このクイック スタートでは、Rust を使用して基本的な Azure DocumentDB アプリケーションを作成します。 Azure DocumentDB は、アプリケーションがドキュメントをクラウドに格納し、公式の MongoDB ドライバーを使用してアクセスできるようにする NoSQL データ ストアです。 このガイドでは、Rust を使用して Azure DocumentDB クラスターでドキュメントを作成し、基本的なタスクを実行する方法について説明します。
API リファレンス | ソース コード | パッケージ (crates.io)
Prerequisites
Azure サブスクリプション
- Azure サブスクリプションがない場合は、無料アカウントを作成してください。
- Rust 1.70 以降
Azure DocumentDB クラスターを作成する
最初に、NoSQL データを格納および管理するための基盤として機能する Azure DocumentDB クラスターを作成する必要があります。
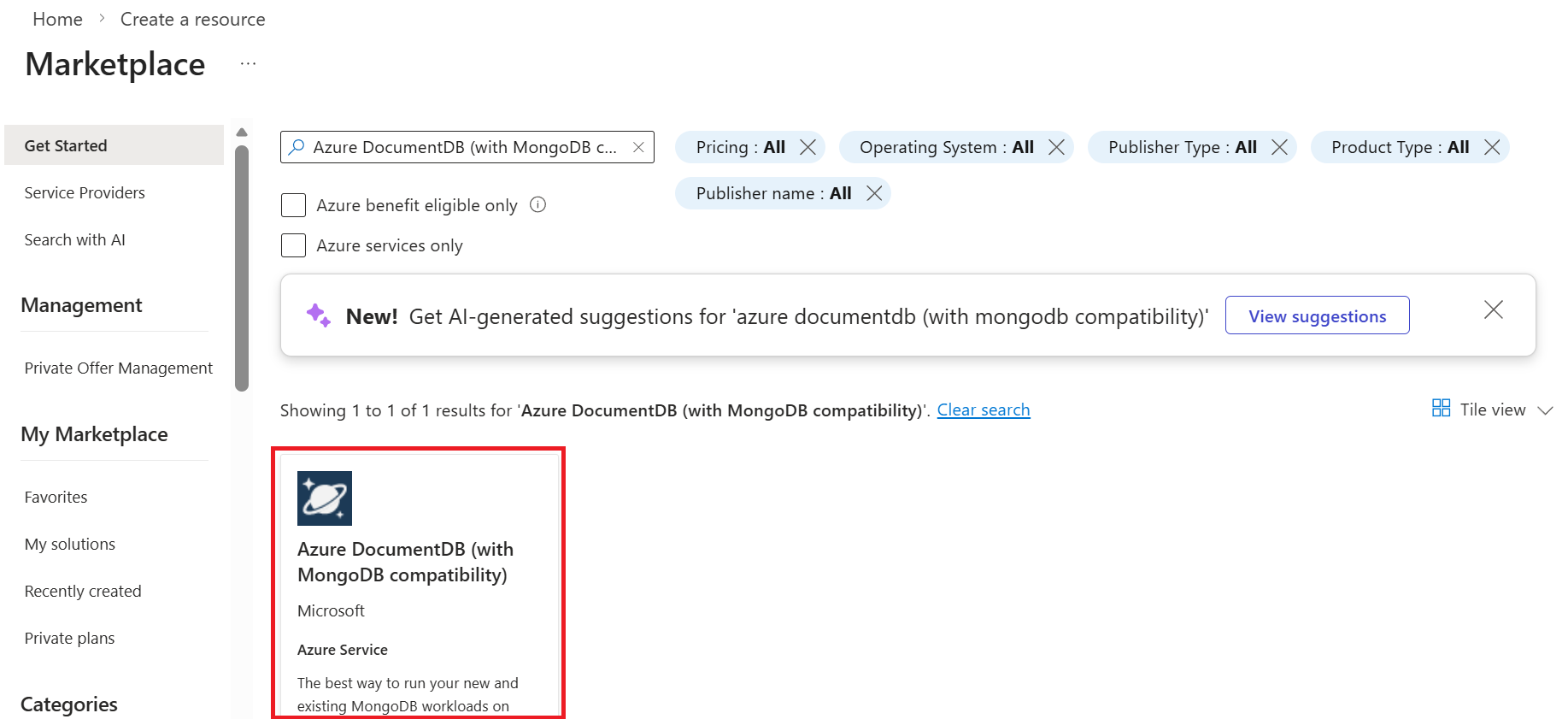
Azure portal にサインインします (https://portal.azure.com)。
Azure ポータル メニューまたは Home ページで、リソースの作成を選択します。
New ページで、Azure DocumentDB を検索して選択します。
[Azure DocumentDB クラスターの作成] ページと [基本] セクションで、[クラスター層] セクションで [構成] オプションを選択します。

[ スケール ] ページで、これらのオプションを構成し、[ 保存] を選択して変更をクラスター層に保持します。
Value クラスター レベル M30 tier, 2 vCore, 8-GiB RAMシャードあたりのストレージ 128 GiB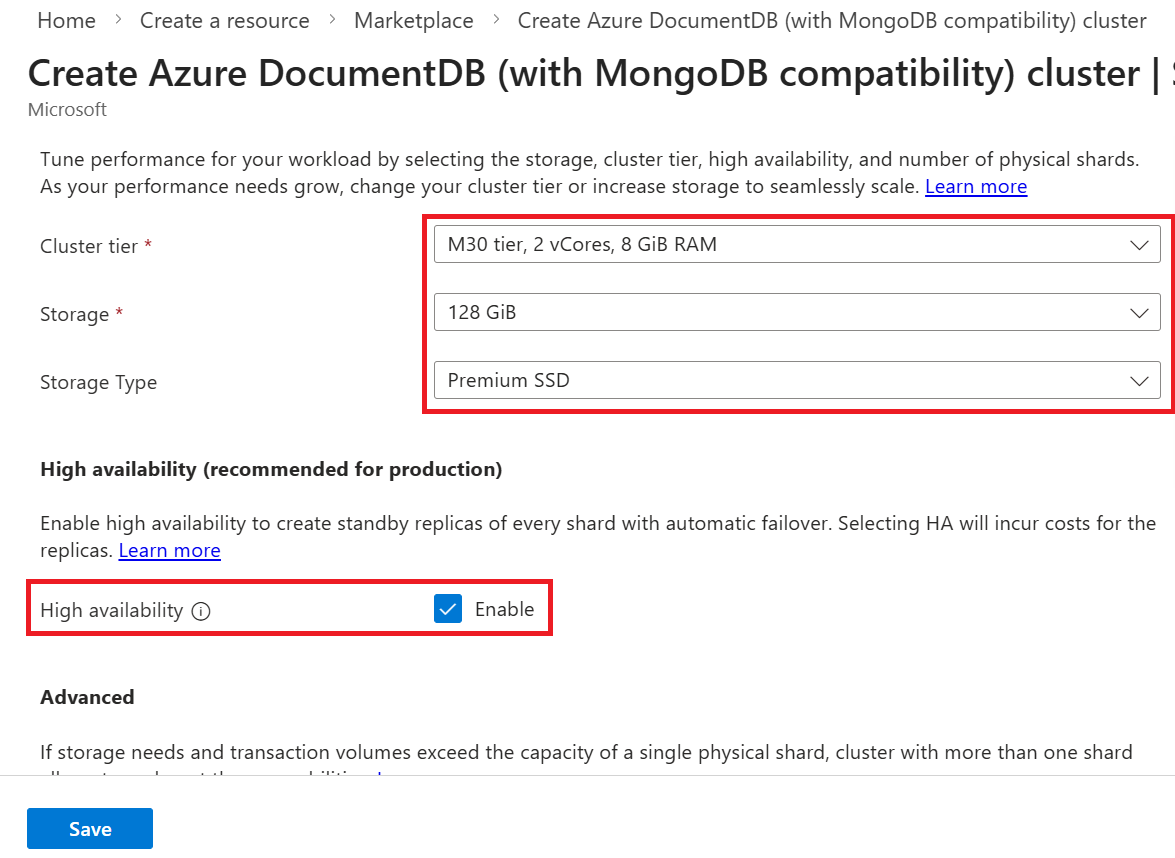
[基本] セクションに戻り、次のオプションを構成します。
Value サブスクリプション お使いの "Azure サブスクリプション" を選択します リソース グループ 新しいリソース グループを作成するか、既存のリソース グループを選択 クラスター名 グローバルに一意の名前を指定 場所 サブスクリプションでサポートされているAzure リージョンを選択する MongoDB バージョン 選択する 8.0管理者ユーザー名 ユーザー管理者としてクラスターにアクセスするためのユーザー名を作成する パスワード ユーザー名に関連付けられている一意のパスワードを使用する 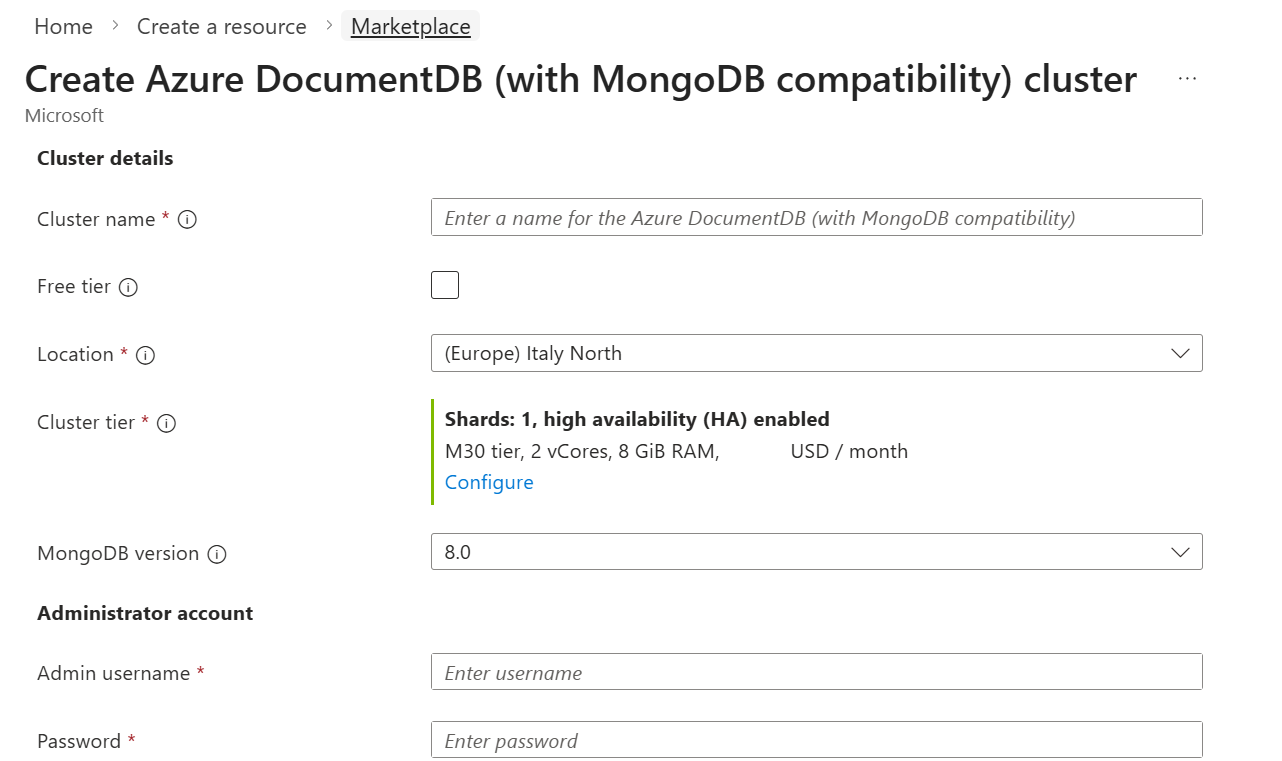
Tip
ユーザー名とパスワードに使用する値を記録します。 これらの値は、このガイドの後半で使用します。 有効な値の詳細については、 クラスターの制限事項を参照してください。
[次へ: ネットワーク] を選択します。
[ネットワーク] タブの [ ファイアウォール規則 ] セクションで、次のオプション を 構成します。
Value 接続方法 Public accessAzure 内の Azure サービスとリソースからこのクラスターへのパブリック アクセスを許可する 有効 [+ 現在のクライアント IP アドレスの追加] を選択して、クラスターへのアクセスを許可する現在のクライアント デバイスのファイアウォール規則を追加します。
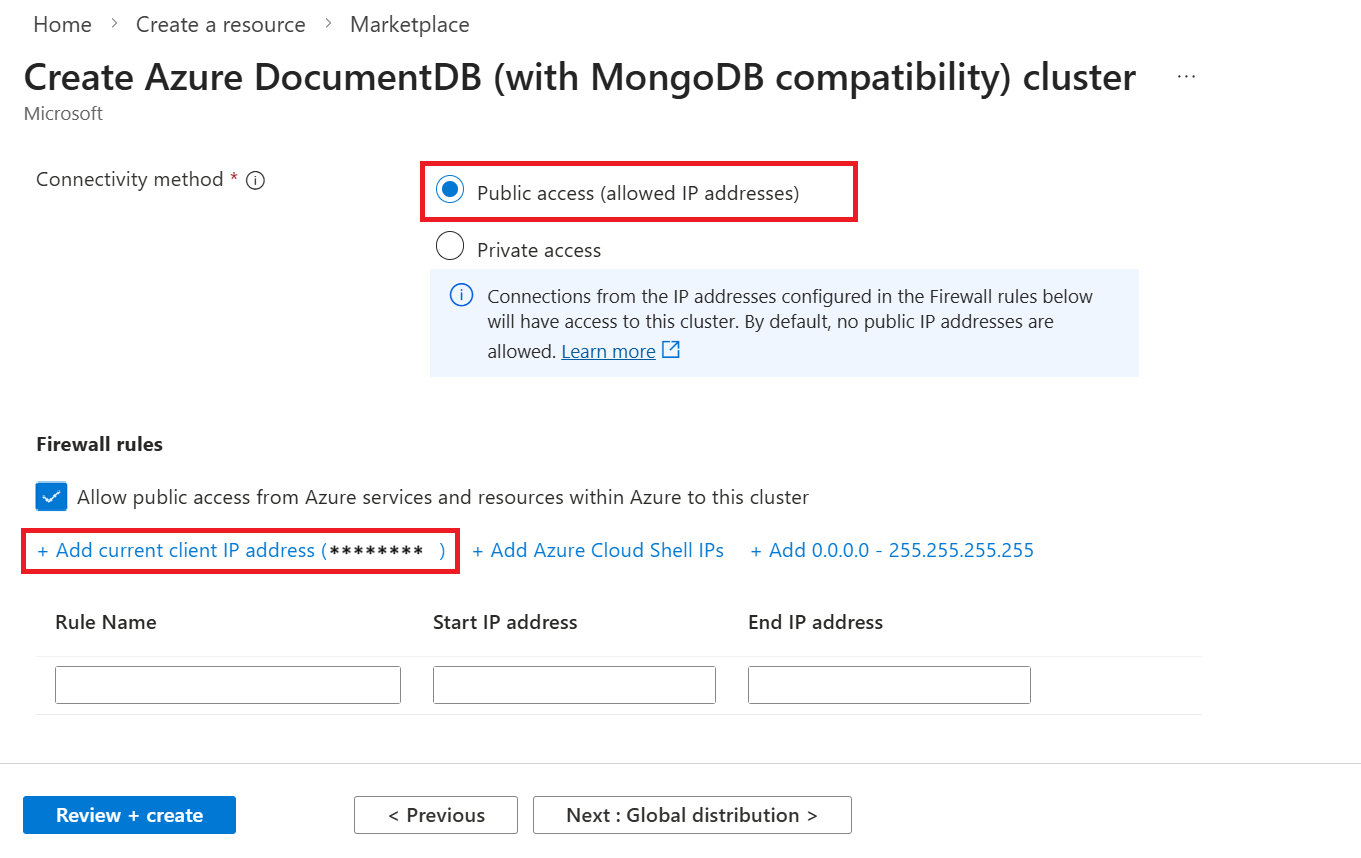
Tip
多くの企業環境では、VPN やその他の企業ネットワーク設定により、開発者用コンピューターの IP アドレスが非表示になっています。 このような場合は、
0.0.0.0-255.255.255.255IP アドレス範囲をファイアウォール規則として追加することで、すべての IP アドレスへのアクセスを一時的に許可できます。 このファイアウォール規則は、接続テストと開発の一環として一時的にのみ使用してください。[Review + create](レビュー + 作成) を選択します。
指定した設定を確認し、[作成] を選択します。 クラスターの作成には数分かかります。 リソースのデプロイが完了するまで待ちます。
最後に、Go to resource を選択して、ポータルで Azure DocumentDB クラスターに移動します。
クラスターの資格情報を取得する
クラスターへの接続に使用する資格情報を取得します。
クラスター ページで、リソース メニューの [接続文字列 ] オプションを選択します。
[ 接続文字列 ] セクションで、[ 接続文字列 ] フィールドの値をコピーまたは記録します。

Important
ポータルの接続文字列には、パスワードの値は含まれません。
<password> プレースホルダーは、クラスターの作成時に入力した資格情報に置き換えるか、対話形式でパスワードを入力する必要があります。
プロジェクトを初期化する
現在のディレクトリに新しい Rust プロジェクトを作成します。
空のディレクトリから開始します。
現在のディレクトリでターミナルを開きます。
Cargo を使用して新しい Rust プロジェクトを作成します。
cargo new azure-documentdb-rust-quickstart cd azure-documentdb-rust-quickstart
クライアント ライブラリをインストールする
クライアント ライブラリは、 mongodb クレートとして、crates.io を介して使用できます。
Cargo を使用して MongoDB Rust ドライバーを追加します。
cargo add mongodb非同期操作用の
tokioランタイムを追加します。cargo add tokio --features fullシリアル化をサポートするために、
serdeクレートを追加します。cargo add serde --features derive非同期ストリーム操作用の
futuresクレートを追加します。cargo add futuresアプリケーション コードの src/main.rs ファイルを開きます。
必要なモジュールをアプリケーション コードにインポートします。
use futures::TryStreamExt; use mongodb::{ bson::doc, options::ClientOptions, Client, Collection, }; use serde::{Deserialize, Serialize};
オブジェクト モデル
| Name | Description |
|---|---|
Client |
MongoDB への接続に使用される型。 |
Database |
クラスター内のデータベースを表します。 |
Collection<T> |
クラスター内のデータベース内のコレクションを表します。 |
コード例
このアプリケーションのコードは、 adventureworks という名前のデータベースと products という名前のコレクションに接続します。
products コレクションには、名前、カテゴリ、数量、一意の識別子、セールフラグなどの各製品の詳細が含まれています。 このコード サンプルでは、コレクションを操作するときに最も一般的な操作を実行します。
クライアントを認証する
まず、基本的な接続文字列を使用してクライアントに接続します。
メインの非同期関数を作成し、接続文字列を設定します。
<your-cluster-name>、<your-username>、および<your-password>を実際のクラスター情報に置き換えます。#[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { // Connection string for Azure DocumentDB cluster let connection_string = "mongodb+srv://<your-username>:<your-password>@<your-cluster-name>.global.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"; // Parse connection string into client options let client_options = ClientOptions::parse(connection_string).await?;MongoDB クライアントを作成し、接続を確認します。
// Create a new client and connect to the server let client = Client::with_options(client_options)?; // Ping the server to verify connection client .database("admin") .run_command(doc! { "ping": 1 }) .await?; println!("Successfully connected and pinged Azure DocumentDB");
コレクションを取得する
次に、データベースとコレクションを取得します。 データベースとコレクションがまだ存在しない場合は、ドライバーを使用して自動的に作成します。
データベースへの参照を取得します。
// Get database reference let database = client.database("adventureworks"); println!("Connected to database: {}", database.name());データベース内のコレクションへの参照を取得します。
// Get collection reference let collection: Collection<Product> = database.collection("products"); println!("Connected to collection: products");
ドキュメントの作成
次に、コレクション内に新しいドキュメントをいくつか作成します。 ドキュメントをアップサートし、同じ一意識別子を持つ既存のドキュメントがある場合、それを置き換えられるようにします。
Product 構造体を定義し、サンプル製品ドキュメントを作成します。
// Define Product struct for type-safe operations #[derive(Debug, Serialize, Deserialize)] struct Product { #[serde(rename = "_id")] id: String, name: String, category: String, quantity: i32, price: f64, sale: bool, } // Create sample products let products = vec![ Product { id: "00000000-0000-0000-0000-000000004018".to_string(), name: "Windry Mittens".to_string(), category: "apparel-accessories-gloves-and-mittens".to_string(), quantity: 121, price: 35.00, sale: false, }, Product { id: "00000000-0000-0000-0000-000000004318".to_string(), name: "Niborio Tent".to_string(), category: "gear-camp-tents".to_string(), quantity: 140, price: 420.00, sale: true, }, ];upsert 操作を使用してドキュメントを挿入します。
// Insert documents with upsert for product in &products { let filter = doc! { "_id": &product.id }; let update = doc! { "$set": mongodb::bson::to_document(product)? }; let result = collection .update_one(filter, update) .upsert(true) .await?; if result.upserted_id.is_some() { println!("Inserted document with ID: {}", product.id); } else { println!("Updated document with ID: {}", product.id); } }
ドキュメントを取得する
次に、ポイント読み取り操作を実行して、コレクションから特定のドキュメントを取得します。
ID で特定のドキュメントを検索するフィルターを定義します。
// Retrieve a specific document by ID let filter = doc! { "_id": "00000000-0000-0000-0000-000000004018" };クエリを実行し、結果を取得します。
let retrieved_product = collection.find_one(filter).await?; match retrieved_product { Some(product) => println!("Retrieved product: {} - ${:.2}", product.name, product.price), None => println!("Product not found"), }
ドキュメントにクエリを実行する
最後に、MongoDB クエリ言語 (MQL) を使用して複数のドキュメントに対してクエリを実行します。
特定の条件に一致するドキュメントを検索するクエリを定義します。
// Query for products on sale let query_filter = doc! { "sale": true }; let mut cursor = collection.find(query_filter).await?;カーソルをイテレーションして、一致するすべてのドキュメントを取得します。
println!("Products on sale:"); while let Some(product) = cursor.try_next().await? { println!( "- {}: ${:.2} (Category: {})", product.name, product.price, product.category ); } Ok(()) }
Visual Studio Code を使用してデータを探索する
Visual Studio Code の DocumentDB 拡張機能を使用して、データのクエリ、挿入、更新、削除などの主要なデータベース操作を実行します。
Visual Studio Code を開きます。
[拡張機能] ビューに移動し、
DocumentDBという用語を検索します。 VS Code 用 DocumentDB 拡張機能を見つけます。拡張機能の [インストール ] ボタンを選択します。 インストールが完了するまで待ちます。 プロンプトが表示されたら、Visual Studio Code をリロードします。
アクティビティ バーで対応するアイコンを選択して 、DocumentDB 拡張機能に移動します。
[DocumentDB 接続] ウィンドウで、[ + 新しい接続...] を選択します。
ダイアログで、[ サービスの検出 ] を選択し、[ Azure DocumentDB - Azure Service Discovery] を選択します。
Azure サブスクリプションと、新しく作成した Azure DocumentDB クラスターを選択します。
Tip
多くの企業環境では、VPN やその他の企業ネットワーク設定により、開発者用コンピューターの IP アドレスが非表示になっています。 このような場合は、
0.0.0.0-255.255.255.255IP アドレス範囲をファイアウォール規則として追加することで、すべての IP アドレスへのアクセスを一時的に許可できます。 このファイアウォール規則は、接続テストと開発の一環として一時的にのみ使用してください。 詳細については、「ファイアウォールの 構成」を参照してください。DocumentDB 接続ペインに戻り、クラスターのノードを展開し、既存のドキュメントノードとコレクションノードに移動します。
コレクションのコンテキスト メニューを開き、[ DocumentDB スクラップブック] > [新しい DocumentDB スクラップブック] を選択します。
次の MongoDB クエリ言語 (MQL) コマンドを入力し、[ すべて実行] を選択します。 コマンドからの出力を確認します。
db.products.find({ price: { $gt: 200 }, sale: true }) .sort({ price: -1 }) .limit(3)
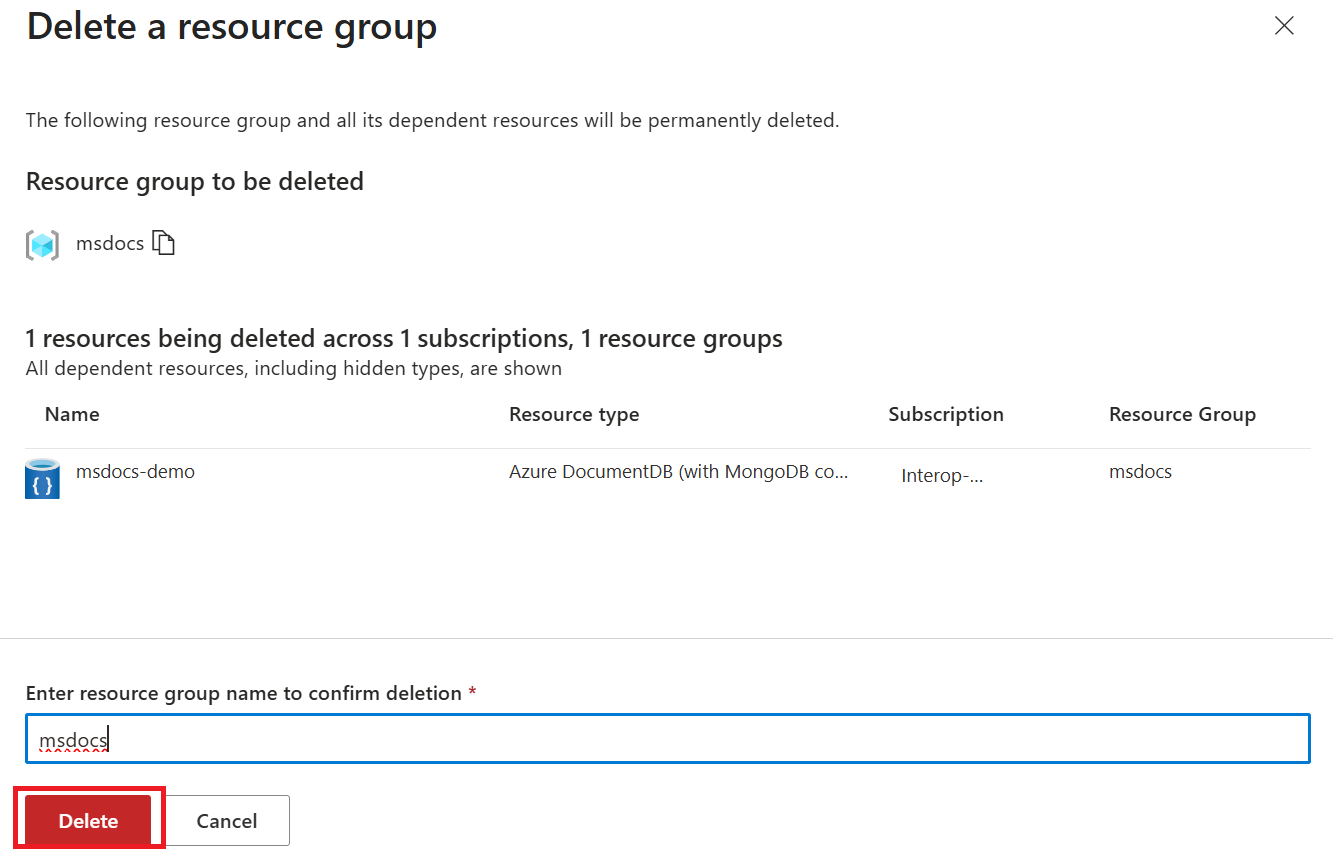
リソースをクリーンアップする
Azure DocumentDB クラスターの使用が完了したら、作成した Azure リソースを削除して、追加の料金が発生しないようにすることができます。
Azure portal の検索バーで、「リソース グループ」を検索して選択します。
一覧で、このクイック スタートで使用したリソース グループを選択します。
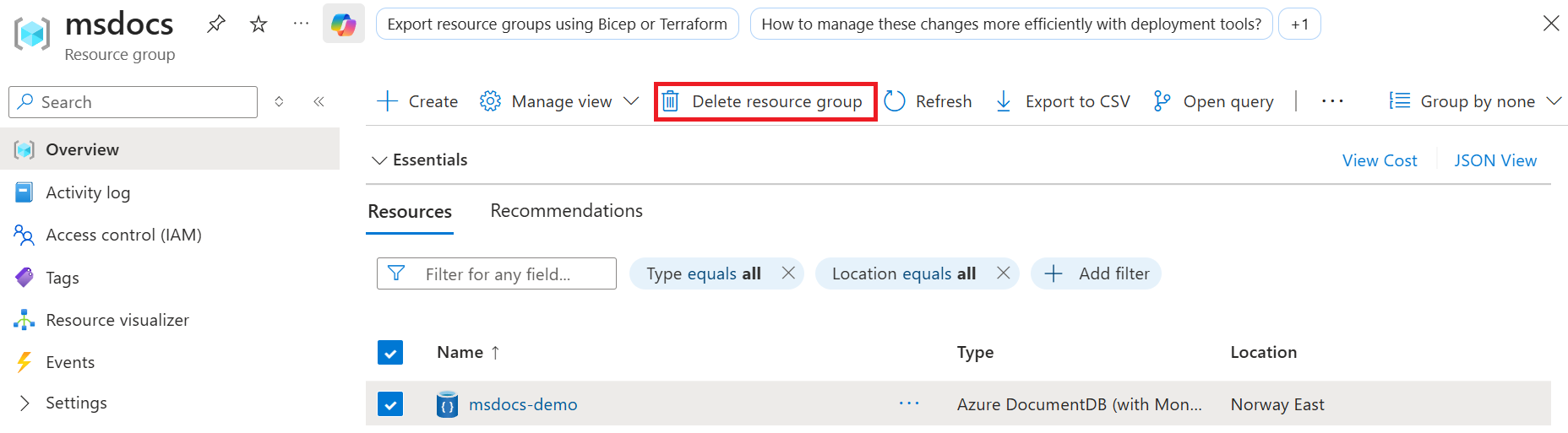
[リソース グループ] ページで、 [リソース グループの削除] を選択します。
削除の確認ダイアログで、リソース グループの名前を入力して、削除することを確認します。 最後に、[削除] を選択して、リソース グループを完全に削除します。