Important
この機能は パブリック プレビュー段階です。
このページでは、Genie Code でエージェント モードを選択して使用できる AI データ エージェントであるパイプライン開発用の Genie Code について説明します。 Lakeflow Spark 宣言パイプライン (SDP) と Lakeflow Pipelines エディター専用に設計されており、データの探索、パイプライン コードの生成と実行、エラーの修正をすべて 1 回のプロンプトから行います。
パイプライン開発のための Genie Code とは
エージェント モードの Genie Code は、SDP と Lakeflow Pipelines Editor でマルチステップ データ エンジニアリング ワークフロー全体を自動化できる自律的なパートナーです。
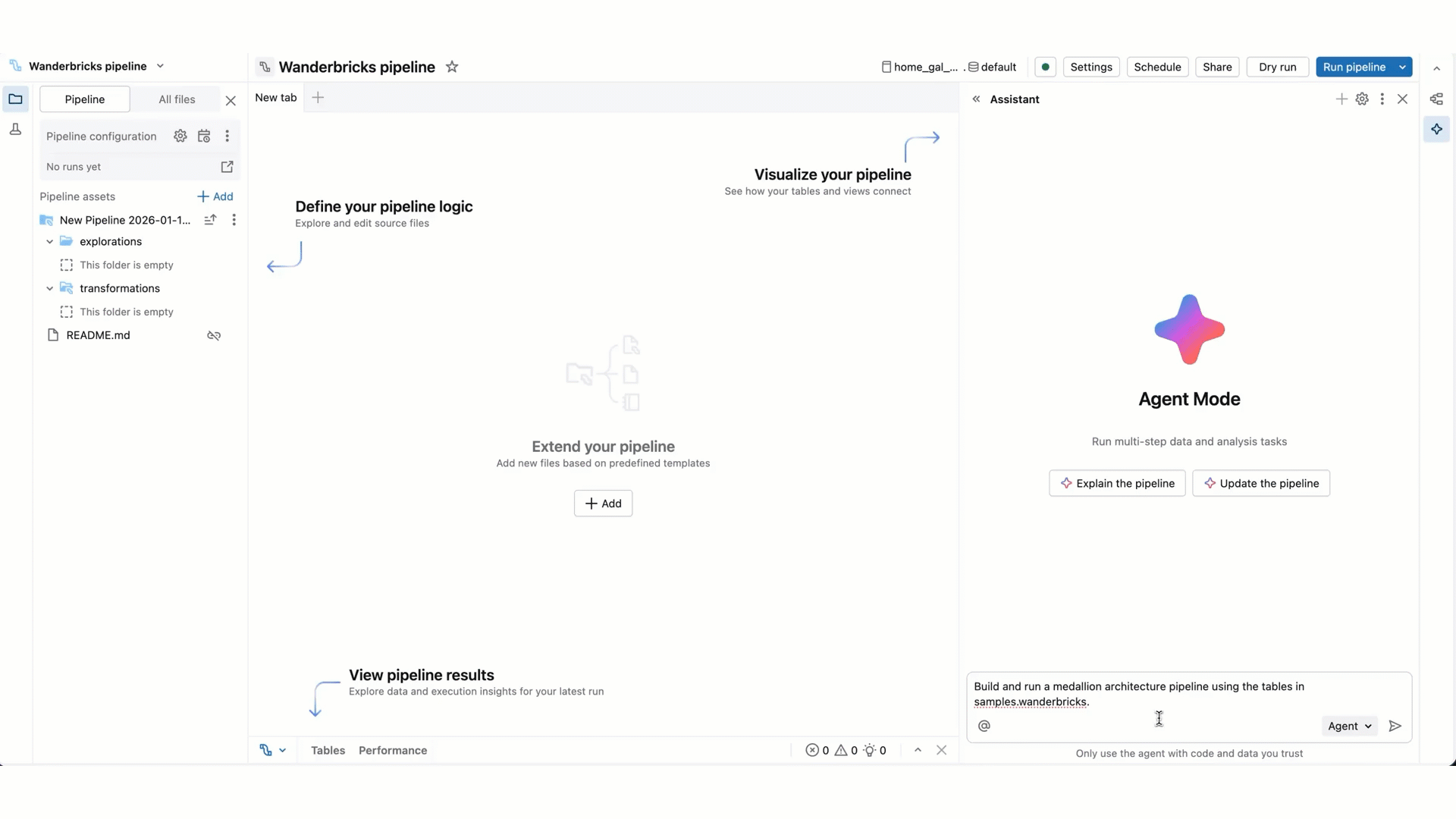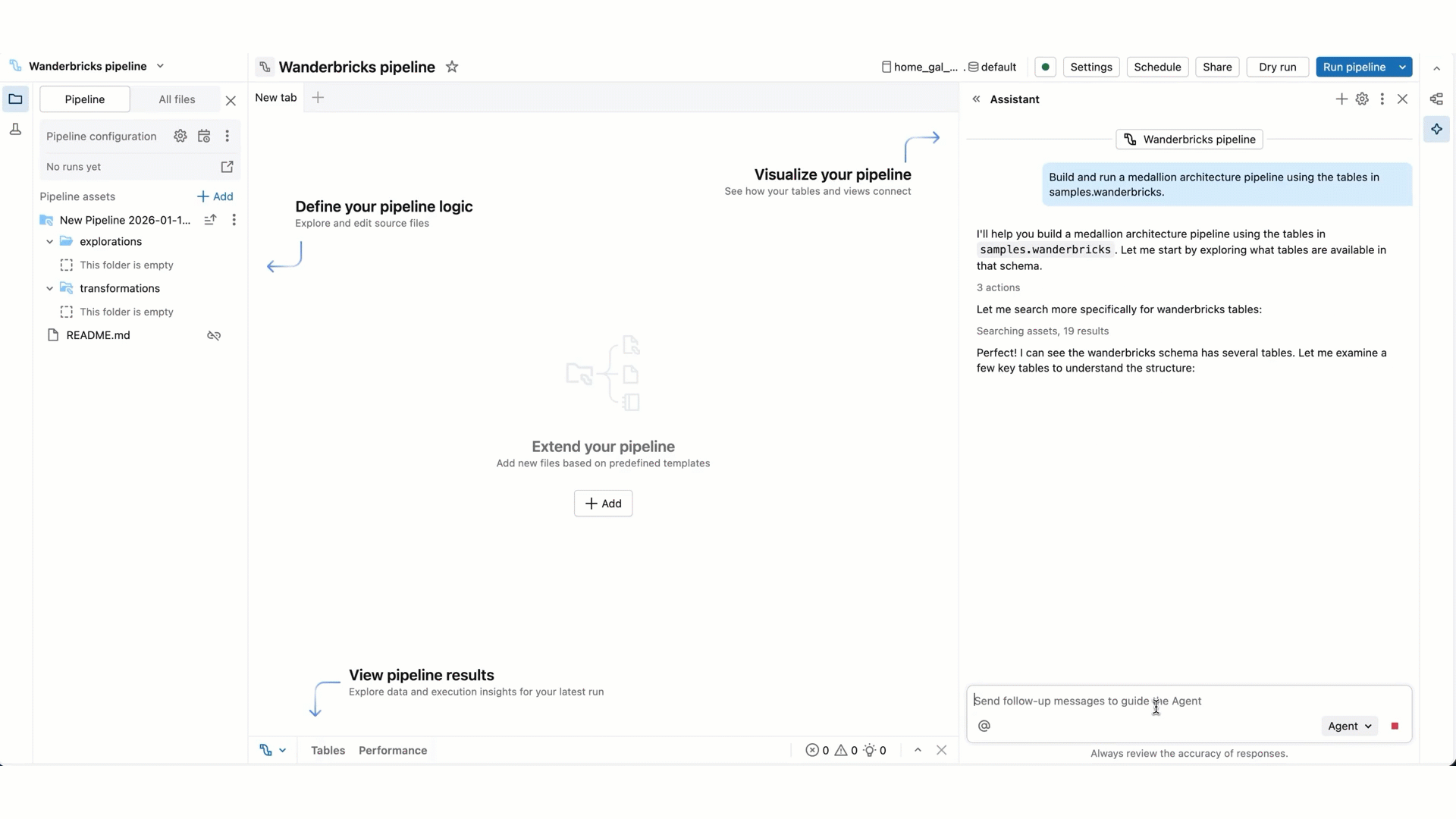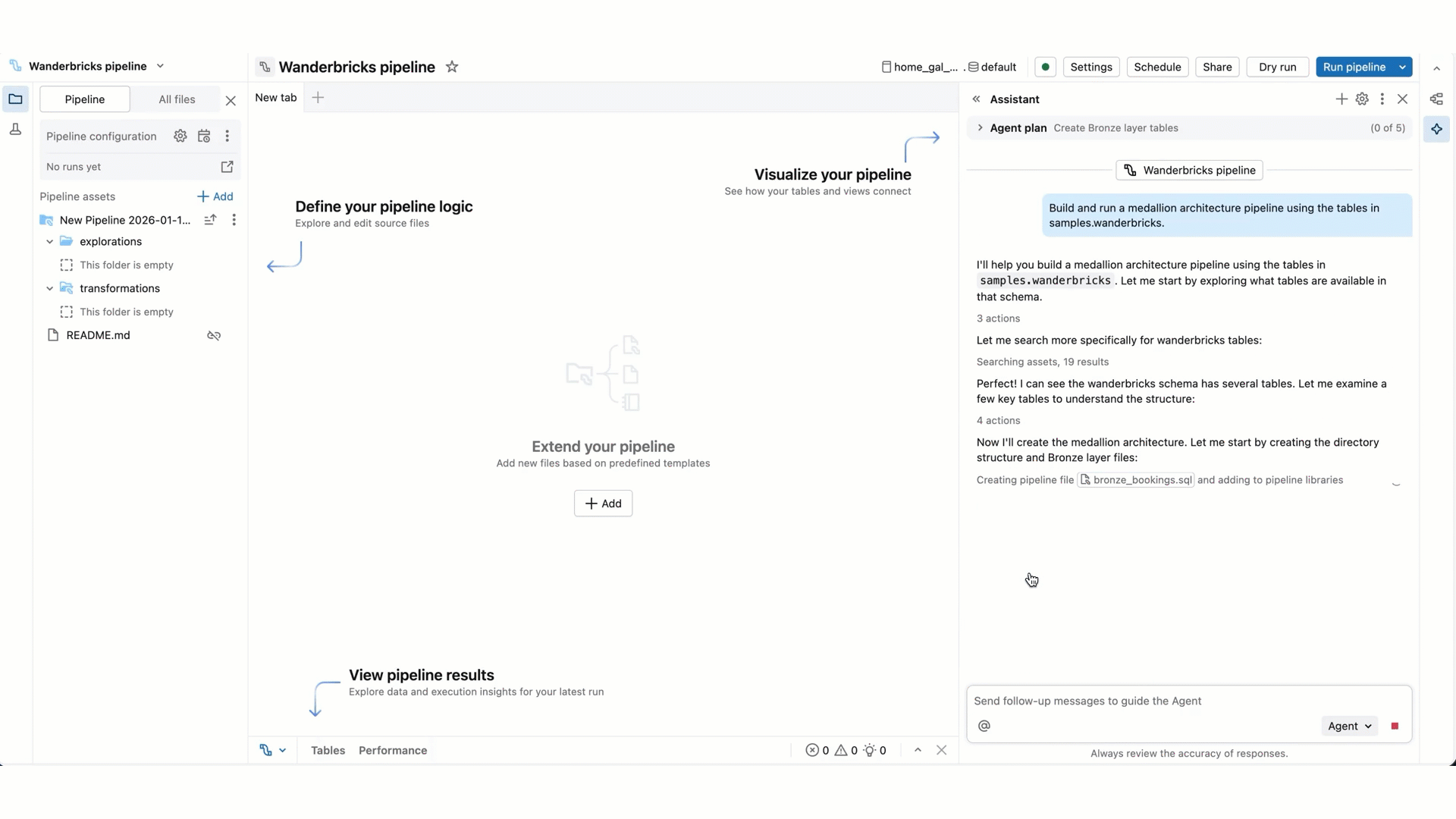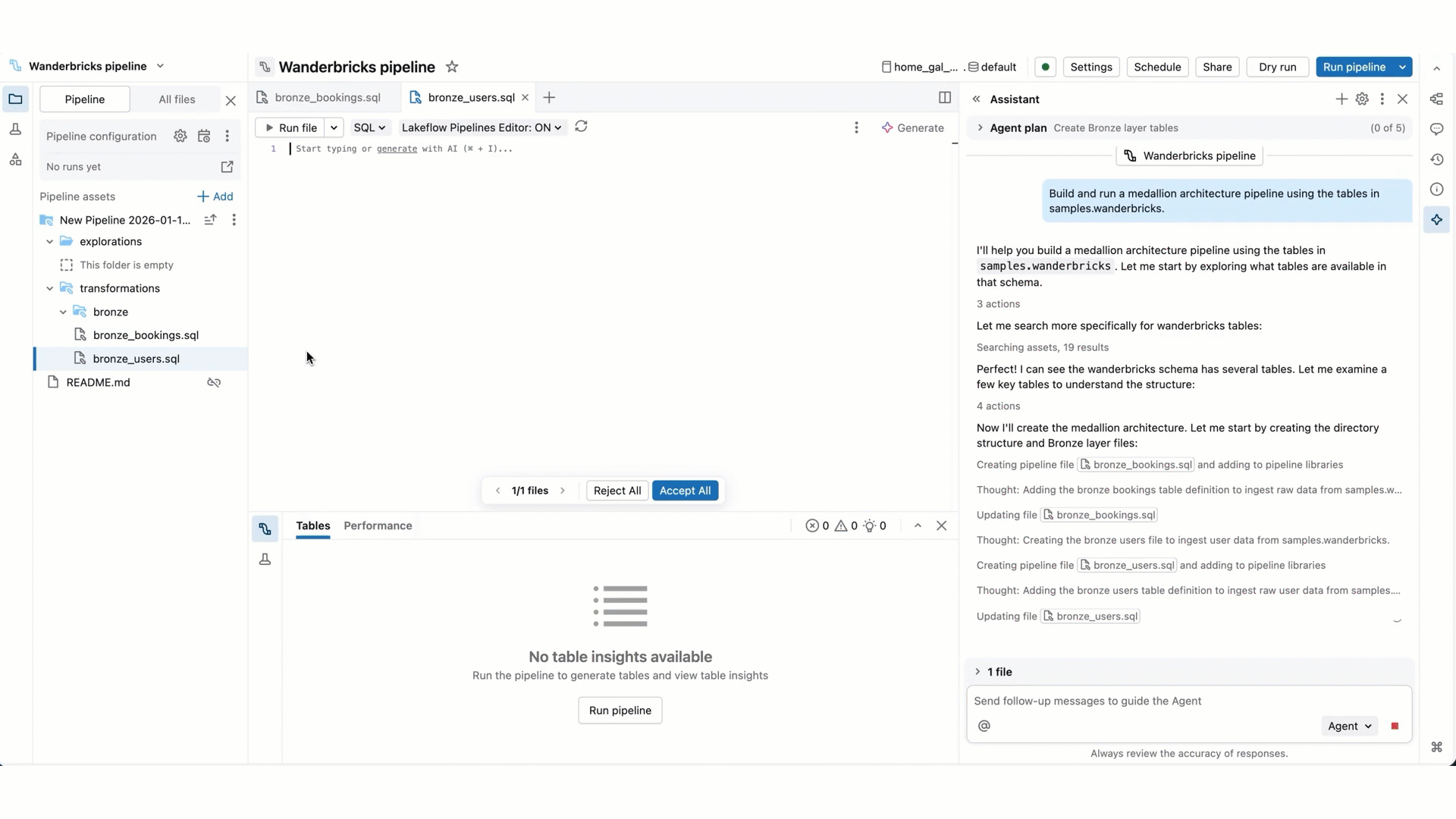
Genie Code チャット モードと比較して、エージェント モードでは、ソリューションの計画、関連する資産の取得、コードの実行、パイプライン出力を使用した結果の改善、エラーの自動修正などの機能が拡張されています。
エージェント モードの Genie Code では、パイプライン全体をゼロからエンドツーエンドで計画および生成したり、既存のパイプラインの作業を高速化したりできます。 エージェントは、続行する前に、お客様と協力してプランを承認し、次の手順を確認します。 Genie Code では、承認を得て、ツールを使用して、テーブルの検索、SQL またはPythonソース ファイルの編集、パイプラインの更新の実行、パイプライン データセットの読み取りなどのタスクを実行できます。
Genie Code のアクセスとアクションは、ユーザーのアクセス許可によって管理されます。 アクセス権を持つデータにのみアクセスし、アクセス許可を持つ操作を実行できます。
注
Genie Code でエージェント モードを有効にすると、Genie Code は Databricks で現在使用している機能に基づいて機能を調整します。 たとえば、Lakeflow Pipelines エディターでは、Genie Code はパイプラインの編集タスクとデータ エンジニアリング タスクに重点を置いています。 ノートブックと SQL エディターでは、Genie Code はデータの探索と分析をサポートします。 詳細については、「 データ サイエンスに Genie Code を使用 する」を参照してください。
Requirements
データ エンジニアリングに Genie Code を使用するには、ワークスペースに次のものが必要です。
- アカウントとワークスペースの両方で有効になっているパートナーを利用した AI 機能。 パートナーを利用した AI 機能を参照してください。
- ワークスペースは、サポートされているリージョンに存在する必要があります。 Genie Code は、Geos を使用してデータ所在地を管理する 指定サービス です。 Genie Code 機能の Geo 可用性を参照してください。
パイプライン開発に Genie Code を使用する
パイプライン開発に Genie Code のエージェント機能を使用するには:
Lakeflow Pipelines エディターで、[
![アバター アシスタント] アイコン](../_static/images/product-icons/sparklecolorfillicon.svg) をクリックして Genie Code サイド パネルを開きます。ワークスペースの右上隅にある Genie Code。
をクリックして Genie Code サイド パネルを開きます。ワークスペースの右上隅にある Genie Code。右下隅にある [エージェント] を選択 します。 これにより、Genie Code のエージェント モードが切り替わります。これにより、Genie Code のエージェント データ エンジニアリング機能を使用できるようになります。
Genie Code のプロンプトを入力します。 たとえば、"このパイプラインについて説明する" など、パイプラインに関する質問をすることができます。 また、新しいデータセットを追加するように依頼することもできます。たとえば、"bronze_sales_dataから読み取ってデータをクリーンアップし、有用な品質の期待を追加する新しいファイルにsilver_sales_dataを作成する" などです。
注
Genie Code はユーザーの Unity カタログのアクセス許可を尊重するため、アクセス権を持つデータとパイプライン ソースにのみアクセスできます。
Genie Code が応答を生成すると、多くの場合、入力を取得するために一時停止します。
より複雑なタスクの場合、Genie Code は段階的な計画を作成し、明確な質問をする場合があります。 その明確な質問に答えて、その計画を磨くのを助けます。
Genie Code でコードを実行したり、パイプラインを更新したりする必要がある場合は、続行する前に承認を求められます。 要求を許可または拒否します。 このスレッドで [許可] (Genie Code 会話スレッドを参照) または [常に許可] を選択することもできます。
Important
エージェント モードの Genie Code は、パイプラインでコードを生成して実行できます。 危険な行動を防ぐためのガードレールがありますが、依然としてリスクがあります。 信頼できるデータでのみ使用し、実行する前にコードを確認する必要があります。
Genie Code の作業が続行されると、[ 続行 ] または [拒否 ] を選択するように求められる場合があります。既存の作業を確認し、[ 続行 ] を選択して次の手順に進むか 、[拒否] を選択して他の操作を試みるように指示します。
Genie Code の動作を停止するには、赤い
 をクリックします。
をクリックします。
Genie Code では、新しいファイルの作成、テキスト、クエリ、コードの生成、ファイルまたはパイプラインの実行、出力データセットへのアクセスを行って結果を解釈できます。
注
Genie Code が作業を続行し、次の手順を実行するには、現在作業しているタブを維持する必要があります。
ヒント
Genie Code でほとんどの応答で使用する手順を追加できます。 たとえば、使用するコード規則や、使用する推奨ライブラリがある場合は、Genie Code の手順にこれらのガイドラインを追加できます。 また、ドメイン固有のタスクに特化した機能を使用して Genie Code を拡張する スキル を作成することもできます。 詳細とその他のヒントについては、「 Genie Code の応答を改善するためのヒント」を参照してください。
能力
エージェント モードでは、Genie Code はほとんどのパイプライン開発タスクに役立ちます。 主な機能は次のとおりです。
- データ検出: Genie Code では、ワークスペース内のテーブルを検索して、タスクに必要なデータを見つけるのに役立ちます。
- パイプライン コードの編集: Genie Code では、一度に複数のファイルを作成および編集できます。 変更中のファイルに関する情報が保持され、各ファイルのコードの相違が表示されるので、最後に変更を個別に、またはすべてまとめて確認できます。
- パイプラインの実行: Genie Code では、個々のファイルを実行したり、パイプラインをドライラン/実行したり、完全な更新を実行したりできます。 Genie Code は、続行する前に確認を求めます。
- パイプラインの動作を理解して改善する: Genie Code では、データセットとパイプライン出力を検査して、パイプラインが何をエンドツーエンドで行っているかとその理由を理解するのに役立ちます。 たとえば、変換の要約、ダウンストリーム テーブルへのデータ フローの追跡、行数やスキーマの予期しない変更の強調表示などを行うことができます。 データ品質の問題が発生する可能性がある場合、Genie Code は原因を特定し、パイプライン内の場所と対処方法を提案するのに役立ちます。
これらの機能は、次のような一般的なユース ケースをサポートします。
- 新しいパイプラインの作成: Genie Code は、データの取り込みからデータの標準化とクリーニング、データの変換と分析まで、新しい medallion アーキテクチャ パイプラインを作成するすべての手順に役立ちます。
- パイプラインの説明: Genie Code では、既存のパイプラインを分析して説明し、迅速に立ち上げるのに役立ちます。
- 問題の修正: エラーがある場合、Genie Code は問題の診断と修正に役立ち、問題が解決されるまで複数のファイルを反復処理できます。
例示
開始するには、次のプロンプトを試してください。
- "my_catalog.my_schema のテーブル トランザクションと顧客を使用して不正行為を検出するための medallion アーキテクチャ パイプラインを構築して実行します。"
- "このパイプラインのすべてのステップについて説明します。"
- "このパイプラインのエラーを修正します。"