Azure HDInsight の Apache Spark クラスターを Azure SQL Database に接続する方法について説明します。 次に、SQL データベースにデータを読み取り、書き込み、ストリーム配信します。 この記事の手順では、Jupyter Notebook を使用して Scala コード スニペットを実行します。 ただし、Scala または Python でスタンドアロン アプリケーションを作成し、同じタスクを実行できます。
前提条件
Azure HDInsight Spark クラスター。 HDInsight での Apache Spark クラスターの作成に関する記事の手順に従います。
Azure SQL データベース。 「Azure SQL Database でのデータベースの作成」の手順に従います。 サンプルの AdventureWorksLT スキーマとデータを使用してデータベースを作成してください。 また、クライアントの IP アドレスから SQL データベースへのアクセスを許可するサーバー レベルのファイアウォール規則を作成してください。 ファイアウォール規則を追加する手順については、同じ記事を参照してください。 SQL データベースを作成したら、次の値を手元に置いてください。 Spark クラスターからデータベースに接続するには、それらを必要とします。
- サーバー名。
- データベース名。
- Azure SQL Database 管理者のユーザー名/パスワード。
SQL Server Management Studio (SSMS)。 SSMS を使用した接続とデータの照会に関する手順に従ってください。
Jupyter Notebook を作成する
まず、Spark クラスターに関連付けられている Jupyter Notebook を作成します。 このノートブックを使用して、この記事で使用するコード スニペットを実行します。
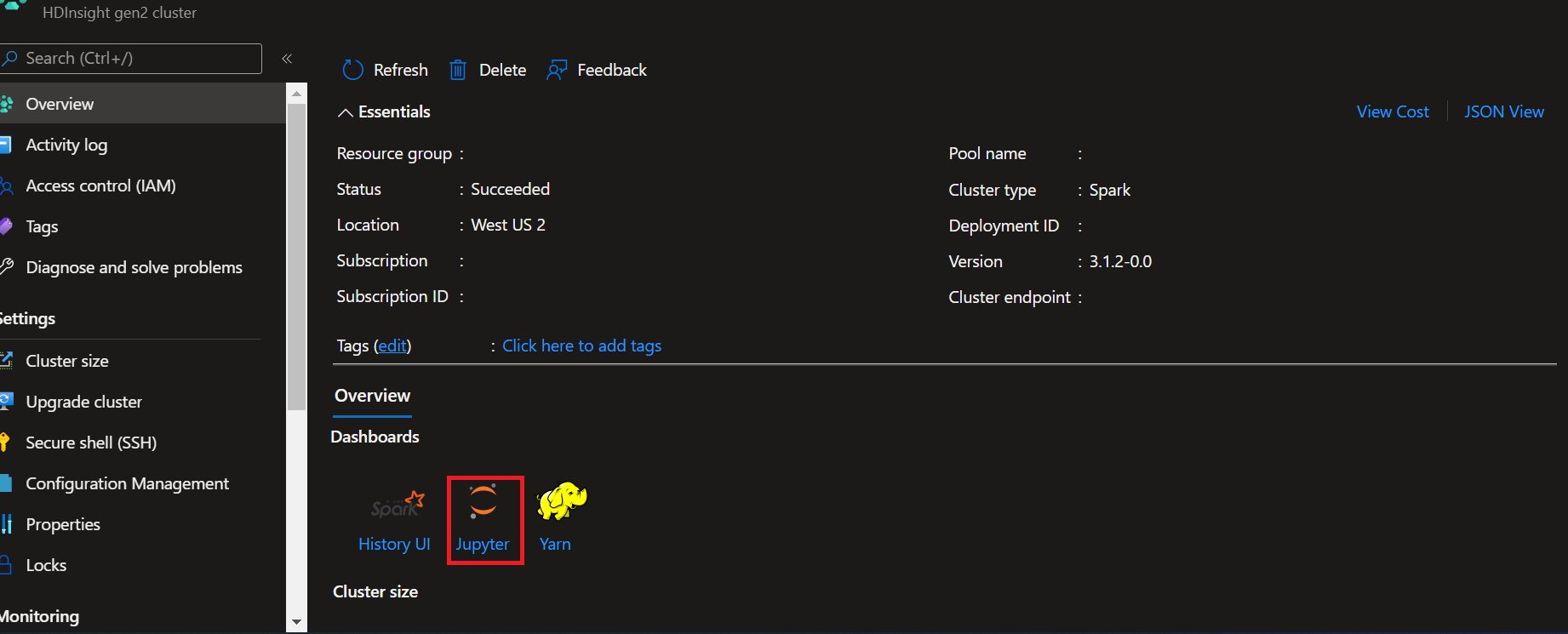
- Azure portal からクラスターを開きます。
- 右側にあるクラスター ダッシュボードの下にある Jupyter Notebook を選択します。 クラスター ダッシュボードが表示されない場合は、左側のメニューから [概要] を選択します。 入力を求められたら、クラスターの管理者資格情報を入力します。
注
ブラウザーで次の URL を開いて、Spark クラスター上の Jupyter Notebook にアクセスすることもできます。 CLUSTERNAME をクラスターの名前に置き換えます。
https://CLUSTERNAME.azurehdinsight.net/jupyter
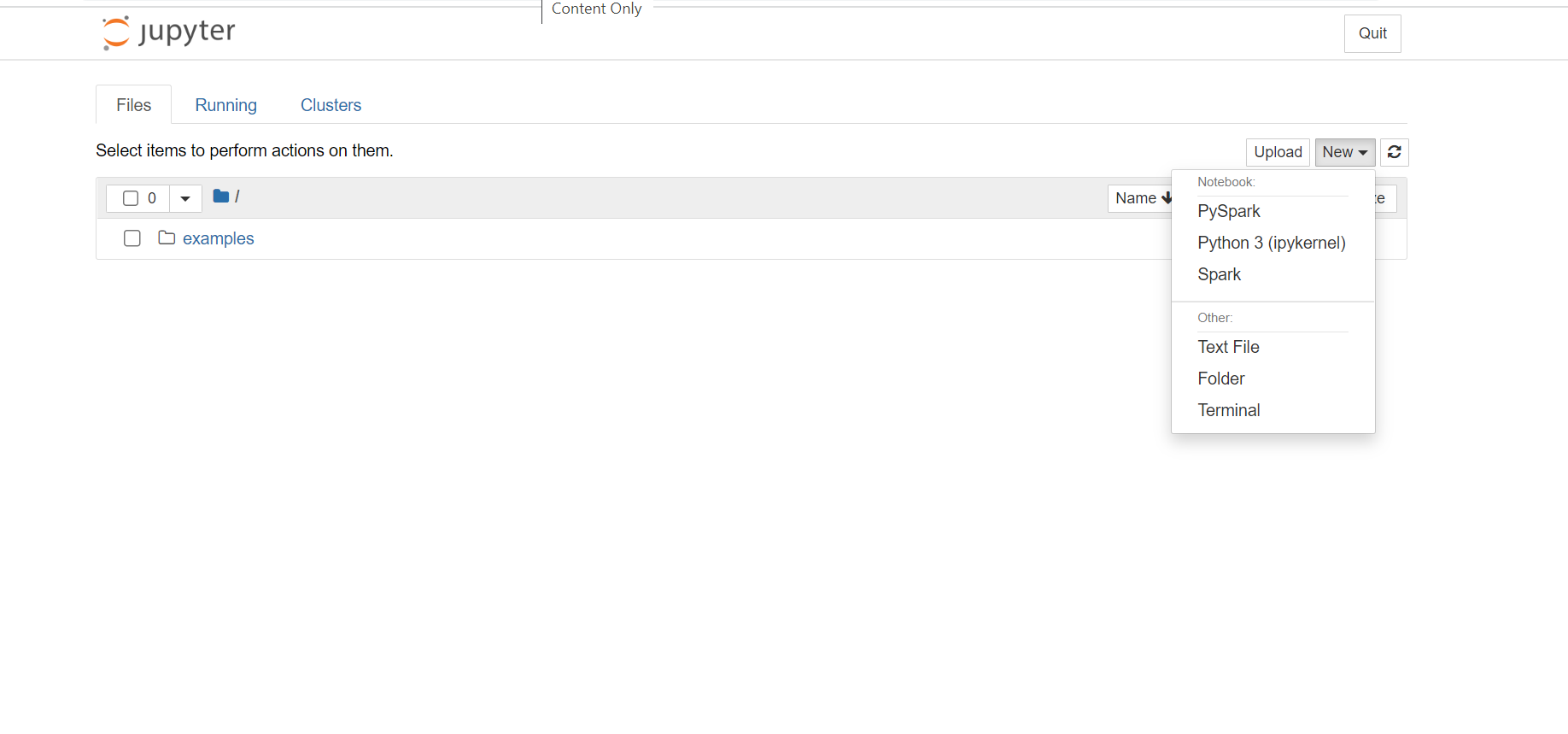
- Jupyter Notebook の右上隅にある [ 新規] をクリックし、[ Spark ] をクリックして Scala ノートブックを作成します。 HDInsight Spark クラスター上の Jupyter Notebook には、Python2 アプリケーション用の PySpark カーネルと、 Python3 アプリケーション用の PySpark3 カーネルも用意されています。 この記事では、Scala ノートブックを作成します。
カーネルの詳細については、「 HDInsight の Apache Spark クラスターで Jupyter Notebook カーネルを使用する」を参照してください。
注
現在、Spark から SQL Database へのデータのストリーミングは Scala と Java でのみサポートされているため、この記事では Spark (Scala) カーネルを使用します。 SQL からの読み取りと SQL への書き込みは Python を使用して実行できますが、この記事では一貫性を保つため、3 つの操作すべてに Scala を使用します。
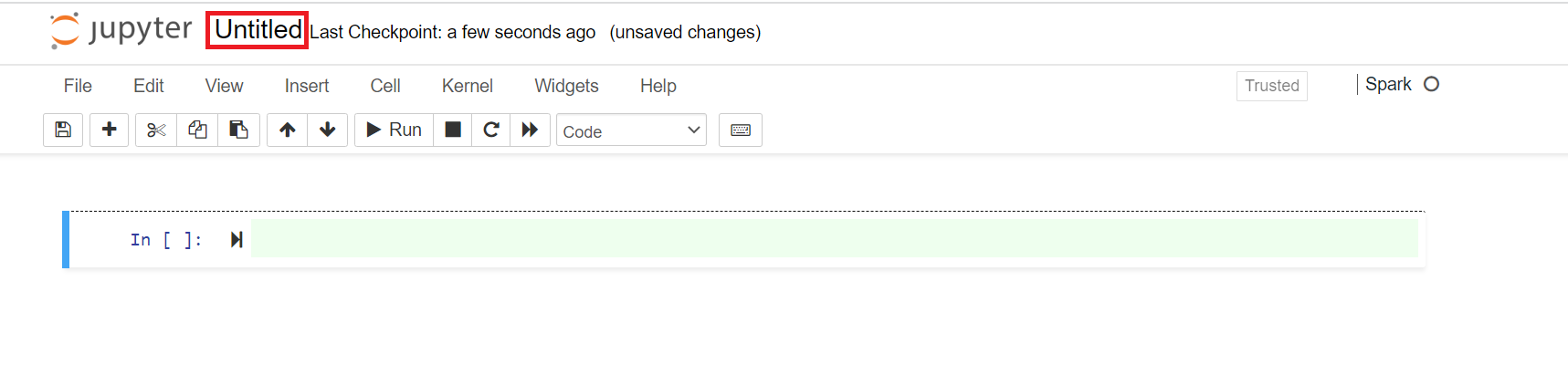
新しいノートブックが開き、既定の名前 ( 無題) が表示されます。 ノートブック名をクリックし、任意の名前を入力します。
これで、アプリケーションの作成を開始できます。
Azure SQL Database からデータを読み取る
このセクションでは、AdventureWorks データベースに存在するテーブル ( SalesLT.Address など) からデータを読み取ります。
新しい Jupyter Notebook のコード セルに次のスニペットを貼り付け、プレースホルダーの値をデータベースの値に置き換えます。
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Shift キーを押しながら Enter キーを押して、コード セルを実行します。
次のスニペットを使用して、Spark データフレーム API に渡すことができる JDBC URL を作成します。 このコードは、パラメーターを保持する
Propertiesオブジェクトを作成します。 スニペットをコード セルに貼り付け、 Shift キーを押しながら Enter キー を押して実行します。import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")次のスニペットを使用して、データベース内のテーブルのデータを含むデータフレームを作成します。 このスニペットでは、AdventureWorksLT データベースの一部として使用できる
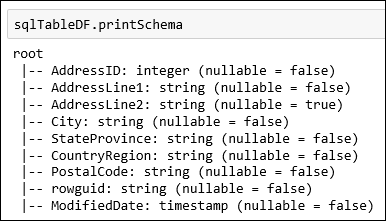
SalesLT.Addressテーブルを使用します。 スニペットをコード セルに貼り付け、 Shift キーを押しながら Enter キー を押して実行します。val sqlTableDF = spark.read.jdbc(jdbc_url, "SalesLT.Address", connectionProperties)データ スキーマの取得など、データフレームに対して操作を実行できるようになりました。
sqlTableDF.printSchema次の図のような出力が表示されます。
上位 10 行を取得するなどの操作を実行することもできます。
sqlTableDF.show(10)または、データセットから特定の列を取得します。
sqlTableDF.select("AddressLine1", "City").show(10)
Azure SQL Database にデータを書き込む
このセクションでは、クラスターで使用できるサンプル CSV ファイルを使用して、データベースにテーブルを作成し、データを設定します。 サンプル CSV ファイル (HVAC.csv) は、 HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvのすべての HDInsight クラスターで使用できます。
新しい Jupyter Notebook のコード セルに次のスニペットを貼り付け、プレースホルダーの値をデータベースの値に置き換えます。
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Shift キーを押しながら Enter キーを押して、コード セルを実行します。
次のスニペットは、Spark データフレーム API に渡すことができる JDBC URL を構築します。 このコードは、パラメーターを保持する
Propertiesオブジェクトを作成します。 スニペットをコード セルに貼り付け、 Shift キーを押しながら Enter キー を押して実行します。import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")次のスニペットを使用して、HVAC.csv のデータのスキーマを抽出し、そのスキーマを使用して CSV からデータフレーム (
readDf) にデータを読み込みます。 スニペットをコード セルに貼り付け、 Shift キーを押しながら Enter キー を押して実行します。val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readDf = spark.read.format("csv").schema(userSchema).load("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")readDfデータフレームを使用して、一時テーブル (temphvactable) を作成します。 次に、一時テーブルを使用して hive テーブルを作成hvactable_hive。readDf.createOrReplaceTempView("temphvactable") spark.sql("create table hvactable_hive as select * from temphvactable")最後に、Hive テーブルを使用して、データベースにテーブルを作成します。 次のスニペットでは、Azure SQL Database に
hvactableを作成します。spark.table("hvactable_hive").write.jdbc(jdbc_url, "hvactable", connectionProperties)SSMS を使用して Azure SQL Database に接続し、そこに
dbo.hvactableが表示されることを確認します。a. 次のスクリーンショットに示すように、接続の詳細を指定して SSMS を起動し、Azure SQL Database に接続します。
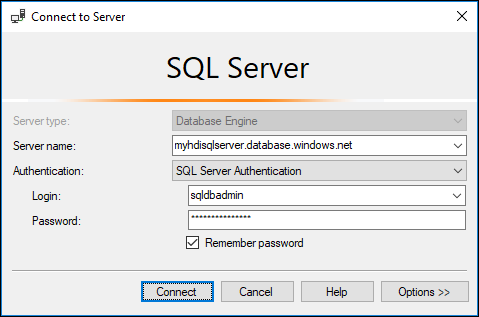
b。 オブジェクト エクスプローラーで、データベースとテーブル ノードを展開して、dbo.hvactable が作成されたのを確認します。
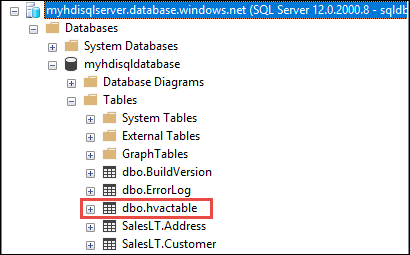
SSMS でクエリを実行して、テーブル内の列を表示します。
SELECT * from hvactable
Azure SQL Database にデータをストリーム配信する
このセクションでは、前のセクションで作成した hvactable にデータをストリーミングします。
最初の手順として、
hvactableにレコードがないことを確認します。 SSMS を使用して、テーブルに対して次のクエリを実行します。TRUNCATE TABLE [dbo].[hvactable]HDInsight Spark クラスターに新しい Jupyter Notebook を作成します。 コード セルに次のスニペットを貼り付け、 Shift キーを押しながら Enter キーを押します。
import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.streaming._ import java.sql.{Connection,DriverManager,ResultSet}HVAC.csvから
hvactableにデータをストリーミングします。 HVAC.csv ファイルは、/HdiSamples/HdiSamples/SensorSampleData/HVAC/のクラスターで使用できます。 次のスニペットでは、まず、ストリーミングされるデータのスキーマを取得します。 次に、そのスキーマを使用してストリーミング データフレームを作成します。 スニペットをコード セルに貼り付け、 Shift キーを押しながら Enter キー を押して実行します。val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readStreamDf = spark.readStream.schema(userSchema).csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/") readStreamDf.printSchema出力には、HVAC.csvのスキーマ が表示されます 。
hvactableにも同じスキーマがあります。 出力には、テーブル内の列が一覧表示されます。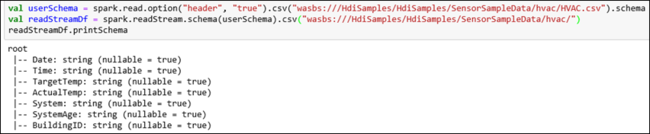
最後に、次のスニペットを使用して、HVAC.csv からデータを読み取り、データベース内の
hvactableにストリーム配信します。 スニペットをコード セルに貼り付け、プレースホルダーの値をデータベースの値に置き換え、 Shift キーを押しながら Enter キー を押して実行します。val WriteToSQLQuery = readStreamDf.writeStream.foreach(new ForeachWriter[Row] { var connection:java.sql.Connection = _ var statement:java.sql.Statement = _ val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>" val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver" val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" def open(partitionId: Long, version: Long):Boolean = { Class.forName(driver) connection = DriverManager.getConnection(jdbc_url, jdbcUsername, jdbcPassword) statement = connection.createStatement true } def process(value: Row): Unit = { val Date = value(0) val Time = value(1) val TargetTemp = value(2) val ActualTemp = value(3) val System = value(4) val SystemAge = value(5) val BuildingID = value(6) val valueStr = "'" + Date + "'," + "'" + Time + "'," + "'" + TargetTemp + "'," + "'" + ActualTemp + "'," + "'" + System + "'," + "'" + SystemAge + "'," + "'" + BuildingID + "'" statement.execute("INSERT INTO " + "dbo.hvactable" + " VALUES (" + valueStr + ")") } def close(errorOrNull: Throwable): Unit = { connection.close } }) var streamingQuery = WriteToSQLQuery.start()SQL Server Management Studio (SSMS) で次のクエリを実行して、データが
hvactableにストリーミングされていることを確認します。 クエリを実行するたびに、テーブル内の行数の増加が表示されます。SELECT COUNT(*) FROM hvactable