データ資産をインポートする (プレビュー)
- [アーティクル]
-
-
適用対象: Azure CLI ML 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ML 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、外部ソースから Azure Machine Learning プラットフォームにデータをインポートする方法について説明します。 データが正常にインポートされると、そのインポート時に指定された名前で Azure Machine Learning データ資産が自動的に作成され、登録されます。 Azure Machine Learning データ資産は、Web ブラウザーのブックマーク (お気に入り) に似ています。 最も頻繁に使用されるデータを指す長いストレージ パス (URI) を覚える必要はありません。 代わりに、データ資産を作成し、フレンドリ名を使用してその資産にアクセスできます。
データ インポートでは、Azure Machine Learning トレーニング ジョブでのデータ アクセスの高速化と信頼性の向上のために、ソース データのキャッシュとメタデータが作成されます。 データ キャッシュにより、ネットワークと接続の制約が回避されます。 キャッシュされたデータは、再現性をサポートするためにバージョン管理されます。 これにより、SQL Server ソースからインポートされたデータのバージョン管理機能が得られます。 さらに、キャッシュされたデータにより、タスクを監査するためのデータ系列が提供されます。 データ インポートでは、バックグラウンドで ADF (Azure Data Factory のパイプライン) が使用されます。したがって、ユーザーは ADF との複雑な対話処理を回避できます。 Azure Machine Learning では、ADF コンピューティング リソース プールのサイズの管理、コンピューティング リソースのプロビジョニング、破棄がバックグランドで処理され、適切な並列化の特定によりデータ転送が最適化されます。
転送されたデータはパーティション分割され、Azure Storage に Parquet ファイルとして安全に格納されます。 これにより、トレーニング中の処理が高速になります。 ADF コンピューティング コストには、データ転送に使用される時間のみが含まれます。 キャッシュされたデータは外部ソースからインポートされたデータのコピーであるため、ストレージ コストにはデータのキャッシュに必要な時間のみが含まれます。 Azure Storage によって、その外部ソースがホストされます。
キャッシュ機能には、前払いのコンピューティング コストとストレージ コストが含まれます。 しかしながら、トレーニング中に外部ソース データに直接接続する場合と比較して、トレーニングのコンピューティング コストが繰り返し発生することが減少するため、元が取れ、費用を節約できます。 データは Parquet ファイルとしてキャッシュされるため、より大きなデータ セットの接続タイムアウトに対するジョブ トレーニングの速度と信頼性が向上します。 これにより、再実行が減り、トレーニングの失敗が少なくなります。
Amazon S3、Azure SQL、Snowflake からデータをインポートできます。
重要
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー バージョンはサービス レベル アグリーメントなしで提供されており、運用環境のワークロードに使用することは推奨されません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。
詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
前提条件
データ資産を作成して操作するには、以下が必要です。
Note
データを正常にインポートするには、SDK 用の最新の azure-ai-ml パッケージ (バージョン 1.15.0 以降) と ml 拡張機能 (バージョン 2.15.1 以降) がインストールされていることを確認してください。
以前の SDK パッケージまたは CLI 拡張機能がある場合は、以前のものを削除し、タブ セクションに表示されているコードを使用して新しいものをインストールしてください。 次に示す SDK および CLI 向けの手順に従います。
コードのバージョン
az extension remove -n ml
az extension add -n ml --yes
az extension show -n ml #(the version value needs to be 2.15.1 or later)
pip install azure-ai-ml
pip show azure-ai-ml #(the version value needs to be 1.15.0 or later)
外部データベースから mltable データ資産としてインポートする
注意
外部データベースには、Snowflake、Azure SQL などの形式を使用できます。
次のコード サンプルでは、外部データベースからデータをインポートできます。 インポート アクションを処理する は connection により、外部データベースのデータソース メタデータが判別されます。 このサンプルでは、Snowflake リソースからデータをインポートします。 接続は Snowflake ソースを指します。 少し変更すると、接続は Azure SQL データベース ソースと Azure SQL データベース ソースを指すことができます。 外部データベース ソースからインポートされた資産 type は mltable です。
YAML ファイル <file-name>.yml を作成します。
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# Datastore: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: mltable
name: <name>
source:
type: database
query: <query>
connection: <connection>
path: <path>
次に、CLI で次のコマンドを実行します。
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import Database
from azure.ai.ml import MLClient
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config()
data_import = DataImport(
name="<name>",
source=Database(connection="<connection>", query="<query>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
注意
ここに示す例では、Snowflake データベースでのプロセスについて説明します。 ただし、このプロセスは、Azure SQL などの他の外部データベース形式もカバーしています。
Azure Machine Learning スタジオに移動します。
左側のナビゲーションの [資産] で [データ] を選択します。 次に、[データ インポート] タブを選択します。その後、次のスクリーンショットに示すように、[作成] を選択します。
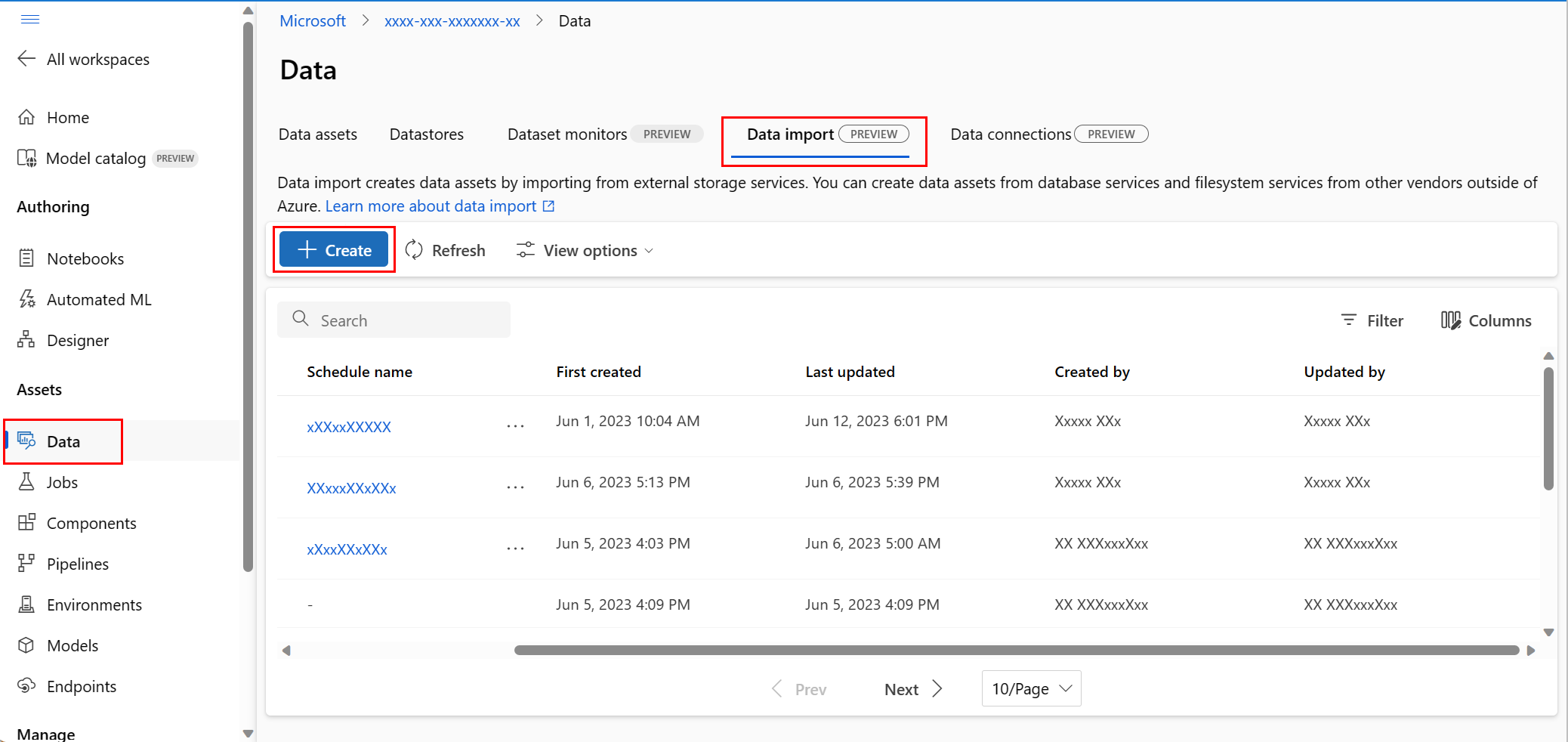
次のスクリーンショットに示すように、[データ ソース] 画面で [Snowflake] を選択し、[次へ] を選択します。

[データ型] 画面で、値を入力します。 [種類] 値の既定値は [Table (mltable)] (テーブル (mltable)) です。 その後、次のスクリーンショットに示すように、[次へ] を選択します。

次のスクリーンショットに示すように、[Create data import](データ インポートの作成) 画面で値を入力して [次へ] を選択します。

次のスクリーンショットに示すように、[Choose a datastore to output](出力するデータストアの選択) 画面で値を入力して [次へ] を選択します。 ワークスペース マネージド データストアは既定で選択されています。マネージド データストアを選択すると、システムによって自動的にパスが割り当てられます。 ワークスペースマネージド データストアを選択すると、[Auto delete setting](自動削除設定) ドロップダウンが表示されます。 既定では 30 日間のデータ削除時間枠が提供されます。この値を変更する方法については、インポートされたデータ資産を管理する方法に関する記事で説明しています。

注意
独自のデータストアを選択するには、[Other datastores](その他のデータストア) を選択します。 その場合、データ キャッシュの場所のパスを選択する必要があります。
スケジュールを追加できます。 次のスクリーンショットに示すように、[スケジュールの追加] を選択します。
![[スケジュールの追加] ボタンの選択を示すスクリーンショット。](media/how-to-import-data-assets/create-data-import-add-schedule.png?view=azureml-api-2)
新しいパネルが開き、[繰り返し] スケジュールまたは [Cron] スケジュールを定義できます。 次のスクリーンショットは、[繰り返し] スケジュールのパネルを示しています。
![[定期的なスケジュールの追加] ボタンの選択を示すスクリーンショット。](media/how-to-import-data-assets/create-data-import-recurrence-schedule.png?view=azureml-api-2)
- [名前]: ワークスペース内のスケジュールの一意識別子。
- [説明]: スケジュールの説明。
- [トリガー]: スケジュールの繰り返しパターン。次のプロパティが含まれます。
- [タイム ゾーン]: トリガー時間の計算は、このタイム ゾーンに基づいています。既定では、協定世界時 (UTC) に設定されています。
- [繰り返し] または [Cron 式]: 定期的なパターンを指定するために、[繰り返し] を選択します。 [繰り返し] では、繰り返し頻度を分、時間、日、週、月単位で指定できます。
- [開始]: スケジュールは、この日付に初めてアクティブになります。 既定では、このスケジュールの作成日です。
- [終了]: スケジュールは、この日付を過ぎると非アクティブになります。 既定では [なし] です。これは、スケジュールは手動で無効にするまでは常にアクティブであることを意味します。
- [タグ]: 選択したスケジュール タグ。
Note
Start は、スケジュールの開始日時とタイムゾーンを指定します。 start を省略した場合、開始時刻はスケジュールの作成時刻と等しくなります。 開始時刻が過去の場合、最初のジョブは、計算された次の実行時刻に実行されます。
次のスクリーンショットは、このプロセスの最後の画面を示しています。 選択内容を確認し、[作成] を選択します。 この画面やこのプロセスの他の画面では、[戻る] を選択して前の画面に移動することで、選択した値を変更できます。

次のスクリーンショットは、[Cron] スケジュールのパネルを示しています。
![[スケジュールの追加] ボタンの選択を示すスクリーンショット。](media/how-to-import-data-assets/create-data-import-cron-expression-schedule.png?view=azureml-api-2)
Note
Start は、スケジュールの開始日時とタイムゾーンを指定します。 start を省略した場合、開始時刻はスケジュールの作成時刻と等しくなります。 開始時刻が過去の場合、最初のジョブは、計算された次の実行時刻に実行されます。
次のスクリーンショットは、このプロセスの最後の画面を示しています。 選択内容を確認し、[作成] を選択します。 この画面やこのプロセスの他の画面では、[戻る] を選択して前の画面に移動することで、選択した値を変更できます。
外部ファイル システムからフォルダー データ資産としてデータをインポートする
注意
Amazon S3 データ リソースは、外部ファイル システム リソースとして機能できます。
データ インポート アクションを処理する connection により、外部データ ソースの各種側面が特定されます。 接続により、Amazon S3 バケットがターゲットとして定義されます。 接続には有効な path 値が必要です。 外部ファイル システム ソースからインポートされた資産値には uri_folder の type があります。
次のコード サンプルでは、Amazon S3 リソースからデータをインポートします。
YAML ファイル <file-name>.yml を作成します。
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: uri_folder
name: <name>
source:
type: file_system
path: <path_on_source>
connection: <connection>
path: <path>
次に、CLI で次のコマンドを実行します。
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import FileSystem
from azure.ai.ml import MLClient
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config()
data_import = DataImport(
name="<name>",
source=FileSystem(connection="<connection>", path="<path_on_source>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
Azure Machine Learning スタジオに移動します。
左側のナビゲーションの [資産] で [データ] を選択します。 次に、[Data Import](データ インポート) タブを選択します。その後、次のスクリーンショットに示すように、[作成] を選択します。
次のスクリーンショットに示すように、[データ ソース] 画面で [S3] を選択し、[次へ] を選択します。

[データ型] 画面で、値を入力します。 [種類] 値の既定値は [Folder (uri_folder)] (フォルダー (uri_folder)) です。 その後、次のスクリーンショットに示すように、[次へ] を選択します。

次のスクリーンショットに示すように、[Create data import](データ インポートの作成) 画面で値を入力して [次へ] を選択します。

次のスクリーンショットに示すように、[Choose a datastore to output](出力するデータストアの選択) 画面で値を入力して [次へ] を選択します。 ワークスペース マネージド データストアは既定で選択されています。マネージド データストアを選択すると、システムによって自動的にパスが割り当てられます。 ワークスペースマネージド データストアを選択すると、[Auto delete setting](自動削除設定) ドロップダウンが表示されます。 既定では 30 日間のデータ削除時間枠が提供されます。この値を変更する方法については、インポートされたデータ資産を管理する方法に関する記事で説明しています。

スケジュールを追加できます。 次のスクリーンショットに示すように、[スケジュールの追加] を選択します。
新しいパネルが開き、[繰り返し] スケジュールまたは [Cron] スケジュールを定義できます。 次のスクリーンショットは、[繰り返し] スケジュールのパネルを示しています。
- [名前]: ワークスペース内のスケジュールの一意識別子。
- [説明]: スケジュールの説明。
- [トリガー]: スケジュールの繰り返しパターン。次のプロパティが含まれます。
- [タイム ゾーン]: トリガー時間の計算は、このタイム ゾーンに基づいています。既定では、協定世界時 (UTC) に設定されています。
- [繰り返し] または [Cron 式]: 定期的なパターンを指定するために、[繰り返し] を選択します。 [繰り返し] では、繰り返し頻度を分、時間、日、週、月単位で指定できます。
- [開始]: スケジュールは、この日付に初めてアクティブになります。 既定では、このスケジュールの作成日です。
- [終了]: スケジュールは、この日付を過ぎると非アクティブになります。 既定では [なし] です。これは、スケジュールは手動で無効にするまでは常にアクティブであることを意味します。
- [タグ]: 選択したスケジュール タグ。
Note
Start は、スケジュールの開始日時とタイムゾーンを指定します。 start を省略した場合、開始時刻はスケジュールの作成時刻と等しくなります。 開始時刻が過去の場合、最初のジョブは、計算された次の実行時刻に実行されます。
次のスクリーンショットに示すように、このプロセスの最後の画面で選択内容を確認し、[作成] を選択します。 この画面やこのプロセスの他の画面では、選択した値を変更する場合は、[戻る] を選択して前の画面に移動します。
次のスクリーンショットは、このプロセスの最後の画面を示しています。 選択内容を確認し、[作成] を選択します。 この画面やこのプロセスの他の画面では、[戻る] を選択して前の画面に移動することで、選択した値を変更できます。

次のスクリーンショットは、[Cron] スケジュールのパネルを示しています。
Note
Start は、スケジュールの開始日時とタイムゾーンを指定します。 start を省略した場合、開始時刻はスケジュールの作成時刻と等しくなります。 開始時刻が過去の場合、最初のジョブは、計算された次の実行時刻に実行されます。
次のスクリーンショットは、このプロセスの最後の画面を示しています。 選択内容を確認し、[作成] を選択します。 この画面やこのプロセスの他の画面では、[戻る] を選択して前の画面に移動することで、選択した値を変更できます。
外部データ ソースのインポート状態を確認する
データ インポート アクションは非同期アクションです。 これには、長い時間がかかる場合があります。 CLI または SDK を使用してデータのインポート アクションを送信した後、Azure Machine Learning service が外部データ ソースに接続するまでに数分かかる場合があります。 その後、サービスによってデータのインポートが開始され、データのキャッシュと登録が処理されます。 データのインポートに必要な時間は、ソース データ セットのサイズによっても異なります。
次の例では、送信されたデータ インポート アクティビティの状態を返します。 このコマンドまたはメソッドでは、入力として "データ資産" 名を使用して、データ具体化の状態を確認します。
> az ml data list-materialization-status --name <name>
from azure.ai.ml.entities import DataImport
from azure.ai.ml import MLClient
ml_client = MLClient.from_config()
ml_client.data.show_materialization_status(name="<name>")
次のステップ





![[スケジュールの追加] ボタンの選択を示すスクリーンショット。](media/how-to-import-data-assets/create-data-import-add-schedule.png?view=azureml-api-2#lightbox)
![[定期的なスケジュールの追加] ボタンの選択を示すスクリーンショット。](media/how-to-import-data-assets/create-data-import-recurrence-schedule.png?view=azureml-api-2#lightbox)

![[スケジュールの追加] ボタンの選択を示すスクリーンショット。](media/how-to-import-data-assets/create-data-import-cron-expression-schedule.png?view=azureml-api-2#lightbox)




