通常、受信データは、クリーニングし変換してから、分析を行うのに適した宛先に読み込む必要があります。 抽出、変換、および読み込み (ETL) の操作は、データを準備し、そのデータをデータの宛先に読み込むために実行されます。 HDInsight 上の Apache Hive では、非構造化データを読み取り、必要に応じてそのデータを処理し、意思決定支援システム用のリレーショナル データ ウェアハウスにデータを読み込むことができます。 この方法では、データはソースから抽出されます。 その後、Azure Storage BLOB や Azure Data Lake Storage などの適応するストレージに格納されます。 その後、データは一連の Hive クエリを使用して変換されます。 次に、変換先のデータ ストアへの一括読み込みの準備として、Hive 内でステージングされます。
ユース ケースとモデルの概要
次の図に、ETL オートメーションのユース ケースとモデルの概要を示します。 入力データは、適切な出力を生成するために変換されます。 変換中には、データのシェイプおよびデータ型に加えて、データの言語も変更されます。 ETL プロセスでは、宛先の既存のデータに厳密に合うように、インペリアル法からメートル法への変換、タイム ゾーンの変更、精度の改善を行うことができます。 ETL プロセスでは、常に最新の状態がレポートされるように、または既存のデータに対するさらなる分析情報が提供されるように、新しいデータを既存のデータに結合することもできます。 レポート ツールやサービスなどのアプリケーションでは、このデータを目的の形式で利用できます。
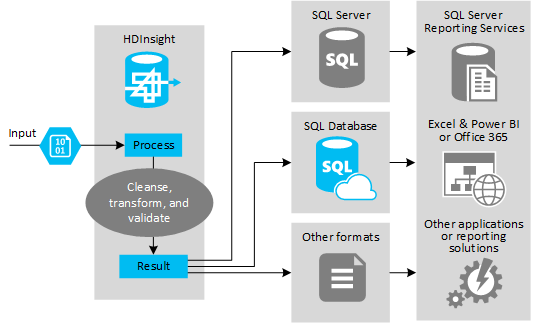
Hadoop は、通常、膨大な数のテキスト ファイル (CSV など) をインポートする ETL プロセスで使用されます。 または、数は少ないが頻繁に変更が発生するテキスト ファイル、あるいはその両方も含まれます。 Hive は、データを宛先に読み込む前に、データの準備を行うのに優れたツールです。 Hive では、CSV に対するスキーマを作成し SQL に似た言語を使用することで、データを操作する MapReduce プログラムを生成することができます。
Hive を使用して ETL を実行する一般的な手順は次のとおりです。
データを Azure Data Lake Storage または Azure Blob Storage に読み込みます。
スキーマの格納時に Hive で使用するメタデータ ストア データベース (Azure SQL Database を使用) を作成します。
HDInsight クラスターを作成し、データ ストアを接続します。
読み取り時にデータ ストア内のデータに適用するスキーマを定義します。
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';データを変換し、それを宛先に読み込みます。 変換および読み込み時の Hive の使い方は複数あります。
- Hive を使用してデータをクエリおよび準備し、そのデータを CSV として Azure Data Lake Storage または Azure Blob Storage に保存します。 SQL Server Integration Services (SSIS) のようなツールを使用して、それらの CSV を取得し、データを SQL Server などの宛先リレーショナル データベースに読み込みます。
- Hive ODBC ドライバーを使用して、Excel または C# からデータを直接クエリします。
- Apache Sqoop を使用して準備済みのフラットな CSV ファイルを読み取り、宛先リレーショナル データベースに読み込みます。
データ ソース
データ ソースは、通常、ご利用のデータ ストア内の既存のデータと一致させることができる外部データとなります。次に例を示します。
- ソーシャル メディア データ、ログ ファイル、センサー、データ ファイルを生成するアプリケーション。
- 気象統計またはベンダーの売上数など、データ プロバイダーから取得したデータセット。
- 適切なツールまたはフレームワークを通してキャプチャ、フィルター処理、および処理されたストリーミング データ。
出力ターゲット
Hive を使用して、次に示すようなあらゆる種類のターゲットにデータを出力することができます。
- SQL Server または Azure SQL Database などのリレーショナル データベース。
- Azure Synapse Analytics などのデータ ウェアハウス。
- Excel。
- Azure テーブルと BLOB ストレージ。
- データが特定の形式に処理される、または特定の種類の情報構造体を含むファイルとしてデータが処理される必要があるアプリケーションまたはサービス。
- Azure Cosmos DB などの JSON ドキュメント ストア。
考慮事項
ETL モデルは、通常、次の場合に使用されます。
*外部ソースから既存のデータベースまたは情報システムに、ストリーム データまたは大量の半構造化データもしくは非構造化データを読み込む。
*多くの場合、クラスターの中で複数の変換パスを使用して、読み込む前にデータのクリーニング、変換、検証を行う。
*定期的に更新されるレポートと視覚化を生成する。 たとえば、日中に生成するには時間がかかりすぎるレポートであれば、夜間に実行するようにレポートをスケジュールできます。 Hive クエリを自動的に実行するために、Azure Logic Apps と PowerShell を使用できます。
データのターゲットがデータベースでない場合、クエリ内で適切な形式 (CSV など) でファイルを生成することができます。 このファイルは、Excel または Power BI にインポートすることができます。
ETL プロセスの一環として、データに対して複数の操作を実行する必要がある場合は、該当する操作の管理方法を検討してください。 操作をソリューション内でワークフローとして制御するのでなく、外部プログラムによって制御する場合は、いくつかの操作を並列に実行できるかどうかを判断する必要があります。 また、各ジョブの完了のタイミングを検出する必要があります。 Hadoop 内で Oozie などのワークフロー メカニズムを使用する方法は、外部スクリプトまたはカスタム プログラムを使用して一連の操作の調整を試みるよりも簡単である可能性があります。