Azure Load Balancer では、次の診断機能が公開されています。
多次元メトリックとアラート: Azure Load Balancer 構成用に、Azure Monitor を介して多次元診断機能が提供されています。 ご利用の Standard Load Balancer リソースの監視、管理、トラブルシューティングを行うことができます。
リソース正常性: Load Balancer の Resource Health の状態は、[監視] にある [Resource Health] ページで確認できます。 この自動チェックによって、Load Balancer リソースの現在の可用性が通知されます。
この記事では、これらの機能の概要、および Standard Load Balancer でこれらの機能を使う方法について説明します。
多次元メトリック
Azure Load Balancer では Azure portal の Azure メトリックを介して多次元メトリックが提供されており、Load Balancer リソースにリアルタイム診断分析情報を取り込むために役立ちます。 Basic Load Balancer では、多次元メトリックはサポートされないことに注意してください
Load Balancer をさまざまに構成することで、次のメトリックを取得できます。
| メトリック | リソースの種類 | 説明 | 推奨される集計 |
|---|---|---|---|
| データパスの可用性 | パブリックおよび内部ロード バランサー | ロード バランサーでは、リージョン内からロード バランサー フロントエンドを経て、VM をサポートするネットワークに至るまでのデータ パスが継続的に使用されます。 正常なインスタンスが保持されていれば、測定ではアプリケーションの負荷分散されたトラフィックと同じパスに従います。 使用中のデータ パスが検証されています。 測定はアプリケーションには見えないので、他の操作と干渉することはありません。 | Average |
| 正常性プローブの状態 | パブリックおよび内部ロード バランサー | ロード バランサーでは、構成設定に従ってアプリケーション エンドポイントの正常性を監視する、分散型の正常性プローブ サービスが使われます。 このメトリックは、ロード バランサー プールのインスタンス エンドポイントの集計ビューまたはエンドポイントごとのフィルター ビューを提供します。 正常性プローブ構成で示されているアプリケーションの正常性を、Load Balancer がどのように表示するのかを確認できます。 | Average |
| SYN Count (SYN 数) | パブリックおよび内部ロード バランサー | ロード バランサーは、伝送制御プロトコル (TCP) 接続を終了したり、TCP またはユーザー データグラム パケット (UDP) フローと対話したりすることはありません。 フローとハンドシェイクは、常にソースと VM インスタンスの間で発生します。 TCP プロトコルのシナリオのトラブルシューティングを適切に行うために、SYN パケット カウンターを使用して TCP 接続試行の数を把握できます。 このメトリックは、受信済みの TCP SYN パケットの数を報告します。 | SUM |
| 送信元ネットワーク アドレス変換 (SNAT) 接続数 | パブリック ロード バランサー | ロード バランサーでは、パブリック IP アドレス フロントエンドにマスカレードされた送信フローの数を報告します。 SNAT ポートは有限のリソースです。 このメトリックはアプリケーションが送信フローで SNAT にどれくらい依存しているかを示すことができます。 送信 SNAT フローの成功および失敗のカウンタが報告されます。 カウンターは、トラブルシューティングや送信フローの健全性を解釈するために使用できます。 | SUM |
| 割り当てられた SNAT ポート | パブリック ロード バランサー | ロード バランサーでは、バックエンド インスタンスごとに割り当てられる SNAT ポートの数を報告します。 | Average |
| 使用された SNAT ポート | パブリック ロード バランサー | ロード バランサーでは、バックエンド インスタンスごとに活用されている SNAT ポートの数を報告します。 | Average |
| Byte Count (バイト数) | パブリックおよび内部ロード バランサー | ロード バランサーでは、フロントエンドごとに処理されたデータを報告します。 バックエンド インスタンス間でバイト数が均等に配布されていないことがわかります。 Azure の Load Balancer アルゴリズムはフローに基づいているため、これは予期されていることです。 | SUM |
| パケット数 | パブリックおよび内部ロード バランサー | ロード バランサーでは、フロントエンドごとに処理されたパケットを報告します。 | SUM |
Note
SYN パケット、バイト数、パケット数などの帯域幅関連のメトリックでは、UDR を介する (たとえば、NVA またはファイアウォールからの) 内部ロード バランサーへのトラフィックはキャプチャされません。
SYN 数、パケット数、SNAT 接続数、バイト数のメトリックでは、最大値と最小値を集計できません。 データ パスの可用性と正常性プローブの状態にはカウントの集計をお勧めしません。 正常性データを最適に表すためには、代わりに平均を使用します。
Azure Portal でロード バランサーのメトリックを表示する
Azure portal は [メトリック] ページを使用してロード バランサーのメトリックを公開します。 このページは、特定のリソースに関するロード バランサーのリソースページと、Azure Monitor のページの両方で利用可能です。
注意
Azure Load Balancer では、割り当て解除された仮想マシンに正常性プローブを送信しません。 仮想マシンの割り当てが解除されると、ロード バランサーでは、そのインスタンスに対するメトリックのレポートを停止します。 取得できないメトリックは、ポータルに破線で表示されるか、メトリックを取得できないことを示すエラー メッセージが表示されます。
ロード バランサー リソースのメトリックを表示するには:
[メトリック] ページに移動し、次のいずれかを実行します。
ロード バランサー リソース ページで、ドロップダウン リストからメトリックの種類を選択します。
Azure Monitor のページで、ロード バランサー リソースを選択します。
適切なメトリック集計の種類を設定します。
必要に応じて、フィルター処理およびグループ化を構成します。
必要に応じて、時間の範囲と集計を構成します。 既定では、時刻は UTC で表示されます。
Note
データは 1 分間に 1 回サンプリングされるため、時間の集計は、特定のメトリックを解釈する場合に重要になります。 時間の集計が 5 分に設定されていて、メトリック集計の種類である合計 (Sum) が SNAT 割り当てなどのメトリックに使用されている場合、グラフには、割り当て済みの SNAT ポートの合計数が 5 回表示されます。
推奨事項: メトリック集計の種類として Sum と Count を分析する場合、1 分を超える時間集計値を使用することをお勧めします。
API を使用してプログラムで多次元メトリックを取得する
多次元メトリックの定義と値を取得するための API のガイダンスについては、「Azure 監視 REST API のチュートリアル」をご覧ください。 これらのメトリックは、"すべてのメトリック" カテゴリに診断設定を追加することでストレージ アカウントに書き込むことができます。
一般的な診断シナリオと推奨されるビュー
データ パスが稼働していて Load Balancer Frontend に使用可能か?
展開
データ パスの可用性メトリックでは、VM が存在するコンピューティング ホストまでのデータ パスのリージョン内の正常性が示されます。 このメトリックには、構成と Azure インフラストラクチャに基づいて、ロード バランサーの正常性が反映されます。 このメトリックは次の目的に使うことができます。
サービスの外部可用性を監視します。
サービスがデプロイされているプラットフォームを調査し、正常かどうかを判断します。 ゲスト OS またはアプリケーション インスタンスが正常かどうかを確認します。
イベントがサービスと基盤のデータ プレーンのどちらに関係するかを切り分けます。 このメトリックと正常性プローブの状態メトリックを混同しないでください。
ロード バランサー リソースのデータ パスの可用性を取得するには:
正しいロード バランサー リソースが選ばれていることを確認します。
[メトリック] ドロップダウン リストで [Data Path Availability](データ パスの可用性) を選択します。
[集計] ドロップダウン リストで [平均] を選択します。
さらに、必要なフロントエンド IP アドレスまたはフロントエンド ポートのディメンションとしてフロントエンド IP アドレスまたはフロントエンド ポートに対するフィルターを追加します。 次に、選択したディメンションでグループ化します。
メトリックは、トラフィックをシミュレートするリージョン内のプローブ サービスによって生成されます。 プローブ サービスでは、デプロイのフロントエンドと負荷分散規則に一致するパケットが定期的に生成されます。 その後、パケットは、ソースから、バックエンド プール内の VM のホストまで、リージョンを移動します。 ロード バランサー インフラストラクチャは、他のすべてのトラフィックの場合と同じ負荷分散操作と変換操作を実行します。 バックエンド プール内の VM が存在するホストにプローブが到達した後に、ホストではプローブ サービスへの応答が生成されます。 VM はこのトラフィックを認識しません。
データ パスの可用性メトリックは、負荷分散規則を使用するフロントエンド IP 構成でのみ生成されることに注意してください。
データ パスの可用性メトリックは、次の理由により低下する可能性があります。
展開のバックエンド プールに正常な VM が残っていない。
インフラストラクチャ障害が発生した。
診断の目的で、データ パスの可用性メトリックと共に正常性プローブの状態を使うことができます。
ほとんどのシナリオでは集計として平均を使います。
Load Balancer のバックエンド インスタンスはプローブに応答しているか?
展開
正常性プローブ状態メトリックでは、ユーザーがロード バランサーの正常性プローブを構成するときにユーザーによって構成されたアプリケーションのデプロイの正常性が示されます。 ロード バランサーは、正常性プローブの状態を使って、新しいフローの送信先を決めます。 正常性プローブは、Azure インフラストラクチャのアドレスから送信され、VM のゲスト OS 内で認識されます。
ロード バランサー リソースの正常性プローブの状態メトリックを取得するには:
[正常性プローブの状態] メトリックと、集計の種類として [平均] を選択します。
必要なフロントエンドの IP アドレスまたはポート (またはその両方) にフィルターを適用します。
正常性プローブは次の理由で失敗します。
リッスンしていないポート、応答していないポート、または正しくないプロトコルを使用しているポートに対して、正常性プローブを構成している。 サービスが Direct Server Return またはフローティング IP ルールを使っている場合は、サービスが、NIC の IP 構成の IP アドレスと、フロントエンド IP アドレスで構成されたループバックをリッスンしていることを確認します。
ネットワーク セキュリティ グループ、VM のゲスト OS ファイアウォール、またはアプリケーション レイヤー フィルターが、正常性プローブのトラフィックを許可していません。
ほとんどのシナリオでは集計として平均を使います。
送信接続の統計情報を確認する方法
展開
SNAT 接続メトリックは、(送信フローの) 接続の成功と失敗の量を示します。
失敗した接続の量が 0 より大きい場合は、SNAT ポートが不足していることを示します。 さらに詳しく調査し、このようなエラーの原因を特定する必要があります。 SNAT ポートの不足は、送信フロー確立の失敗として示されます。 シナリオおよび動作メカニズムを理解し、SNAT ポートの不足を軽減する方法または回避する設計の方法を学習するには、送信接続に関する記事をご覧ください。
SNAT 接続の統計情報を取得するには:
トリックの種類として [SNAT Connections](SNAT 接続) を、集計として [合計] を選択します。
SNAT 接続の成功と失敗のカウントを異なる行に表示するには、 [接続の状態] でグループ化します。
SNAT ポートの使用状況と割り当てを確認する方法
展開
[使用された SNAT ポート] メトリックでは、送信フローを保持するために使用されている SNAT ポートの数が追跡されます。 このメトリックは、インターネット ソースと、ロード バランサーの背後にあり、パブリック IP アドレスを持たないバックエンド VM または仮想マシン スケール セットの間で確立された一意のフローの数を示します。 使用している SNAT の数と割り当てられた SNAT ポート メトリックを比較すると、サービスで SNAT 不足が発生しているか、またはそのリスクがあるか、および結果の送信フローで障害が発生しているかどうかを判断できます。
メトリックが送信フロー障害のリスクを示している場合は、サービスの正常性を確保するために、こちらの記事を参照し、この問題を軽減するための手順を実行してください。
SNAT ポートの使用状況と割り当てを確認するには:
グラフの時間の集計を 1 分に設定して、目的のデータが表示されるようにします。
メトリックの種類として [使用された SNAT ポート] および/または [割り当てられた SNAT ポート] を選択し、集計として [平均] を選択します。
既定では、これらのメトリックは、各バックエンド VM または仮想マシン スケール セットに割り当てられた、またはこれらが使用している SNAT ポートの平均数です。 これらは、ロード バランサーにマップされているすべてのフロントエンド パブリック IP に対応し、TCP と UDP を介して集計されます。
ロード バランサーが使用している、またはロード バランサーに割り当てられた SNAT ポートの合計数を確認するには、メトリック集計の [Sum](合計) を使用します。
フィルター処理によって、特定のプロトコルの種類、一連のバックエンド IP、および/またはフロントエンド IP に絞り込みます。
バックエンドまたはフロントエンド インスタンスごとに正常性を監視するには、分割を適用します。
- 分割では、一度に 1 つのメトリックしか表示できないので注意してください。
たとえば、コンピューターごとに TCP フローの SNAT 使用状況を監視するには、 [平均] で集計し、 [Backend IPs](バックエンド IP) で分割し、 [プロトコルの種類] でフィルター処理します。
サービスに対する受信/送信接続の試行を確認する方法
展開する
SYN パケット メトリックは、特定のフロントエンドに関連付けられている、到着した TCP SYN パケットまたは送信された TCP SYN パケット (送信フローの場合) の量を示します。 このメトリックを使用して、サービスへの TCP 接続の試行を把握できます。アウトバウンド接続の詳細については、「アウトバウンド接続に送信元ネットワーク アドレス変換 (SNAT) を使用する」を参照してください。
ほとんどのシナリオでは、集計として Sum を使用します。
ネットワーク帯域幅の消費量を確認する方法
展開
バイト カウンターおよびパケット カウンターのメトリックは、フロントエンドごとにサービスによって送信または受信されたバイトおよびパケットの量を示します。
ほとんどのシナリオでは、集計として Sum を使用します。
バイト数またはパケット数の統計情報を取得するには:
メトリックの種類として [Bytes Count](バイト数) および [Packet Count](パケット数) 、またはその両方を、集計として [Sum] を選択します。
以下のいずれかを実行します。
特定のフロントエンド IP、フロントエンド ポート、バックエンド IP、またはバックエンド ポートに対してフィルターを適用します。
フィルターを適用せずにロード バランサー リソースの全体的な統計情報を取得します。
ロード バランサーのデプロイを診断する方法
展開
データ パスの可用性メトリックと正常性プローブの状態メトリックを 1 つのグラフに組み合わせて使用すると、問題を探して解決する必要がある場所を特定することができます。 Azure が正常に動作している保証が得られ、この情報を利用して、構成またはアプリケーションが根本原因であることを確定できます。
正常性プローブ メトリックを使うと、ユーザーが指定した構成に従って、Azure が展開の正常性を表示する方法を解釈できます。 正常性プローブを確認することは、常に、原因を監視または特定するのに適した第一歩です。
その後さらに、データ パスの可用性メトリックを使って、特定のデプロイに関与する基盤データ プレーンの正常性を Azure が表示する方法についての分析情報を得ることができます。 次の例に示すように、両方のメトリックを組み合わせると、障害の可能性がある場所を分離できます。
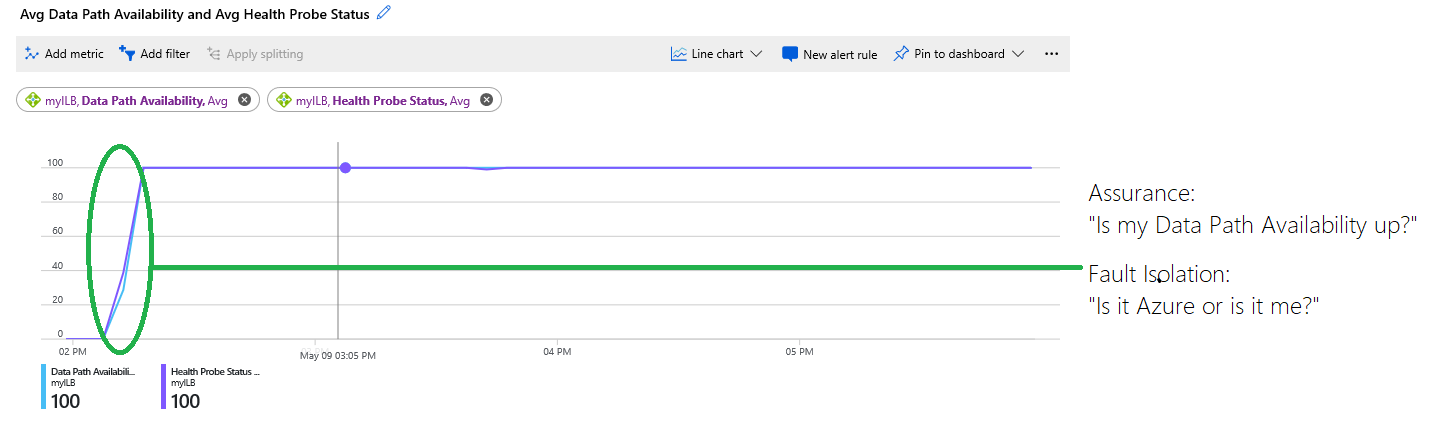
図: データ パスの可用性メトリックと正常性プローブの状態メトリックの組み合わせ
このグラフには次の情報が表示されます。
グラフの先頭では、VM をホストするインフラストラクチャは使用できず、0% でした。 その後、インフラストラクチャは正常で、VM に到達可能になり、複数の VM がバックエンドに配置されていました。 この情報は、データ パスの可用性を表す青いトレースによって示され、後で 100% になっています。
紫色のトレースで示されている正常性プローブの状態は、グラフの先頭では 0% です。 緑色の円で囲んだ領域は正常性プローブ状態が正常になった場所を示し、この時点で、ユーザーのデプロイは新しいフローを受け付けることができるようになりました。
このグラフを見ることで、ユーザーは、他の問題が発生していたかどうかを推測したりサポートに問い合わせたりすることなく、独力でデプロイのトラブルシューティングを行うことができます。 このサービスは、誤った構成またはアプリケーションの障害によって正常性プローブが失敗したため、利用できませんでした。
多次元メトリックのアラートを構成する
Azure Load Balancer では、多次元メトリックの簡単に構成できるアラートがサポートされています。 タッチレスのリソース監視エクスペリエンスを強化するには、特定のメトリックのカスタムしきい値を、さまざまなレベルの重大度でアラートをトリガーするように構成します。
アラートを構成するには、以下の手順に従います。
ロード バランサーのアラート ページに移動します
新しいアラート ルールの作成
アラートの条件を構成する (注: ノイズの多いアラートを回避するために、集計の種類を平均に設定し、過去 5 分間のデータを監視し、95% のしきい値を指定したアラートを構成することをお勧めします)。
(省略可能) 自動修復のアクション グループを追加します。
アラートの重大度、名前、直感的な反応を可能にする説明を割り当てます。
受信可用性のアラート
Note
ロード バランサーのバックエンド プールが空の場合、ロード バランサーにテストする有効なデータ パスはありません。 その結果、データ パスの可用性メトリックは使用できなくなり、データ パス可用性メトリックに対して構成された Azure アラートはトリガーされません。
受信の可用性についてアラートを生成する場合は、データ パスの可用性と正常性プローブの状態メトリックを使用して、2 つの異なるアラートを作成できます。 必要となるアラート ロジックはお客様のシナリオによって変わってきますが、ほとんどの構成では、次の例が役立ちます。
データ パスの可用性を使用すると、特定の負荷分散規則が使用できなくなったときにアラートを発生させることができます。 このアラートを構成するには、データ パスの可用性に関するアラート条件を設定し、フロントエンド ポートとフロントエンド IP アドレスの両方について、すべての現在値と将来値で分割します。 アラート ロジックを 0 以下に設定すると、いずれかの負荷分散規則が応答しなくなったときに、毎回このアラートが発生します。 どのような評価が望ましいかに応じて、集計の粒度と評価の頻度を設定してください。
正常性プローブの状態を使用すると、特定のバックエンド インスタンスが正常性プローブに長時間応答しない場合に、アラートを表示できます。 正常性プローブの状態メトリックを使用し、バックエンド IP アドレスとバックエンド ポートで分割するようにアラート条件を設定してください。 これにより、個々のバックエンド インスタンスが特定のポートでトラフィックを処理できるかどうかについて、個別にアラートを送信できるようになります。 集計の種類として平均を使用し、バックエンド インスタンスのプローブ頻度と、健全と思われるしきい値を考慮したうえで、しきい値を設定してください。
ディメンションによる分割を行わず、集計の種類として平均を使用して、バックエンド プール レベルでアラートを作成することもできます。 これにより、バックエンド プール メンバーの 50% が異常な場合にアラートを発するなどといったアラート ルールを設定できます。
送信可用性のアラート
送信の可用性については、"SNAT 接続数" メトリックと "使用中の SNAT ポート" メトリックを使用して、2 つの異なるアラートを構成できます。
送信接続エラーを検出するには、SNAT 接続数を使用し、接続状態を Failed でフィルター処理してアラートを構成します。 集計は合計を使用します。 次に、すべての現在値と将来値に設定されたバックエンド IP アドレスでこれを分割することにより、接続エラーが発生しているバックエンド インスタンスごとに、個別のアラートを生成することができます。 送信接続エラーの発生が予想される場合は、しきい値を 0 以上の数値に設定してください。
"使用中の SNAT ポート" を使用すると、SNAT の枯渇や送信接続エラーのリスクが高いことを示すアラートを生成できます。 このアラートを使用する場合は、バックエンド IP アドレスとプロトコルで分割してください。 平均集計を使用します。 しきい値は、インスタンスごとの割り当て済みポート数に対する割合として、安全でないと思われる水準よりも大きい値に設定します。 たとえば、バックエンド インスタンスが割り当てられたポートの 75% を使用したときに、重大度の低いアラートを発するように設定します。 割り当てられたポートの 90% または 100% を使用する場合は、重大度の高いアラートを構成します。
リソースの正常性状態
Standard Load Balancer リソースの正常性状態は、[監視] > [サービスの正常性] の既存の [リソース正常性] によって表示されます。 フロントエンドの負荷分散エンドポイントが利用できるかどうかを判断するデータ パス可用性を見ることで 2 分おきに評価されます。
| リソースの正常性状態 | 説明 |
|---|---|
| 利用可能 | ご利用の Standard Load Balancer リソースは正常であり、使用可能です。 |
| 低下しています | Standard Load Balancer のプラットフォームやユーザーが開始したイベントのパフォーマンスが影響を受けます。 [データパスの可用性] メトリックでは、少なくとも 2 分間に 90% を下回るが、25% を上回る正常性が報告されました。 この状態では、パフォーマンスは、中から重大までの影響を受けます。 ユーザーが開始したイベントによって可用性が影響を受けるかどうかをトラブルシューティング RHC ガイドに従って確認します。 |
| 使用不可 | ご利用の Standard Load Balancer リソースは正常ではありません。 [データパスの可用性] メトリックでは、少なくとも 2 分間に 25% を下回る正常性が報告されました。 この状態では、パフォーマンスが大きな影響を受けたり、受信接続の可用性が不足したりします。 ユーザーまたはプラットフォーム イベントによって可用性が失われる可能性もあります。 ユーザーが開始したイベントによって可用性が影響を受けるかどうかをトラブルシューティング RHC ガイドに従って確認します。 |
| Unknown | ロード バランサー リソースの正常性状態が更新されていないか、過去 10 分間にデータ パスの可用性に関する情報が受信されていません。 これは一時的な状態であり、データが受信されれば、すぐに正しい状態が反映されます。 |
パブリック Standard Load Balancer リソースの正常性を表示するには:
[監視]>[サービス正常性] の順に選択します。
[リソース正常性] を選び、[サブスクリプション ID] が選ばれていることと [リソースの種類] = [ロード バランサー] に設定されていることを確認します。
一覧で、正常性状態の履歴を表示するロード バランサー リソースを選択します。
リソースの正常性状態の一般的な説明については、リソース正常性に関するドキュメントを参照してください。
リソース正常性アラート
Azure Resource Health アラートは、ロード バランサー リソースの正常性状態が変化したときに、ほぼリアルタイムで通知できます。 ロード バランサー リソースが [機能低下] または [利用不可] 状態になったときに通知するように、リソース正常性アラートを設定することをお勧めします。
ロード バランサーの Azure リソース正常性アラートを作成すると、Azure はリソース正常性通知を Azure サブスクリプションに送信します。 アラートは、次に基づいて作成およびカスタマイズできます:
- 影響を受けたサブスクリプション
- 影響を受けるリソース グループ
- 影響を受けるリソースの種類 (ロード バランサー)
- 特定のリソース (アラートを設定するために選択した任意のロード バランサー リソース)
- 影響を受けるロード バランサー リソースのイベントの状態
- 影響を受けるロード バランサー リソースの現在の状態
- 影響を受けるロード バランサー リソースの以前の状態
- 影響を受けるロード バランサー リソースの理由の種類
アラートの送信先ユーザーを構成することもできます:
- 新しいアクション グループを作成します (将来のアラートで使用できます)
- 既存のアクション グループ
これらのリソース正常性アラートを設定する方法の詳細については、次を参照してください:
次のステップ
- ネットワーク分析の詳細を確認する。
- お使いの Load Balancer に事前構成されているこれらのメトリックを表示するには、分析情報の使用方法を確認してください。
- Standard Load Balancer について理解を深める。