自動ローダーを使用したデータ オーケストレーション用の新しい Lakeflow パイプラインを作成し、データをクリーニングし、上位 100 人のユーザーを検索するクエリを作成してサンプル パイプラインを拡張します。
このチュートリアルでは、Lakeflow Pipelines エディターを使用して次の操作を行う方法について説明します。
- 既定のフォルダー構造で新しいパイプラインを作成し、一連のサンプル ファイルから始めます。
- 期待値を使用してデータ品質制約を定義します。
- エディター機能を使用して、新しい変換でパイプラインを拡張し、データの分析を実行します。
Requirements
このチュートリアルを開始する前に、次の作業を行う必要があります。
- Azure Databricks ワークスペースにログインします。
- ワークスペースに対して Unity カタログを有効にします。
- コンピューティング リソースを作成したり、コンピューティング リソースにアクセスしたりするためのアクセス許可を持っている。
- カタログに新しいスキーマを作成するためのアクセス許可を持っている。 必要なアクセス許可は、
ALL PRIVILEGESまたはUSE CATALOGとCREATE SCHEMAです。 - パイプラインとその出力を作成、実行、更新、および表示するために必要な権限の完全なセットについては、「パイプラインの ID、アクセス許可、および特権の管理」を参照してください。
手順 1: パイプラインを作成する
この手順では、既定のフォルダー構造とコード サンプルを使用してパイプラインを作成します。 コード サンプルは、users サンプル データ ソースのwanderbricks テーブルを参照します。
Azure Databricks ワークスペースで、
 New をクリックします。 次に、
New をクリックします。 次に、 ETL パイプライン。 これにより、
ETL パイプライン。 これにより、 New Pipeline <date> <time>などの既定のパイプライン名でパイプライン エディターが開きます。(省略可能)名前を選択し、パイプラインのわかりやすい名前を入力します。
(省略可能)名前の右側にあるカタログとスキーマをクリックして、別の既定値を設定します。
(省略可能)作成した
my_transformationソース ファイルで、言語ドロップダウン リストから Python または SQL を選択して、ファイルの言語を設定します。[
![コード] アイコンをクリックします。](../_static/images/product-icons/codeicon.svg) サンプル コードを使用します。
サンプル コードを使用します。選択した言語のサンプル コードが、
my_transformationフォルダーのtransformationsソース ファイルに表示されます。 出力データセットはまだ作成されておらず、画面の右側の パイプライン グラフ は空です。パイプライン コード (
transformationsフォルダー内のコード) を実行するには、画面の右上にある [ パイプラインの実行 ] をクリックします。実行が完了すると、ワークスペースの下部に、作成された 2 つの新しいテーブル (
sample_users_<date_time>とsample_aggregation_<date_time>) が表示されます。 ワークスペースの右側にあるパイプライン グラフには、sample_usersのソースであるsample_aggregationを含む 2 つのテーブルが表示されるようになりました。 完全なsample_users_<date_time>テーブル名を書き留めます。次の手順で参照します。
手順 2: データ品質チェックを適用する
この手順では、データ品質チェックを sample_users テーブルに追加します。 パイプラインの 期待値を 使用して、データを制限します。 この場合、有効な電子メール アドレスを持たないユーザー レコードを削除し、クリーニングされたテーブルを users_cleanedとして出力します。
左側の パイプライン 資産ブラウザー で、[
をクリックし、[変換] を選択 します。[ 新しい変換ファイルの作成 ] ダイアログで、次の項目を選択します。
- <
Python またはSQL Language を選択します。 これは、前の選択内容と一致する必要はありません。 - ファイルに名前を付けます。 この場合は、[
users_cleaned] を選択します。 - [宛先パス] では、既定値のままにします。
- [データセットの種類] では、[なし] を選択したままにするか、[具体化されたビュー] を選択します。 具体化されたビューを選択すると、サンプル コードが生成されます。
- <
[ 作成 ] をクリックして変換コード ファイルを作成します。
新しいコード ファイルで、次に一致するようにコードを編集します (前の画面の選択内容に基づいて、SQL またはPythonを使用します)。
sample_users_<date_time>は、前のセクションのsample_usersテーブルの完全な名前に置き換えます。SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )[ パイプラインの実行 ] をクリックしてパイプラインを更新します。 これで 3 つのテーブルが作成されます。
手順 3: 上位のユーザーを分析する
次に、作成した予約数で上位 100 人のユーザーを取得します。
wanderbricks.bookings テーブルをusers_cleanedマテリアライズド ビューに結合します。
左側のパイプライン 資産ブラウザーで、[
をクリックし、[変換] を選択 します。[ 新しい変換ファイルの作成 ] ダイアログで、次の項目を選択します。
- <
Python またはSQL Language を選択します。 これは、以前の選択内容と一致する必要はありません。 - ファイルに名前を付けます。 この場合は、[
users_and_bookings] を選択します。 - [宛先パス] では、既定値のままにします。
- [データセットの種類] では、[なし] を選択したままにします。
- <
[ 作成 ] をクリックして変換コード ファイルを作成します。
新しいコード ファイルで、次に一致するようにコードを編集します (前の画面の選択内容に基づいて、SQL またはPythonを使用します)。
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )[ パイプラインの実行 ] をクリックしてデータセットを更新します。 実行が完了すると、 パイプライン グラフ に、新しい
users_and_bookingsテーブルを含む 4 つのテーブルがあることを確認できます。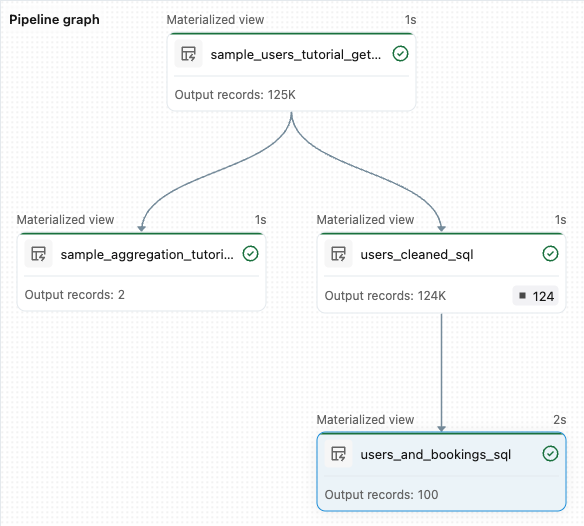
その他のリソース
これで、Lakeflow パイプライン エディターの機能の一部を使用してパイプラインを作成する方法を学習しました。詳細については、次の他の機能を参照してください。
パイプラインの作成時に変換を操作およびデバッグするためのツール:
- 選択的な実行
- データプレビュー
- 対話型パイプライン グラフ (パイプライン内のデータセットのグラフ)
組み込みの 宣言型オートメーション バンドル 統合により、効率的なコラボレーション、バージョン管理、CI/CD 統合をエディターから直接行うことができます。