この記事では、バッチとストリーミングの主な違い、データ エンジニアリング ワークロードに使用される 2 つの異なるデータ処理セマンティクス (インジェスト、変換、リアルタイム処理など) について説明します。
ストリーミングは、通常、Apache Kafka などのメッセージ バスからの低待機時間および継続的な処理に関連付けられます。
ただし、Azure Databricks では、より広範な定義があります。 Lakeflow 宣言パイプライン (Apache Spark および構造化ストリーミング) の基になるエンジンには、バッチ処理とストリーミング処理のための統合アーキテクチャがあります。
- エンジンは、 クラウド オブジェクト ストレージ や Delta Lake などのソースをストリーミング ソースとして扱い、効率的な増分処理を行うことができます。
- ストリーミング処理は、トリガーされた方法と継続的な方法の両方で実行できるため、ストリーミング ワークロードのコストとパフォーマンスのトレードオフを柔軟に制御できます。
バッチとストリーミングを区別する基本的なセマンティックの違いを以下に示します。これには、その長所と短所、ワークロードに合わせてそれらを選択するための考慮事項が含まれます。
バッチ セマンティクス
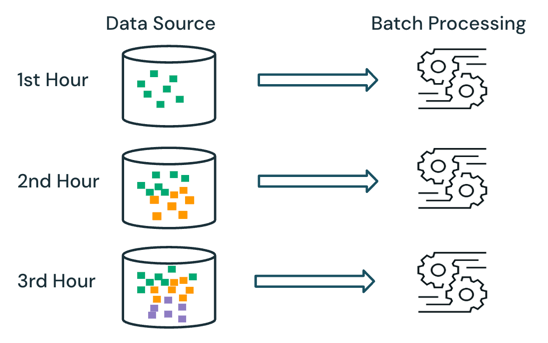
バッチ処理では、エンジンはソースで既に処理されているデータを追跡しません。 ソースで現在使用可能なすべてのデータは、処理中に処理されます。 実際には、バッチ データ ソースは通常、データの再処理を制限するために、たとえば日や地域ごとに論理的にパーティション分割されます。
たとえば、eコマース企業が実行する販売イベントに対して、時間単位の粒度で集計された平均品目販売価格を計算し、1 時間ごとに平均販売価格を計算するバッチ処理としてスケジュールできます。 バッチでは、前の時間のデータが 1 時間ごとに再処理され、以前に計算された結果が上書きされて最新の結果が反映されます。
ストリーミング セマンティクス
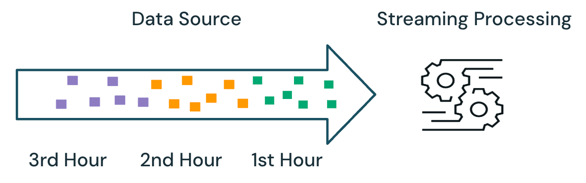
ストリーミング処理では、エンジンは処理されているデータを追跡し、後続の実行時にのみ新しいデータを処理します。 上記の例では、バッチ処理ではなくストリーミング処理をスケジュールして、1 時間ごとに平均販売価格を計算できます。 ストリーミングでは、最後の実行以降にソースに追加された新しいデータのみが処理されます。 完全な結果を確認するには、以前に計算された結果に新しく計算された結果を追加する必要があります。
Batch とストリーミング
上記の例では、ストリーミングは、前の実行で処理されたのと同じデータを処理しないため、バッチ処理よりも優れています。 ただし、ストリーミング処理は、ソース内の順序が外れたデータや到着遅延データなどのシナリオで複雑になります。
到着遅延データの例は、最初の 1 時間の売上データが 2 時間目までソースに到着しない場合です。
- バッチ処理では、最初の 1 時間の到着遅延データは、2 時間目のデータと最初の 1 時間の既存のデータで処理されます。 最初の 1 時間の前の結果は上書きされ、到着遅延データで修正されます。
- ストリーミング処理では、最初の 1 時間からの到着遅延データは、処理された他の最初の 1 時間のデータなしで処理されます。 処理ロジックは、前の結果を正しく更新するために、最初の 1 時間の平均計算の合計とカウント情報を格納する必要があります。
通常、これらのストリーミングの複雑さは、 結合、 集計、 重複除去など、処理がステートフルな場合に導入されます。
ソースからの新しいデータの追加などのステートレス ストリーミング処理の場合、データがソースに到着すると、到着遅延データを前の結果に追加できるため、順序が正しくないデータや到着遅延データの処理は複雑ではありません。
次の表は、バッチ処理とストリーミング処理の長所と短所、および Databricks Lakeflow でこれら 2 つの処理セマンティクスをサポートするさまざまな製品機能の概要を示しています。
| バッチ | ストリーミング | |
|---|---|---|
| 利点 |
|
|
| 短所 |
|
|
| データ エンジニアリング製品 |
|
|
推奨事項
次の表は、 medallion アーキテクチャの各レイヤーにおけるデータ処理ワークロードの特性に基づいて、推奨される処理セマンティクスの概要を示しています。
| メダリオンレイヤー | ワークロードの特性 | 勧告 |
|---|---|---|
| 銅 |
|
|
| 銀 |
|
|
| 金 |
|
|