重要
英語以外の翻訳は便宜上のみ提供されています。 詳細なバージョンについては、このドキュメントのEN-USバージョンを参照してください。
透明度に関するメモとは
AI システムには、テクノロジだけでなく、それを使用するユーザー、影響を受けるユーザー、デプロイされる環境も含まれます。 目的に合ったシステムを作成するには、テクノロジのしくみ、その機能と制限事項、および最適なパフォーマンスを実現する方法を理解する必要があります。 Microsoftの透明性に関するメモは、AI テクノロジのしくみ、システム所有者がシステムのパフォーマンスと動作に影響を与える選択肢、およびテクノロジ、人、環境など、システム全体について考えることの重要性を理解するのに役立ちます。 透過性メモは、独自のシステムを開発または展開するときに使用したり、システムを使用したり、システムの影響を受けるユーザーと共有したりできます。
Microsoftの透明性に関するメモは、AI 原則を実践するためのMicrosoftの広範な取り組みの一環です。 詳細については、Microsoft AI の原則を参照してください。
Azure Content Understanding の基本
導入
Content Understanding では、ドキュメント、画像、ビデオ、オーディオなどのモダリティで非構造化コンテンツを取り込み、事前構築済みまたはユーザー定義スキーマから構造化された出力を生成し、コンテンツからのタスク固有のシナリオを最適に表します。 この出力は、データベースへの保存、LLM を使用した推論 (つまり、拡張生成または RAG の取得)、データに対する特定の AI/ML モデルの構築、またはビジネス プロセスを自動化するためのワークフローで使用するために、顧客が開発したシステムに出力を送信するなど、ダウンストリーム アプリケーションによって使用できます。 Content Understanding は、Foundry Tools の
主な用語
| 用語 | 定義 |
|---|---|
| 分類 | これはフィールドの種類の一種です。 フィールドは、フィールド名を使用して入力データの値を分類します。 たとえば、画像に欠陥があるかどうか、または顔に眼鏡が付いているかどうかを分類します。 |
| 信頼度値 | すべての Content Understanding 出力は、抽出されたすべての単語とキーと値のマッピングについて、0 ~ 1 の範囲の信頼度値を返します。 この値は、単語が 100 から正しく抽出された回数、またはキーと値のペアが正しくマップされた回数の推定値の割合を表します。 たとえば、時間の 82% 正しく抽出されると推定される単語は、信頼度値 0.82 になります。 |
| 話者分離 | Diarization では、オーディオ ファイル内で話している話者を示すために、各スピーカー (GUEST1、GUEST2、GUEST3 など) に一時的な匿名ラベルを割り当てることで、各オーディオ録音の個々のスピーカーを区別します。 文字起こしをサポートするすべての Content Understanding API も、ダイアライゼーションをサポートします。 |
| 抽出 | これはフィールドの種類の一種です。 フィールドは、入力データから直接値を抽出します。 たとえば、請求書から日付を抽出したり、ドキュメントから署名を抽出したりします。 |
| 顔検出 | 画像内の人の顔を検出し、顔が存在する場所を示す境界ボックスを返します。顔検出モデルだけでは、個別に識別可能な特徴は見つからず、顔全体を示す境界ボックスのみを返します。 検出されたすべての顔に対して、顔 ID は埋め込みに基づいて割り当てられます。 詳細については、 顔検出の概念に関するドキュメント を参照してください。 |
| 顔のグループ化 | 顔が検出されると、識別された顔がローカル グループにフィルター処理されます。 1 人の人物が複数回検出されると、その人物に対して複数の観察された顔のインスタンスが作成されます。 詳細については、[顔のグループ化に関するドキュメント](/azure/ai-services/computer-vision/overview-identity" \l "group-faces) を参照してください。 |
| 生成 | これはフィールドの種類の一種です。 このフィールドは、親フィールドのコンテンツから値を生成します。 たとえば、ビデオからシーンの説明を生成したり、通話オーディオから要約したりします。 |
| スキーマ | スキーマは、入力から値を抽出するためにお客様が提供する必要があるフィールド名と説明に使用する用語です。 Content Understanding には、シナリオに合わせて事前構築済みのスキーマのセットが用意されています。 シナリオに応じて、Content Understanding には、入力に基づいて入力されるフィールドの定義済みの一覧があります。 これらの事前構築済みスキーマを使用すると、フィールドを自分で定義しなくても、プロジェクトをより迅速に開始できます。 |
| 文字起こし | Content Understanding の自動音声テキスト変換出力機能は、コンピューターの文字起こしまたは自動音声認識 (ASR) とも呼ばれます。 文字起こしは Azure Speech を使用し、完全に自動化されます。 文字起こしをサポートするすべての Content Understanding API も、ダイアライゼーションをサポートします。 |
機能
システムの動作
Content Understanding はクラウドベースの Foundry ツールであり、さまざまな AI/ML モデル (Azure OpenAI Service、Azure Face Service、Azure Speech で使用できるモデルなど) を使用して、顧客の入力ファイルからフィールドを抽出、分類、生成します。 Content Understanding では、お客様が取り込むモデルの統合はサポートされていません。
Content Understanding は、最初にコンテンツを構造化された出力に抽出します。 その後、大きな言語モデル (LLM) を使用してフィールドを生成し、適用可能なフィールドに信頼度スコアを割り当てます。
現在、Content Understanding では、ドキュメント、画像、テキスト、ビデオ、オーディオの種類のデータを取り込むことができます。 ユーザーがアップロードするデータの種類に応じて、Content Understanding は、ユーザーが使用を開始できる一般的な事前構築済みスキーマを自動的に提案します。 また、ユーザーはスキーマ自体をカスタマイズして、より充実したデータ インジェスト機能を実現することもできます。 ユーザーが有害なコンテンツをアップロードした場合、Content Understanding は出力に警告を出して、入力ファイルに有害なコンテンツが含まれていることをユーザーに知らせますが、フィールドは引き続き出力されます。
このサービスの目的は、正規化されたタスク固有の入力データ表現を提供して、顧客に抽出的および生成的なシナリオを可能にし、モダリティ間で一貫したエクスペリエンスを提供することです。 Content Understanding は、非グラウンド推論をサポートするためのものではなく、ユーザーが提供する情報とコンテキストに基づいてのみ出力を生成することに注意してください。
メモ
顔のぼかし
人の画像やビデオを含むビジョンと GPT-4o を備えた GPT-4 Turbo への入力の場合、システムは要求された結果を返す処理の前に顔をぼかします。 ぼかしは、関係する個人とグループのプライバシーを保護するのに役立ちます。 ぼかしは入力候補の品質には影響しませんが、場合によっては、システムが顔のぼかしを参照している場合があります。
重要
個人の識別は、顔認識の結果でも、顔テンプレートの生成と比較の結果でもありません。 識別は、画像のタグ付けを使用して個人の画像を同じ名前に関連付けるためにモデルをトレーニングした結果です。これにより、モデルはその個人の後続の画像入力で名前を返します。 また、モデルは顔以外のコンテキストキューを取得することもできます。これは、顔がぼやけた場合でも、モデルが画像を個人に関連付ける方法です。 たとえば、チームのジャージを着た人気のあるアスリートの写真と特定の番号が画像に含まれている場合でも、モデルはコンテキストキューに基づいて個人を検出できます。
コンテンツのフィルター処理
Azure Content Understanding サービスには、入力プロンプトと出力入力候補の両方で、有害な可能性のあるコンテンツの特定のカテゴリを検出してブロックするコンテンツ フィルタリング システムが含まれています。 API 構成とアプリケーション設計のバリエーションは、完了とフィルター処理の動作に影響を与える可能性があります。 承認されたお客様は、潜在的に有害な出力をブロックするのではなく、注釈を付けるために Content Understanding の既定のコンテンツ フィルタリング システムをカスタマイズできます。
メモ
コンテンツ フィルターを無効にすると、サービスが有害なコンテンツ ( ヘイトや公平性に関連するカテゴリ、 性的、 暴力 、 自傷行為 のカテゴリなど) を効果的にブロックできなくなる可能性があります。 詳細については、「コンテンツフィルタリング」を参照してください。
間接攻撃プロンプト シールドを無効にすると、システムが脆弱性にさらされる可能性があります。第三者は、Generative AI システムからアクセスして処理できるドキュメント内に悪意のある命令を埋め込む可能性があります。 類似の脆弱性は、特定のプロンプトを通じて組み込みのセーフガードを回避し、オーバーライドしようとする脱獄の試みから生じる可能性があります。
Content Understanding への制限付きアクセス
Content Understanding の Face グループ化機能は制限付きアクセス サービスであり、それにアクセスするには登録が必要です。 詳細については、Microsoft の制限付きアクセス ポリシーを参照し、Face API の登録にアクセスします。 特定の機能は、管理対象の顧客と承認されたパートナー Microsoftでのみ使用でき、登録時に選択された特定のユース ケースに対してのみ使用できます。 顔検出、顔属性、顔の編集のユース ケースでは、登録は必要ありません。
メモ
2020年6月11日、Microsoftは、人権に基づく強力な規制が制定されるまで、米国の警察に顔認識技術を販売しないことを発表した。 そのため、お客様がアメリカ合衆国の警察である場合、またはそのようなサービスの使用を警察のために許可している場合、お客様は、Azure サービスに含まれる顔認識機能 (Face、Video Indexer、Content Understanding など) を使用することはできません。
ユースケース例
意図された用途
Content Understanding を使用する場合の例をいくつか次に示します。
- 税プロセスの自動化: Content Understanding のドキュメント抽出機能を使用して、税フォームからフィールドを抽出できます。 さまざまなテンプレートに関係なく、税フォームからキー データを抽出して、税プロセスの自動化をもたらす情報の統一されたビューを生成できます。
- コール センターの通話後分析: 企業は通話記録から分析情報を生成できます。 オーディオ入力はテキスト文字起こし出力に変換されます。これを使用して、コール センターの効率とカスタマー エクスペリエンスの向上につながる貴重な分析情報を抽出できます。
- マーケティングオートメーションとDAM (デジタル資産管理):メディア資産管理ソリューションを構築するために、Content Understanding を使用して画像やビデオからスキーマで定義されたフィールドを抽出し、分析情報を抽出して、ターゲット広告の関連性を高めることができます。
- RAG (検索拡張生成) を使用したコンテンツの検索と検出: コンテンツ、メタデータ、または機能に基づいて、任意のモダリティ (テキスト、画像、オーディオ、ビデオ、混合メディアなど) のコンテンツを検索および検出する必要があるお客様は、Content Understanding からの構造化された出力を使用して、ダウンストリーム RAG シナリオを有効にすることができます。
- コンテンツまたはメディアの概要: たとえば、あるメディア企業が Content Understanding を使用して、スポーツ イベントの概要とハイライトを生成できます。
- グラフとグラフの理解: グラフやグラフを含む財務フォームや学術雑誌は、通常、テキストのみが抽出されている場合、理解するのが困難です。 Content Understanding は、特定のドキュメントまたは画像自体のコンテキストでグラフとグラフを解釈することで問題を解決します。ユーザーは、グラフやグラフの種類、概要、全体的な意味など、必要な情報を簡単に抽出できます。
その他のユース ケースを選択する際の考慮事項
ユース ケースを選択するときは、次の要因を考慮してください。
-
使用や誤用によって物理的または精神的な損害が生じる可能性があるシナリオは避けてください。 たとえば、Content Understanding を使用して患者を診断したり、薬を処方したりすると、重大な損害が発生する可能性があります。
注意
Content Understanding は、医療デバイスとして設計、意図、提供されるものではなく、専門的な医療アドバイス、診断、治療、または判断の代わりに設計または使用されるものではなく、専門的な医療アドバイス、診断、治療、または判断を置き換えたり置き換えたりするために使用しないでください。
-
生体認証の識別や検証には適していません。 たとえば、Content Understanding は、顔のジオメトリ、音声パターン、またはその他の物理的、生理的、または行動特性に基づいて個人を一意に識別または検証するために設計または意図されていません。
重要
Microsoft製品またはサービスを使用して生体認証データを処理する場合は、(i) 保持期間や破棄に関する通知をデータ主体に提供する責任があります。(ii) データ主体から同意を得る。(iii) 生体認証データの削除は、該当するデータ保護要件に従って、必要に応じてすべて削除します。 「生体認証データ」は、GDPR の第 4 条に規定されている意味を持ち、該当する場合は、他のデータ保護要件で同等の用語を持ちます。 関連情報については、「Face のデータとプライバシー」を参照してください。
- 実際のコンテキストでユーザーを追跡するために使用しないでください。 たとえば、実際のコンテキストでの個人の監視に Content Understanding を使用したり、別の場所で撮影された個人が同じ人物であることを確認したりします。 この推奨事項は、同じアクターで移動のさまざまなシーンを見つけるなど、クリエイティブな目的で Context Understanding を使用する場合には適用されません。
- システムの使用または誤用が、生命の機会や法的地位に結果的な影響を与える可能性があるシナリオは避けてください。 たとえば、Content Understanding を使用すると、個人の法的地位、法的権利、クレジット、教育、雇用、医療、住宅、保険、社会保障、サービス、機会、または提供される条件へのアクセスに影響を与える可能性があるシナリオが挙げられます。 有害な結果のリスクを軽減するために、意味のある人間のレビューと監視を組み込むことを検討してください。
- 高いステークのドメインまたは業界のユース ケースを慎重に検討してください。 例としては、医療、医療、金融、法律などがありますが、これらに限定されません。
- プライバシーを妨げる可能性のあるタスク監視システムでは使用しないでください。 Content Understanding の基になる AI モデルは、個人の性的または政治的指向などの親密な個人情報を推測するために、個々のパターンを監視するように設計されていません。
- システムの使用や誤用によって、機密性の高いトピックやユーザーに関する誤った説明が広がる可能性があるシナリオは避けてください。 たとえば、機密性の高いイベントに関する誤った情報の作成と配布、または偽の物語を反映する状況での実際のユーザーに関する情報の生成などがあります。
- サポートされているロケールと言語を慎重に検討してください。Content Understanding モデルには、サポートされているロケールと言語が異なります。 たとえば、英語自体には、米国、英国、オーストラリアなど、さまざまなロケールがあり、時刻の書式設定方法や一部の単語のスペルに違いがあります。 各モダリティについて、公式にサポートされているロケールと言語を慎重に確認してください。
- ループ内の人間またはセカンダリ検証方法を使用できない場合は使用しないでください。 フェールセーフ メカニズム (テクノロジが失敗した場合にエンド ユーザーが使用できるセカンダリ メソッドなど) は、出力エラーによる重要なサービスの拒否やその他の損害を防ぐのに役立ちます。
- 最新かつ正確な情報が重要なシナリオには適していません。人間のレビュー担当者がいるか、モデルを使用して自分のドキュメントを検索し、そのシナリオへの適合性を確認していない限り適切ではありません。 Content Understanding には、トレーニング日以降に発生するイベントに関する情報がありません。また、一部のトピックに関する知識が不足している可能性があり、必ずしも実際に正確な情報が生成されるとは限りません。
- 話者認識を使用した会話の文字起こし: Content Understanding は、話者認識でダイアライゼーションを提供するようには設計されておらず、個人を識別するために使用することはできません。 つまり、話者は、文字起こしで Guest1、Guest2、Guest3 などとして表示されます。 これらはランダムに割り当てられ、会話内の個々の話者を識別するために使用されない場合があります。 会話の文字起こしごとに、Guest1、Guest2、Guest3 などの割り当てがランダムになります。
- 法的および規制上の考慮事項。 組織は、Content Understanding を使用する際に、特定の法的義務や規制上の義務を評価する必要があります。 Content Understanding は、すべての業界またはシナリオでの使用には適していません。 コンテンツの理解は、該当するサービス利用規約および関連する行動規範 (ジェネレーティブ AI 行動規範を含む) に従って常に使用してください。
制限
技術的な制限事項、運用上の要因、範囲
すべての AI システムと同様に、お客様が認識する必要がある Content Understanding にはいくつかの制限があります。
非常に迷惑な入力ファイルが Content Understanding にアップロードされると、結果の一部として有害で不快なコンテンツが返される可能性があります。 この意図しない結果を軽減するには、システムへのアクセスを制御し、適切な使用についてそれを使用するユーザーを教育することをお勧めします。
顔のグループ化
画像またはビデオが分析のためにモデルに送信される前に顔がぼやけているため、感情などの顔の推論は画像でもビデオでも機能しません。 ビデオ モダリティのみが顔のグループ化をサポートします。これは、追加の分析なしで類似した顔のグループのみを提供します。
重要
Content Understanding の顔グループ化機能は、資格と使用条件に基づいて制限されます。 責任ある AI の原則をサポートするため。 Face サービスは、管理対象の顧客とパートナー Microsoftのみが利用できます。 顔認識の取り込みフォームを使用して、アクセスを申請します。 詳細については、「 Face の制限付きアクセス」ページを参照してください。
ドキュメント
ドキュメント抽出機能は、フィールドに名前を付ける方法とフィールドの説明に大きく依存します。 製品は、出力を入力ドキュメントのテキストにしっかりと根拠付けることを強制し、根拠付けできない場合には回答を返しません。 したがって、場合によっては、フィールドの値が欠落している可能性があります。 地表抽出の性質上、ドキュメントが正しくない場合や、コンテンツが人間の目に見えない場合でも、システムはドキュメントからコンテンツを返します。 また、レイアウト モデル が認識するにはテキストがぼやけすぎないように、ドキュメントには適切な解像度が必要です。
Video
Content Understanding は、ビデオの完全な視聴エクスペリエンスを置き換えることを意図したものではありません。特に、詳細と微妙さが重要なコンテンツの場合です。 また、コンテキストとプライバシーが最も重要な機密性の高いビデオや機密ビデオを要約するためにも設計されていません。
- ビデオ品質: 常に高品質のビデオとオーディオ コンテンツをアップロードします。 推奨される最大フレーム サイズは HD で、フレーム レートは 30 FPS です。 フレームには10人を超えてはいけません。 ビデオから AI モデルにフレームを出力する場合は、1 秒あたり約 1 フレームのみを送信します。 10 フレーム以上のフレームを処理すると、AI の結果が遅れる可能性があります。 分析を実行するには、少なくとも 1 分間の自然な会話音声が必要です。 サウンド エフェクトや歌声などの音声以外の音声信号の検出はサポートされていません。
- 高マウント、下向き、または広視野 (FOV) のカメラによって記録された顔のピクセル数が少ない場合、生成される分析情報の精度が低くなる可能性があります。
- 検出機能は、オブジェクトの正面ビューを使用してトレーニングされた場合に、オーバーヘッド ビューにあるビデオ内のオブジェクトを誤って分類する可能性があります。
- 英語以外の言語: Content Understanding は、主に英語用にテストおよび最適化されました。 英語以外の言語に適用すると、要約の精度と品質が異なる場合があります。 この制限を軽減するには、英語以外の言語の機能を使用しているユーザーは、生成された要約の精度と完全性を確認する必要があります。
- 複数の言語のビデオ: ビデオに複数の言語の音声が組み込まれている場合、テキスト ビデオの概要では、ビデオ コンテンツに含まれるすべての言語を正確に認識するのに苦労する可能性があります。 ユーザーは、多言語ビデオのテキスト ビデオ要約機能を使用する場合に、この潜在的な制限事項に注意する必要があります。
- 高度に特殊化されたビデオまたは技術的なビデオ: ビデオサマリー AI モデルは、ニュース、映画、その他の一般的なコンテンツなど、さまざまなビデオでトレーニングされます。 ビデオが高度に特殊化または技術的な場合、モデルはビデオの概要を正確に抽出できない可能性があります。
- オーディオ品質が低いビデオや (光学式文字認識) OCR: Textual Video Summary AI モデルは、オーディオやその他の分析情報に依存してビデオから概要を抽出するか、OCR を使用して画面に表示されるテキストを抽出します。 オーディオ品質が低く、識別されたテキストがない場合、モデルはビデオから要約を正確に抽出できない可能性があります。
- 低照明または高速モーションのビデオ: 低照明で撮影されたビデオや、高速なモーションを持つビデオは、モデルが分析情報を処理するのが難しく、パフォーマンスが低下する可能性があります。
- 一般的でないアクセントや方言を含むビデオ: AI モデルは、さまざまなアクセントや方言など、さまざまな音声でトレーニングされます。 ただし、トレーニング データであまり表現されていないアクセントまたは方言を含む音声がビデオに含まれている場合、モデルはビデオからトランスクリプトを正確に抽出するのに苦労する可能性があります。
オーディオ
オーディオ ファイルの場合は、各オーディオ入力のロケールを指定する必要があります。 ロケールは、入力音声で読み上げられた実際の言語と一致する必要があります。 Content Understanding では、一部のユース ケースでも自動言語検出がサポートされています。 詳細については、 サポートされているロケールの一覧を参照してください。
- 音響品質: 音声からテキストへの変換が可能なアプリケーションやデバイスでは、さまざまなマイクの種類と仕様が使用される場合があります。 統合音声モデルは、電話、携帯電話、スピーカー デバイスなど、さまざまな音声オーディオ デバイス シナリオでトレーニングされています。 高品質のマイクを使用している場合でも、ユーザーがマイクに話し込む方法によって音声品質が低下する可能性があります。 たとえば、スピーカーがマイクから離れた場所にある場合、入力品質が低すぎる可能性があります。 マイクに近すぎるスピーカーは、オーディオ品質の低下を引き起こす可能性もあります。 このような場合や、オーディオ ファイルの品質が低下する場合は、音声テキスト変換の精度に悪影響を及ぼす可能性があります。
- 非音声ノイズ: 入力オーディオに特定のレベルのノイズが含まれている場合、精度が影響を受けます。 録音に使用されるオーディオ デバイスまたはオーディオ入力自体から発生するノイズには、背景や環境ノイズなどのノイズが含まれている可能性があります。
- 音声の重複: 1 つのオーディオ入力デバイスの範囲内に複数のスピーカーが存在し、同時に話すことがあります。 メイン スピーカーの録音中に他のスピーカーの音声がバックグラウンドで録音されているオーディオ ファイルでも、音声ファイルが重複します。 また、会話内の話者数に制限はありませんが、話者数が30人以下の場合にシステムのパフォーマンスが向上します。
- ボキャブラリ: モデルに存在しない単語がオーディオに表示される場合、結果は文字起こしのエラーになります。
- Accents: 英語 - 米国 (en-US) など、1 つのロケール内でも、多くのユーザーがアクセントが異なります。 非常に具体的なアクセントも文字起こしのエラーにつながる可能性があります。
- 不一致した言語またはロケール: 音声入力に英語 - 米国 (en-US) を指定したが、スウェーデン語で話した場合、精度が低下します。
- 挿入エラー: モデルでは、ノイズやソフトバックグラウンド音声が存在する場合に挿入エラーが発生することがあります。
Image
- オブジェクト認識: モデルで認識できない場合、特定のあいまいな製品の認識が正確でない可能性があります。 画像に対応しない抽象的な概念 (性別や感情など) も認識されない場合があります。
システム パフォーマンス
パフォーマンス メトリックは、Content Understanding 内のモダリティごとに異なります。 各モダリティには、AI のパフォーマンスを測定するための業界標準が異なります。
すべてのモダリティ全体で Content Understanding で提供される一般的なメトリックの 1 つは、フィールドの信頼度スコアです。 現時点では、"extract" と "generate" の種類のフィールドのみが信頼度スコアを持つことになります。
Content Understanding の特徴は、基礎スコアと信頼度スコアのサポートです。現在はドキュメント モダリティでのみ使用できますが、今後の拡張が計画されています。 ドキュメント内の「情報の補足」には、抽出された値のページ番号と境界ボックスが含まれており、ユーザーがレビューや修正を行う際に、その位置を強調表示することで体験を向上させます。 信頼度スコアは、0 から 1 までの範囲で、分析またはトレーニングドキュメントに基づいて抽出された値の精度を推定し、より高いスコアは信頼度が高いことを示します。 信頼度スコアの使用に関するガイドラインについては、「Content Understanding」の「評価」セクションを参照してください。
各モダリティに使用できる一般的なパフォーマンス メトリックを次に示します。
ドキュメント
精度
テキストは、基本レベルの行と単語、およびドキュメント理解レベルの名前、価格、金額、会社名、製品などのエンティティで構成されます。
単語レベルの精度
OCR の精度の尺度は、単語エラー率 (WER) または抽出された結果で誤って出力された単語の数です。 WER が低いほど、精度が高くなります。
WER は次のように定義されます。
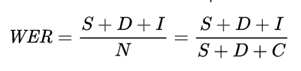
どこ:
| 用語 | 定義 | 例 |
|---|---|---|
| S | 出力内の不適切な単語 ("置換") の数。 | "l" が "i" として検出されるため、"Velvet" は "Veivet" として抽出されます。 |
| D | 出力に含まれていない ("削除された") 単語の数。 | "会社名: Microsoft" というテキストの場合、Microsoftは手書きまたは読みにくいため抽出されません。 |
| I | 出力に存在しない ("inserted") 単語の数。 | "Department" は、"Dep artm ent" という 3 つの単語に誤って分割されます。この場合、結果は 1 つの削除された単語と 3 つの挿入された単語になります。 |
| C | 出力で正しく抽出された単語の数。 | 正しく抽出されたすべての単語。 |
| N | 元の参照に含まれていない単語が存在すると誤って予測されたため、参照 (N=S+D+C) 内の単語の合計数 (N=S+D+C) (I を除く)。 | 「Microsoft、ワシントン州レドモンドに本社を置く、金融部門向けベルベットという新製品を発表しました」という文の画像を考えてみましょう。OCR の出力が "、Redmond, WA に本社を置くは Veivet for finance dep artm ents と呼ばれる新製品を発表しました。この場合、S (ベルベット) = 1, D (Microsoft) = 1, I (dep artm ents) = 3, C (11)、N = S + D + C = 13。 したがって、WER = (S + D + I) / N = 5 / 13 = 0.38 または 38% (100 個中)。 |
ドキュメントとエンティティ レベルの精度 たとえば、請求書や領収書の場合、ドキュメント全体に 1 文字のみのエラーが発生した場合、ドキュメント レベルでは重要でないと評価される場合があります。 そのエラーが支払額を表すテキスト内にある場合は、請求書または領収書全体に誤ったフラグが設定される可能性があります。
もう 1 つのメトリックは、エンティティ エラー率 (EER) です。 これは、1 つ以上のドキュメント内の対応するエンティティの合計数のうち、名前、価格、金額、電話番号など、誤って抽出されたエンティティの割合です。 たとえば、10 個の名前を表す合計 30 個の単語の場合、30 個のうち 2 つの不適切な単語は 0.06 (6%) WER になります。 ただし、10 個のうち 2 つの名前が正しくない場合、名前 EER は 0.20 (20%) であり、WER よりもはるかに大きくなります。
WER と EER の両方を測定することは、ドキュメントの理解精度に関する完全な視点を得るための便利な演習です。
Video
ビデオ解析の精度は、カメラの配置やシステムの出力の解釈など、いくつかの要因によって異なります。 精度は、モードのフィールド値の結果がビデオの実際のコンテンツとどれだけ近い位置にあるかによって評価する必要があります。 たとえば、ユーザーがビデオ内のエンティティを検索すると、ビデオで見つかったエンティティの完全な一覧が返されることが予想されます。 精度を評価するために、さまざまな実際のシナリオと条件を代表する特定のテスト データセットが使用されます。 これらのデータセットには、さまざまなビデオ コンテンツ タイプとユーザー操作シナリオが含まれます。
| 用語 | 定義 |
|---|---|
| 真陽性 | システム生成の出力は、実際のイベントに正しく対応します。 |
| 真陰性 | 実際のイベントが発生していない場合、システムはイベントを正しく生成しません。 |
| 偽陽性 | 実際のイベントが発生しなかった場合、システムによって出力が誤って生成/抽出/分類されます。 |
| 偽陰性 | 実際のイベントが発生したときに、システムが誤って出力を生成できません。 |
オーディオ
システムのパフォーマンスは、次の重要な要因によって測定されます。
- Word エラー率 (WER)
- トークン エラー率 (TER)
- ランタイム待機時間
モデルは、リソース使用量と応答待機時間の目標に沿いながら、すべてのシナリオ (会話音声の文字起こし、コール センターの文字起こし、ディクテーション、音声アシスタントなど) で大幅な改善 (5% 相対的な WER 改善など) を示す場合にのみ、より優れていると見なされます。
分音化の場合は、単語の分数化誤差率 (WDER) を使用して品質を測定します。 WDER が低いほど、ダイアライゼーションの品質が向上します。
Image
画像分析の精度は、出力が画像に存在する実際のビジュアル コンテンツにどの程度対応しているかを示す尺度です。 画像分析の精度を測定するために、実際の地上データで画像を評価し、AI モデルの出力を比較することができます。 地上の真実と AI で生成された結果を比較することで、イベントを 2 種類の正しい ("true") 結果と 2 種類の正しくない ("false") 結果に分類できます。
| 用語 | 定義 |
|---|---|
| 真陽性 | このシステム生成の出力は、実際データに正しく対応しています。 たとえば、犬の画像を犬として正しくタグ付けします。 |
| 真陰性 | システムは、グラウンド・トゥルース・データに存在しない結果を正しく生成しません。 たとえば、画像に犬が存在しない場合、システムは画像に犬として正しくタグ付けしません。 |
| 偽陽性 | システムは、グラウンド・トゥルース・データに存在しない出力を誤って生成します。 たとえば、システムは猫の画像に犬としてタグ付けします。 |
| 偽陰性 | システムは、グラウンド・トゥルース・データに存在する結果を生成できません。 たとえば、システムは、画像に存在していた犬の画像にタグ付けに失敗します。 |
これらのイベント カテゴリは、精度と再現率を計算するために使用されます。
| 用語 | 定義 |
|---|---|
| 精度 | 抽出されたコンテンツの正確性の尺度。 複数のオブジェクトを含むイメージから、正しく抽出されたオブジェクトの数を確認します。 |
| リコール | 抽出された総合的な内容の尺度。 複数のオブジェクトを含む画像から、その正確性に関係なく、全体的に検出されたオブジェクトの数を確認できます。 |
精度と再現率の定義は、場合によっては、精度と再現率の両方を同時に最適化することが難しい可能性があることを意味します。 シナリオによっては、一方に優先順位を付ける必要がある場合があります。 たとえば、画像の検索結果を表示するなど、コンテンツ内の最も正確なタグまたはラベルのみを検出するソリューションを開発する場合は、より高い精度を得るために最適化します。 ただし、インデックス作成または内部カタログ化のために画像内のすべての可能なビジュアル コンテンツにタグを付けようとしている場合は、より高い再現率を得るために最適化します。
システム パフォーマンスを向上するためのベスト プラクティス
ほとんどの場合、システムパフォーマンスの向上は、Content Understanding が値を抽出する際に合理的に理解できるデータを提供するユーザーに大きく依存します。
コンテンツから生成されたフィールドが、ダウンストリームの用途に関連していることを確認します。 たとえば、"裏庭で遊んでいる犬" を検索する場合は、フィールド出力にこれらの概念が含まれていることを確認し、フィールド名やフィールドの説明などのスキーマ定義を更新して、修正しない場合は修正してください。
画像については、特定の入力要件に関する次の ドキュメント を参照してください。 画像には、妥当な品質、明るい露出、コントラストが必要です。
オーディオの場合、ロケールの不一致によって精度が低下するため、入力ロケールをファイル内のスピーカーと一致させることが重要です。 適切な音響条件でオーディオ ファイルを使用し、バックグラウンド ノイズ、サイドスピーチ、マイクとの距離、および精度に悪影響を与える可能性のある読み上げスタイルを含むファイルを避けます。
現在サポートされている入力、言語、ロケール、シナリオに関する各モダリティの制限を考慮すると、システムパフォーマンスの向上にも役立ちます。
ただし、ドキュメントの抽出では、アナライザーの品質を向上させる方法があります。これは、データセットに追加する各ドキュメントで必要に応じてフィールド ラベルの結果を更新または修正することです。 ドキュメント抽出機能はコンテキスト内学習をサポートしているため、データセットと正確なフィールド ラベルが多いほど、一般的にシステムのパフォーマンスが向上します。 入力フォームの場合は、すべてのフィールドが入力されている例を使用し、各フィールドに表示される実際の値を使用することもお勧めします。
コンテンツ理解の評価
評価方法
Content Understanding を作成するために、一般的な顧客のユース ケースを対象とするデータセットを準備しました。 これらはMicrosoftによって個別に準備されており、トレーニングや評価の目的でサービスに送信された顧客データは使用しません。
Content Understanding の有効性は、使用されている特定のアプリケーションによって異なります。 お客様は、最適な結果を保証するために独自のテストを実行する必要があります。
たとえば、ドキュメント抽出では、サービスは単語とフィールドごとに信頼度の値を 0 から 1 に割り当てます。 パイロットを実行すると、お客様が信頼性の範囲とデータ抽出の品質を判断するのに役立てることができます。 その後、しきい値を設定できます。たとえば、ストレートスルー処理では信頼度値が 0.80 以上の結果を送信し、人間のレビューでは以下の値を送信できます。
評価結果
サービスのパフォーマンスを確保するために、定期的に評価とエラー分析を実施し、その結果を使用してオファリングを強化します。 これらの評価の多くは、顧客のシナリオに合わせて調整され、フィールド番号やトレーニング データ サイズなどの制約を決定するのに役立ちます。 これらの制約は、顧客参照のために文書化されています。 さまざまなシナリオが考えられるため、すべてをテストすることはできません。 たとえば、金融分野を頻繁にテストしていますが、医療分野でのカバー範囲は少なくなります。
公平性に関する考慮事項
AI システムを使用する際に考慮すべき重要なディメンションの 1 つは、システムがさまざまなグループのユーザーに対してどの程度適切に実行されるかです。 調査によると、すべてのグループのパフォーマンスの向上に重点を置いた意識的な取り組みがなければ、AI システムは、人種、民族性、性別、年齢など、さまざまな人口統計要因にわたってさまざまなレベルのパフォーマンスを示すことができます。
コンテンツ理解の評価の一環として、潜在的な公平性の害を評価するための分析を行いました。 私たちは、存在する可能性があり、公平性に影響を与える可能性のある差異や相違を特定することを目的として、さまざまな人口統計グループ間のシステムのパフォーマンスを調べました。
場合によっては、パフォーマンスの差異が残っている可能性があります。 これらの差異が目標を超える可能性があることに注意することが重要であり、潜在的なバイアスやパフォーマンスのギャップに対処し、最小限に抑え、さまざまな背景から多様な視点を求めることに積極的に取り組んでいます。
ステレオタイピング、軽蔑、消去などの表現上の損害については、これらの問題に関連するリスクを認識します。 評価プロセスではこのようなリスクを軽減することを目的としていますが、ユーザーは特定のユース ケースを慎重に検討し、必要に応じて追加の軽減策を実装することをお勧めします。 人間をループ内に入れると、潜在的なバイアスや意図しない結果に対処するための監視の追加レイヤーが提供される可能性があります。
私たちは、さまざまな人口統計グループ全体のシステムのパフォーマンスと潜在的な公平性の懸念をより深く理解するために、公平性評価を継続的に改善することに取り組んでいます。 評価プロセスは進行中であり、公平性と包摂性を強化し、特定された差異を軽減するために積極的に取り組んでいます。 音声に関連するより公平性のテストについては、この ドキュメントを参照してください。
使用する画像分析の評価と統合
ユース ケースに対して Content Understanding を統合する際に、Content Understanding が Microsoft Generative AI Services Code of Conduct の対象であることを知ることで、統合を成功に導きます。
Content Understanding を製品または機能に統合する準備ができたら、次のアクティビティを使用して成功を収めるのに役立ちます。
- 何ができるかを理解する: Content Understanding の可能性を十分に評価して、その機能と制限事項を理解します。 シナリオとコンテキストでそれがどのように実行されるかを理解します。 たとえば、オーディオ コンテンツ抽出を使用している場合は、ビジネス プロセスからの実際の記録でテストし、既存のプロセス メトリックに対して結果を分析してベンチマークします。
- プライバシーに対する個人の権利を尊重する:同意を得た個人からのデータと情報のみを収集し、合法的かつ正当な目的のために収集します。
- 法的および規制上の考慮事項。 組織は、Content Understanding を使用する際に、特定の法的義務や規制上の義務を評価する必要があります。 Content Understanding は、すべての業界またはシナリオでの使用には適していません。 コンテンツの理解は、該当するサービス利用規約と Microsoft Generative AI Services の行動規範に従って常に使用してください。
- Human-in-the-loop: 人間をループ内に留め、検討する一貫したパターン領域として人間による監視を組み込みます。 つまり、AI を利用した製品または機能を継続的に人間が監視し、意思決定における人間の役割を維持することを意味します。 損害を防ぐために、ソリューションに人間がリアルタイムで介入できることを確認します。 ループ内の人間は、Content Understanding が必要に応じて実行されない状況を管理できます。
- セキュリティ: ソリューションが安全であり、コンテンツの整合性を維持し、不正アクセスを防ぐための適切な制御があることを確認します。
責任ある AI の詳細
Content Understanding の詳細
- Azure OpenAI の概要
- ドキュメント インテリジェンスの概要
- Azure Speech の概要
- ビジョンの概要
- Azure AI Face サービスの概要
- Azure AI Video Indexerの概要