GenAI エージェントは、GenAI モデルのインテリジェンスと、データ取得、外部アクション、およびその他の機能のためのツールを組み合わせます。 このページでは、エージェントの設計について説明します。
- エージェント システムを構築する具体的な例は、モデル呼び出しとツール呼び出しがどのように一緒にフローするかを調整する方法を示しています。
- エージェント システムの設計パターン は、決定論的なチェーンから、動的な決定を行うことができる単一エージェント システム、複数の特殊なエージェントを調整するマルチエージェント アーキテクチャまで、複雑さと自律性の連続性を形成します。
- 実践的なアドバイスセクション では、適切な設計の選択と、エージェントの開発、テスト、運用環境への移行に関するアドバイスを提供します。
エージェントは、情報を収集し、外部アクションを実行するためのツールに大きく依存しています。 ツールの背景については、「 ツール」を参照してください。
エージェント システムの例
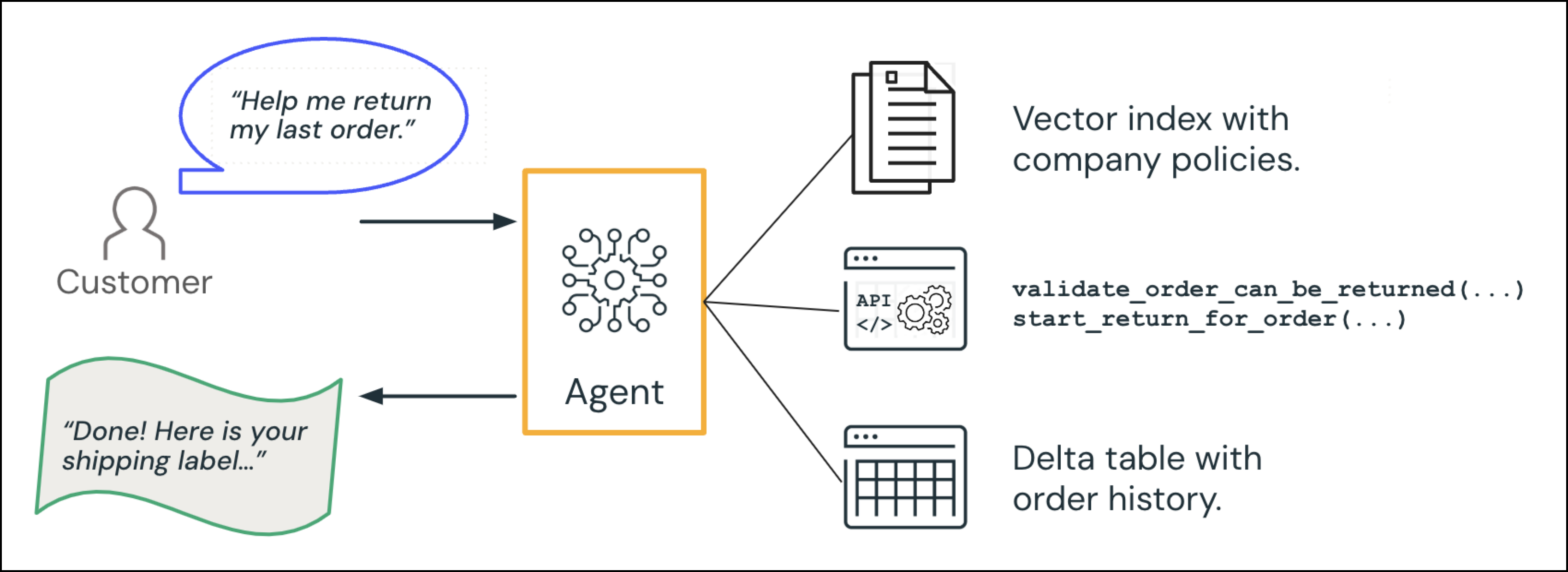
エージェント システムの具体的な例として、顧客と対話するコール センター GenAI エージェントを考えてみましょう。
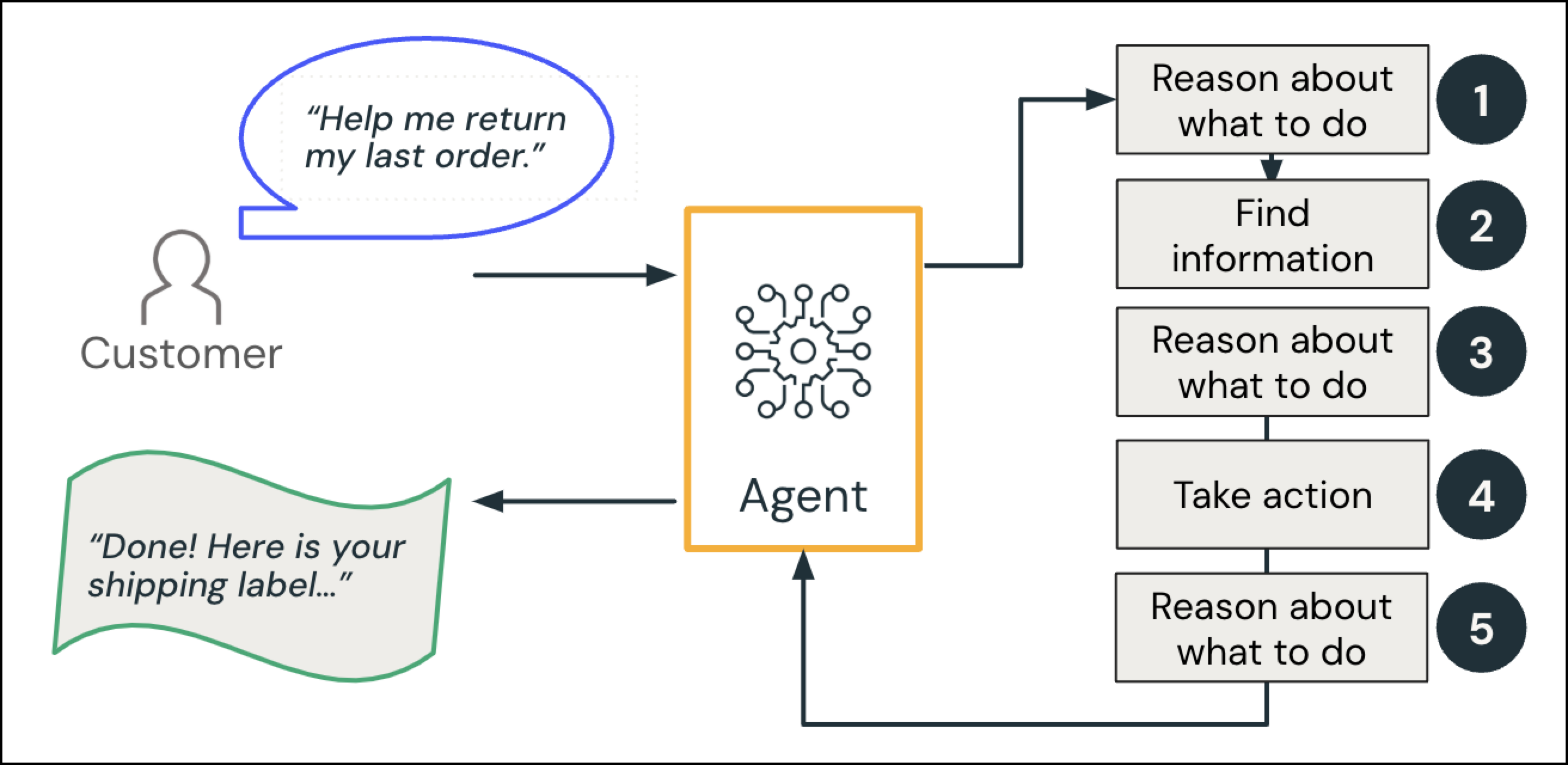
顧客が "前回の注文を返すのを手伝ってもらえますか" という要求を行います。
- 理由とプラン: クエリの意図を考えると、エージェントは "プラン": "ユーザーの最近の注文を検索し、返品ポリシーを確認します"。
- 情報の検索 (データ インテリジェンス): エージェントは注文データベースを照会して関連する注文を取得し、ポリシー ドキュメントを参照します。
-
理由: エージェントは、その順序が返品ウィンドウに収まるかどうかを確認します。
- オプションの human-in-the-loop: エージェントは追加のルールをチェックします。アイテムが特定のカテゴリに分類されるか、通常の返品ウィンドウの外にある場合は、人間にエスカレートします。
- アクション: エージェントは返品プロセスをトリガーし、配送先住所ラベルを生成します。
- 理由: エージェントは顧客に対する応答を生成します。
AI エージェントは、顧客に対して "完了! こちらが発送ラベルです。
これらの手順は、人間 のコールセンターにおいては当たり前のことです。 エージェント システム コンテキストでは、LLM は特殊なツールまたはデータ ソースを呼び出して詳細を入力する一方で、"理由" を示します。
複雑さのレベル: LLM からエージェント システムへ
GenAI アプリは、単純な LLM 呼び出しから複雑なマルチエージェント システムまで、さまざまなシステムを利用できます。 AI を利用したアプリケーションを構築する場合は、簡単に始めます。 柔軟性やモデル主導の意思決定を向上させるために本当に必要な場合は、より複雑なエージェント動作を導入します。 決定論的チェーンは、明確に定義されたタスクに対して予測可能なルールベースのフローを提供します。 エージェント型のアプローチが増えるほど、柔軟性と可能性が高くなりますが、複雑さと潜在的な待機時間のコストが伴います。
| デザイン パターン | 使用するタイミング | 長所 | 短所 |
|---|---|---|---|
| LLM + prompt |
|
|
|
| 決定論的チェーン |
|
|
|
| 単一エージェント システム |
|
|
|
| マルチエージェント システム |
|
|
|
Agent Framework は、これらのパターンに依存しないため、簡単に開始でき、アプリケーション要件の拡大に合わせて、より高いレベルの自動化と自律性に向けて進化します。
エージェント システムの背後にある理論の詳細については、Databricks の創設者からのブログ記事を参照してください。
LLM とプロンプト
最もシンプルな設計には、膨大なトレーニング データセットからの知識に基づいてプロンプトに応答するスタンドアロンの LLM またはその他の GenAI モデルがあります。 この設計は、単純なクエリや汎用クエリに適していますが、多くの場合、実際のビジネス データから切断されます。 カスタム命令または埋め込みデータを使用してシステム プロンプトを提供することで、動作をカスタマイズできます。

決定論的チェーン (ハードコーディングされたステップ)
決定論的チェーンは、ツール呼び出しによって GenAI モデルを拡張しますが、開発者は、どのツールまたはモデルを呼び出すか、どのような順序で、どのパラメーターを使用して呼び出すかを定義します。 LLM は、呼び出 すツール や 順序に関する決定を行いません。 システムは、すべての要求に対して定義済みのワークフローまたは "チェーン" に従い、非常に予測可能になります。
たとえば、決定論的検索拡張生成 (RAG) チェーンは常に次のようになります。
- ベクター インデックスから top-k の結果を取得して、ユーザー要求に関連するコンテキストを見つけます。
- ユーザー要求と取得したコンテキストを組み合わせてプロンプトを拡張します。
- 拡張プロンプトを LLM に送信して応答を生成します。

使用するタイミング:
- 予測可能なワークフローを持つ明確に定義されたタスクの場合。
- 一貫性と監査が最優先事項である場合。
- オーケストレーションの決定に対する複数の LLM 呼び出しを回避して待機時間を最小限に抑える場合。
の利点:
- 最高の予測可能性と監査可能性。
- 通常、待機時間が短くなります (オーケストレーションの LLM 呼び出しが少なくなります)。
- テストと検証が簡単です。
考慮事項:
- 多様な要求や予期しない要求を処理するための柔軟性が制限されています。
- ロジック ブランチが拡大するにつれて、複雑になり、保守が困難になる可能性があります。
- 新機能に対応するために重要なリファクタリングが必要な場合があります。
単一エージェント システム
単一エージェント システムには、1 つの調整されたロジック フローを調整する LLM があります。 LLM は、使用するツール、LLM 呼び出しを増やすタイミング、停止するタイミングを適応的に決定します。 このアプローチでは、動的なコンテキストに対応した決定がサポートされます。
単一エージェント システムでは、次のことができます。
- ユーザー クエリなどの要求と、会話履歴などの関連するコンテキストを受け入れます。
- 外部データまたはアクションに対してツールを呼び出すかどうかを必要に応じて決定する、最適な応答方法に関する理由。
- 必要に応じて反復処理し、目的が達成されるか、有効なデータの受信やエラーの解決などの特定の条件が満たされるまで、LLM またはツールを繰り返し呼び出します。
- ツールの出力を会話に統合します。
- 出力としてまとまりのある応答を返します。
たとえば、ヘルプ デスク アシスタント エージェントは次のように適応します。
- ユーザーが簡単な質問 ("What is our returns policy?") を尋ねると、エージェントは LLM の知識から直接応答する可能性があります。
- ユーザーが注文の状態を希望する場合、エージェントは関数
lookup_order(customer_id, order_id)を呼び出す可能性があります。 そのツールが "無効な注文番号" で応答した場合、エージェントは再試行するか、ユーザーに正しい ID の入力を求め、最終的な回答が得られるまで続行できます。

使用するタイミング:
- さまざまなユーザー クエリが必要ですが、それでも、まとまりのあるドメインまたは製品領域内にあります。
- 特定のクエリや条件では、顧客データをフェッチするタイミングの決定など、ツールの使用が保証される場合があります。
- 決定論的チェーンよりも柔軟性を高める必要がありますが、異なるタスクに個別の特殊なエージェントを必要としません。
の利点:
- エージェントは、呼び出すツール (ある場合) を選択することで、新しいクエリや予期しないクエリに適応できます。
- エージェントは、LLM 呼び出しまたはツール呼び出しを繰り返しループして結果を絞り込むことができます。完全にマルチエージェントをセットアップする必要はありません。
- この設計パターンは、多くの場合、エンタープライズユース ケースのスイートスポットです。マルチエージェントのセットアップよりもデバッグが簡単ですが、動的ロジックと制限された自律性が可能です。
考慮事項:
- ハードコーディングされたチェーンと比較して、繰り返しまたは無効なツール呼び出しから保護する必要があります。 無限ループは、任意のツール呼び出しシナリオで発生する可能性があるため、イテレーションの制限またはタイムアウトを設定します。
- アプリケーションが大幅に異なるサブドメイン (財務、開発、マーケティングなど) にまたがる場合、1 つのエージェントが扱いにくくなるか、機能要件で過負荷になる可能性があります。
- エージェントが集中し、関連性を保つためには、慎重に設計されたプロンプトと制約が必要です。
- エージェンシーは連続体である。システムの動作を制御するモデルに与える自由度が高いほど、アプリケーションはよりエージェンシー的になります。 実際には、ほとんどの運用システムでは、コンプライアンスと予測可能性を確保するためにエージェントの自律性を慎重に制限します。たとえば、危険なアクションに対して人間の承認を要求します。
マルチエージェント システム
マルチエージェント システムには、メッセージの交換やタスクの共同作業を行う、2 つ以上の特殊なエージェントが含まれます。 各エージェントには、独自のドメインまたはタスクの専門知識、コンテキスト、および異なる可能性のあるツール セットがあります。 別の "コーディネーター" または "AI スーパーバイザー" は、要求を適切なエージェントに送信するか、エージェント間で引き渡すタイミングを決定します。 スーパーバイザは、別の LLM またはルール ベースのルータにすることができます。

たとえば、顧客アシスタントには、特殊なエージェントに委任する監督者が存在する場合があります。
- ショッピング アシスタント: 顧客が製品を検索し、レビューの長所と短所に関するアドバイスを提供するのに役立ちます
- カスタマー サポート エージェント: フィードバック、返品、発送を処理します
使用するタイミング:
- コーディング エージェントや財務エージェントなど、個別の問題領域またはスキル セットがあります。
- 各エージェントは、会話履歴またはドメイン固有のプロンプトにアクセスする必要があります。
- 1 つのエージェントのスキーマにすべてを適合させるツールは非常に多く、実用的ではありません。各エージェントはサブセットを所有できます。
- 特殊なエージェント間でリフレクション、批判、または双方向のコラボレーションを実装したいと考えています。
の利点:
- このモジュール方式は、各エージェントを個別のチームで開発または管理できることを意味し、狭いドメインに特化しています。
- 1 つのエージェントがまとまりのある管理に苦労する可能性がある大規模で複雑なエンタープライズ ワークフローを処理できます。
- 高度なマルチステップまたはマルチパースペクティブの推論を容易にします。たとえば、1 つのエージェントが回答を生成し、もう 1 つそれを検証します。
考慮事項:
- エージェント間のルーティング戦略と、複数のエンドポイント間でのログ記録、トレース、デバッグのオーバーヘッドが必要です。
- 多数のサブエージェントとツールがある場合、どのエージェントがどのデータまたは API にアクセスできるかを判断するのが複雑になる可能性があります。
- エージェントは、慎重に制約されていない場合、解決なしでタスクを無期限にバウンスできます。 単一エージェント のツール呼び出しにも無限ループ リスクが存在しますが、マルチエージェントセットアップではデバッグの複雑さが増します。
実用的なアドバイス
ナレッジ アシスタントまたは AI 関数オファリングを使用してユース ケースに対処できる場合は、そのガイド付きの簡単なオプションから始めます。
カスタム エージェント システムを構築する必要がある場合、Azure Databricks と Mosaic AI Agent Framework は、選択したパターンに依存しないため、アプリケーションの成長に合わせて設計パターンを簡単に進化させることができます。 安定した保守可能なエージェント システムを開発するための次のベスト プラクティスを検討してください。
- 単純な開始: 単純なチェーンのみが必要な場合は、決定論的チェーンを構築するのが高速です。
- 徐々に複雑さを増します。 動的なクエリや柔軟なデータ ソースが必要な場合は、ツール呼び出しを使用して単一エージェント システムに移行します。 明確に異なるドメインまたはタスク、複数の会話コンテキスト、または大規模なツール セットがある場合は、マルチエージェント システムを検討してください。
- パターンを組み合わせる: 実際には、多くの実際のエージェント システムはパターンを組み合わせています。 たとえば、ほとんどの決定論的チェーンには、LLM が必要に応じて特定の API を動的に呼び出すことができる 1 つのステップがあります。
開発ガイダンス
-
プロンプトとツール
- 矛盾した指示や気が散る情報を避け、幻覚を減らすために、プロンプトを明確かつ最小限に抑えます。
- 無制限の API セットや大規模な無関係なコンテキストではなく、エージェントに必要なツールとコンテキストのみを提供します。 設計時にツールのアプローチを選択します。
-
ログ記録と可観測性
- MLflow Tracing を使用して、各ユーザー要求、エージェント プラン、およびツール呼び出しの詳細なログ記録を実装します。
- ログを安全に保存し、会話データ内の個人を特定できる情報 (PII) に注意してください。 自動化のために データ分類 を検討してください。
テストとイテレーションのガイダンス
-
評価
- MLflow の評価と運用の監視を使用して、開発と運用の評価メトリックを定義します。
- 専門家やユーザーからの 人間のフィードバック を収集して、自動評価メトリックが適切に調整されていることを確認します。
-
エラー処理とフォールバック ロジック
- ツールやLLMの障害に備えて計画を立てましょう。 タイムアウト、正しくない応答、または空の結果は、ワークフローを中断する可能性があります。 高度な機能が失敗した場合は、再試行戦略、フォールバック ロジック、またはより単純なフォールバック チェーンを含めます。
-
反復的な改善
- 時間の経過と同時にプロンプトとエージェント ロジックを調整することが期待されます。 MLflow Prompt Registry を使用して、プロンプトのバージョンを変更し、アプリの MLflow アプリのバージョン追跡を行います。 バージョン管理により、操作が簡略化され、ロールバックと比較が可能になります。
- 評価データを収集してメトリックを定義するときは、 MLflow Prompt Optimization などのより自動化された最適化方法を検討してください。
運用ガイダンス
-
モデルの更新とバージョンのピン留め
- LLM の動作は、プロバイダーがバックグラウンドでモデルを更新するときに変化する可能性があります。 バージョン固定と頻繁な回帰テストを使用して、エージェント ロジックが堅牢で安定していることを確認します。
-
待機時間とコストの最適化
- 追加の LLM またはツール呼び出しのたびに、トークンの使用と応答時間が増加します。 可能であれば、ステップを組み合わせるか、繰り返しクエリをキャッシュして、パフォーマンスとコストを管理できるようにします。
-
セキュリティとサンドボックス
- エージェントがレコードを更新したりコードを実行したりできる場合は、それらのアクションをサンドボックス化するか、必要に応じて人による承認を強制します。 これは、意図しない損害を避けるために、企業または規制された環境で重要です。 Unity カタログ関数 は、運用環境でサンドボックス実行を提供します。
- ツール オプションの詳細については、 AI エージェント ツールを参照してください。
これらのガイドラインに従うことで、ツールの誤呼、LLM のパフォーマンスの低下、予期しないコストの急増など、最も一般的な障害モードの多くを軽減し、より信頼性の高いスケーラブルなエージェント システムを構築できます。