Important
この機能は試験段階です。
この記事では、メトリック ビューに具体化を使用してクエリのパフォーマンスを高速化する方法について説明します。
メトリック ビューの具体化は、具体化されたビューを使用してクエリを高速化します。 Lakeflow Spark 宣言型パイプラインは、特定のメトリック ビューに対してユーザー定義の具体化されたビューを調整します。 クエリ時に、クエリ オプティマイザーは、自動集計対応クエリ 照合 (クエリ書き換えとも呼ばれます) を使用して、メトリック ビューのユーザー クエリを最適な具体化されたビューにインテリジェントにルーティングします。
この方法では、事前計算と自動増分更新の利点があるため、さまざまなパフォーマンス目標を照会するために集計テーブルまたは具体化されたビューを決定する必要がなく、個別の運用パイプラインを管理する必要がなくなります。
概要
次の図は、メトリック ビューが定義とクエリの実行を処理する方法を示しています。
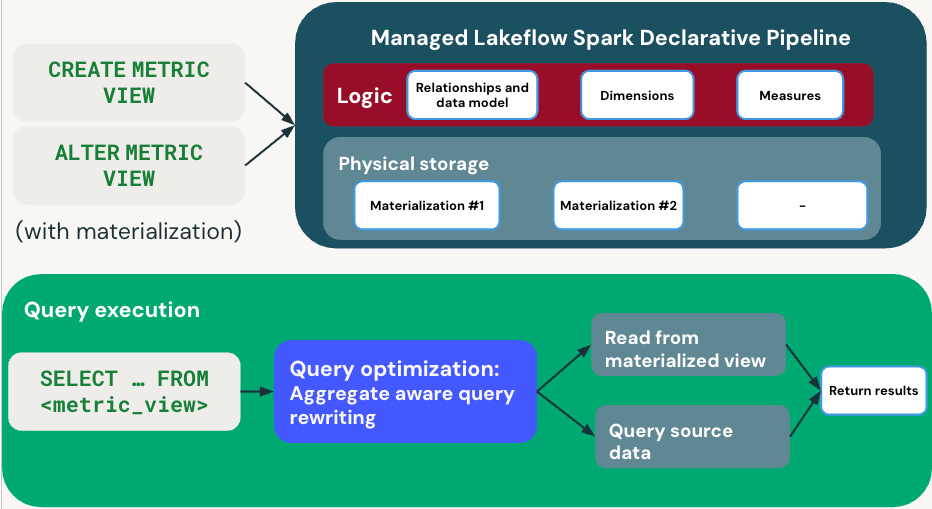
定義フェーズ
メトリック ビューを具体化を使用して定義する場合、ディメンション、メジャー、および更新スケジュールがCREATE METRIC VIEW またはALTER METRIC VIEWによって指定されます。 Databricks は、具体化されたビューを維持する マネージド パイプライン を作成します。
クエリ実行
SELECT ... FROM <metric_view>を実行すると、クエリ オプティマイザーは集計対応クエリの書き換えを使用してパフォーマンスを最適化します。
- 高速パス: 事前に計算された具体化されたビュー (該当する場合) からの読み取り。
- フォールバック パス: 具体化が使用できない場合に、ソース データから直接読み取ります。
クエリ オプティマイザーは、具体化されたデータとソース データを選択することで、パフォーマンスと鮮度のバランスを自動的に調整します。 どのパスが使用されているかに関係なく、透過的に結果を受け取ります。
Requirements
メトリック ビューに具体化を使用するには:
- ワークスペースでサーバーレス コンピューティングが有効になっている必要があります。 これは、Lakeflow Spark 宣言パイプラインを実行するために必要です。
- Databricks Runtime 17.2 以降。
構成参照
具体化に関連するすべての情報は、メトリック ビューの YAML 定義の materialization という名前の最上位フィールドで定義されます。
注
この機能がロールアウトされると、バージョン 1.1 のマテリアライズされたメトリック ビューで、基になるパイプライン に次のエラーが発生する可能性があります。
[METRIC_VIEW_INVALID_VIEW_DEFINITION] The metric view definition is invalid. Reason: Invalid YAML version: 1.1.
この場合は、代わりにバージョン 0.1 を使用してください。 バージョン 0.1 では、バージョン 1.1 で使用できる一部の機能がサポートされていないことに注意してください。 メトリック ビューの具体化は、今後数週間以内にすべてのワークスペースで利用できるようになります。
materialization フィールドには、次の必須フィールドが含まれています。
- schedule: 具体化されたビューの schedule 句と同じ構文をサポートします。
-
mode:
relaxedに設定する必要があります。 -
materialized_views: マテリアライズドビューとして具体化するビューの一覧。
- name: 具体化の名前。
- ディメンション: 具体化するディメンションの一覧。 ディメンション名への直接参照のみが許可されます。式はサポートされていません。
- 対策: 具体化するための対策の一覧。 メジャー名への直接参照のみが許可されます。式はサポートされていません。
-
type: 具体化されたビューを集計するかどうかを指定します。
aggregatedとunaggregatedの 2 つの値を受け入れます。-
typeがaggregatedの場合は、少なくとも 1 つのディメンションまたはメジャーが必要です。 -
typeがunaggregatedされている場合は、ディメンションまたはメジャーを定義しないでください。
-
注
TRIGGER ON UPDATE句は、メトリック ビューの具体化ではサポートされていません。
定義の例
version: 0.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
Mode
relaxed モードでは、クエリの自動書き換えは、候補の具体化されたビューにクエリを処理するために必要なディメンションとメジャーがあるかどうかを確認するだけです。
これは、いくつかのチェックがスキップされることを意味します。
- 具体化されたビューが最新かどうかのチェックはありません。
- 一致する SQL 設定 (
ANSI_MODEやTIMEZONEなど) があるかどうかのチェックはありません。 - 具体化されたビューが確定的な結果を返すかどうかのチェックはありません。
クエリに次のいずれかの条件が含まれている場合、クエリの書き換えは行われず、クエリはソース テーブルにフォールバックします。
- マテリアライズドビューにおける行レベル セキュリティ (RLS) または列レベル マスキング (CLM)。
- 具体化されたビューの
current_timestamp()のような非決定論的関数。 これらは、メトリック ビューの定義またはメトリック ビューで使用されるソース テーブルに表示される場合があります。
注
試験段階のリリース期間中は、 relaxed のみがサポートされるモードです。 これらのチェックが失敗した場合、クエリはソース データにフォールバックします。
メトリック ビューの具体化の種類
以降のセクションでは、メトリック ビューで使用できる具体化されたビューの種類について説明します。
集計型
この型は、対象範囲の指定されたメジャーとディメンションの組み合わせの集計を事前に計算します。
これは、特定の一般的な集計クエリ パターンまたはウィジェットをターゲットにするのに役立ちます。 Databricks では、具体化されたビュー構成に、潜在的なフィルター列をディメンションとして含めるようにすることをお勧めします。 フィルター列として考えられるのは、 WHERE 句のクエリ時に使用される列です。
集計されていない型
この型は、集計された型に比べてパフォーマンス上昇が少なく、より広い範囲で対応できるように、集計されていないデータ モデル全体 ( source、 join、 filter フィールドなど) を具体化します。
以下の条件が満たされるときに、この型を使用します。
- ソースは、コストの高いビューまたは SQL クエリです。
- メトリック ビューで定義されている結合はコストがかかります。
注
ソースが選択的フィルターが適用されていない直接テーブル参照である場合、未集計の具体化されたビューでは利点が得られない可能性があります。
具体化のライフサイクル
このセクションでは、具体化がライフサイクル全体にわたってどのように作成、管理、更新されるかについて説明します。
作成と変更
メトリック ビューの作成または変更 ( CREATE、 ALTER、またはカタログ エクスプローラーを使用) は同期的に行われます。 指定された具体化されたビューは、Lakeflow Spark 宣言パイプラインを使用して非同期的に具体化されます。
メトリック ビューを作成すると、Databricks によって Lakeflow Spark 宣言パイプライン パイプラインが作成され、具体化されたビューが指定されている場合は、すぐに初期更新がスケジュールされます。 メトリック ビューは、ソース データからのクエリにフォールバックすることで、具体化されずにクエリ可能なままになります。
メトリック ビューを変更する場合、初めて具体化を有効にしない限り、新しい更新はスケジュールされません。 具体化されたビューは、次回のスケジュールされた更新が完了するまで、クエリの自動書き換えに使用されません。
具体化スケジュールを変更しても、更新はトリガーされません。
更新の動作を細かく制御するには、「 手動 更新」を参照してください。
基になるパイプラインを検査する
メトリック ビューの具体化は、Lakeflow Spark 宣言パイプラインを使用して実装されます。 パイプラインへのリンクは、カタログ エクスプローラーの [ 概要 ] タブに表示されます。 カタログ エクスプローラーにアクセスする方法については、「カタログ エクスプローラー とは」を参照してください。
メトリック ビューで DESCRIBE EXTENDED を実行して、このパイプラインにアクセスすることもできます。 [ 情報の更新 ] セクションには、パイプラインへのリンクが含まれています。
DESCRIBE EXTENDED my_metric_view;
出力例:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE TABLE EXTENDED customer;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh information
Latest Refresh status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 3 HOURS
手動更新
Lakeflow Spark 宣言パイプラインへのリンクから、パイプラインの更新を手動で開始してマテリアライゼーションを更新できます。 パイプライン ID に基づく API 呼び出しを使用して、これを調整することもできます。
たとえば、次の Python スクリプトはパイプラインの更新を開始します。
from databricks.sdk import WorkspaceClient
client = WorkspaceClient()
pipeline_id = "01484540-0a06-414a-b10f-e1b0e8097f15"
client.pipelines.start_update(pipeline_id)
Lakeflow ジョブの一部として手動更新を実行するには、上記のロジックを使用して Python スクリプトを作成し、 Python スクリプト型のタスクとして追加します。 または、同じロジックを使用してノートブックを作成し、 Notebook 型のタスクを追加することもできます。
増分更新
具体化されたビューでは、可能な限り増分更新が使用され、データ ソースとプラン構造に関して同じ制限があります。
前提条件と制限の詳細については、 具体化されたビューの増分更新を参照してください。
クエリの自動書き換え
メトリックビューへのクエリは、できるだけその具体化を利用しようとします。 クエリ書き換え戦略には、完全一致と未集計の一致の 2 つがあります。

メトリック ビューに対してクエリを実行すると、オプティマイザーはクエリと使用可能なユーザー定義の具体化を分析します。 クエリは、次のアルゴリズムを使用して、ベース テーブルではなく、最適な具体化で自動的に実行されます。
- 最初に完全一致を試みます。
- 未集計マテリアライズが存在する場合は、未集計の適合を試みます。
- クエリの書き換えが失敗した場合、クエリはソース テーブルから直接読み取ります。
注
具体化は、クエリの書き換えを有効にする前に具体化を完了する必要があります。
クエリで具体化されたビューが使用されていることを確認する
クエリが具体化されたビューを使用しているかどうかを確認するには、クエリで EXPLAIN EXTENDED 実行してクエリ プランを表示します。 クエリで具体化されたビューを使用している場合、リーフ ノードには、YAML ファイルからの具体化の名前 __materialization_mat___metric_view が含まれます。
または、クエリ プロファイルに同じ情報が表示されます。
完全一致
完全一致戦略の対象にするには、クエリのグループ化式が具体化ディメンションと正確に一致する必要があります。 クエリの集計表現は、マテリアライゼーションメジャーのサブセットである必要があります。
集計されていないマッチ
未集計の具体化が使用可能な場合、この戦略は常に対象となります。
Billing
具体化されたビューを更新すると、Lakeflow Spark 宣言パイプラインの使用料金が発生します。
既知の制限事項
メトリック ビューの具体化には、次の制限が適用されます。
- 別のメトリック ビューをソースとして参照する具体化を含むメトリック ビューには、未集計の具体化を含めることはできません。