AutoML での予測に関するよくある質問
適用対象:  Python SDK azure-ai-ml v2 (現行)
Python SDK azure-ai-ml v2 (現行)
この記事では、自動機械学習 (AutoML) での予測に関する一般的な質問に回答します。 AutoML の予測方法に関する一般的な情報については、「AutoML の予測方法の概要」の記事を参照してください。
AutoML で予測モデルの構築を開始するにはどうすればよいですか?
時系列予測モデルをトレーニングするための AutoML の設定に関する記事を最初にお読みください。 いくつかの Jupyter ノートブックで実践的な例を見つけることもできます。
自分のデータで AutoML が遅くなるのはなぜですか?
AutoML をより高速でスケーラブルにするための取り組みは常に進められています。 一般的な予測プラットフォームとして機能するために、AutoML は広範なデータ検証と複雑な特徴エンジニアリングを行い、大規模なモデル空間を検索します。 この複雑さは、データと構成によっては、多くの時間が必要になる場合があります。
実行時間が遅くなる一般的な原因の 1 つは、多数の時系列を含むデータに対して既定の設定で AutoML をトレーニングすることです。 多くの予測方法のコストは、系列の数に比例します。 たとえば、指数平滑法や Prophet などの方法は、トレーニング データの時系列ごとにモデルをトレーニングします。
AutoML の多数モデル機能は、トレーニング ジョブをコンピューティング クラスター全体に分散することでこれらのシナリオに対応します。 数百万の時系列を持つデータにも問題なく応用されています。 詳細については、「多数モデル」の記事セクションを参照してください。 また、注目度の高い競合データセットでの多数モデルの成功についても読むこともできます。
AutoML を高速化するにはどうすればよいですか?
「自分のデータで AutoML が遅くなるのはなぜですか?」の回答を参照して、ご自分のケースで AutoML が遅くなる理由を理解してください。
ジョブを高速化できる可能性がある次の構成変更を検討してください。
- ARIMA や Prophet などの時系列モデルをブロックする。
- ラグやローリング ウィンドウなどのルックバック特徴をオフにする。
- 以下を削減する。
- 試行/イテレーションの回数。
- 試行/イテレーションのタイムアウト。
- 実験のタイムアウト。
- クロス検証フォールド数。
- 早期終了が有効になっていることを確認します。
どのようなモデリング構成を使用すればよいですか?
AutoML 予測では、4 つの基本的な構成がサポートされています。
| 構成 | シナリオ | 長所 | 短所 |
|---|---|---|---|
| 既定の AutoML | データセットに、過去のビヘイビアーがほぼ同様の少数の時系列がある場合にお勧めします。 | - コードと SDK、または Azure Machine Learning スタジオから簡単に構成できます。 - AutoML では、回帰モデルによってすべての系列がトレーニングにまとめてプールされるため、さまざまな時系列間で学習できる。 詳細については、「モデルのグループ化」を参照してください。 |
- トレーニング データの時系列のビヘイビアーが異なる場合、回帰モデルの精度が低下する可能性がある。 - トレーニング データに多数の系列がある場合、時系列モデルのトレーニングに時間がかかることがある。 詳細については、「自分のデータで AutoML が遅くなるのはなぜですか?」の回答を参照してください。 |
| ディープ ラーニングを使用した AutoML | 1,000 を超える観測値を持つデータセット、および複雑なパターンを示す可能性のある多数の時系列にお勧めします。 有効にすると、トレーニング中にテンポラル畳み込みニューラル ネットワーク (TCN) モデルが AutoML によってスイープされます。 詳細については、「ディープ ラーニングを有効にする」を参照してください。 | - コードと SDK、または Azure Machine Learning スタジオから簡単に構成できます。 - すべての系列のデータが TCN によってプールされるため、クロスラーニングの機会がある。 - ディープ ニューラル ネットワーク (DNN) モデルの容量が大きいため、精度が高くなる可能性がある。 詳細については、「AutoML でのモデルの予測」を参照してください。 |
- DNN モデルが複雑なため、トレーニングにかなりの時間がかかる場合がある。 - 履歴の量が少ない系列は、これらのモデルの恩恵を受ける可能性が低い。 |
| 多数モデル | 多数の予測モデルをスケーラブルな方法でトレーニングおよび管理する必要がある場合にお勧めします。 詳細については、「多数モデル」の記事セクションを参照してください。 | - スケーラブル。 - 時系列のビヘイビアーが互いに異なる場合は、精度が高くなる可能性がある。 |
- 時系列間での学習がない。 - Azure Machine Learning スタジオから多数モデルのジョブを構成または実行することはできない。 現在は、コード/SDK エクスペリエンスのみが使用できます。 |
| 階層時系列 (HTS) | データ内の系列に入れ子になった階層構造があり、階層の集計レベルでトレーニングまたは予測を行う必要がある場合にお勧めします。 詳細については、「階層型時系列予測」の記事セクションを参照してください。 | - 集計レベルでのトレーニングにより、リーフ ノードの時系列のノイズが減り、モデルの精度が向上する可能性がある。 - トレーニング レベルから予測を集計または分解することで、階層の任意のレベルの予測を取得できる。 |
- トレーニングの集計レベルを指定する必要がある。 AutoML には現在、最適なレベルを見つけるためのアルゴリズムはありません。 |
注意
高い DNN 容量を最大限に活用するために、ディープ ラーニングが有効になっている場合は、GPU を備えた計算ノードを使用することをお勧めします。 CPU のみのノードと比較して、トレーニング時間が大幅に短縮されます。 詳細については、「GPU 最適化済み仮想マシンのサイズ」の記事を参照してください。
注意
HTS は、階層内の集計レベルでトレーニングまたは予測が必要なタスク用に設計されています。 リーフ ノードのトレーニングと予測のみを必要とする階層データの場合は、代わりに多数モデルを使用します。
オーバーフィットやデータ漏えいを防ぐにはどうすればよいですか?
AutoML では、クロス検証されたモデルの選択などの機械学習のベスト プラクティスを使用して、多くのオーバーフィットの問題を軽減します。 ただし、オーバーフィットの潜在的な原因は他にもあります。
入力データに、単純な数式を使用してターゲットから派生した特徴列が含まれている。 たとえば、ターゲットの正確な倍数である特徴は、ほぼ完璧なトレーニング スコアになる可能性があります。 ただし、モデルはサンプル外のデータには一般化されない可能性があります。 モデル トレーニングの前にデータを探索し、ターゲット情報を "リーク" する列を削除することをお勧めします。
トレーニング データで、予測ホライズンまで、未知の特徴が使用されている。 AutoML の回帰モデルでは、現在、すべての特徴が予測ホライズンまで既知であることを前提としています。 トレーニングの前にデータを探索し、過去でしか知られていない特徴列を削除することをお勧めします。
データの トレーニング、検証、またはテスト部分の間に、構造上の大きな相違点 (体制変革) がある。 たとえば、2020 年と 2021 年の間のほぼすべての商品の需要に対する COVID-19 パンデミックの影響を考えてみましょう。 これは体制変革の典型的な例です。 体制変革によるオーバーフィットは、シナリオに大きく依存しており、特定するには深い知識が必要な場合があるため、対処するのが最も困難な問題です。
防御の最前線として、全履歴の 10 ~ 20% を検証データまたはクロス検証データ用に予約するようにしてください。 トレーニング履歴が短い場合は、常にこの量の検証データを予約できるわけではありませんが、ベスト プラクティスです。 詳細については、「データをトレーニングして検証する」を参照してください。
トレーニング ジョブが完全な検証スコアを達成した場合、それは何を意味しますか?
トレーニング ジョブから検証メトリックを表示するときに、完全なスコアを確認できることがあります。 完全なスコアは、検証セットの予測と実績値が同じか、ほぼ同じであることを意味します。 たとえば、二乗平均平方根誤差が 0.0 に等しい、または R2 スコアが 1.0 である場合です。
完全な検証スコアは、"通常"、モデルが著しくオーバーフィットしており、データ漏えいが原因である可能性が高いことを示します。 最善のアクションは、データ漏えいを検査し、漏えいの原因となっている列を削除することです。
時系列データに一定間隔の観測値がない場合はどうすればよいですか?
AutoML のすべての予測モデルでは、トレーニング データがカレンダーに対して一定間隔の観測値を持っている必要があります。 この要件には、月単位や年単位の観測など、観測間の日数が異なる可能性がある場合が含まれます。 以下の 2 つのケースでは、時間依存データがこの要件を満たさない場合があります。
データの頻度は明確に定義されているが、観測値の欠落によって系列にギャップが生じている。 このケースでは、AutoML は頻度を検出し、ギャップの新しい観測値を埋め、欠落しているターゲットと特徴量の値を補完しようとします。 ユーザーは必要に応じて、SDK 設定または Web UI を使用して補完方法を構成できます。 詳細については、「カスタムの特徴量化」を参照してください。
データの頻度が明確に定義されていない。 つまり、観測間の期間に識別可能なパターンがありません。 販売時点管理システムなどのトランザクション データはその一例です。 このケースでは、選択した頻度にデータを集計するように AutoML を設定できます。 データとモデリングの目的に最適な一定の頻度を選択できます。 詳細については、データの集計に関するページを参照してください。
主要メトリックを選択するにはどうすればよいですか?
検証データの値によってスイープと選択の際に最適なモデルが決定されるため、主要メトリックは重要です。 予測タスクの主要メトリックには、通常、正規化された平均平方二乗誤差 (NRMSE) および正規化された平均絶対誤差 (NMAE) が最適な選択肢です。
どちらかを選択するには、NRMSE は誤差の 2 乗を使用するため、NMAE よりもトレーニング データの外れ値にペナルティが課されることに注意してください。 モデルの外れ値に対する感度を下げる場合は、NAME を選択した方がよい場合があります。 詳細については、「回帰/予測メトリック」を参照してください。
Note
R2 スコア (R2) を予測の主要メトリックとして使用することはお勧めしません。
Note
AutoML では、主要メトリックのカスタム関数またはユーザー指定関数はサポートされていません。 AutoML でサポートされている定義済みの主要メトリックのいずれかを選択する必要があります。
モデルの精度を向上させるにはどうすればよいですか?
- データに最適な方法で AutoML を構成していることを確認します。 詳細については、「どのようなモデリング構成を使用すればよいですか?」の回答を参照してください。
- 予測モデルを構築して改善する方法の詳細なガイドについては、予測レシピ ノートブックを参照してください。
- 複数の予測サイクルにわたってバック テストを使用してモデルを評価します。 この手順により、予測誤差のより確実な見積もりが得られ、改善を測定するためのベースラインが得られます。 例については、バックテスト ノートブックを参照してください。
- データにノイズが多い場合は、より粗い頻度に集約して SN 比を高めることを検討してください。 詳細については、「頻度とターゲット データの集計」を参照してください。
- ターゲットの予測に役立つ可能性がある新しい特徴を追加します。 対象分野の専門知識は、トレーニング データを選択するときに大いに役立ちます。
- 検証とテストのメトリック値を比較し、選択したモデルがデータにアンダーフィットかオーバーフィットかを判断します。 この知識は、より優れたトレーニング構成に役立ちます。 たとえば、オーバーフィットに対応して、より多くのクロス検証フォールドを使用する必要があると判断できます。
同じトレーニング データと構成から、AutoML で常に同じ最適モデルが選択されますか?
AutoML のモデル検索プロセスは決定論的ではないため、同じデータと構成から常に同じモデルが選択されるとは限りません。
メモリ不足エラーを修正するにはどうすればよいですか?
メモリ エラーには、次の 2 種類があります。
- RAM のメモリ不足
- ディスクのメモリ不足
まず、データに最適な方法で AutoML を構成していることを確認します。 詳細については、「どのようなモデリング構成を使用すればよいですか?」の回答を参照してください。
既定の AutoML 設定では、より多くの RAM を備えた計算ノードを使用することで、RAM のメモリ不足を修正できます。 既定の設定で AutoML を実行するには、原則として、RAM の空き容量が生データのサイズの少なくとも 10 倍である必要があります。
ディスクのメモリ不足エラーは、コンピューティング クラスターを削除して新しいクラスターを作成すると解決できます。
AutoML でサポートされている高度な予測シナリオは何ですか?
AutoML では、次の高度な予測シナリオがサポートされています。
- 分位点予測
- ローリング予測による堅牢なモデル評価
- 予測ホライズンを超えた予測
- トレーニング期間と予測期間の間に時間のギャップがある場合の予測
例と詳細については、高度な予測シナリオのノートブックを参照してください。
トレーニング ジョブの予測からメトリックを表示するにはどうすればよいですか?
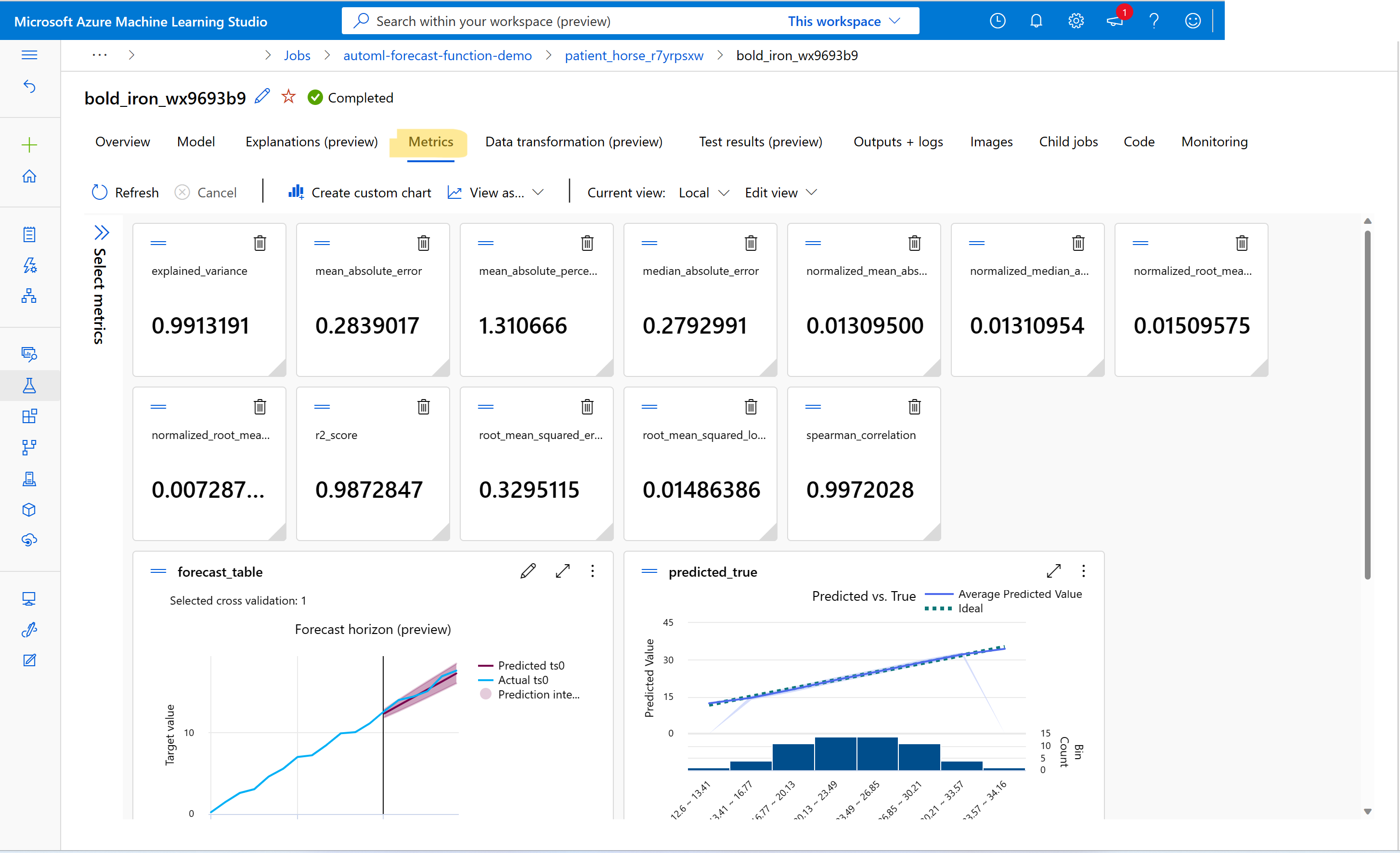
トレーニングと検証のメトリック値を確認するには、「スタジオでジョブ/実行の情報を表示する」を参照してください。 スタジオの AutoML ジョブ UI からモデルにアクセスし、[メトリック] タブを選択すると、AutoML でトレーニングされた任意の予測モデルのメトリックを表示できます。
トレーニング ジョブの予測でエラーをデバッグするにはどうすればよいですか?
AutoML 予測ジョブが失敗した場合、スタジオ UI のエラー メッセージが問題の診断と修正に役立つ可能性があります。 エラー メッセージ以外のエラーに関する最適な情報源は、ジョブのドライバー ログです。 ドライバー ログを検索する手順については、MLflow を使用したジョブ/実行情報の表示に関するページを参照してください。
Note
多数モデルまたは HTS ジョブの場合、トレーニングは通常、複数ノード コンピューティング クラスター上で行われます。 これらのジョブのログは、ノード IP アドレスごとに存在します。 この場合は、各ノードでエラー ログを検索する必要があります。 エラー ログとドライバー ログは、各ノード IP の user_logs フォルダーにあります。
トレーニング ジョブの予測からモデルをデプロイするにはどうすればよいですか?
次のいずれかの方法で、トレーニング ジョブの予測からモデルをデプロイできます。
- オンライン エンドポイント: デプロイに使用するスコアリング ファイルをチェックするか、スタジオのエンドポイント ページの [テスト] タブを選択して、デプロイで想定される入力の構造を確認します。 例については、このノートブックを参照してください。 オンライン デプロイの詳細については、「AutoML モデルをオンライン エンドポイントにデプロイする方法」を参照してください。
- バッチ エンドポイント: このデプロイ方法では、カスタム スコアリング スクリプトを作成する必要があります。 例については、このノートブックを参照してください。 バッチ デプロイの詳細については、「バッチ エンドポイントを使用したバッチ スコアリング」を参照してください。
UI のデプロイでは、次のオプションのいずれかを使用することをお勧めします。
- リアルタイム エンドポイント
- バッチ エンドポイント
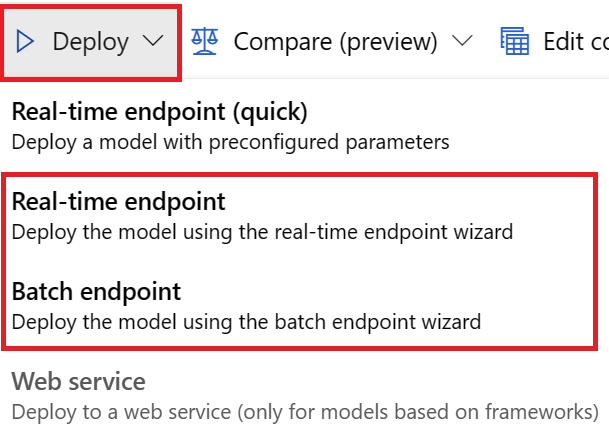
最初のオプションである [リアルタイム エンドポイント (クイック)] は使用しないでください。
Note
現時点では、SDK、CLI、または UI を使用してトレーニング ジョブの予測から MLflow モデルをデプロイすることはできません。 試してみると、エラーが発生します。
ワークスペース、環境、実験、コンピューティング インスタンス、コンピューティング先とは何ですか?
Azure Machine Learning の概念に詳しくない場合は、まず「Azure Machine Learning とは」および「Azure Machine Learning ワークスペースとは」の記事を参照してください。
次のステップ
- 時系列予測モデルをトレーニングするように AutoML を設定する方法の詳細について確認します。
- AutoML での時系列予測のカレンダー機能について確認します。
- AutoML が機械学習を使用して予測モデルを構築する方法について確認します。
- ラグ特徴量の AutoML 予測について確認します。