注
この記事では、Databricks Runtime 13.3 LTS 以降用の Databricks Connect について説明します。
Databricks Connect を使用すると、IntelliJ IDEA などの一般的な IDE、ノートブック サーバー、その他のカスタム アプリケーションを Azure Databricks クラスターに接続できます。 「Databricks Connect とは」を参照してください。
この記事では、IntelliJ IDEA と Scala プラグインを使用して、Databricks Connect for Scala をすぐに使い始める方法について説明します。
- この記事の Python バージョンについては、「Databricks Connect for Python」を参照してください。
- この記事の R バージョンについては、「Databricks Connect for R」を参照してください。
チュートリアル
次のチュートリアルでは、IntelliJ IDEA でプロジェクトを作成し、Databricks Connect for Databricks Runtime 13.3 LTS 以降をインストールし、IntelliJ IDEA から Databricks ワークスペースのコンピューティングで単純なコードを実行します。 詳細と例については、「次の手順を参照してください。
必要条件
このチュートリアルを完了するには、次の要件を満たす必要があります。
ターゲットの Azure Databricks ワークスペースとクラスターは、 Databricks Connect のコンピューティング要件を満たしている必要があります。
クラスター ID を使用できる必要があります。 クラスター ID を取得するには、ワークスペースでサイドバーの [コンピューティング ] をクリックし、クラスターの名前をクリックします。 Web ブラウザーのアドレス バーで、URL の
clustersとconfigurationの間で文字の文字列をコピーします。ローカル環境とコンピューティングは、Databricks Connect for Scala のインストール バージョンの要件を満たしています。
開発マシンに Java Development Kit (JDK) がインストールされている。 Databricks では、JDK インストールのバージョンが Azure Databricks クラスターの JDK バージョンと一致することを推奨します。 クラスター上の Databricks Runtime の JDK バージョンを確認するには、Databricks Runtime リリース ノートまたはバージョン サポート マトリックスのシステム環境セクションを参照してください。
注
JDK がインストールされていない場合、または開発用マシンに複数の JDK がインストールされている場合は、後の手順 1 で特定の JDK をインストールまたは選択できます。 クラスターの JDK バージョンより下または上の JDK インストールを選択すると、予期しない結果が発生したり、コードがまったく実行されない可能性があります。
IntelliJ IDEA がインストールされている。 このチュートリアルは、IntelliJ IDEA Community Edition 2023.3.6 でテストされました。 別のバージョンまたはエディションの IntelliJ IDEA を使用する場合、次の手順は異なる場合があります。
IntelliJ IDEA 用の Scala プラグインがインストールされている。。
手順 1: Azure Databricks 認証を構成する
このチュートリアルでは、Azure Databricks OAuth ユーザー対マシン (U2M) 認証と Azure Databricks 構成プロファイルを使用しており、Azure Databricks ワークスペースを使用して認証します。 代わりに別の認証の種類を使うには、「接続プロパティの構成」をご覧ください。
OAuth U2M 認証を構成するには、次のように Databricks CLI が必要です。
Databricks CLI がまだインストールされていない場合は、次のようにしてインストールします。
Linux、macOS
Homebrew を使用し、次の 2 つのコマンドを実行して Databricks CLI をインストールします。
brew tap databricks/tap brew install databricksウィンドウズ
winget、Chocolatey または Linux 用 Windows サブシステム (WSL) を使用して、Databricks CLI をインストールできます。
winget、Chocolatey、WSL を使えない場合は、この手順をスキップし、代わりにコマンド プロンプトまたは PowerShell を使ってソースから Databricks CLI をインストールする必要があります。注
Chocolatey を使用した Databricks CLI のインストールは、試験段階です。
wingetを使用して Databricks CLI をインストールするには、次の 2 つのコマンドを実行し、コマンド プロンプトを再起動してください。winget search databricks winget install Databricks.DatabricksCLIChocolatey を使用して Databricks CLI をインストールするには、次のコマンドを実行します。
choco install databricks-cliWSL を使って Databricks CLI をインストールするには、次のようにします。
WSL を使用して
curlとzipをインストールします。 詳細については、オペレーティング システムのドキュメントを参照してください。WSL を使用して、次のコマンドを実行して Databricks CLI をインストールしてください。
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
次のコマンドを実行して、Databricks CLI がインストールされていることを確認します。これにより、インストールされている Databricks CLI の現在のバージョンが表示されます。 このバージョンは 0.205.0 以降である必要があります。
databricks -v注
databricksを実行してもcommand not found: databricksなどの エラーが発生する場合、またはdatabricks -vを実行するとバージョン番号 0.18 以下が表示される場合は、お使いのマシンで正しいバージョンの Databricks CLI 実行可能ファイルが見つからないことを意味します。 これを修正するには、「CLI のインストールを確認する」を参照してください。
次のように OAuth U2M 認証を開始します。
Databricks CLI を使用して、ターゲット ワークスペースごとに次のコマンドを実行して、OAuth トークン管理をローカルで開始します。
次のコマンド内では、
<workspace-url>を Azure Databricks ワークスペース単位の URL (例:https://adb-1234567890123456.7.azuredatabricks.net) に置き換えます。databricks auth login --configure-cluster --host <workspace-url>Databricks CLI では、入力した情報を Azure Databricks 構成プロファイルとして保存するように求められます。
Enterキーを押して提案されたプロファイル名を受け入れるか、新規または既存のプロファイル名を入力します。 同じ名前の既存のプロファイルは、入力した情報で上書きされます。 プロファイルを使用すると、複数のワークスペース間で認証コンテキストをすばやく切り替えることができます。既存のプロファイルの一覧を取得するには、別のターミナルまたはコマンド プロンプト内で、Databricks CLI を使用してコマンド
databricks auth profilesを実行します。 特定のプロファイルの既存の設定を表示するには、コマンドdatabricks auth env --profile <profile-name>を実行します。Web ブラウザーで、画面の指示に従って Azure Databricks ワークスペースにログインします。
ターミナルまたはコマンド プロンプトに表示される使用可能なクラスターのリストで、上下の方向キーを使ってワークスペース内のターゲット Azure Databricks クラスターを選び、
Enterキーを押します。 クラスターの表示名の任意の部分を入力して、使用可能なクラスターの一覧をフィルター処理することもできます。プロファイルの現在の OAuth トークン値とトークンの今後の有効期限のタイムスタンプを表示するには、次のいずれかのコマンドを実行します。
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
同じ
--host値を持つ複数のプロファイルがある場合は、Databricks CLI が正しく一致する OAuth トークン情報を見つけるのに役立つ--hostと-pのオプションを一緒に指定することが必要になる場合があります。
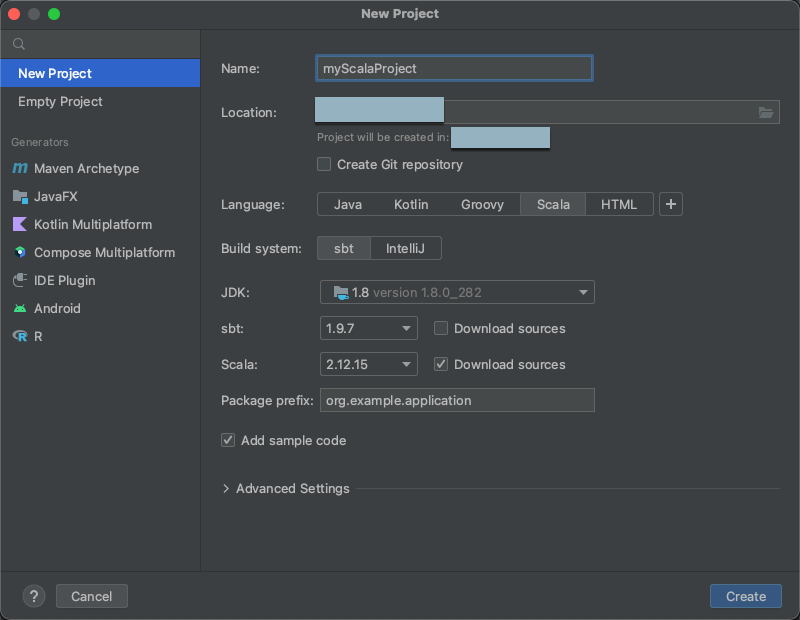
手順 2: プロジェクトを作成する
IntelliJ IDEA を開始します。
メイン メニューで、[ファイル]>[新規]>[プロジェクト] の順にクリックします。
プロジェクトにわかりやすい名前を付けてください。
[場所] では、フォルダー アイコンをクリックし、画面上の指示を完了して、新しい Scala プロジェクトへのパスを指定してください。
[言語] では、[Scala] をクリックしてください。
[ビルド システム] では、[sbt] をクリックしてください。
[JDK] ドロップダウン リストで、クラスターの JDK バージョンと一致する開発マシンの JDK の既存のインストールを選択するか、[JDK のダウンロード] を選択し、画面上の指示に従って、クラスターの JDK のバージョンに一致する JDK をダウンロードしてください。 要件を参照してください。
注
クラスターの JDK バージョンより上または下の JDK インストールを選択すると、予期しない結果が発生したり、コードがまったく実行されないおそれがあります。
[sbt] ドロップダウン リストで、最新バージョンを選択してください。
[Scala] ドロップダウン リストで、クラスターの Scala バージョンと一致する Scala のバージョンを選択します。 要件を参照してください。
注
クラスターの Scala バージョンより下または上の Scala バージョンを選択すると、予期しない結果が発生したり、コードがまったく実行されない可能性があります。
[Scala] の横にある [ソースのダウンロード] ボックスにチェックが入っていることを確認します。
[ パッケージ プレフィックス] に、プロジェクトのソースのパッケージ プレフィックス値を入力します (例:
org.example.application)。[サンプル コードの追加] ボックスにチェックが入っていることを確認してください。
Create をクリックしてください。
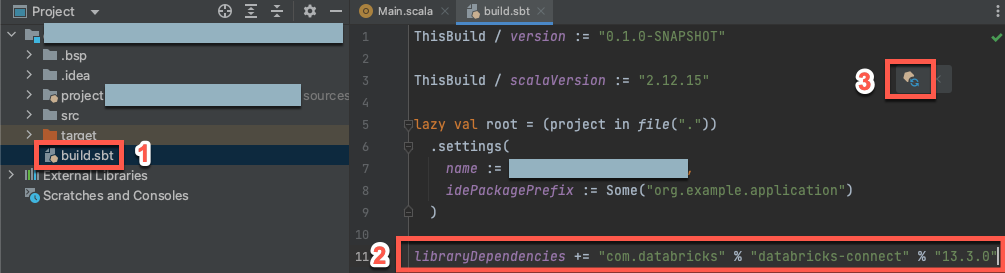
手順 3: Databricks Connect パッケージを追加する
新しい Scala プロジェクトを開いた状態で、[プロジェクト] ツール ウィンドウ ([表示] > [ツール ウィンドウ] > [プロジェクト]) で、
build.sbtという名前のファイルを、project-name> target で開きます。次のコードを
build.sbtファイルの末尾に追加します。このファイルは、クラスターの Databricks Runtime バージョンと互換性のある Scala 用 Databricks Connect ライブラリの特定のバージョンに対するプロジェクトの依存関係を宣言します。libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"14.3.1を、クラスターの Databricks Runtime バージョンと一致する Databricks Connect ライブラリのバージョンに置き換えてください。 たとえば、Databricks Connect 14.3.1 は Databricks Runtime 14.3 LTS と一致します。 Databricks Connect ライブラリのバージョン番号は、Maven 中央リポジトリで確認できます。[sbt の変更の読み込み] 通知アイコンをクリックして、Scala プロジェクトを新しいライブラリの場所と依存関係で更新してください。
IDE の下部にある
sbt進行状況インジケーターが消えるまで待ちます。sbt読み込みプロセスの完了には、数分かかる場合があります。
手順 4: コードを追加する
[プロジェクト] ツール ウィンドウで、
Main.scalaの中にある という名前のファイルを開きます。構成プロファイルの名前に応じて、ファイル内の既存のコードを次のコードで置き換え、ファイルを保存します。
手順 1 の構成プロファイルの名前が
DEFAULTの場合は、ファイル内の既存のコードを次のコードで置き換え、ファイルを保存します。package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }手順 1 の構成プロファイルの名前が
DEFAULTでない場合は、代わりにファイル内の既存のコードを次のコードで置き換えます。 プレースホルダー<profile-name>を手順 1 の構成プロファイルの名前に置き換えて、ファイルを保存します。package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
手順 5: コードを実行する
- リモートの Azure Databricks ワークスペースでターゲット クラスターを開始します。
- クラスターが起動したら、メイン メニューの [実行] > [メイン] をクリックします。
-
[実行] ツール ウィンドウ ([表示] > [ツール ウィンドウ] > [実行]) の [メイン] タブに、
samples.nyctaxi.tripsテーブルの最初の 5 行が表示されます。
手順 6: コードをデバッグする
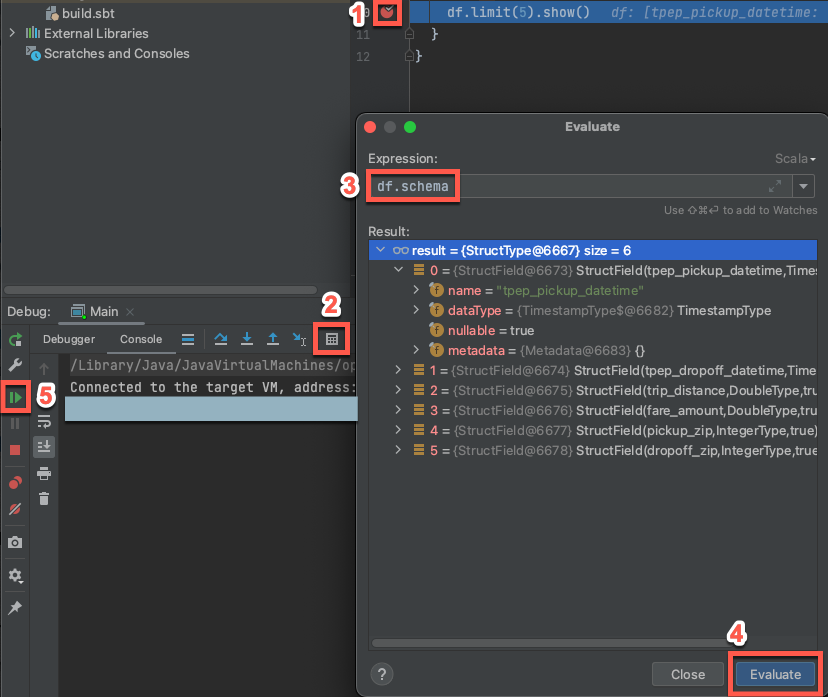
- ターゲット クラスターがまだ実行中の状態で、前述のコードで、
df.limit(5).show()の横にある余白をクリックしてブレークポイントを設定します。 - メイン メニューで、> をクリックします。
- [デバッグ] ツール ウィンドウ ([表示] > [ツール ウィンドウ] > [デバッグ]) の [コンソール] タブで、計算ツール ([式の評価]) アイコンをクリックします。
-
df.schema式を入力し、[評価] をクリックして DataFrame のスキーマを表示します。 - デバッグ ツール ウィンドウのサイドバーで、緑色の矢印 (プログラムの再開) アイコンをクリックします。
-
[コンソール] ペインに、
samples.nyctaxi.tripsテーブルの最初の 5 行が表示されます。
次のステップ
Databricks Connect の詳細については、次のような記事を参照してください。
- Azure Databricks 個人用アクセス トークン以外の種類の Azure Databricks 認証を使うには、「接続プロパティの構成」をご覧ください。
- その他の単純なコード例については、「Databricks Connect for Scala のコード例」を参照してください。
- より複雑なコード例を表示するには、GitHub の Databricks Connect リポジトリのサンプル アプリケーションを参照してください。具体的には、次を参照してください。
- Databricks Runtime 12.2 LTS 以下用の Databricks Connect から Databricks Runtime 13.3 LTS 以上用の Databricks Connect に移行するには、「Databricks Connect for Scala に移行する」を参照してください。
- トラブルシューティングと制限に関する情報も参照してください。