パイプラインで変換を宣言して、ストリーム静的結合、増分集計、ストリーミング テーブルと具体化されたビューの混在などの一般的なパターンを使用して、クエリ ロジックを使用してレコードを処理する方法を指定します。
DataFrame を返す任意のクエリに対してデータセットを定義できます。 Apache Spark の組み込み操作、UDF、カスタム ロジック、MLflow モデルをパイプラインの変換として使用できます。 データがパイプラインに取り込まれた後、アップストリーム ソースに対して新しいデータセットを定義して、新しいストリーミング テーブル、具体化されたビュー、ビューを作成できます。
ビュー、具体化されたビュー、ストリーミング テーブルの選択に関するガイダンスについては、「 パイプラインとは」を参照してください。 パイプラインでステートフル処理を効果的に実行する方法については、「 ウォーターマークを使用してステートフル処理を最適化する」を参照してください。
ターゲット スキーマからテーブルを除外する
外部使用を意図していない中間テーブルを計算する必要がある場合は、PRIVATE キーワードを使用して、テーブルがスキーマに発行されないようにすることができます。 プライベート テーブルは引き続きパイプライン セマンティクスに従ってデータを格納および処理しますが、現在のパイプラインの外部にはアクセスしないでください。 プライベート テーブルは、それを作成するパイプラインの有効期間中保持されます。 プライベート テーブルを宣言するには、次の構文を使用します。
SQL
CREATE PRIVATE STREAMING TABLE private_table
AS SELECT ... ;
Python
@dp.table(
private=True)
def private_table():
return ("...")
ストリーミング テーブルと具体化されたビューを 1 つのパイプラインに結合する
ストリーミング テーブルは、Apache Spark 構造化ストリーミングの処理の保証を継承し、追加専用のデータ ソースからのクエリを処理するように構成されています。ここでは、新しい行は変更されるのではなく、常にソース テーブルに挿入されます。
注
ストリーミング テーブルには既定では追加専用のデータ ソースが必要とされますが、更新や削除が必要な別のストリーミング テーブルをストリーミング ソースにする場合は、その動作を skipChangeCommits フラグでオーバーライドできます。
一般的なストリーミング パターンには、パイプラインで初期データセットを作成するためのソース データの取り込みが含まれます。 これらの初期データセットは、一般的にブロンズ テーブルと呼ばれ、多くの場合、単純な変換を実行します。
これに対し、パイプライン内の最終的なテーブル (一般にゴールド テーブルと呼ばれます) では、多くの場合、複雑な集計や AUTO CDC ... INTO 操作のターゲットからの読み取りが必要になります。 これらの操作は本質的に追加ではなく更新を作成するため、ストリーミング テーブルへの入力としてサポートされていません。 これらの変換は、具体化されたビューに適しています。
ストリーミング テーブルと具体化されたビューを 1 つのパイプラインに組み合わせると、パイプラインを簡素化し、コストがかかる生データの再取り込みまたは再処理を避け、SQL の全機能を活用して効率的にエンコードおよびフィルター処理されたデータセットに対して複雑な集計を計算することができます。 次の例は、この種類の混合処理を示しています。
注
これらの例では、自動ローダーを使用してクラウド ストレージからファイルを読み込みます。 Unity Catalog が有効になったパイプラインで自動ローダーを使用してファイルを読み込むには、外部の場所を使用する必要があります。 パイプラインで Unity カタログを使用する方法の詳細については、「パイプライン で Unity カタログを使用する」を参照してください。
Python
@dp.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dp.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dp.materialized_view
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.read.table("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM STREAM read_files(
"abfss://path/to/raw/data",
format => "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
自動ローダーを使用して Azure Storage から JSON ファイルを増分的に取り込む方法について説明します。
ストリーム静的結合
ストリーム静的結合は、主に静的なディメンション テーブルを使用して追加専用のデータの連続したストリームを非正規化する場合に最適な選択肢です。
パイプラインが更新されるたびに、ストリームからの新しいレコードが静的テーブルの最新のスナップショットと結合されます。 ストリーミング テーブルからの対応するデータが処理された後に、レコードが静的テーブルで追加または更新された場合は、完全な更新が実行されない限り、結果のレコードは再計算されません。
トリガーされた実行に対して構成されたパイプラインでは、静的テーブルは更新が開始された時点での結果を返します。 連続実行に対して構成されたパイプラインでは、静的テーブルに対し、テーブルで更新を処理するたびに最新バージョンのクエリが実行されます。
ストリーム静的結合の例を以下に示します。
Python
@dp.table
def customer_sales():
return spark.readStream.table("sales").join(spark.read.table("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
集計を効率的に計算する
カウント、最小、最大、合計などの単純な分散集計や、平均または標準偏差などの代数集計も、ストリーミング テーブルを使用してインクリメンタルに計算できます。 Databricks では、グループの数が限られているクエリ (GROUP BY country 句を含むクエリなど) には増分集計をお勧めします。 更新ごとに新しい入力データだけが読み取られます。
増分集計を実行するパイプライン クエリの記述の詳細については、「 透かしを使用してウィンドウ集計を実行する」を参照してください。
パイプラインで MLflow モデルを使用する
注
Unity Catalog 対応パイプラインで MLflow モデルを使うには、preview チャネルを使うようにパイプラインを構成する必要があります。
current チャネルを使うには、Hive メタストアに公開するようにパイプラインを構成する必要があります。
パイプラインで MLflow トレーニング済みモデルを使用できます。 MLflow モデルは Azure Databricks で変換として扱われます。つまり、Spark DataFrame の入力に基づいて動作し、結果を Spark DataFrame として返します。 パイプラインは DataFrames に対してデータセットを定義するため、MLflow を使用する Apache Spark ワークロードを、わずか数行のコードでパイプラインに変換できます。 MLflow の詳細については、 Databricks の MLflow に関する説明を参照してください。
MLflow モデルを呼び出す Python スクリプトが既にある場合は、 @dp.table または @dp.materialized_view デコレーターを使用し、変換結果を返すために関数が定義されていることを確認することで、このコードをパイプラインに適応させることができます。 パイプラインでは MLflow が既定でインストールされないため、 %pip install mlflow を使用して MLFlow ライブラリをインストールし、ソースの上部に mlflow と dp をインポートしていることを確認します。 パイプライン構文の概要については、「Python を 使用したパイプライン コードの開発」を参照してください。
パイプラインで MLflow モデルを使用するには、次の手順を実行します。
- MLflow モデルの実行 ID とモデル名を取得します。 実行 ID とモデル名は、MLflow モデルの URI の構築に使用されます。
- この URI を使用して、MLflow モデルを読み込む Spark UDF を定義します。
- テーブル定義で UDF を呼び出して、MLflow モデルを使用します。
次の例は、このパターンの基本的な構文を示しています。
%pip install mlflow==2.20.2
from pyspark import pipelines as dp
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dp.materialized_view
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
完全な例として、次のコードでは、ローン リスク データでトレーニングされた MLflow モデルを読み込む loaded_model_udf という名前の Spark UDF を定義します。 予測を行うために使用するデータ列は、引数として UDF に渡されます。 テーブル loan_risk_predictions では、loan_risk_input_data の各行の予測を計算します。
%pip install mlflow==2.20.2
from pyspark import pipelines as dp
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dp.materialized_view(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
手動での削除または更新の保持
パイプラインを使用すると、テーブルからレコードを手動で削除または更新したり、更新操作を実行してダウンストリーム テーブルを再計算したりできます。
既定では、パイプラインは更新されるたびに入力データに基づいてテーブルの結果を再計算するため、削除されたレコードがソース データから再読み込みされないようにする必要があります。
pipelines.reset.allowed テーブル プロパティを false に設定すると、テーブルへの更新は防止されますが、テーブルへの増分書き込み、または新しいデータがテーブルに流れるのが防止されることはありません。
次の図は、2 つのストリーミング テーブルを使用した例を示しています。
-
raw_user_tableでソースから生のユーザー データを取り込む。 -
bmi_tableは、raw_user_tableの体重と身長を使用して BMI スコアをインクリメンタルに計算する。
raw_user_table からユーザー レコードを手動で削除または更新し、bmi_table を再計算する必要があります。
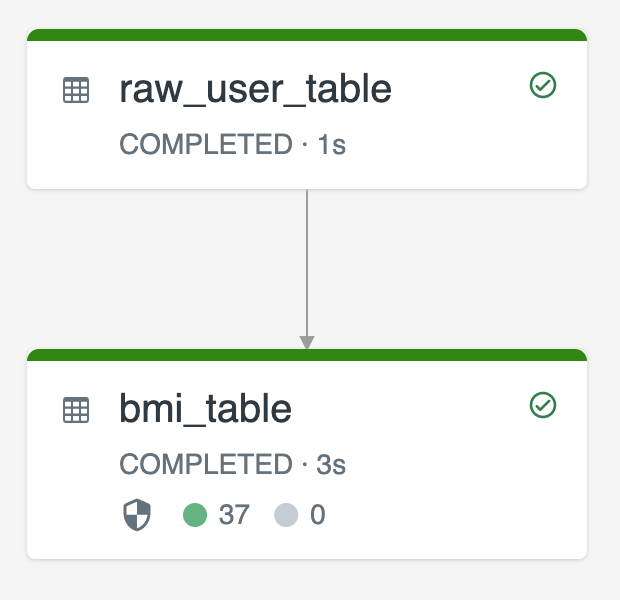
次のコードでは、pipelines.reset.allowed テーブル プロパティを false に設定し、raw_user_table の完全更新を無効にして、意図した変更が経時的に維持されるようにしますが、パイプラインの更新の実行時にダウンストリーム テーブルが再計算されることを示しています。
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM STREAM read_files("/databricks-datasets/iot-stream/data-user", format => "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);