Azure 仮想ネットワークで Azure Machine Learning Studio を使用する
ヒント
この記事の手順ではなく、Azure Machine Learning のマネージド仮想ネットワークを使用できます。 マネージド仮想ネットワークを使用すると、Azure Machine Learning はワークスペースとマネージド コンピューティングのネットワーク分離のジョブを処理します。 また、ワークスペースに必要なリソース (Azure Storage アカウントなど) のプライベート エンドポイントを追加することもできます。 詳しくは、ワークスペースのマネージド ネットワーク分離に関する記事をご覧ください。
この記事では、仮想ネットワークで Azure Machine Learning スタジオを使用する方法について説明します。 Studio には、AutoML、デザイナー、データのラベル付けなどの機能が含まれています。
仮想ネットワークでは、Studio の機能の一部が既定で無効になっています。 これらの機能を再度有効にするには、Studio で使用する予定のストレージ アカウントのマネージド ID を有効にする必要があります。
仮想ネットワークでは、次の操作が既定で無効になっています。
- スタジオでのデータのプレビュー
- デザイナーでのデータの視覚化
- デザイナーでのモデルのデプロイ
- AutoML 実験の送信
- ラベル付けプロジェクトの開始
スタジオでは、仮想ネットワーク内の次のデータストアの種類からのデータの読み取りがサポートされています。
- Azure Storage アカウント (BLOB とファイル)
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure SQL データベース
この記事では、次のことについて説明します。
- 仮想ネットワーク内に格納されているデータへのアクセス権を Studio に付与します。
- 仮想ネットワーク内のリソースから Studio にアクセスします。
- Studio によるストレージのセキュリティへの影響について理解します。
前提条件
ネットワーク セキュリティの概要に関するページを参照して、一般的な仮想ネットワークのシナリオとアーキテクチャについて理解してください。
使用する仮想ネットワークとサブネットが既に存在すること。
- 安全なワークスペースを作成する方法については、「チュートリアル: 安全なワークスペースを作成する」、「Bicep テンプレート」、または「Teraform テンプレート」を参照してください。
制限事項
Azure Storage アカウント
ストレージ アカウントが仮想ネットワーク内にある場合は、Studio を使用するための以下の追加の検証要件があります。
- ストレージ アカウントが サービス エンドポイント を使っている場合、ワークスペースのプライベート エンドポイントとストレージのサービス エンドポイントが 仮想ネットワーク の同じサブネット内に存在する必要があります。
- ストレージ アカウントが プライベート エンドポイント を使っている場合、ワークスペースのプライベート エンドポイントとストレージのプライベート エンドポイントが同じ 仮想ネットワーク 内に存在する必要があります。 この場合、サブネットは違っていても構いません。
デザイナーのサンプル パイプライン
ユーザーがデザイナー ホームページでサンプル パイプラインを実行できないという既知の問題があります。 この問題は、サンプル パイプラインで使用されるサンプル データセットが Azure グローバル データセットであるために発生します。 仮想ネットワーク環境からアクセスすることはできません。
この問題を解決するには、パブリック ワークスペースを使用してサンプル パイプラインを実行します。 または、サンプル データセットを、仮想ネットワーク内のワークスペース内の独自のデータセットに置き換えます。
データストア: Azure Storage アカウント
次の手順を使用して、Azure Blob および File ストレージの格納データへのアクセスを有効にします。
ヒント
ワークスペースの既定のストレージ アカウントの場合、最初の手順は必要ありません。 その他の手順は、既定のストレージ アカウントを含め、VNet の背後にありワークスペースで使用されている "すべて" のストレージ アカウントに必要です。
ストレージ アカウントがワークスペースの "既定" のストレージである場合は、この手順をスキップします。 これが既定でない場合は、Azure Storage アカウントのストレージ BLOB データ閲覧者ロールをワークスペース マネージド ID に付与し、BLOB ストレージからデータを読み取れるようにします。
詳細については、BLOB データ閲覧者組み込みロールに関するページを参照してください。
Azure ストレージ アカウントの、ストレージ BLOB データ閲覧者ロールを Azure ユーザー ID に付与します。 ワークスペースのマネージド ID に閲覧者ロールがある場合でも、スタジオは ID を使用して BLOB ストレージへのデータにアクセスします。
詳細については、BLOB データ閲覧者組み込みロールに関するページを参照してください。
ストレージ プライベート エンドポイントの閲覧者ロールをワークスペース マネージド ID に付与します。 ストレージ サービスにプライベート エンドポイントを使用している場合は、プライベート エンドポイントへの閲覧者アクセス権をワークスペースのマネージド ID に付与します。 Microsoft Entra ID のワークスペースのマネージド ID の名前は、Azure Machine Learning ワークスペースと同じ名前です。 プライベート エンドポイントは、BLOB とファイル ストレージの両方の種類に必要です。
ヒント
ストレージ アカウントでは、複数のプライベート エンドポイントを持つことができます。 たとえば、1 つのストレージ アカウントが、BLOB、ファイル、dfs (Azure Data Lake Storage Gen2) 用に個別のプライベート エンドポイントを持つことができます。 これらのすべてのエンドポイントにこのマネージド ID を追加します。
詳細については、閲覧者組み込みロールに関するページを参照してください。
既定のストレージ アカウントでマネージド ID 認証を有効にします。 各 Azure Machine Learning ワークスペースには、既定の BLOB ストレージ アカウントと既定のファイル ストア アカウントの 2 つの既定のストレージ アカウントがあります。 どちらも、ワークスペースを作成するときに定義されます。 データストア 管理ページで新しい既定値を設定することもできます。
次の表に、ワークスペースの既定のストレージ アカウントにマネージド ID 認証を使用する理由を示します。
ストレージ アカウント Notes ワークスペースの既定の BLOB ストレージ デザイナーからのモデル アセットが格納されます。 デザイナーでモデルをデプロイするには、このストレージ アカウントでマネージド ID 認証を有効にします。 マネージド ID 認証が無効になっている場合は、ユーザーの ID を使用して BLOB の格納データにアクセスします。
マネージド ID を使用するように構成されている既定以外のデータストアを使用するデザイナー パイプラインは、視覚化して実行できます。 ただし、既定のデータストアでマネージド ID を有効にせずにトレーニング済みのモデルをデプロイしようとすると、他のデータストアの使用に関係なく、デプロイは失敗します。ワークスペースの既定のファイル ストア AutoML 実験アセットが格納されます。 AutoML 実験を送信するには、このストレージ アカウントでマネージド ID 認証を有効にします。 マネージド ID 認証を使用するようにデータストアを構成します。 サービス エンドポイントまたはプライベート エンドポイントのいずれかが設定されている仮想ネットワークに Azure ストレージ アカウントを追加した後、マネージド ID 認証を使用するようにデータストアを構成する必要があります。 これにより、Studio でストレージ アカウント内のデータにアクセスできるようになります。
Azure Machine Learning では、データストアを使用してストレージ アカウントに接続します。 新しいデータストアを作成するときは、次の手順を使用して、マネージド ID 認証を使用するようにデータストアを構成します。
スタジオで、 [データストア] を選択します。
新しいデータストアを作成するには、[+ 作成] を選択します。
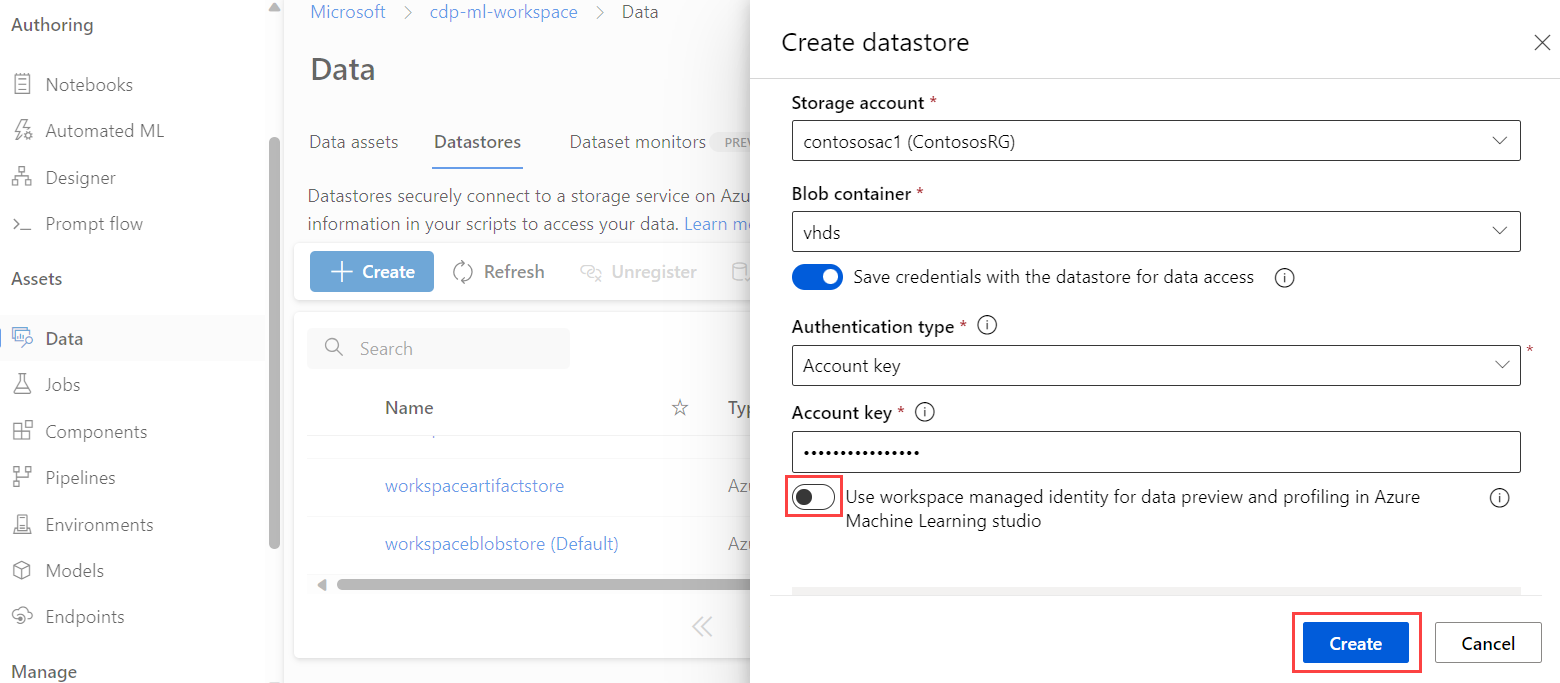
データストアの設定で、[Azure Machine Learning スタジオでのデータのプレビューおよびプロファイルにワークスペース マネージド ID を使用する] のスイッチをオンにします。
Azure Storage アカウントの [ネットワーク] 設定で、
Microsoft.MachineLearningService/workspacesリソースの種類 を追加し、[インスタンス名] をそのワークスペースに設定します。
この手順により、Azure ロールベース アクセス制御 (RBAC) を使用して、ワークスペースのマネージド ID が新しいストレージ サービスに閲覧者として追加されます。 閲覧者アクセス権では、ワークスペースはリソースを表示できますが、変更を加えることはできません。


データストア: Azure Data Lake Storage Gen1
Azure Data Lake Storage Gen1 をデータストアとして使用する場合は、POSIX スタイルのアクセス制御リストのみを使用できます。 他のセキュリティ プリンシパルと同様に、ワークスペースのマネージド ID にリソースへのアクセス権を割り当てることができます。 詳細については、「Azure Data Lake Storage Gen1 のアクセス制御」を参照してください。
データストア: Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 をデータストアとして使用する場合、仮想ネットワーク内のデータ アクセスの制御には、Azure RBAC と POSIX スタイルのアクセス制御リスト (ACL) の両方を使用できます。
Azure RBAC を使用するには、この記事の「データストア: Azure Storage アカウント」セクションの手順に従います。 Data Lake Storage Gen2 は Azure Storage をベースにしているため、Azure RBAC を使用する手順は同じです。
ACL を使用する場合は、他のセキュリティ プリンシパルと同様に、ワークスペースのマネージド ID にアクセス権を割り当てることができます。 詳細については、「ファイルとディレクトリのアクセス制御リスト」を参照してください。
データストア: Azure SQL Database
マネージド ID を使用して Azure SQL Database 内の格納データにアクセスするには、そのマネージド ID にマップされる SQL 包含ユーザーを作成する必要があります。 外部プロバイダーからユーザーを作成する方法の詳細については、「Microsoft Entra ID にマップされる包含ユーザーを作成する」を参照してください。
SQL 包含ユーザーを作成したら、これに対してアクセス許可を付与するため、GRANT T-SQL コマンドを使用します。
中間コンポーネントの出力
Azure Machine Learning デザイナーの中間コンポーネント出力を使用する場合、デザイナーの任意のコンポーネントについて出力場所を指定できます。 これは、セキュリティ、ログ、または監査の目的で、中間データセットを別の場所に格納する場合に使用します。 出力を指定するには、次の手順を実行します。
- 出力を指定するコンポーネントを選択します。
- [コンポーネント設定] ウィンドウで、[出力設定] を選びます。
- 各コンポーネントの出力に使用するデータストアを指定します。
仮想ネットワーク内の中間ストレージ アカウントにアクセスできることを確認してください。 それ以外の場合、パイプラインは失敗します。
また、出力データを視覚化するために、中間ストレージ アカウントのマネージド ID 認証を有効にします。
VNet 内のリソースから Studio にアクセスする
仮想ネットワーク内のリソース (コンピューティング インスタンスや仮想マシンなど) からスタジオにアクセスする場合は、仮想ネットワークからスタジオへの送信トラフィックを許可する必要があります。
たとえば、ネットワーク セキュリティ グループ (NSG) を使用して送信トラフィックを制限している場合は、AzureFrontDoor.Frontend のサービス タグ宛先に規則を追加します。
ファイアウォールの設定
Azure ストレージ アカウントなど、一部のストレージ サービスには、その特定のサービス インスタンスのパブリック エンドポイントに適用されるファイアウォール設定があります。 通常、この設定を使用すると、パブリック インターネットの特定の IP アドレスからのアクセスを許可または禁止できます。 Azure Machine Learning スタジオを使用している場合、これはサポートされません。 Azure Machine Learning SDK または CLI を使用している場合にサポートされます。
ヒント
Azure Machine Learning スタジオは、Azure Firewall サービスを使用している場合にサポートされます。 詳細については、ネットワークの着信トラフィックおよび送信トラフィックの構成に関する記事を参照してください。
関連するコンテンツ
この記事は、Azure Machine Learning ワークフローのセキュリティ保護に関するシリーズの一部です。 このシリーズの他の記事は次のとおりです。