"データ パイプライン" は、多くのデータ分析ソリューションの基礎になります。 名前が示すように、データ パイプラインは、生データを受け取り、必要に応じてクリーンアップと整形を行い、通常は計算や集計を実行してから、処理済みのデータを格納します。 処理されたデータは、クライアント、レポート、または API によって利用されます。 データ パイプラインは、スケジュールまたは新しいデータのどちらでトリガーされても、反復可能な結果を提供する必要があります。
この記事では、HDInsight Hadoop クラスターで実行されている Oozie を使って、再現性のためにデータ パイプラインを運用化する方法について説明します。 この例のシナリオでは、航空会社のフライトの時系列データを準備して処理するデータ パイプラインについて説明します。
次のシナリオの入力データは、1 か月のフライト データのバッチを含むフラット ファイルです。 このフライト データには、出発空港と到着空港、飛行マイル数、出発時刻と到着時刻などの情報が含まれます。 このパイプラインの目標は、航空会社の毎日の運航実績をまとめることであり、航空会社ごとに毎日 1 行を使って、出発と到着の平均遅延時間 (分単位) と、その日の総飛行マイル数を示します。
| YEAR | MONTH | DAY_OF_MONTH | CARRIER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
この例のパイプラインでは、新しい期間のフライト データが到着するまで待ってから、その詳細なフライト情報を長期的な分析のために Apache Hive データ ウェアハウスに格納します。 また、パイプラインは、毎日のフライト データだけを集計するはるかに小さいデータセットも作成します。 この毎日のフライト集計データは、Web サイトなどでレポートを提供するために SQL Database に送られます。
次の図はこの例のパイプラインを示したものです。
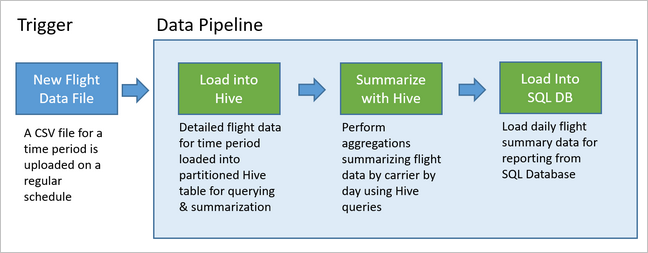
Apache Oozie ソリューションの概要
このパイプラインでは、HDInsight Hadoop クラスターで実行されている Apache Oozie を使います。
Oozie では、パイプラインは "アクション"、"ワークフロー"、"コーディネーター" によって記述されます。 アクションは、Hive クエリの実行など、実際に実行する作業を決定します。 ワークフローは、アクションのシーケンスを定義します。 コーディネーターは、ワークフローを実行するスケジュールを定義します。 コーディネーターは、ワークフローのインスタンスを開始する前に、新しいデータが使用可能になるのを待つこともできます。
次の図では、この例の Oozie パイプラインの概要設計を示します。
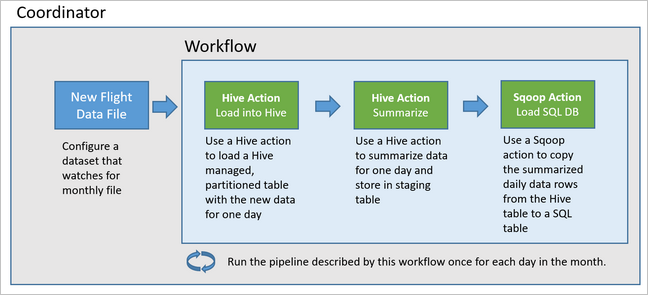
Azure リソースをプロビジョニングする
このパイプラインには、同じ場所に存在する Azure SQL Database と HDInsight Hadoop クラスターが必要です。 Azure SQL Database は、パイプラインによって生成された概要データと Oozie メタデータ ストアの両方を格納します。
Azure SQL Database をプロビジョニングする
Azure SQL Database を作成します。 Azure portal での Azure SQL Database の作成に関するページを参照してください。
HDInsight クラスターが接続された Azure SQL Database にアクセスできるようにするには、Azure のサービスとリソースがサーバーにアクセスできるように Azure SQL Database ファイアウォール規則を構成します。 このオプションを Azure portal で有効にするには、サーバー ファイアウォールの設定] [ を選択し、Azure SQL Database についての ] [Azure サービスおよびリソースにこのサーバーへのアクセスを許可する の下にある [ON] を選択します。 詳細については、「IP ファイアウォール規則の作成および管理」を参照してください。
クエリ エディターを使用して次の SQL ステートメントを実行し、パイプラインの各実行から集計されたデータを格納する
dailyflightsテーブルを作成します。CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Azure SQL Database の準備ができました。
Apache Hadoop クラスターをプロビジョニングする
カスタム metastore を使用して Apache Hadoop クラスターを作成します。 ポータルからクラスターを作成するときに、 [ストレージ] タブの [metastore の設定] の下で、必ず SQL Database を選択してください。 metastore の選択の詳細については、「クラスターの作成時にカスタム metastore を選択する」を参照してください。 クラスターの作成の詳細については、Linux での HDInsight の使用に関するページをご覧ください。
SSH トンネリングの設定を確認する
Oozie Web コンソールを使ってコーディネーター インスタンスとワークフロー インスタンスの状態を表示するには、HDInsight クラスターへの SSH トンネルを設定します。 詳しくは、「SSH トンネル」をご覧ください。
Note
Chrome と Foxy Proxy 拡張機能を使って、SSH トンネル経由でクラスターの Web リソースを参照することもできます。 トンネルのポート 9876 でホスト localhost を経由してすべての要求をプロキシするように構成します。 この方法は、Windows Subsystem for Linux (Bash on Windows 10 とも呼ばれます) と互換性があります。
次のコマンドを実行して、クラスターへの SSH トンネルを開きます。
CLUSTERNAMEはクラスターの名前です。ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netヘッド ノードで Ambari に移動し、次のアドレスを参照して、トンネルが動作可能であることを確認します。
http://headnodehost:8080Ambari 内から Oozie Web コンソールにアクセスするには [Oozie]>[Quick Links](クイックリンク)> [Active server](アクティブ サーバー) > >[Oozie Web UI] に移動します。
Hive を構成する
データのアップロード
1 か月のフライト データを含むサンプル CSV ファイルをダウンロードします。 ZIP ファイル
2017-01-FlightData.zipを HDInsight GitHub リポジトリからダウンロードし、CSV ファイル2017-01-FlightData.csvに解凍します。この CSV ファイルを、HDInsight クラスターに接続されている Azure Storage アカウントにコピーして、
/example/data/flightsフォルダーに配置します。SCP を使って、ローカル コンピューターから HDInsight クラスターのヘッド ノードのローカル ストレージにファイルをコピーします。
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvssh コマンドを使用してクラスターに接続します。 次のコマンドを編集して
CLUSTERNAMEをクラスターの名前に置き換えてから、そのコマンドを入力します。ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netssh セッションから、HDFS コマンドを使用して、ヘッド ノードのローカル ストレージから Azure Storage にファイルをコピーします。
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
テーブルの作成
これで、サンプル データを利用できるようになりました。 ただし、パイプラインには処理用に 2 つの Hive テーブルが必要です。1 つは受信データ用 (rawFlights) で、もう 1 つは集約済みデータ用 (flights) です。 次のようにして、Ambari でこれらのテーブルを作成します。
http://headnodehost:8080に移動して Ambari にログインします。サービスの一覧から、 [Hive] を選びます。
Hive ビュー 2.0 のラベルの横にある [ビューに移動] を選びます。
rawFlightsテーブルを作成する次のステートメントを、クエリのテキスト領域に貼り付けます。rawFlightsテーブルでは、Azure Storage の/example/data/flightsフォルダー内の CSV ファイルに対する読み取り時スキーマが提供されています。CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'[実行] を選んでテーブルを作成します。
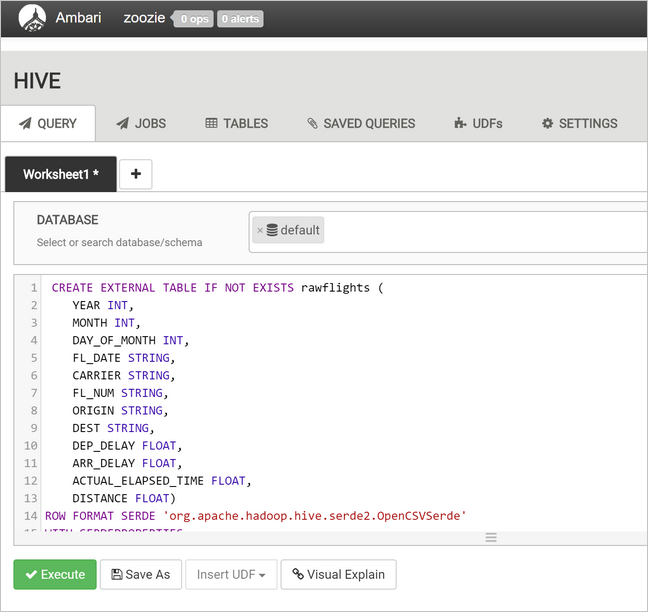
flightsテーブルを作成するには、クエリのテキスト領域内のテキストを次のステートメントに置き換えます。flightsテーブルは Hive のマネージド テーブルであり、読み込まれたデータを年、月、日で分割します。 このテーブルには、フライトごとに 1 行というソース データの最小の細分性で、すべてのフライト履歴データが格納されます。SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );[実行] を選んでテーブルを作成します。
Oozie ワークフローを作成する
パイプラインは通常、指定された時間間隔でデータをバッチ処理します。 この例のパイプラインは、フライト データを毎日処理します。 この方法では、入力 CSV ファイルは毎日、毎週、毎月、または毎年到着できます。
サンプル ワークフローは、次の 3 つの主要ステップでフライト データを毎日処理します。
- Hive クエリを実行して、
rawFlightsテーブルによって表されるソース CSV ファイルからその日の日付範囲のデータを抽出し、flightsテーブルにデータを挿入します。 - Hive クエリを実行して、その日のステージング テーブルを Hive に動的に作成します。このテーブルには、日および航空会社の単位で集計されたフライト データのコピーが格納されます。
- Apache Sqoop を使って、Hive の毎日のステージング テーブルから Azure SQL Database のコピー先
dailyflightsテーブルに、すべてのデータをコピーします。 Sqoop は、Azure Storage に存在する Hive テーブルの背後にあるデータからソース行を読み取り、JDBC 接続を使って SQL Database にそれらを読み込みます。
これら 3 つのステップは、Oozie ワークフローによって調整されます。
ローカル ワークステーションから、
job.propertiesというファイルを作成します。 ファイルの開始コンテンツとして、次のテキストを使用します。 使用している特定の環境に合わせて値を更新します。 テキストの下の表では、各プロパティと、独自環境でその値が見つかる場所をまとめて示します。nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03プロパティ 値のソース nameNode HDInsight クラスターに接続されている Azure ストレージ コンテナーへの完全なパスです。 jobTracker アクティブなクラスターの YARN ヘッド ノードに対する内部ホスト名です。 Ambari のホーム ページで、サービスの一覧から YARN を選び、アクティブな Resource Manager を選びます。 ページの上部に、ホスト名の URI が表示されます。 ポート 8050 を追加します。 queueName Hive アクションをスケジュールするときに使う YARN キューの名前です。 既定値のままにします。 oozie.use.system.libpath true のままにします。 appBase Oozie ワークフローとサポート ファイルを展開する、Azure Storage 内のサブフォルダーへのパスです。 oozie.wf.application.path 実行する Oozie ワークフロー workflow.xmlの場所です。hiveScriptLoadPartition Hive クエリ ファイル hive-load-flights-partition.hqlへの Azure Storage 内のパスです。hiveScriptCreateDailyTable Hive クエリ ファイル hive-create-daily-summary-table.hqlへの Azure Storage 内のパスです。hiveDailyTableName ステージング テーブルに使われる、動的に生成された名前です。 hiveDataFolder ステージング テーブルに含まれるデータへの Azure Storage 内のパスです。 sqlDatabaseConnectionString Azure SQL Database への JDBC 構文の接続文字列です。 sqlDatabaseTableName 集計行が挿入される Azure SQL Database のテーブルの名前です。 dailyflightsのままにします。year フライトの集計を計算する日付の年の部分です。 現状のままにします。 month フライトの集計を計算する日付の月の部分です。 現状のままにします。 day フライトの集計を計算する日付の日の部分です。 現状のままにします。 ローカル ワークステーションから、
hive-load-flights-partition.hqlというファイルを作成します。 ファイルの内容として、次のコードを使用します。SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Oozie 変数は
${variableName}という構文を使います。job.propertiesファイルでは、次の変数が設定されます。 Oozie は、実行時に実際の値に置き換えます。ローカル ワークステーションから、
hive-create-daily-summary-table.hqlというファイルを作成します。 ファイルの内容として、次のコードを使用します。DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};このクエリは、1 日分の集計されたデータのみを格納するステージング テーブルを作成します。航空会社と日付別に平均遅延と総飛行距離を計算する SELECT ステートメントに注目してください。 このテーブルに挿入されたデータは、次のステップで Sqoop に対するソースとして使えるように、既知の場所 (hiveDataFolder 変数によって示されるパス) に格納されます。
ローカル ワークステーションから、
workflow.xmlというファイルを作成します。 ファイルの内容として、次のコードを使用します。 上記の手順は、Oozie ワークフロー ファイル内で個別のアクションとして表現されています。<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
2 つの Hive クエリは Azure Storage 内のパスによってアクセスされ、残りの変数値は job.properties ファイルで提供されます。 このファイルでは、2017 年 1 月 3 日に実行するワークフローが構成されます。
Oozie ワークフローを展開して実行する
bash セッションから SCP を使って、Oozie ワークフロー (workflow.xml)、Hive クエリ (hive-load-flights-partition.hql と hive-create-daily-summary-table.hql)、およびジョブ構成 (job.properties) を展開します。 Oozie では、ヘッド ノードのローカル ストレージに存在できるのは job.properties ファイルだけです。 その他のファイルはすべて、HDFS (この場合は Azure Storage) に格納する必要があります。 ワークフローによって使われる Sqoop アクションは、SQL Database と通信するための JDBC ドライバーによって異なります。データベースをヘッド ノードから HDFS にコピーする必要があります。
ヘッド ノードのローカル ストレージ内のユーザーのパスの下に、
load_flights_by_dayサブフォルダーを作成します。 開いている SSH セッションから次のコマンドを実行します。mkdir load_flights_by_day現在のディレクトリ (
workflow.xmlファイルとjob.propertiesファイル) からload_flights_by_dayサブフォルダーまでのすべてのファイルをコピーします。 ローカル ワークステーションから次のコマンドを実行します。scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayワークフロー ファイルを HDFS にコピーします。 開いている SSH セッションから以下のコマンドを実行します。
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayローカル ヘッド ノードから HDFS のワークフロー フォルダーに
mssql-jdbc-7.0.0.jre8.jarをコピーします。 クラスターに別の jar ファイルが含まれている場合は、必要に応じてコマンドを変更します。 別の jar ファイルを反映するように、必要に応じてworkflow.xmlを変更します。 開いている SSH セッションから次のコマンドを実行します。hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayワークフローを実行します。 開いている SSH セッションから次のコマンドを実行します。
oozie job -config job.properties -runOozie Web コンソールを使って状態を確認します。 Ambari 内から、 [Oozie] 、 [クイック リンク] 、 [Oozie Web Console](Oozie Web コンソール) の順に選びます。 [Workflow Jobs](ワークフロー ジョブ) タブで、 [All Jobs](すべてのジョブ) を選びます。
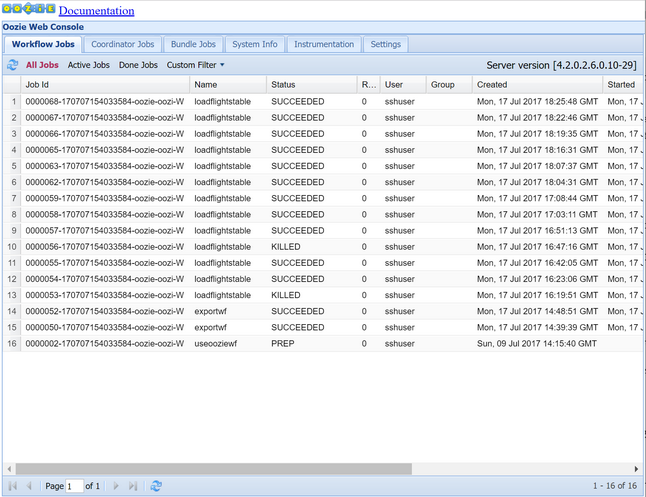
状態が [SUCCEEDED](成功) の場合、SQL Database テーブルにクエリを実行して、挿入された行を表示します。 Azure Portal で SQL Database のウィンドウに移動し、 [ツール] を選んで、 [クエリ エディター] を開きます。
SELECT * FROM dailyflights
特定のテスト日に対してワークフローを実行できるようになったので、毎日実行するようにワークフローをスケジュールするコーディネーターでこのワークフローをラップできます。
コーディネーターでワークフローを実行する
毎日 (または日付範囲のすべての日に) 実行されるようにこのワークフローをスケジュールするには、コーディネーターを使うことができます。 コーディネーターは XML ファイルによって定義されています (例: coordinator.xml)。
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
見るとわかるように、コーディネーターの処理の大部分は、ワークフロー インスタンスに構成情報を渡すだけです。 ただし、注意する必要のある重要な項目がいくつかあります。
ポイント 1:
coordinator-app要素自体のstart属性とend属性は、コーディネーターを実行する期間を制御します。<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>コーディネーターは、
frequency属性で指定された間隔に従って、startとendの日付範囲内でアクションをスケジュールします。 スケジュールされた各アクションは、構成に従ってワークフローを実行します。 上記のように定義されたコーディネーターは、2017 年 1 月 1 日から 2017 年 1 月 5 日までアクションを実行するように構成されます。 頻度は、Oozie 式言語の頻度式${coord:days(1)}によって 1 日に設定されています。 これにより、コーディネーターはアクション (したがってワークフロー) を 1 日に 1 回実行するようにスケジュールします。 この例のように、過去の日付範囲の場合は、アクションは遅延なしで実行するようにスケジュールされます。 アクションの実行がスケジュールされる日付の開始時刻は、"標準時刻" と呼ばれます。 たとえば、2017 年 1 月 1 日のデータを処理する場合、コーディネーターは標準時刻 2017-01-01T00:00:00 GMT でアクションをスケジュールします。ポイント 2: ワークフローの日付範囲内で、
dataset要素は特定の日付範囲のデータを HDFS で検索する場所を指定し、データを処理にまだ使用できるかどうかを Oozie が判断する方法を構成します。<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>HDFS 内のデータへのパスは、
uri-template要素で提供される式に従って動的に作成されます。 このコーディネーターでは、1 日という頻度はデータセットでも使われます。 コーディネーター要素の開始日と終了日はアクションがスケジュールされるときを制御 (およびその標準時刻を定義) するのに対し、データセットのinitial-instanceとfrequencyはuri-templateの作成で使われる日付の計算を制御します。 このケースでは、初期インスタンスをコーディネーターの開始の 1 日前に設定し、最初の日 (2017 年 1 月 1 日) のデータが確実に取得されるようにします。 データセットの日付計算は、initial-instance(12/31/2016) から、データセット頻度 (1 日) の増分で、コーディネーターによって設定される標準時刻 (最初のアクションの場合は 2017-01-01T00:00:00 GMT) を越えない最新の日付が見つかるまで行われます。空の
done-flag要素は、Oozie が指定された日時で入力データの存在をチェックするときに、Oozie がディレクトリまたはファイルの有無によってデータを利用できるかどうかを判断することを示します。 この例では、csv ファイルの存在です。 csv ファイルが存在する場合、Oozie はデータの準備が整っているものと見なし、ワークフロー インスタンスを開始してファイルを処理します。 csv ファイルが存在しない場合は、データの準備がまだできていないものと見なされ、ワークフローのその実行は待機状態になります。ポイント 3:
data-in要素は、関連付けられているデータセットのuri-templateの値を置き換えるときに標準時刻として使う特定のタイムスタンプを指定します。<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>この例では、インスタンスを式
${coord:current(0)}に設定しています。これにより、コーディネーターによって最初にスケジュールされたアクションの標準時刻を使うようになります。 つまり、コーディネーターが標準時刻 01/01/2017 で実行するようにアクションをスケジュールすると、01/01/2017 が URI テンプレートの YEAR (2017) 変数と MONTH (01) 変数の置換に使われます。 このインスタンスに対して URI テンプレートが計算された後、Oozie は予期されるディレクトリまたはファイルが使用可能かどうかをチェックし、それに従ってワークフローの次の実行をスケジュールします。
上記の 3 つのポイントの組み合わせにより、コーディネーターは日単位でソース データの処理をスケジュールするようになります。
ポイント 1: コーディネーターは、標準日 2017-01-01 で開始します。
ポイント 2: Oozie は
sourceDataFolder/2017-01-FlightData.csvで使用可能なデータを検索します。ポイント 3: Oozie は、そのファイルを見つけると、2017 年 1 月 1 日のデータを処理するワークフローのインスタンスをスケジュールします。 Oozie は、2017-01-02 の処理を続けます。 この評価は 2017-01-05 まで繰り返されますが、2017-01-05 は含まれません。
ワークフローと同様に、コーディネーターの構成は job.properties ファイルで定義されています。このファイルには、ワークフローで使われる設定のスーパーセットが保持されています。
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
この job.properties ファイルでは、以下のプロパティだけが新しく導入されます。
| プロパティ | 値のソース |
|---|---|
| oozie.coord.application.path | 実行する Oozie コーディネーターが含まれる coordinator.xml ファイルの場所を示します。 |
| hiveDailyTableNamePrefix | ステージング テーブルのテーブル名を動的に作成するときに使われるプレフィックスです。 |
| hiveDataFolderPrefix | すべてのステージング テーブルが格納されるパスのプレフィックスです。 |
Oozie コーディネーターを展開して実行する
コーディネーターでパイプラインを実行するには、ワークフローの場合と同様の方法で行います。ただし、ワークフローが含まれるフォルダーの 1 レベル上のフォルダーから作業する点が異なります。 このフォルダー規則によりディスク上でワークフローからコーディネーターが分離されるため、1 つのコーディネーターを異なる複数の子ワークフローと関連付けることができます。
ローカル コンピューターから SCP を使って、クラスターのヘッド ノードのローカル ストレージにコーディネーター ファイルをコピーします。
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~ヘッド ノードに SSH で接続します。
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netコーディネーター ファイルを HDFS にコピーします。
hdfs dfs -put ./* /oozie/コーディネーターを実行します。
oozie job -config job.properties -runOozie Web コンソールを使って状態を確認します。今度は、[Coordinator Jobs](コーディネーター ジョブ) タブの [All jobs](すべてのジョブ) を選びます。
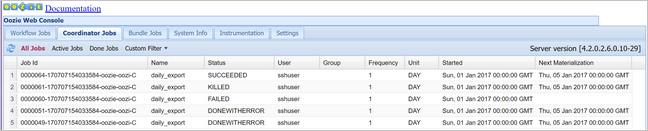
スケジュールされたアクションの一覧を表示するには、コーディネーター インスタンスを選びます。 このケースでは、予定時刻が 2017 年 1 月 1 日から 2017 年 1 月 4 日までの範囲にある 4 つのアクションが表示されるはずです。
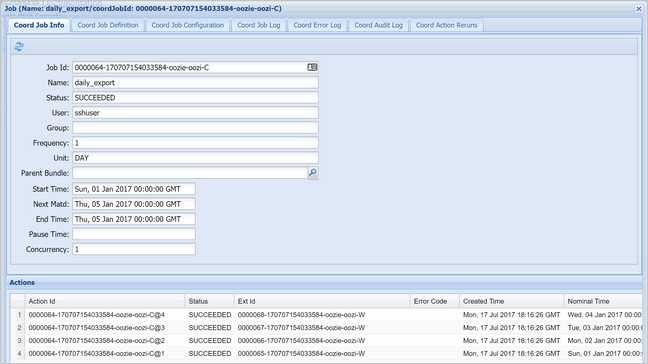
この一覧の各アクションは、1 日分のデータを処理するワークフローのインスタンスに対応します。その日の開始は標準時刻によって示されます。