この記事では、Databricks 上の MLflow を使用して、高品質の生成 AI エージェントと機械学習モデルを開発する方法について説明します。
注
Azure Databricks の使用を開始したばかりの場合は、 Databricks Free Edition で MLflow を試すことを検討してください。
MLflow とは?
MLflow は、 エージェント、LLM、ML モデル向けの最大のオープン ソース AI エンジニアリング プラットフォームです。 MLflow を使用すると、あらゆる規模のチームが、コストを制御し、モデルやデータへのアクセスを管理しながら、運用品質の AI アプリケーションをデバッグ、評価、監視、最適化できます。 毎月 3,000 万ダウンロードを超える数千の組織が、自信を持って AI を運用環境に出荷するために、毎日 MLflow に依存しています。
エージェントと LLM アプリケーション用の MLflow の包括的な機能セットには、運用グレードの 可観測性、 評価、 プロンプト管理、コストとモデル アクセスを管理するための AI ゲートウェイ などが含まれます。
機械学習 (ML) モデル開発の場合、MLflow は 実験追跡、 モデル評価機能、 運用モデル レジストリ、 モデルデプロイ ツールを提供します。
MLflow では、LLM プロバイダー、エージェント フレームワーク、ML ライブラリ、およびプログラミング言語がサポートされます。 MLflow には、 Python、 TypeScript/JavaScript、 Java、 R 用のネイティブ SDK が用意されています。
MLflow 3
Azure Databricks の MLflow 3 は、エージェントと LLM アプリケーションに対して最新の可観測性、評価、およびプロンプト管理を提供します。 ML モデル開発の場合、MLflow 3 には実験追跡、モデル評価、運用モデル レジストリ、モデルデプロイ ツールが用意されています。 Azure Databricks で MLflow 3 を使用すると、次のことができます。
開発ノートブック内の対話型クエリから運用バッチ、またはリアルタイム サービスデプロイまで、すべての環境でモデル、AI アプリケーション、エージェントのパフォーマンスを一元的に追跡および分析します。
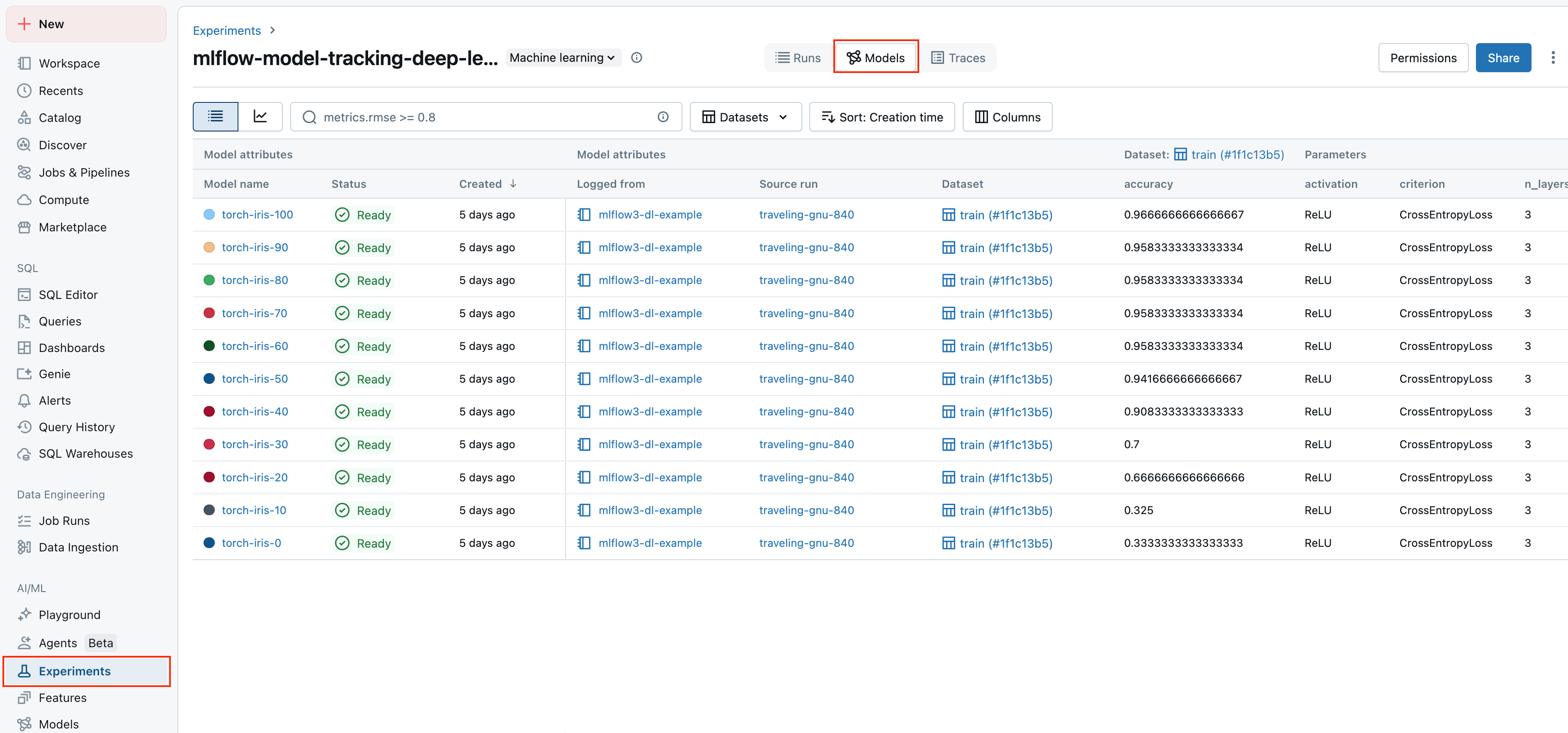
Unity カタログを使用して評価とデプロイのワークフローを調整し、モデル、AI アプリケーション、またはエージェントの各バージョンの包括的な状態ログにアクセスします。
Unity カタログのモデル バージョン ページと REST API から、モデルのメトリックとパラメーターを表示およびアクセスします。
![複数の実行からのメトリックを示す Unity カタログの [モデル バージョン] ページ。](../_static/images/mlflow/uc-model-version-page.png)
すべての Gen AI アプリケーションとエージェントの要求と応答 (トレース) に注釈を付け、人間の専門家と自動化された手法 (LLM-as-a-judge など) が豊富なフィードバックを提供できるようにします。 このフィードバックを利用して、アプリケーション バージョンのパフォーマンスを評価および比較し、品質を向上させるためにデータセットを構築できます。
![複数のトレースの詳細を示すモデル ページの [トレース] タブ。](../_static/images/mlflow/model-details-traces.png)
これらの機能により、すべての AI イニシアチブの評価、デプロイ、デバッグ、監視が簡素化され、合理化されます。
MLflow 3 には、ログに記録されたモデルとデプロイ ジョブの概念も導入されています。
-
ログに記録されたモデル は、モデルのライフサイクル全体の進行状況を追跡するのに役立ちます。
log_model()を使用してモデルをログに記録すると、モデルのライフサイクル全体を通じて、さまざまな環境と実行にわたって保持されるLoggedModelが作成され、メタデータ、メトリック、パラメーター、モデルの生成に使用されるコードなどの成果物へのリンクが含まれます。 ログに記録されたモデルを使用して、モデルを相互に比較し、最もパフォーマンスの高いモデルを見つけ、デバッグ中に情報を追跡できます。 - デプロイ ジョブ を使用して、評価、承認、デプロイなどの手順を含む、モデルのライフサイクルを管理できます。 これらのモデル ワークフローは Unity カタログによって管理され、すべてのイベントは Unity カタログのモデル バージョン ページで使用可能なアクティビティ ログに保存されます。
MLflow 3 のインストールと使用の開始については、次の記事を参照してください。
- モデル向けの MLflow 3 を始めましょう。
- MLflow ログに記録されたモデルを使用してモデルを追跡および比較します。
- MLflow 3 でのモデル レジストリの機能強化。
- MLflow 3 デプロイ ジョブ。
Databricks マネージド MLflow
Databricks は、フル マネージドでホストされたバージョンの MLflow を提供し、オープン ソース エクスペリエンスを基にして、エンタープライズでの使用に対してより堅牢でスケーラブルなものにします。
エージェントと LLM アプリケーション
Databricks の MLflow は、エージェントと LLM アプリケーションを開発、評価、監視するための完全なプラットフォームを提供します。
- Observability:MLflow Tracing では、要求の各中間ステップに関連付けられている入力、出力、およびメタデータが記録され、エージェントで予期しない動作の原因をすばやく見つけることができます。
- 評価:エージェント評価を使用して、MLflow 評価を利用してエージェントの品質を測定および改善します。
- プロンプト管理: AI アプリケーション全体で使用されるプロンプト テンプレートのバージョン管理と反復処理。
- エージェント開発:カスタム エージェントを使用してエージェントを作成します。エージェントのコード、パフォーマンス メトリック、トレースを追跡するために MLflow に依存します。
- 対話型デバッグ:エージェントの可観測性と評価のために Genie Code を使用して、MLflow 実験内のトレース、評価実行、スコアラーなどの自然言語アクセスを実現します。
ML モデルの開発
Databricks の MLflow には、ML モデル開発用の実験追跡、モデル評価、運用モデル レジストリ、モデルデプロイ ツールが用意されています。
次の図は、Databricks と MLflow を統合して機械学習モデルをトレーニングおよびデプロイする方法を示しています。
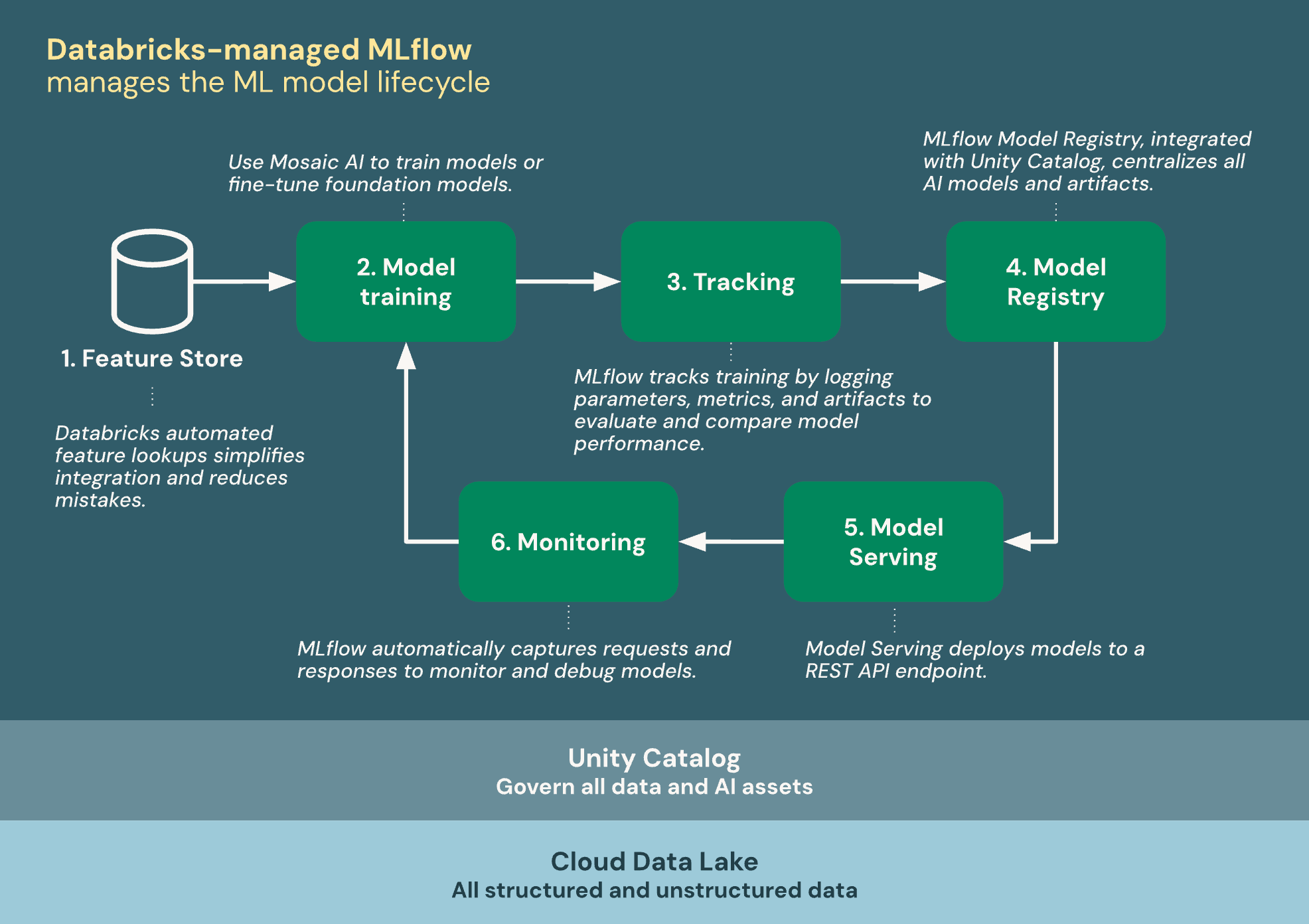
Databricks で管理される MLflow は、ML ライフサイクル内のすべてのデータと AI 資産を統合するために、Unity カタログと Cloud Data Lake 上に構築されています。
- フィーチャー ストア: Databricks の自動機能検索により、統合が簡素化され、間違いが軽減されます。
- モデルのトレーニング: Azure Databricks AI 機能を使用してモデルをトレーニングしたり、基礎モデルを微調整したりできます。
- 追跡: MLflow は、モデルのパフォーマンスを評価および比較するために、パラメーター、メトリック、成果物をログに記録することでトレーニングを追跡します。
- モデル レジストリ: Unity カタログと統合された MLflow モデル レジストリにより、AI モデルとアーティファクトが一元化されます。
- モデルの提供: Model Serving は、REST API エンドポイントにモデルをデプロイします。
- 監視: Model Serving では、モデルを監視およびデバッグするための要求と応答が自動的にキャプチャされます。 MLflow は、要求ごとにトレース データを使用してこのデータを拡張します。
モデル訓練
MLflow モデルは、Databricks での AI および ML 開発の中核をなしています。 MLflow モデルは、機械学習モデルと生成 AI エージェントをパッケージ化するための標準化された形式です。 標準化された形式により、Databricks のダウンストリーム ツールとワークフローでモデルとエージェントを使用できるようになります。
- MLflow ドキュメント - モデル。
Databricks には、さまざまな種類の ML モデルのトレーニングに役立つ機能が用意されています。
実験の追跡
Databricks では、MLflow 実験を組織単位として使用して、モデルの開発中に作業を追跡します。
実験追跡を使用すると、機械学習のトレーニングとエージェントの開発中に、パラメーター、メトリック、成果物、およびコード バージョンをログに記録して管理できます。 ログを実験と実行に整理することで、モデルの比較、パフォーマンスの分析、反復処理をより簡単に行うことができます。
- Databricks を使用した実験の追跡。
- 実行と実験の追跡に関する一般的な情報については、MLflow のドキュメントを参照してください。
Unity カタログを使用したモデル レジストリ
MLflow モデル レジストリは、モデル デプロイ プロセスを管理するための一元化されたモデル リポジトリ、UI、API のセットです。
Databricks は、モデル レジストリと Unity カタログを統合して、モデルの一元的なガバナンスを提供します。 Unity カタログ統合を使用すると、ワークスペース間でモデルにアクセスしたり、モデル系列を追跡したり、再利用のためにモデルを検出したりできます。
- Databricks Unity カタログを使用してモデルを管理します。
- モデル レジストリに関する一般的な情報については、MLflow のドキュメントを参照してください。
Model Serving
Databricks Model Serving は、MLflow モデル レジストリと緊密に統合されており、AI モデルのデプロイ、管理、クエリを行う、統合されたスケーラブルなインターフェイスを提供します。 サービスを提供する各モデルは、Web またはクライアント アプリケーションに統合できる REST API として使用できます。
これらは個別のコンポーネントですが、モデル サービスは MLflow モデル レジストリに大きく依存して、モデルのバージョン管理、依存関係の管理、検証、ガバナンスを処理します。
オープン ソースと Databricks で管理される MLflow 機能
オープン ソースと Databricks で管理されるバージョン間で共有される一般的な MLflow の概念、API、および機能については、 MLflow のドキュメントを参照してください。 Databricks で管理される MLflow 専用の機能については、Databricks のドキュメントを参照してください。
次の表では、オープン ソースの MLflow と Databricks で管理される MLflow の主な違いを示し、詳細情報に役立つドキュメント リンクを示します。
| 特徴 | オープン ソース MLflow での可用性 | Databricks で管理される MLflow での可用性 |
|---|---|---|
| セキュリティ | ユーザーは、独自のセキュリティ ガバナンス レイヤーを提供する必要があります | Databricks エンタープライズ レベルのセキュリティ |
| 障害復旧 | 利用不可 | Databricks の障害復旧 |
| 実験の追跡 | MLflow 追跡 API | Databricks の高度な実験追跡と統合された MLflow Tracking API |
| モデル レジストリ | MLflow モデル レジストリ | Databricks Unity カタログと統合された MLflow モデル レジストリ |
| Unity Catalog の統合 | オープン ソースと Unity カタログの統合 | Databricks Unity カタログ |
| モデル デプロイ | 外部サービス ソリューション (SageMaker、Kubernetes、コンテナー サービスなど) とのユーザー構成の統合 | Databricks モデルサービング と外部サービング ソリューション |
| AI エージェント | MLflow LLM 開発 | カスタム エージェントとエージェント評価と統合された MLflow LLM 開発 |
| 暗号化 | 利用不可 | カスタマー マネージド キーを使用した暗号化 |
注
オープン ソーステレメトリ収集は MLflow 3.2.0 で導入され、 Databricks では既定で無効になっています。 詳細については、 MLflow の使用状況追跡に関するドキュメントを参照してください。