks.acl.needAdminPermissionToViewLogs": "false"
}
}
パイプライン イベントの通知を追加する
次の場合に通知を受信するように 1 つ以上のメール アドレスを構成できます:
- パイプラインの更新が正常に完了しました。
- パイプラインの更新は、再試行可能または再試行不可能なエラーで失敗します。 すべてのパイプラインの失敗について通知を受け取るには、このオプションを選択します。
- パイプラインの更新が失敗し、再試行できない (致命的な) エラーが発生します。 再試行不可能なエラーが発生した場合にのみ通知を受け取るには、このオプションを選択します。
- 1 つのデータ フローが失敗します。
パイプラインを 作成 または編集するときに電子メール通知を構成するには:
- [通知の追加] をクリックします。
- 通知を受信する 1 つ以上のメール アドレスを入力します。
- 構成されたメール アドレスに送信する通知の種類ごとに、チェック ボックス をクリックします。
- [通知の追加] をクリックします。
SCD タイプ 1 クエリの廃棄標識の管理を制御する
次の設定を使用して、SCD タイプ 1 の処理中の DELETE イベントの廃棄標識管理の動作を制御できます。
pipelines.applyChanges.tombstoneGCThresholdInSeconds: この値を、順序が正しくないデータ間の予想される最大間隔 (秒単位) に一致するように設定します。 既定値は 172,800 秒 (2 日) です。pipelines.applyChanges.tombstoneGCFrequencyInSeconds: この設定は、クリーンアップのために廃棄標識を確認する頻度を秒単位で制御します。 既定値は 1,800 秒 (30 分) です。
「APPLY CHANGES API: Delta Live Tables の変更データ キャプチャを簡略化する」を参照してください。
パイプラインのアクセス許可を構成する
パイプラインに対するアクセス許可を管理するには、それに対する CAN MANAGE または IS OWNER アクセス許可が必要です。
サイドバーで、[Delta Live Tables] をクリックします。
パイプラインの名前を選択します。
ケバブ メニュー
 をクリックして、[アクセス許可] を選びます。
をクリックして、[アクセス許可] を選びます。[アクセス許可の設定] で、[ユーザー、グループ、またはサービス プリンシパルの選択] ドロップダウン メニューを選択してから、ユーザー、グループ、またはサービス プリンシパルを選びます。
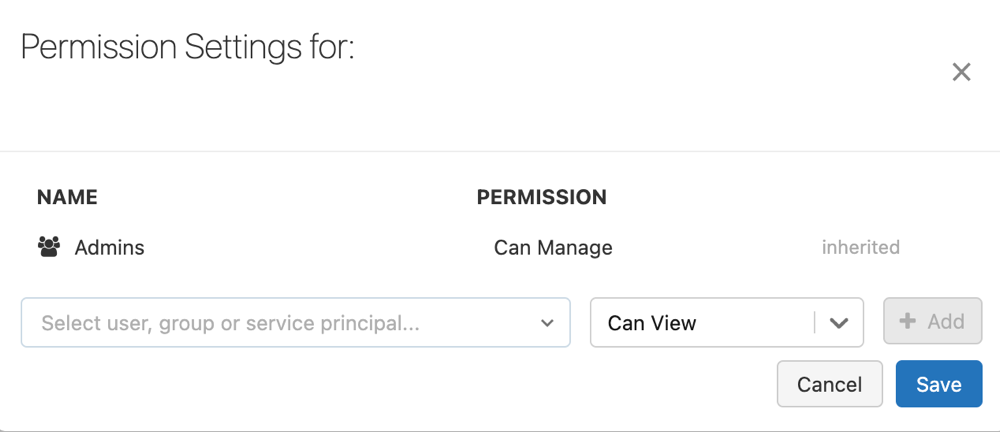
[アクセス許可] ドロップダウン メニューからアクセス許可を選択します。
[追加] をクリックします。
[保存] をクリックします。
Delta Live Tables の RocksDB 状態ストアを有効にする
パイプラインをデプロイする前に次の構成を設定することで、RocksDB ベースの状態管理を有効にすることができます。
{
"configuration": {
"spark.sql.streaming.stateStore.providerClass": "com.databricks.sql.streaming.state.RocksDBStateStoreProvider"
}
}
RocksDB の構成に関する推奨事項など、RocksDB 状態ストアの詳細については、「Azure Databricks で RocksDB 状態ストアを構成する」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示