重要
この記事では、Azure Machine Learning SDK v1 の使用に関する情報を提供します。 SDK v1 は 2025 年 3 月 31 日の時点で非推奨となり、サポートは 2026 年 6 月 30 日に終了します。 SDK v1 は、その日付までインストールして使用できます。
2026 年 6 月 30 日より前に SDK v2 に移行することをお勧めします。 SDK v2 の詳細については、「 Azure Machine Learning Python SDK v2 と SDK v2 リファレンスとは」を参照してください。
この記事では、機械学習用に独自のデータを準備できるように、Azure Machine Learning デザイナーでデータセットを変換および保存する方法について説明します。
サンプルの Adult Census Income Binary Classification データセットを使って、2 つのデータセットを準備します。 1 つのデータセットには米国のみの成人の国勢調査情報が含まれており、もう 1 つのデータセットには米国以外の成人からの国勢調査情報が含まれます。
この記事では、次の方法について説明します。
- データセットを変換し、トレーニング用に準備します。
- 結果のデータセットをデータストアにエクスポートします。
- 結果を表示します。
このハウツー ガイドは、 パイプライン入力を使用したモデルの再トレーニングに関する 記事の前提条件です。 この記事では、変換されたデータセットを使用して、パイプライン入力を使用して複数のモデルをトレーニングする方法について説明します。
重要
このドキュメントで言及しているグラフィカル要素 (スタジオやデザイナーのボタンなど) が表示されない場合は、そのワークスペースに対する適切なレベルのアクセス許可がない可能性があります。 ご自分の Azure サブスクリプションの管理者に連絡して、適切なレベルのアクセス許可があることを確認してください。 詳細については、「ユーザーとロールを管理する」を参照してください。
データセットの変換
このセクションでは、サンプル データセットをインポートし、米国および米国以外のデータセットにデータを分割する方法について説明します。 詳細については、「 Azure Machine Learning デザイナーにデータをインポートする」を参照してください。
データのインポート
サンプル データセットをインポートするには、次の手順を使用します。
Azure Machine Learning Studio にサインインし、使用するワークスペースを選択します。
サイドバー メニューから [デザイナー ] を選択します。 [ クラシック事前構築済み] で、[ クラシック事前構築済みコンポーネントを使用して新しいパイプラインを作成する] を選択します。
パイプライン キャンバスの左側にある [ コンポーネント ] タブで、[ サンプル データ ] ノードを展開します。
[国勢調査の成人収入に関する二項分類] データセットをキャンバスにドラッグ アンド ドロップします。
Adult Census Income データセット コンポーネントを右選択し、[データのプレビュー] を選択します。
データ プレビュー ウィンドウを使用して、データセットを探索します。 ネイティブ国の列の値を特にメモしておきます。
データを分割する
データの分割コンポーネントを使用して、ネイティブ国の列に米国を含む行を識別して分割します。
キャンバスの左側にある [コンポーネント] タブで、[ データ変換 ] セクションを展開し、[ データの分割 ] コンポーネントを見つけます。
データ分割コンポーネントをキャンバスにドラッグし、そのコンポーネントをデータセット コンポーネントの下にドロップします。
データセット コンポーネントの出力を Split Data コンポーネントの入力に接続します。
[ データの分割 ] コンポーネントをダブルクリックして、[ データの分割 ] ウィンドウを開きます。
分割モードを正規表現に設定します。
正規表現:
\"native-country" United-Statesを入力します。正規表現モードでは、1 つの列に値があるかどうかがテストされます。 データ分割コンポーネントの詳細については、関連する アルゴリズム コンポーネントのリファレンス ページを参照 してください。
実際のパイプラインはこのスクリーンショットのようになります。

データセットの保存
データを分割するようにパイプラインを設定したら、データセットを保持する場所を指定する必要があります。 この例では、Export Data コンポーネントを使用して、データセットをデータストアに保存します。 データストアの詳細については、「 Azure Storage サービスへの接続」を参照してください。
コンポーネント パレットのキャンバスの左側にある [ データの入力と出力 ] セクションを展開し、[ データのエクスポート] コンポーネントを見つけます。
[データの分割] コンポーネントの下に 2 つの [データのエクスポート] コンポーネントをドラッグ アンド ドロップします。
Split Data コンポーネントの各出力ポートを別のエクスポート データ コンポーネントに接続します。
パイプラインは次のようになります。
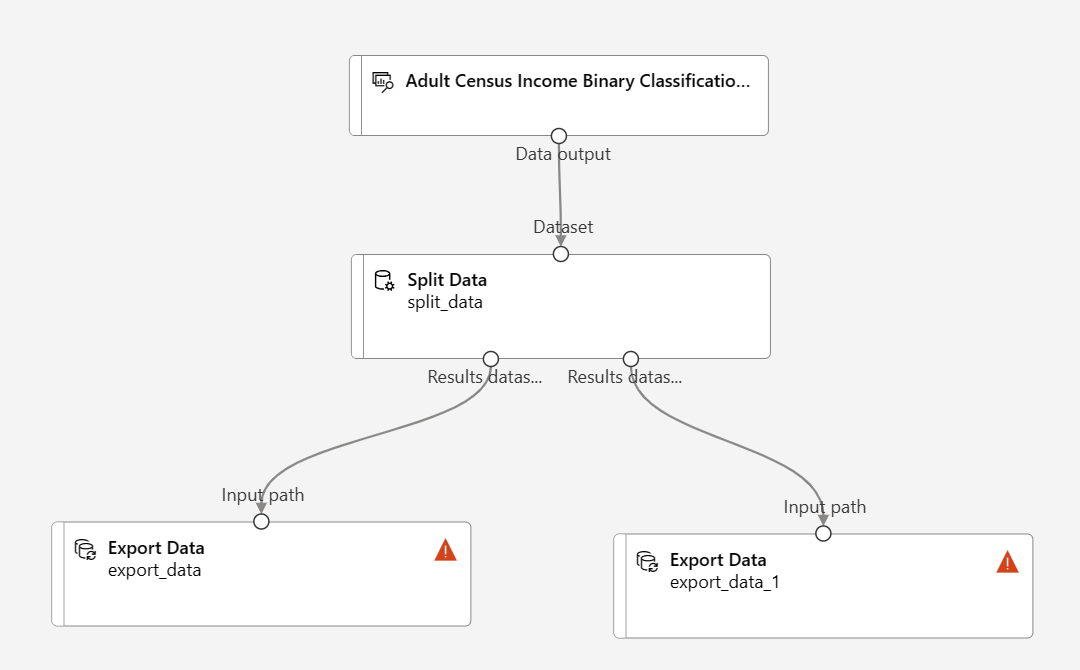
[データの分割] コンポーネントの左端のポートに接続されている [データのエクスポート] コンポーネントをダブルクリックして、[データのエクスポート] 構成ウィンドウを開きます。
[データの分割] コンポーネントでは、出力ポートの順序が重要です。 最初の出力ポートには、正規表現が true である行が含まれます。 この場合、最初のポートには米国ベースの収入の行が含まれており、2 番目のポートには米国以外の収入の行が含まれます。
次のオプションを設定します。
Datastore type (データストアの種類) :Azure Blob Storage
データストア: 既存のデータストアを選択するか、[ 新しいデータストア ] を選択して新しいデータストアを作成します
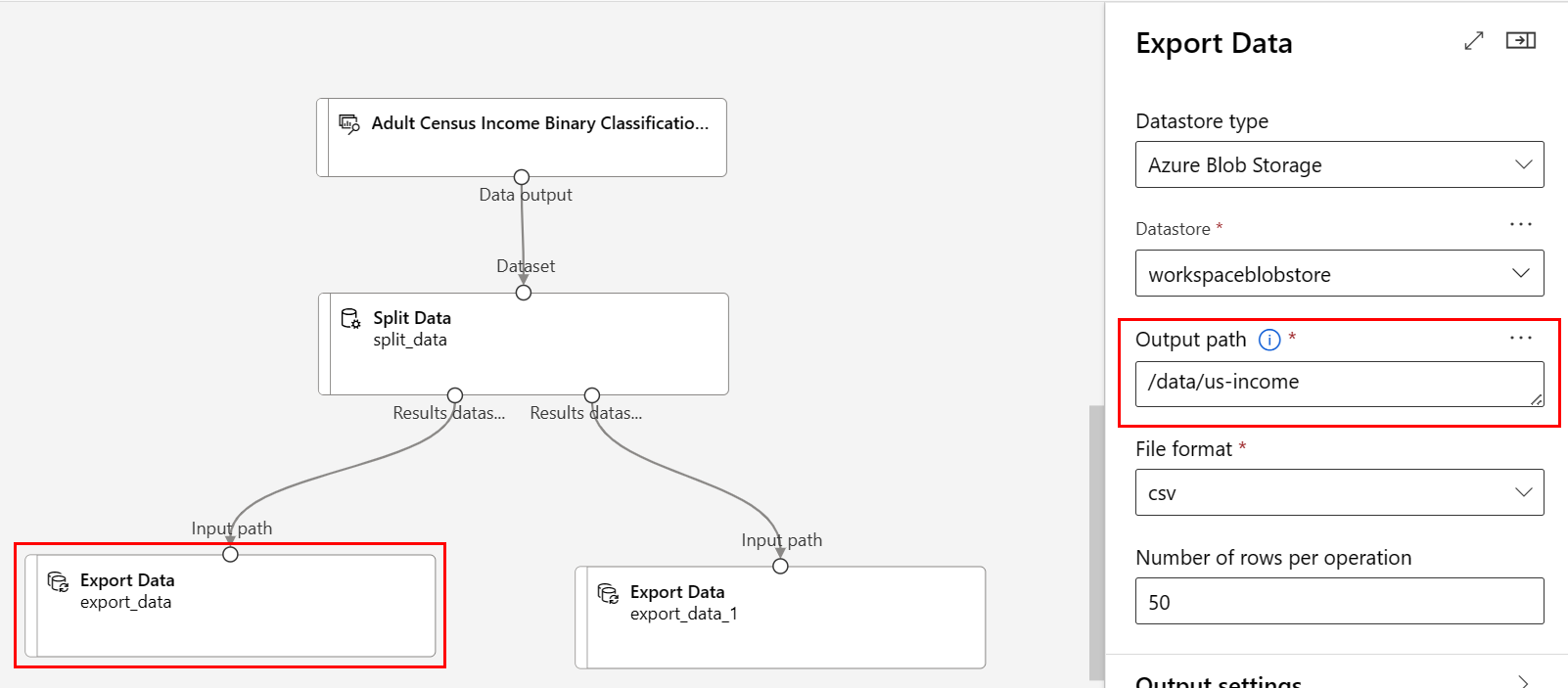
出力パス:
/data/us-incomeファイル形式: csv
注意
この記事では、現在の Azure Machine Learning ワークスペースに登録されているデータストアにアクセスできることを前提としています。 データストアのセットアップ手順については、 Azure Storage サービスへの接続に関するページを参照してください。
データストアがない場合は、データストアを作成できます。 例として、この記事では、ワークスペースに関連付けられている既定の BLOB ストレージ アカウントにデータセットを保存します。 データセットは、
azuremlという名前の新しいフォルダー内のdataコンテナーに保存されます。[データの分割] コンポーネントの右端のポートに接続されている [データのエクスポート] コンポーネントをダブルクリックして、[データのエクスポート] 構成ウィンドウを開きます。
次のオプションを設定します。
Datastore type (データストアの種類) :Azure Blob Storage
データストア: 前のデータストアを選択します
出力パス:
/data/non-us-incomeファイル形式: csv
Split Data の左側のポートに接続されている Export Data コンポーネントに Path
/data/us-incomeがあることを確認します。適切なポートに接続されている データのエクスポート コンポーネントに Path
/data/non-us-incomeがあることを確認します。パイプラインと設定は、次のようになります。


ジョブを送信する
データを分割してエクスポートするようにパイプラインを設定したら、パイプライン ジョブを送信します。
キャンバスの上部にある [構成] と [送信] を選択します。
実験を作成するには、[パイプライン ジョブのセットアップ] の [基本] ウィンドウで [新しい作成] オプションを選択します。
実験では、関連するパイプライン ジョブを論理的にまとめてグループ化します。 このパイプラインを将来実行する場合は、ログ記録と追跡の目的で同じ実験を使用する必要があります。
わかりやすい実験名 ( split-census-data など) を指定します。
[ ランタイム設定 ] ウィンドウで、コンピューティング リソースを選択または作成します。
[ 確認と送信] を選択し、[ 送信] を選択します。
結果の表示
パイプラインの実行が完了したら、Azure portal の BLOB ストレージに移動して結果を表示できます。 データが正常に分割されたことを確認するために、[データの分割] コンポーネントの中間結果を表示することもできます。
サイドバー メニューから [ジョブ ] を選択し、ジョブを選択します。
[データの分割] コンポーネントをダブルクリックします。
キャンバスの右側にあるコンポーネントの詳細ペインで、[ 出力 + ログ ] タブを選択します。
[ データ出力の表示 ] ドロップダウンを選択します。
結果データセット 1 の横にある視覚化アイコンを選択します。
![コンポーネントの詳細ペインの [データの分割] 結果データセットを示すスクリーンショット。](media/how-to-designer-transform-data/show-data-outputs.png?view=azureml-api-1)
ネイティブ国の列に値 United-States のみが含まれていることを確認します。
結果データセット 2 の横にある
 を選択します。
を選択します。ネイティブ国の列に値 United-States が含まれていないことを確認します。
![コンポーネントの詳細ペインの [データの分割] 結果データセットを示すスクリーンショット。](media/how-to-designer-transform-data/show-data-outputs.png?view=azureml-api-1#lightbox)
リソースをクリーンアップする
このハウツー ガイドのパート 2 に進む場合は、このセクションをスキップしてください。
重要
作成したリソースは、Azure Machine Learning のその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
すべてを削除する
作成したすべてのものを使用する予定がない場合は、料金が発生しないように、リソース グループ全体を削除します。
Azure portal で、ウィンドウの左側にある [リソース グループ] を選択します。
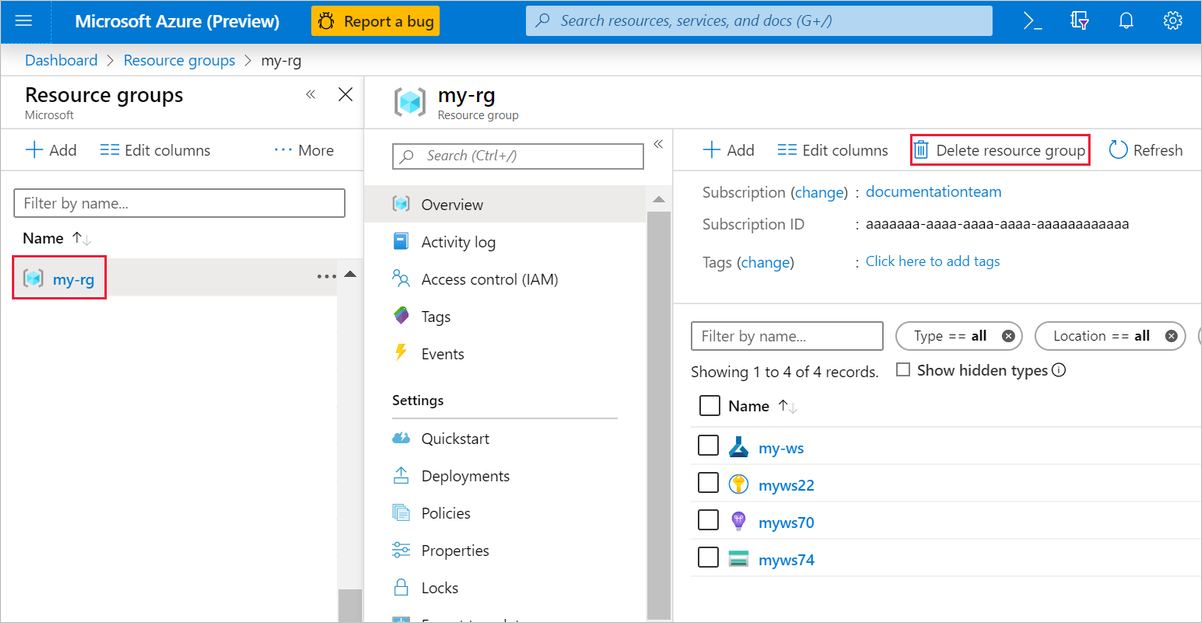
一覧から、作成したリソース グループを選択します。
[リソース グループの削除] を選択します。
リソース グループを削除すると、デザイナーで作成したすべてのリソースも削除されます。
個々の資産を削除する
実験を作成したデザイナーで、個々の資産を選択し、[削除] ボタンを選択してそれらを削除します。
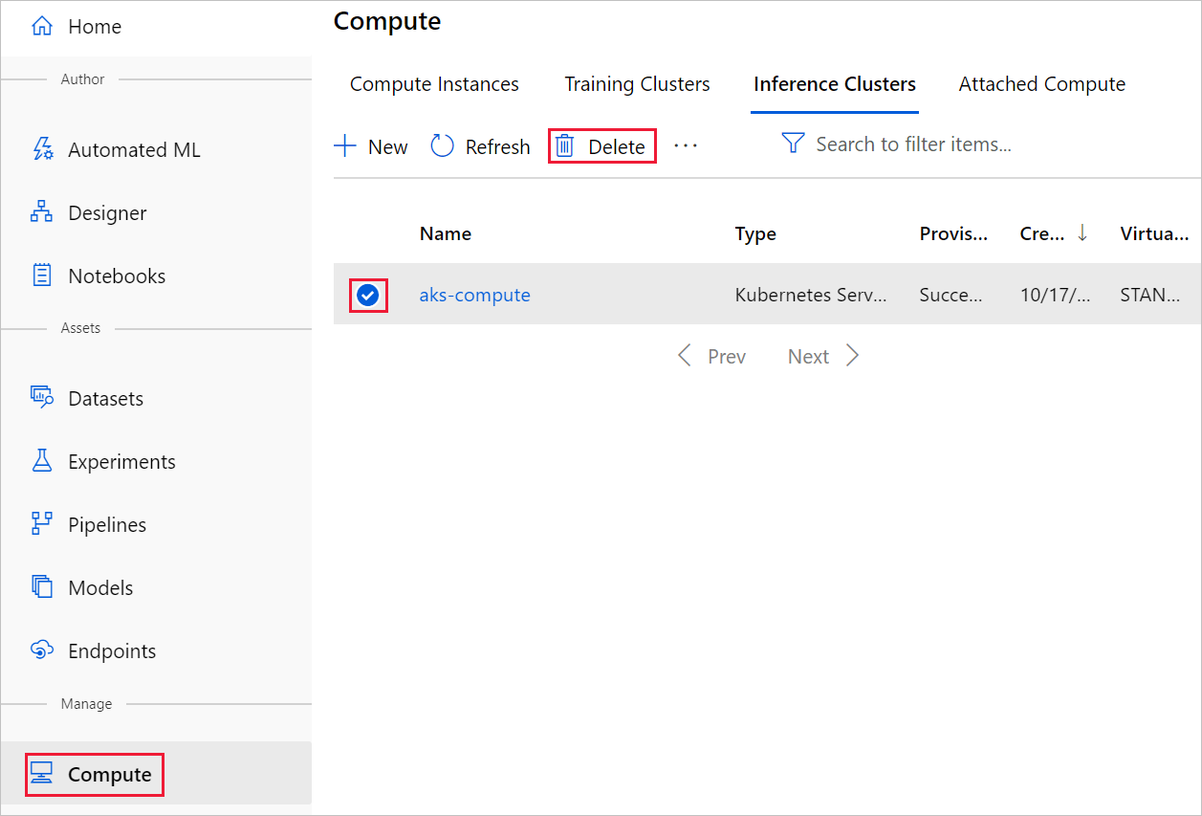
ここで作成したコンピューティング ターゲットは、使用されていない場合、自動的にゼロ ノードに自動スケーリングされます。 このアクションは、料金を最小限に抑えるために実行されます。 コンピューティング ターゲットを削除する場合は、次の手順を実行してください。
各データセットを選択し、[登録解除] を選択することによって、ワークスペースからデータセットを登録解除できます。
データセットを削除するには、Azure portal または Azure Storage Explorer を使用してストレージ アカウントに移動し、これらのアセットを手動で削除します。
次のステップ
このハウツー シリーズの次の部分に進みます。