Data Lakehouse は、データ レイクとデータ ウェアハウスの利点を組み合わせたデータ管理システムです。 この記事では、レイクハウスのアーキテクチャ パターンと、Azure Databricks でできることについて説明します。
データレイクハウスはどのように利用されるのですか?
データ レイクハウスでは、機械学習 (ML) やビジネス インテリジェンス (BI) などのさまざまなワークロードがばらばらのシステムで処理されるのを避けたい最新の組織のために、スケーラブルなストレージと処理機能が提供されます。 データ レイクハウスは、信頼できる唯一の情報源を確立し、冗長なコストをなくし、データの鮮度を保証するのに役立ちます。
Data Lakehouse では、多くの場合、ステージングと変換のレイヤー間を移動するにつれて、データの増分的な改善、強化、および調整を行うデータ設計パターンが使用されます。 レイクハウスの各レイヤーには、1 つ以上のレイヤーを含めることができます。 このパターンは、多くの場合、メダリオン アーキテクチャと呼ばれます。 詳細については、「medallion lakehouse のアーキテクチャとは」を参照してください。
Databricks Lakehouse のしくみ
Databricks は Apache Spark 上に構築されています。 Apache Spark を使用すると、ストレージから切り離されたコンピューティング リソースで実行される、非常にスケーラブルなエンジンを実現できます。 詳細については、Azure Databricks の Apache Spark に関するページを参照してください。
Databricks Lakehouse では、次の 2 つの重要なテクノロジが使用されています。
- Delta Lake: ACID トランザクションとスキーマの適用をサポートする最適化されたストレージ レイヤー。
- Unity カタログ: データと AI 用の統一されたきめ細かいガバナンス ソリューション。
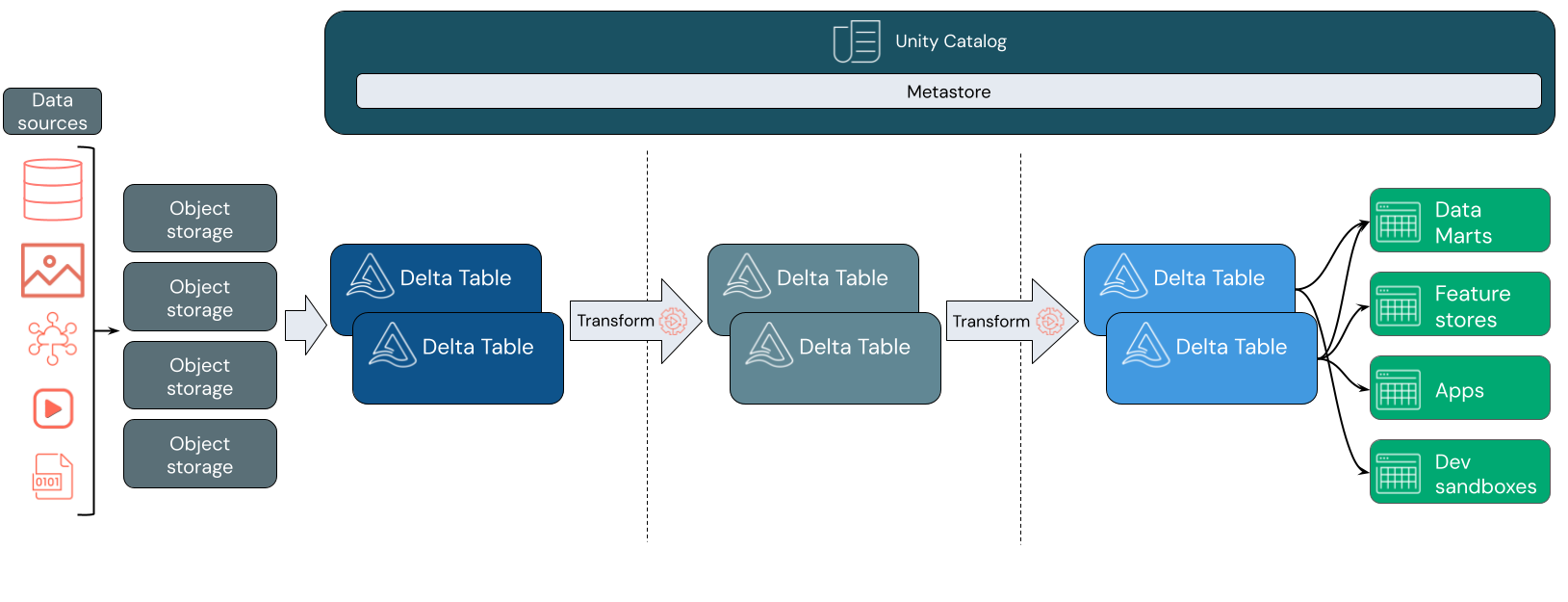
データ インジェスト
インジェスト レイヤーでは、バッチデータまたはストリーミング データがさまざまなソースから、さまざまな形式で到着します。 この最初の論理レイヤーは、そのデータが生形式で配置される場所を提供します。 これらのファイルを Delta テーブルに変換するときに、Delta Lake のスキーマ強制機能を使用して、不足しているデータまたは予期しないデータを確認できます。 Unity カタログを使用すると、データ ガバナンス モデルと必要なデータ分離境界に従ってテーブルを登録できます。 Unity Catalog を使用すると、データが変換および調整されるときにデータの系列を追跡できるほか、統合されたガバナンス モデルを適用して機密データをプライベートで安全に保つことができます。
データ処理、キュレーション、統合
検証が完了したら、データのキュレーションと調整を開始できます。 データ サイエンティストと機械学習実践者は、この段階でデータを頻繁に操作して、新しい機能の組み合わせまたは作成を開始し、完全なデータ クレンジングを開始します。 データが完全にクレンジングされたら、特定のビジネス ニーズを満たすように設計されたテーブルに統合および再構成できます。
書き込み時スキーマアプローチと差分スキーマ進化機能を組み合わせることで、エンド ユーザーにデータを提供するダウンストリーム ロジックを書き換える必要なく、このレイヤーに変更を加えることができます。
データ提供
最後のレイヤーは、クリーンでエンリッチメントされたデータをエンド ユーザーに提供します。 最終的なテーブルは、すべてのユース ケースのデータを提供するように設計する必要があります。 統一されたガバナンス モデルは、データ系列を追跡して、単一の信頼できるソースに戻すことができるということです。 さまざまなタスク用に最適化されたデータ レイアウトを使用すると、エンド ユーザーは機械学習アプリケーション、データ エンジニアリング、ビジネス インテリジェンスとレポート用のデータにアクセスできます。
Delta Lake の詳細については、「Azure Databricks の Delta Lake とは」を参照してください。Unity カタログの詳細については、「Unity カタログとは」を参照してください。
Databricks Lakehouse の機能
Databricks 上に構築された lakehouse は、最新のデータを扱う企業におけるデータレイクとデータウェアハウスへの依存を取って代わります。 実行できる主なタスクには、次のようなものがあります。
- リアルタイム データ処理: ストリーミング データをリアルタイムで処理して、迅速な分析とアクションを実現します。
- データ統合: 1 つのシステムでデータを統合し、コラボレーションを可能にし、組織の単一の信頼できるソースを確立します。
- スキーマの進化: 既存のデータ パイプラインを中断することなく、変化するビジネス ニーズに適応するように、時間の経過と同時にデータ スキーマを変更します。
- データ変換: Apache Spark と Delta Lake を使用すると、データの速度、スケーラビリティ、信頼性が向上します。
- データ分析とレポート: データ ウェアハウス ワークロード用に最適化されたエンジンを使用して、複雑な分析クエリを実行します。
- 機械学習と AI: すべてのデータに高度な分析手法を適用します。 ML を使用してデータを強化し、他のワークロードをサポートします。
- データのバージョン管理と系列: データセットのバージョン履歴を維持し、系列を追跡して、データの実証と追跡可能性を確保します。
- データ ガバナンス: 単一の統合システムを使用して、データへのアクセスを制御し、監査を実行します。
- データ共有: チーム間でキュレーションされたデータ セット、レポート、分析情報を共有できるようにすることで、コラボレーションを容易にします。
- 運用分析: Lakehouse 監視データに機械学習を適用して、データ品質メトリック、モデル品質メトリック、および誤差を監視します。
Lakehouse vs Data Lake vs Data Warehouse
データ ウェアハウスは、ビジネス インテリジェンス (BI) の決定を約 30 年間強化してきました。これは、データフローを制御するシステムの設計ガイドラインのセットとして進化してきました。 エンタープライズ データ ウェアハウスは BI レポートのクエリを最適化しますが、結果を生成するのに数分または数時間かかることがあります。 データ ウェアハウスは、頻度の高い変更の可能性が低いデータ用に設計されており、同時に実行されるクエリ間の競合を防ぎます。 多くのデータ ウェアハウスは独自の形式に依存しており、多くの場合、機械学習のサポートが制限されます。 Azure Databricks のデータ ウェアハウスでは、Databricks Lakehouse と Databricks SQL の機能を活用します。 詳細については、「 Azure Databricks でのデータ ウェアハウス」を参照してください。
データ ストレージの技術的な進歩を利用し、データの種類と量が指数関数的に増加することで、データ レイクは過去 10 年間に広く使用されています。 データ レイクは、データを安価かつ効率的に格納および処理します。 データ レイクは、多くの場合、データ ウェアハウスとは反対に定義されます。データ ウェアハウスは、BI 分析用にクリーンで構造化されたデータを提供し、データ レイクはあらゆる性質のデータを任意の形式で永続的かつ安価に格納します。 多くの組織では、データ サイエンスと機械学習にデータ レイクを使用しますが、未検証の性質のため BI レポートには使用しません。
Data Lakehouse は、データ レイクとデータ ウェアハウスの利点を組み合わせ、次の機能を提供します。
- 標準のデータ形式で格納されているデータに直接アクセスできる、オープンです。
- 機械学習とデータ サイエンス用に最適化されたインデックス作成プロトコル。
- BI と高度な分析のクエリ待機時間が短く、信頼性が高い。
最適化されたメタデータ レイヤーと、クラウド オブジェクト ストレージの標準形式で格納されている検証済みデータを組み合わせることにより、データ サイエンティストと ML エンジニアは、同じデータドリブン BI レポートからモデルを構築できます。
次のステップ
Databricks を使用して Lakehouse を実装および運用するための原則とベスト プラクティスの詳細については、適切に設計された Data lakehouse の概要を参照してください。