この記事では、 モザイク AI ベクター検索を使用してベクター検索エンドポイントとインデックスを作成する方法について説明します。
UI、Python SDK、または REST API を使用して、ベクター検索エンドポイントやベクター検索インデックスなどのベクター検索コンポーネントを作成および管理できます。
ベクター検索エンドポイントを作成してクエリを実行する方法を示すノートブックの例については、 ベクター検索のノートブックの例を参照してください。 リファレンス情報については、Python SDK リファレンスを参照してください。
Requirements
- Unity Catalog 対応ワークスペース。
- サーバーレス コンピューティングが有効になっている。 手順については、「サーバーレス コンピューティングに接続する」を参照してください。
- 標準エンドポイントの場合、ソース テーブルで Change Data Feed が有効になっている必要があります。 「Azure Databricks で Delta Lake 変更データ フィードを使用するを参照してください。」
- ベクター検索インデックスを作成するには、インデックスが作成されるカタログ スキーマに対する CREATE TABLE 権限が必要です。
- 別のユーザーが所有するインデックスに対してクエリを実行するには、追加の権限が必要です。 ベクター検索インデックスのクエリを実行する方法を参照してください。
ベクター検索エンドポイントを作成および管理するためのアクセス許可は、アクセス制御リストを使用して構成されます。 ベクター検索エンドポイント ACL を参照してください。
Installation
ベクター検索 SDK を使用するには、ノートブックにインストールする必要があります。 パッケージをインストールするには、次のコードを使用します。
%pip install databricks-vectorsearch
dbutils.library.restartPython()
次に、次のコマンドを使用して VectorSearchClientをインポートします。
from databricks.vector_search.client import VectorSearchClient
認証の詳細については、「 データ保護と認証」を参照してください。
ベクター検索エンドポイントを作成する
Databricks UI、Python SDK、または API を使用して、ベクター検索エンドポイントを作成できます。
UI を使用してベクター検索エンドポイントを作成する
UI を使用してベクター検索エンドポイントを作成するには、次の手順に従います。
左側のサイドバーで、[ コンピューティング] をクリックします。
[ ベクター検索 ] タブをクリックし、[ エンドポイントの作成] をクリックします。
[ エンドポイントの作成] フォーム が開きます。 このエンドポイントの名前を入力します。
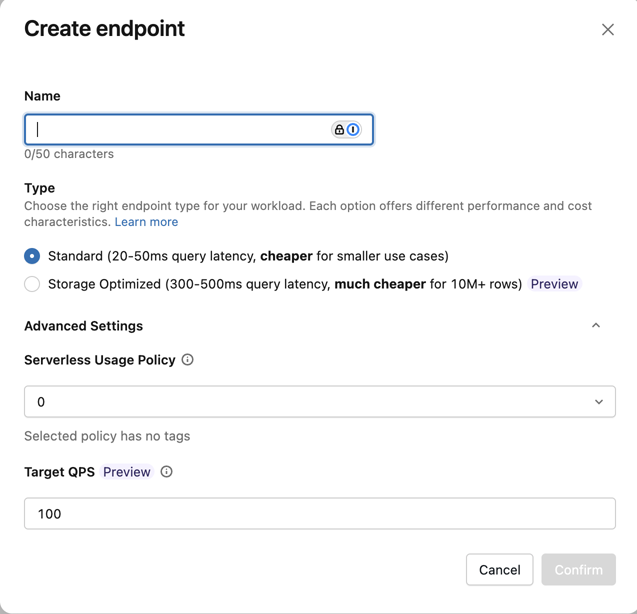
[ タイプ ] フィールドで、[ Standard ] または [ Storage Optimized] を選択します。 「エンドポイント オプション」を参照してください。
(省略可能)[ 詳細設定] で、予算ポリシーを選択します。 ベクター検索の予算ポリシーを参照してください。
[Confirm](確認) をクリックします。
Python SDK を使用してベクター検索エンドポイントを作成する
次の例では 、create_endpoint() SDK 関数を使用してベクター検索エンドポイントを作成します。
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
REST API を使用してベクター検索エンドポイントを作成する
REST API リファレンス ドキュメント POST /api/2.0/vector-search/endpoints を参照してください。
高スループットワークロード用の最小 QPS ターゲットを持つエンドポイントを作成する
Important
この機能は ベータ版です。 ワークスペース管理者は、[ プレビュー] ページからこの機能へのアクセスを制御できます。 Manage Azure Databricks プレビューを参照してください。
スループットの高いワークロードの場合は、最小 QPS ターゲットを使用してエンドポイントを作成できます。 この機能は、標準エンドポイントでのみ使用できます。
最小 QPS ターゲットを設定するには、 min_qps パラメーターを使用します。 QPS(ベータ)が高いエンドポイントのスループットをスケーリングする方法については、こちらを参照してください。
Important
min_qps設定すると、追加の容量がプロビジョニングされるため、エンドポイントのコストが増加します。 実際のクエリ トラフィックに関係なく、この追加容量に対して課金されます。 これらの料金の発生を停止するには、 min_qps=-1を使用してエンドポイントをリセットします。 スループットのスケーリングはベスト エフォートであり、ベータ期間中は保証されません。
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
min_qps=500, # Beta: minimum QPS target for high-throughput workloads
)
既存のエンドポイントで最小 QPS を変更するには、 update_endpoint()を使用します。
from databricks.vector_search.client import VectorSearchClient, MIN_QPS_RESET_TO_DEFAULT
client = VectorSearchClient()
# Set or update minimum QPS
response = client.update_endpoint(name="vector_search_endpoint_name", min_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
# Remove high QPS configuration and return to default
client.update_endpoint(name="vector_search_endpoint_name", min_qps=MIN_QPS_RESET_TO_DEFAULT)
最小 QPS を更新した後、インデックスを同期して新しい構成を適用します。
(省略可能)埋め込みモデルを提供するエンドポイントを作成して構成する
Databricks で埋め込みを計算するように選択した場合は、事前構成済みの Foundation Model API エンドポイントを使用するか、モデル サービス エンドポイントを作成して、任意の埋め込みモデルを提供できます。 手順については、トークンごとの支払い基盤モデル API またはエンドポイントを提供する基盤モデルの作成に関する記事を参照してください。 ノートブックの例については、 ベクター検索のノートブックの例を参照してください。
埋め込みエンドポイントを構成する場合、Databricks では、既定の [Scale to zero] の選択を外すことをお勧めします。 エンドポイントの提供にはウォームアップに数分かかる場合があり、スケールダウンされたエンドポイントを持つインデックスに対する最初のクエリがタイムアウトになる可能性があります。
注
埋め込みエンドポイントがデータセットに対して適切に構成されていない場合、ベクター検索インデックスの初期化がタイムアウトになる可能性があります。 CPU エンドポイントは、小規模なデータセットとテストにのみ使用する必要があります。 大規模なデータセットの場合は、最適なパフォーマンスを得るための GPU エンドポイントを使用します。
ベクター検索インデックスを作成する
ベクター検索インデックスは、UI、Python SDK、または REST API を使用して作成できます。 UI は最も簡単なアプローチです。
インデックスには次の 2 種類があります。
- 差分同期インデックス は、ソース差分テーブルと自動的に同期され、差分テーブルの基になるデータが変更されるとインデックスが自動的に増分更新されます。
- Direct Vector Access Index では、ベクトルとメタデータの直接読み取りと書き込みがサポートされます。 ユーザーは、REST API または Python SDK を使用してこのテーブルを更新する必要があります。 この種類のインデックスは、UI を使用して作成することはできません。 REST API または SDK を使用する必要があります。
差分同期インデックスは、以下の検索モードをサポートします。
-
ベクター検索 (ANN またはハイブリッド): 列を埋め込む必要があります。 Standard エンドポイントとストレージ最適化エンドポイントの両方をサポートします。
query_type="FULL_TEXT"を使用して、これらのインデックスのキーワード検索を行うこともできます。 - 専用フルテキスト検索インデックス (ベータ): キーワードのみの検索のために、列を埋め込まずに作成された差分同期インデックス。 トリガーされた同期モードを使用するストレージ最適化エンドポイントでのみ使用できます。 フルテキスト検索インデックスの作成を参照してください。
注
列名 _id は予約されています。 ソース テーブルに _id という名前の列がある場合は、ベクター検索インデックスを作成する前に名前を変更します。
UI を使用してインデックスを作成する
左側のサイドバーで、カタログ をクリックして、カタログエクスプローラー UI を開きます。
使用する Delta テーブルに移動します。
右上にある [ 作成 ] ボタンをクリックし、ドロップダウン メニューから ベクター検索インデックス を選択します。
![[インデックスの作成] ボタン](../_static/images/generative-ai/create-index-button.png)
ダイアログのセレクターを使用して、インデックスを構成します。
![[インデックスの作成] ダイアログ](../_static/images/generative-ai/create-index-form.png)
名前: Unity カタログのオンライン テーブルに使用する名前。 名前には、
<catalog>.<schema>.<name>3 レベルの名前空間が必要です。 英数字とアンダースコアのみを使用できます。主キー: 主キーとして使用する列。
同期する列: ベクター インデックスと同期する列を選択します。 このフィールドを空白のままにすると、ソース テーブルのすべての列がインデックスと同期されます。 主キー列と埋め込みソース列または埋め込みベクター列は常に同期されます。
埋め込みソース: Databricks で Delta テーブル内のテキスト列の埋め込みを計算するか (コンピューティング埋め込み)、または Delta テーブルに事前計算済みの埋め込み (既存の埋め込み列を使用) が含まれているかどうかを示します。
[コンピューティング埋め込み] を選択した場合は、埋め込みを計算する列と、計算に使用する埋め込みモデルを選択します。 テキスト列のみがサポートされています。
標準エンドポイントを使用する運用アプリケーションの場合、Databricks では、プロビジョニングされたスループット サービス エンドポイントで
databricks-gte-large-en基盤モデルを使用することをお勧めします。Databricks でホストされるモデルでストレージ最適化エンドポイントを使用する運用アプリケーションの場合は、埋め込みモデル エンドポイントとしてモデル名 (
databricks-gte-large-enなど) を直接使用します。 ストレージ最適化エンドポイントでは、インジェスト時にバッチ推論でai_queryが使用され、埋め込みジョブのスループットが高くなります。 プロビジョニングされたスループット エンドポイントをクエリに使用する場合は、インデックスの作成時にmodel_endpoint_name_for_queryフィールドで指定します。
[ 既存の埋め込み列を使用] を選択した場合は、事前計算済みの埋め込みと埋め込みディメンションを含む列を選択します。 事前計算済み埋め込み列の形式は
array[float]する必要があります。 ストレージ最適化エンドポイントの場合、埋め込みディメンションは 16 で均等に割り切れる必要があります。
計算された埋め込みの同期: 生成された埋め込みを Unity カタログ テーブルに保存するには、この設定を切り替えます。 詳細については、「 生成された埋め込みテーブルを保存する」を参照してください。
ベクター検索エンドポイント: インデックスを格納するベクター検索エンドポイントを選択します。
同期モード: 継続的に インデックスを秒単位の待機時間で同期します。 ただし、継続的同期ストリーミング パイプラインを実行するためにコンピューティング クラスターがプロビジョニングされるため、それに関連するコストは高くなります。
- 標準エンドポイントの場合、 継続的 更新と トリガー実行の 両方で増分更新が実行されるため、最後の同期以降に変更されたデータのみが処理されます。
- ストレージ最適化エンドポイントの場合、すべての同期によってインデックスが部分的に再構築されます。 後続の同期のマネージド インデックスの場合、ソース行が変更されていない生成された埋め込みはすべて再利用され、再計算する必要はありません。 ストレージ最適化エンドポイントの制限事項を参照してください。
Triggered 同期モードでは、Python SDK または REST API を使用して同期を開始します。「差分同期インデックスの更新を参照してください。
ストレージ最適化エンドポイントの場合、 トリガーされた 同期モードのみがサポートされます。
詳細設定: (省略可能)
インデックスに予算ポリシーを適用できます。 ベクター検索の予算ポリシーを参照してください。
[コンピューティング埋め込み] を選択した場合は、ベクター検索インデックスに対してクエリを実行する別の埋め込みモデルを指定できます。 これは、インジェストに高スループットのエンドポイントが必要だが、インデックスのクエリを実行するための待機時間の短いエンドポイントが必要な場合に便利です。 [埋め込みモデル] フィールドで指定されたモデルは、常にインジェストに使用され、ここで別のモデルを指定しない限り、クエリにも使用されます。 別のモデルを指定するには、[ インデックスのクエリを実行する別の埋め込みモデルの選択 ] をクリックし、ドロップダウン メニューからモデルを選択します。

インデックスの構成が完了したら、[ 作成] をクリックします。
Python SDK を使用してインデックスを作成する
次の例では、Databricks によって計算された埋め込みを使用して差分同期インデックスを作成します。 詳細については、Python SDK リファレンスを参照してください。
この例では、オプションのパラメーター model_endpoint_name_for_queryも示しています。これは、インデックスのクエリに使用するエンドポイントを提供する別の埋め込みモデルを指定します。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
次の例では、自己管理型埋め込みを使用して差分同期インデックスを作成します。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
既定では、ソース テーブルのすべての列がインデックスと同期されます。 同期する列のサブセットを選択するには、 columns_to_syncを使用します。 主キーと埋め込み列は常にインデックスに含まれます。
主キーと埋め込み列 のみを 同期するには、次のように columns_to_sync で指定する必要があります。
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
追加の列を同期するには、次のように指定します。 主キーと埋め込み列は常に同期されるため、含める必要はありません。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
フルテキスト検索インデックスの作成 (ベータ)
Important
フルテキスト検索インデックスの作成は、ストレージ最適化エンドポイントでのみベータ機能として使用できます。 これを使用するには、 vs_full_text ワークスペース プレビューを有効にする必要があります。 プレビューを有効にするには、アカウント チームに問い合わせるか、Manage Azure Databricks プレビューをご覧ください。
フルテキスト検索インデックスを使用すると、ベクター埋め込みを必要とせずに、テキスト列に対するキーワードベースの検索が可能になります。 これは、セマンティックの類似性ではなく、正確な用語、識別子、またはキーワードを検索する場合に便利です。
フルテキスト検索インデックスには、次の要件があります。
- ストレージ最適化エンドポイントを使用する必要があります。 標準エンドポイントはサポートされていません。
- トリガーされた同期モードを使用する必要があります。 継続的同期はサポートされていません。
- パラメーター
embedding_source_column、embedding_vector_column、embedding_dimensionはサポートされていません。
次の例では、Python SDK を使用してフルテキスト検索インデックスを作成します。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
インデックスを作成した後、同期処理をトリガーして投入します。
index.sync()
フルテキスト インデックスのクエリを実行するには、 query_type="FULL_TEXT"を使用します。 詳細については 、ベクター検索インデックスのクエリ を参照してください。
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
次の例では、Direct Vector Access インデックスを作成します。
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
REST API を使用してインデックスを作成する
REST API リファレンス ドキュメント POST /api/2.0/vector-search/indexes を参照してください。
生成された埋め込みテーブルを保存する
Databricks で埋め込みを生成する場合は、生成された埋め込みを Unity カタログのテーブルに保存できます。 このテーブルは、ベクター インデックスと同じスキーマで作成され、ベクター インデックス ページからリンクされます。
テーブルの名前は、ベクター検索インデックスの名前で、 _writeback_tableが追加されます。 名前は編集できません。
Unity カタログの他のテーブルと同様に、テーブルにアクセスしてクエリを実行できます。 ただし、手動で更新することを意図していないため、テーブルを削除または変更しないでください。 インデックスが削除されると、テーブルは自動的に削除されます。
ベクター検索インデックスを更新する
Delta 同期インデックスを更新する
継続的同期モードで作成されたインデックスは、ソース Delta テーブルが変更されると自動的に更新されます。 Triggered 同期モードを使用している場合は、UI、Python SDK、または REST API を使用して同期を開始できます。
Databricks ユーザーインターフェース
カタログ エクスプローラーで、ベクター検索インデックスに移動します。
[ 概要 ] タブの [ データ取り込み ] セクションで、[ 今すぐ同期] をクリックします。
![[今すぐ同期] ボタンをクリックして、カタログ エクスプローラーからベクター検索インデックスを同期します](../_static/images/generative-ai/sync-now.png) 。
。
Python SDK
詳細については、Python SDK リファレンスを参照してください。
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
REST API リファレンス ドキュメント POST /api/2.0/vector-search/indexes/{index_name}/sync を参照してください。
直接ベクター アクセス インデックスを更新する
Python SDK または REST API を使用して、直接ベクター アクセス インデックスのデータを挿入、更新、または削除できます。
Python SDK
詳細については、Python SDK リファレンスを参照してください。
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
REST API リファレンス ドキュメント POST /api/2.0/vector-search/indexes を参照してください。
運用アプリケーションの場合、Databricks では、個人用アクセス トークンではなくサービス プリンシパルを使用することをお勧めします。 クエリあたり最大 100 ミリ秒でパフォーマンスを向上させることができます。
次のコード例は、サービス プリンシパルを使用してインデックスを更新する方法を示しています。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
次のコード例は、個人用アクセス トークン (PAT) を使用してインデックスを更新する方法を示しています。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
ダウンタイムなしでスキーマを変更する方法
インデックスを再構築しない限り、ソース テーブルに対するスキーマの変更はサポートされません。 これには、既存の列の変更や新しい列の追加が含まれます。 インデックス スキーマは作成時に固定されるため、スキーマを変更する場合は、有効にするために新しいインデックスを作成する必要があります。
ダウンタイムなしでインデックスを再構築してデプロイするには、次の手順に従います。
- ソース テーブルでスキーマの変更を実行します。
- 更新されたスキーマを使用して新しいインデックスを作成します。
- 新しいインデックスの準備ができたら、トラフィックを新しいインデックスに切り替えます。
- 元のインデックスを削除します。