適用対象: Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure Machine Learning では、モデルの監視を使用して、運用環境の機械学習モデルのパフォーマンスを継続的に追跡できます。 モデル監視は、監視信号の広い視野を提供します。 また、潜在的な問題に関するアラートも表示されます。 運用環境のモデルのシグナルとパフォーマンス メトリックを監視すると、モデル固有のリスクを重大に評価できます。 また、ビジネスに悪影響を及ぼす可能性のある盲点を特定することもできます。
この記事では、次のタスクを実行する方法について説明します。
- Azure Machine Learning オンライン エンドポイントにデプロイされるモデルに対して、すぐに使用できる高度な監視を設定する
- 運用環境のモデルのパフォーマンス メトリックを監視する
- Azure Machine Learning の外部にデプロイされているモデル、または Azure Machine Learning バッチ エンドポイントにデプロイされているモデルを監視する
- モデル監視で使用するカスタム シグナルとメトリックを設定する
- モニタリング結果を使用する
- Azure Machine Learning モデルモニタリングを Azure Event Grid と統合する
前提条件
Azure CLI と Azure CLI の
ml拡張機能(インストールおよび構成済み)。 詳細については、「 CLI のインストールと設定 (v2)」を参照してください。Bash シェルまたは互換性のあるシェル (Linux システム上のシェルや Linux 用 Windows サブシステムなど)。 この記事の Azure CLI の例では、この種類のシェルを使用することを前提としています。
Azure Machine Learning ワークスペース。 ワークスペースを作成する手順については、「 設定」を参照してください。
次の Azure ロールベースのアクセス制御 (Azure RBAC) ロールの少なくとも 1 つを持つユーザー アカウント。
- Azure Machine Learning ワークスペースの所有者ロール
- Azure Machine Learning ワークスペースの共同作成者ロール
-
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*アクセス許可を持つカスタム ロール
詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。
Azure Machine Learning マネージド オンライン エンドポイントまたは Kubernetes オンライン エンドポイントを監視する場合:
Azure Machine Learning オンライン エンドポイントにデプロイされるモデル。 マネージド オンライン エンドポイントと Kubernetes オンライン エンドポイントがサポートされています。 Azure Machine Learning オンライン エンドポイントにモデルをデプロイする手順については、オンライン エンドポイントを 使用した機械学習モデルのデプロイとスコア付けを参照してください。
モデルデプロイメントでデータ収集が有効化されています。 Azure Machine Learning オンライン エンドポイントのデプロイ手順の間に、データ収集を有効にできます。 詳細については、「 リアルタイム推論のためにデプロイされたモデルから実稼働データを収集する」を参照してください。
Azure Machine Learning バッチ エンドポイントにデプロイされた、または Azure Machine Learning の外部にデプロイされたモデルを監視する場合:
- 運用データを収集し、Azure Machine Learning データ資産として登録する手段
- モデル監視のために登録されたデータ資産を継続的に更新する手段
- (推奨)系列追跡のための Azure Machine Learning ワークスペースでのモデルの登録
サーバーレス Spark コンピューティング プールを構成する
モデル監視ジョブは、サーバーレス Spark コンピューティング プールで実行するようにスケジュールされます。 次の Azure Virtual Machines インスタンスの種類がサポートされています。
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standard_E64s_v3
この記事の手順に従うときに仮想マシン インスタンスの種類を指定するには、次の手順を実行します。
Azure CLI を使用してモニターを作成する場合は、YAML 構成ファイルを使用します。
create_monitor.compute.instance_type値を使用したい型に設定し、そのファイルに保存します。
すぐに使用できるモデル監視を設定する
Azure Machine Learning オンライン エンドポイントで運用環境にモデルをデプロイし、デプロイ時に データ収集 を有効にするシナリオを考えてみましょう。 この場合、Azure Machine Learning は運用環境の推論データを収集し、Azure Blob Storage に自動的に格納します。 Azure Machine Learning モデルの監視を使用して、この運用環境の推論データを継続的に監視できます。
Azure CLI、Python SDK、またはスタジオを使って、すぐに使用できるモデルモニタリングのセットアップを行うことができます。 すぐに使用できるモデルモニタリング構成には、次のモニタリング機能が用意されています。
- Azure Machine Learning は、Azure Machine Learning オンライン デプロイに関連付けられている運用推論データ資産を自動的に検出し、モデルの監視にデータ資産を使用します。
- 比較参照データ資産は、最近の過去の運用推論データ資産として設定されます。
- 監視設定には、次の組み込みの監視信号(データドリフト、予測ドリフト、データ品質)が自動的に含まれており、追跡されます。 監視シグナルごとに、Azure Machine Learning では次のものが使われます。
- 比較参照データ資産としての最近の過去の運用推論データ資産。
- メトリックとしきい値のスマートな既定値。
- 監視ジョブは、通常のスケジュールで実行するように構成されます。 そのジョブは監視信号を取得し、対応するしきい値と比較して各メトリックの結果を評価します。 既定では、しきい値を超えると、Azure Machine Learning はモニターを設定したユーザーにアラート 電子メールを送信します。
すぐに使用できるモデルモニタリングを設定するには、次の手順を実行します。
Azure CLI では、 az ml schedule を使用して監視ジョブをスケジュールします。
YAML ファイルに監視定義を作成します。 即時利用可能の定義のサンプルについては、次の YAML コードを参照してください。これは azureml-examples リポジトリでも入手できます。
この定義を使用する前に、環境に合わせて値を調整します。
endpoint_deployment_idの場合は、azureml:<endpoint-name>:<deployment-name>形式の値を使用します。# out-of-box-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: credit_default_model_monitoring display_name: Credit default model monitoring description: Credit default model monitoring setup with minimal configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: # specify a spark compute for monitoring job instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification # model task type: [classification, regression, question_answering] endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id alert_notification: # emails to get alerts emails: - abc@example.com - def@example.com次のコマンドを実行してモデルを作成します。
az ml schedule create -f ./out-of-box-monitoring.yaml
![[監視] ボタンと [追加] ボタンが強調表示され、いくつかのモニターが表示されている Azure Machine Learning Studio ワークスペースの [監視] ページのスクリーンショット。](media/how-to-monitor-models/add-model-monitoring.png?view=azureml-api-2#lightbox)
![名前、モデル、デプロイなどの設定が入力された、モデル監視の [基本設定] ページのスクリーンショット。](media/how-to-monitor-models/model-monitoring-basic-setup.png?view=azureml-api-2#lightbox)
高度なモデル監視を設定する
Azure Machine Learning には、継続的なモデル監視のための多くの機能が用意されています。 この機能の包括的な一覧については、「 モデル監視の機能」を参照してください。 多くの場合、高度な監視タスクをサポートするモデル監視を設定する必要があります。 次のセクションでは、高度な監視の例をいくつか示します。
- 広い視野のための複数の監視信号の使用
- 比較参照データ資産としての履歴モデル トレーニング データまたは検証データの使用
- N 個の最も重要な機能と個々の機能の監視
特徴量の重要度を構成する
特徴量の重要度は、モデルの出力に対する各入力特徴量の相対的な重要度を表します。 たとえば、標高よりもモデルの予測にとって温度の方が重要な場合があります。 機能の重要度をオンにすると、運用環境で誤差やデータ品質の問題が発生したくない機能を可視化できます。
データ ドリフトやデータ品質など、シグナルで特徴量の重要度を有効にするには、次を提供する必要があります。
-
reference_dataデータ資産としてのトレーニング データ資産。 -
reference_data.data_column_names.target_columnプロパティ。モデルの出力列または予測列の名前です。
機能の重要度を有効にすると、Azure Machine Learning Studio で監視する各機能の機能の重要度が表示されます。
Python SDK または Azure CLI を使用するときに alert_enabled プロパティを設定することで、シグナルごとにアラートをオンまたはオフにすることができます。
Azure CLI、Python SDK、またはスタジオを使用して、高度なモデル監視を設定できます。
YAML ファイルに監視定義を作成します。 高度な定義のサンプルについては、次の YAML コードを参照してください。これは 、azureml-examples リポジトリでも使用できます。
この定義を使用する前に、環境のニーズに合わせて次の設定やその他の設定を調整します。
-
endpoint_deployment_idの場合は、azureml:<endpoint-name>:<deployment-name>形式の値を使用します。 - 参照入力データ セクションの
pathには、azureml:<reference-data-asset-name>:<version>形式の値を使用します。 -
target_columnの場合は、DEFAULT_NEXT_MONTHなど、モデルが予測する値を含む出力列の名前を使用します。 -
featuresでは、高度なデータ品質信号で使用するSEX、EDUCATION、AGEなどの機能を一覧表示します。 - [
emails] で、通知に使用するメール アドレスを一覧表示します。
# advanced-model-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with advanced configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:credit-default:main monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 # use training data as comparison reference dataset type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH features: top_n_feature_importance: 10 # monitor drift for top 10 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_data_quality: type: data_quality # reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training features: # monitor data quality for 3 individual features only - SEX - EDUCATION alert_enabled: true metric_thresholds: numerical: null_value_rate: 0.05 categorical: out_of_bounds_rate: 0.03 feature_attribution_drift_signal: type: feature_attribution_drift # production_data: is not required input here # Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data # Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH alert_enabled: true metric_thresholds: normalized_discounted_cumulative_gain: 0.9 alert_notification: emails: - abc@example.com - def@example.com-
次のコマンドを実行してモデルを作成します。
az ml schedule create -f ./advanced-model-monitoring.yaml
![[データ資産の構成] ページのスクリーンショット。いくつかのデータ資産がテーブルに一覧表示され、[追加] ボタンが強調表示されています。](media/how-to-monitor-models/model-monitoring-advanced-configuration-data.png?view=azureml-api-2#lightbox)
![[監視シグナルの選択] ページのスクリーンショット。シグナルを追加、編集、削除するための 3 つの既定の監視信号とボタンが表示されます。](media/how-to-monitor-models/model-monitoring-monitoring-signals.png?view=azureml-api-2#lightbox)
![データ ドリフト信号の [シグナルの編集] ページのスクリーンショット。さまざまな設定を構成する方法を提供する 5 つの手順が表示されます。](media/how-to-monitor-models/model-monitoring-configure-signals.png?view=azureml-api-2#lightbox)
![[シグナルの編集] ページのスクリーンショット。[特徴量属性のドリフト] タブが強調表示され、4つの手順でさまざまな設定を設定する方法が示されています。](media/how-to-monitor-models/model-monitoring-configure-feature-attribution-drift.png?view=azureml-api-2#lightbox)
![[監視シグナルの選択] ページのスクリーンショット。3 つの既定のシグナルと、機能属性のドリフト信号が表示されています。](media/how-to-monitor-models/model-monitoring-configured-signals.png?view=azureml-api-2#lightbox)
![[監視の詳細の確認] ページのスクリーンショット。基本設定、3 つの構成済みデータ資産、および 4 つの構成済みシグナルが表示されます。](media/how-to-monitor-models/model-monitoring-advanced-configuration-review.png?view=azureml-api-2#lightbox)
モデル パフォーマンス監視を設定する
Azure Machine Learning モデルの監視を使用する場合は、パフォーマンス メトリックを計算することで、運用環境のモデルのパフォーマンスを追跡できます。 現在、次のモデル パフォーマンス メトリックがサポートされています。
- 分類モデルの場合:
- Precision
- 精度
- 再現率
- 回帰モデルの場合:
- 平均絶対誤差 (MAE)
- 平均二乗誤差 (MSE)
- 二乗平均平方根誤差 (RMSE)
モデル パフォーマンス監視の前提条件
各行の一意の ID を持つ実稼働モデル (モデルの予測) の出力データ。 Azure Machine Learning データ コレクターを使用して運用データを収集する場合は、推論要求ごとに関連付け ID が提供されます。 データ コレクターには、アプリケーションから独自の一意の ID をログに記録するオプションも用意されています。
注
Azure Machine Learning モデルのパフォーマンス監視では、 Azure Machine Learning データ コレクター を使用して、独自の列に一意の ID を記録することをお勧めします。
各行に一意の ID を持つ基準データ(実際の値)。 特定の行の一意の ID は、その特定の推論要求のモデル出力データの一意の ID と一致する必要があります。 この一意の ID は、グラウンド トゥルース データ資産とモデル出力データを結合するために使用されます。
グラウンド トゥルース データがないと、モデル パフォーマンスの監視を実行できません。 グラウンド・トゥルース・データはアプリケーション・レベルで検出されるため、使用可能になった時点で収集するのはユーザーの責任です。 また、データ資産をこのグラウンド トゥルース データが含まれている Azure Machine Learning に保持することも必要です。
(省略可能)モデルの出力データとグラウンドトゥルースデータがあらかじめ統合されている表形式データ資産。
データ コレクターを使用する場合のモデル パフォーマンス監視の要件
Azure Machine Learning では、次の条件を満たすと、関連付け ID が生成されます。
- Azure Machine Learning データ コレクターを使用して、運用環境の推論データを収集します。
- 各行に個別の列として独自の一意の ID を指定することはできません。
生成された関連付け ID は、ログに記録された JSON オブジェクトに含まれます。 ただし、データ コレクターは、互いに短い時間間隔で送信される 行をバッチ処理 します。 バッチ処理された行は、同じ JSON オブジェクト内に含まれます。 各オブジェクト内では、すべての行が同じ関連付け ID を持ちます。
JSON オブジェクト内の行を区別するために、Azure Machine Learning モデルのパフォーマンス監視では、インデックス作成を使用してオブジェクト内の行の順序が決定されます。 たとえば、バッチに 3 つの行が含まれており、関連付け ID が test場合、最初の行の ID は test_0、2 行目の ID は test_1、3 番目の行の ID は test_2 です。 グラウンド トゥルース データ資産の一意の ID と収集された運用推論モデルの出力データの ID を照合するには、各関連付け ID にインデックスを適切に適用します。 ログに記録された JSON オブジェクトに 1 行しかない場合は、 correlationid_0 を correlationid 値として使用します。
このインデックス作成を使用しないように、一意の ID を独自の列に記録することをお勧めします。 Azure Machine Learning データ コレクターがログに記録する pandas データ フレーム内にその列を配置します。 モデル監視構成では、この列の名前を指定して、モデルの出力データをグラウンド トゥルース データと結合できます。 両方のデータ資産の各行の ID が同じである限り、Azure Machine Learning モデルの監視ではモデルのパフォーマンス監視を実行できます。
モデルのパフォーマンスを監視するためのワークフローの例
モデルのパフォーマンス監視に関連する概念を理解するには、次のワークフロー例を検討してください。 これは、クレジット カードトランザクションが不正であるかどうかを予測するためにモデルをデプロイするシナリオに適用されます。
- データ コレクターを使用してモデルの運用推論データ (入力および出力データ) を収集するようにデプロイを構成します。 出力データを
is_fraudという列に格納します。 - 収集された推論データの行ごとに、一意の ID をログに記録します。 一意の ID は、アプリケーションから取得することも、ログに記録された JSON オブジェクトごとに Azure Machine Learning によって一意に生成される
correlationid値を使用することもできます。 - 実地検証用の (または実際の)
is_fraudデータが使用可能な場合、各行をモデルの出力データ内の対応する行に対して記録された一意のIDに一致させ、マッピングします。 - Azure Machine Learning にデータ資産を登録して、それを用いて、信頼できるデータ
is_fraudを収集し、維持するために利用します。 - 一意の ID 列を使用して、モデルの運用推論とグラウンド トゥルース データ資産を結合するモデル パフォーマンス監視シグナルを作成します。
- モデルのパフォーマンス メトリックを計算します。
モデル パフォーマンス監視の前提条件を満たしたら、次の手順を実行してモデルの監視を設定します。
YAML ファイルに監視定義を作成します。 次のサンプル仕様では、運用環境の推論データを使用したモデル監視を定義します。 この定義を使用する前に、環境のニーズに合わせて次の設定やその他の設定を調整します。
-
endpoint_deployment_idの場合は、azureml:<endpoint-name>:<deployment-name>形式の値を使用します。 - 入力データ セクションの
path値ごとに、azureml:<data-asset-name>:<version>形式の値を使用します。 -
prediction値には、モデルが予測する値を含む出力列の名前を使用します。 -
actual値には、モデルが予測しようとする実際の値を含む地表真理値列の名前を使用します。 -
correlation_id値には、出力データとグラウンド トゥルース データの結合に使用される列の名前を使用します。 - [
emails] で、通知に使用するメール アドレスを一覧表示します。
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.3" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com-
次のコマンドを実行してモデルを作成します。
az ml schedule create -f ./model-performance-monitoring.yaml
![[データ資産の構成] ページのスクリーンショット。2 つの構成済みデータ資産が表示され、[追加] ボタンが強調表示されます。](media/how-to-monitor-models/model-monitoring-configure-data-asset.png?view=azureml-api-2#lightbox)
![[データ資産の構成] ページのスクリーンショット。グラウンド トゥルース、入力、出力のデータ資産が表示されます。出力とグラウンド トゥルース資産が強調表示されています。](media/how-to-monitor-models/model-monitoring-added-ground-truth-data-asset.png?view=azureml-api-2#lightbox)
![[シグナルの編集] ページのスクリーンショット。[モデル パフォーマンス] タブが開き、さまざまな設定を構成する方法を提供する 3 つの手順が表示されます。](media/how-to-monitor-models/model-monitoring-configure-model-performance.png?view=azureml-api-2#lightbox)
![[監視シグナルの選択] ページのスクリーンショット。構成済みのモデル パフォーマンス信号が表示されます。](media/how-to-monitor-models/model-monitoring-configured-model-performance-signal.png?view=azureml-api-2#lightbox)
![[監視の詳細の確認] ページのスクリーンショット。基本設定、3 つの構成済みデータ資産、および 1 つの構成済みパフォーマンス 信号が表示されます。](media/how-to-monitor-models/model-monitoring-review-monitoring-details.png?view=azureml-api-2#lightbox)
運用データのモデル監視を設定する
また、Azure Machine Learning バッチ エンドポイントにデプロイするモデルや、Azure Machine Learning の外部にデプロイするモデルを監視することもできます。 デプロイがなく、運用データがある場合は、データを使用して継続的なモデル監視を実行できます。 これらのモデルを監視するには、次のことが可能である必要があります。
- 運用環境にデプロイされたモデルから運用環境の推論データを収集します。
- 運用環境の推論データを Azure Machine Learning データ資産として登録し、データの継続的な更新を保証します。
- データ コレクターを使用してデータを収集しない場合は、カスタム データ 前処理コンポーネントを指定し、Azure Machine Learning コンポーネントとして登録します。 このカスタム データ前処理コンポーネントがないと、Azure Machine Learning モデル監視システムは、時間枠をサポートする表形式にデータを処理できません。
カスタム前処理コンポーネントには、次の入力署名と出力シグネチャが必要です。
| 入力または出力 | シグネチャ名 | タイプ | 説明 | 値の例 |
|---|---|---|---|---|
| 入力 | data_window_start |
リテラル、文字列 | ISO8601形式のデータ ウィンドウの開始時刻 | 2023-05-01T04:31:57.012Z |
| 入力 | data_window_end |
リテラル、文字列 | データ ウィンドウの終了時刻 (ISO8601形式) | 2023-05-01T04:31:57.012Z |
| 入力 | input_data |
uri_folder | 収集された運用推論データ。Azure Machine Learning データ資産として登録されます。 | azureml:myproduction_inference_data:1 |
| 出力 | preprocessed_data |
mltable | 参照データ スキーマのサブセットと一致する表形式のデータ資産 |
カスタム データ前処理コンポーネントの例については、azuremml-examples の GitHub リポジトリにある custom_preprocessing を参照してください。
Azure Machine Learning コンポーネントを登録する手順については、「 ワークスペースにコンポーネントを登録する」を参照してください。
運用データと前処理コンポーネントを登録したら、モデル監視を設定できます。
次のような監視定義 YAML ファイルを作成します。 この定義を使用する前に、環境のニーズに合わせて次の設定やその他の設定を調整します。
-
endpoint_deployment_idの場合は、azureml:<endpoint-name>:<deployment-name>形式の値を使用します。 -
pre_processing_componentの場合は、azureml:<component-name>:<component-version>形式の値を使用します。1.0.0ではなく、1などの正確なバージョンを指定します。 -
pathごとに、azureml:<data-asset-name>:<version>形式の値を使用します。 -
target_column値には、モデルが予測する値を含む出力列の名前を使用します。 - [
emails] で、通知に使用するメール アドレスを一覧表示します。
# model-monitoring-with-collected-data.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with your own production data trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_inputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_training_data:1 # use training data as comparison baseline type: mltable data_context: training data_column_names: target_column: is_fraud features: top_n_feature_importance: 20 # monitor drift for top 20 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_prediction_drift: # monitoring signal name, any user defined name works type: prediction_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_outputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset type: mltable data_context: validation alert_enabled: true metric_thresholds: categorical: pearsons_chi_squared_test: 0.02 alert_notification: emails: - abc@example.com - def@example.com-
次のコマンドを実行してモデルを作成します。
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
カスタム シグナルとメトリックを使用してモデル監視を設定する
Azure Machine Learning モデルの監視を使用する場合は、カスタム シグナルを定義し、任意のメトリックを実装してモデルを監視できます。 カスタム シグナルを Azure Machine Learning コンポーネントとして登録できます。 モデル監視ジョブは、指定されたスケジュールで実行されると、データドリフト、予測ドリフト、および事前構築済み信号の場合と同様に、カスタムシグナル内で定義されたメトリックを計算します。
モデルモニタリングに使用するカスタム シグナルを設定するには、まずカスタム シグナルを定義し、Azure Machine Learning コンポーネントとして登録する必要があります。 Azure Machine Learning コンポーネントには、次の入力署名と出力署名が必要です。
コンポーネント入力シグネチャ
コンポーネント入力データ フレームには、次の項目が含まれている必要があります。
- 前処理コンポーネントから処理されたデータを格納する
mltable構造体。 - カスタム シグナル コンポーネントの一部として実装されたメトリックを表す任意の数のリテラル。 たとえば、
std_deviationメトリックを実装する場合は、std_deviation_thresholdの入力が必要です。 一般に、メトリックごとに<metric-name>_thresholdという名前の入力が 1 つ必要です。
| シグネチャ名 | タイプ | 説明 | 値の例 |
|---|---|---|---|
production_data |
mltable | 参照データ スキーマのサブセットと一致する表形式のデータ資産 | |
std_deviation_threshold |
リテラル、文字列 | 実装されたメトリックのそれぞれのしきい値 | 2 |
コンポーネント出力シグネチャ
コンポーネント出力ポートには、次の署名が必要です。
| シグネチャ名 | タイプ | 説明 |
|---|---|---|
signal_metrics |
mltable | 計算されたメトリックを含む mltable 構造体。 この署名のスキーマについては、次のセクション 「スキーマのsignal_metrics」を参照してください。 |
signal_metrics シグナルメトリクス スキーマ
コンポーネント出力データ フレームには、 group、 metric_name、 metric_value、 threshold_valueの 4 つの列が含まれている必要があります。
| シグネチャ名 | タイプ | 説明 | 値の例 |
|---|---|---|---|
group |
リテラル、文字列 | カスタム メトリックに適用する最上位の論理グループ | TRANSACTIONAMOUNT |
metric_name |
リテラル、文字列 | カスタム メトリックの名前 | 標準偏差 |
metric_value |
数値 | カスタム メトリックの値 | 44,896.082 |
threshold_value |
数値 | カスタム メトリックのしきい値 | 2 |
次の表は、 std_deviation メトリックを計算するカスタムシグナルコンポーネントからの出力例を示しています。
| グループ | metric_value | metric_name | 閾値 |
|---|---|---|---|
| TRANSACTIONAMOUNT | 44,896.082 | 標準偏差 | 2 |
| LOCALHOUR | 3.983 | 標準偏差 | 2 |
| TRANSACTIONAMOUNTUSD | 54,004.902 | 標準偏差 | 2 |
| DIGITALITEMCOUNT | 7.238 | 標準偏差 | 2 |
| PHYSICALITEMCOUNT | 5.509 | 標準偏差 | 2 |
カスタムシグナルコンポーネント定義とメトリック計算コードの例については、 azureml-examples リポジトリのcustom_signalを参照してください。
Azure Machine Learning コンポーネントを登録する手順については、「 ワークスペースにコンポーネントを登録する」を参照してください。
Azure Machine Learning でカスタムシグナルコンポーネントを作成して登録したら、次の手順を実行してモデル監視を設定します。
次のような監視定義を YAML ファイルに作成します。 この定義を使用する前に、環境のニーズに合わせて次の設定やその他の設定を調整します。
-
component_idの場合は、azureml:<custom-signal-name>:1.0.0形式の値を使用します。 - 入力データ セクションの
pathには、azureml:<production-data-asset-name>:<version>形式の値を使用します。 -
pre_processing_componentの場合:-
データ コレクターを使用してデータを収集する場合は、
pre_processing_componentプロパティを省略できます。 - データ コレクターを使用せず、コンポーネントを使用して運用データを前処理する場合は、
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>形式の値を使用します。
-
データ コレクターを使用してデータを収集する場合は、
- [
emails] で、通知に使用するメール アドレスを一覧表示します。
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com-
次のコマンドを実行してモデルを作成します。
az ml schedule create -f ./custom-monitoring.yaml
モニタリング結果を使用する
モデル モニターを構成し、最初の実行が完了したら、Azure Machine Learning Studio で結果を表示できます。
スタジオの [ 管理] で、[監視] を選択 します。 [監視] ページで、モデル モニターの名前を選択して、その概要ページを表示します。 このページには、監視モデル、エンドポイント、デプロイが表示されます。 また、構成された信号に関する詳細情報も提供します。 次の図は、データ ドリフトとデータ品質信号を含む監視の概要ページを示しています。
![[監視] が強調表示されている、モデルの監視ページのスクリーンショット。失敗率と合格率に関する情報は、2 つの信号に対して表示されます。](media/how-to-monitor-models/monitoring-dashboard.png?view=azureml-api-2)
概要ページの [通知 ] セクションを確認します。 このセクションでは、それぞれのメトリックに対して構成されたしきい値に違反する各シグナルの機能を確認できます。
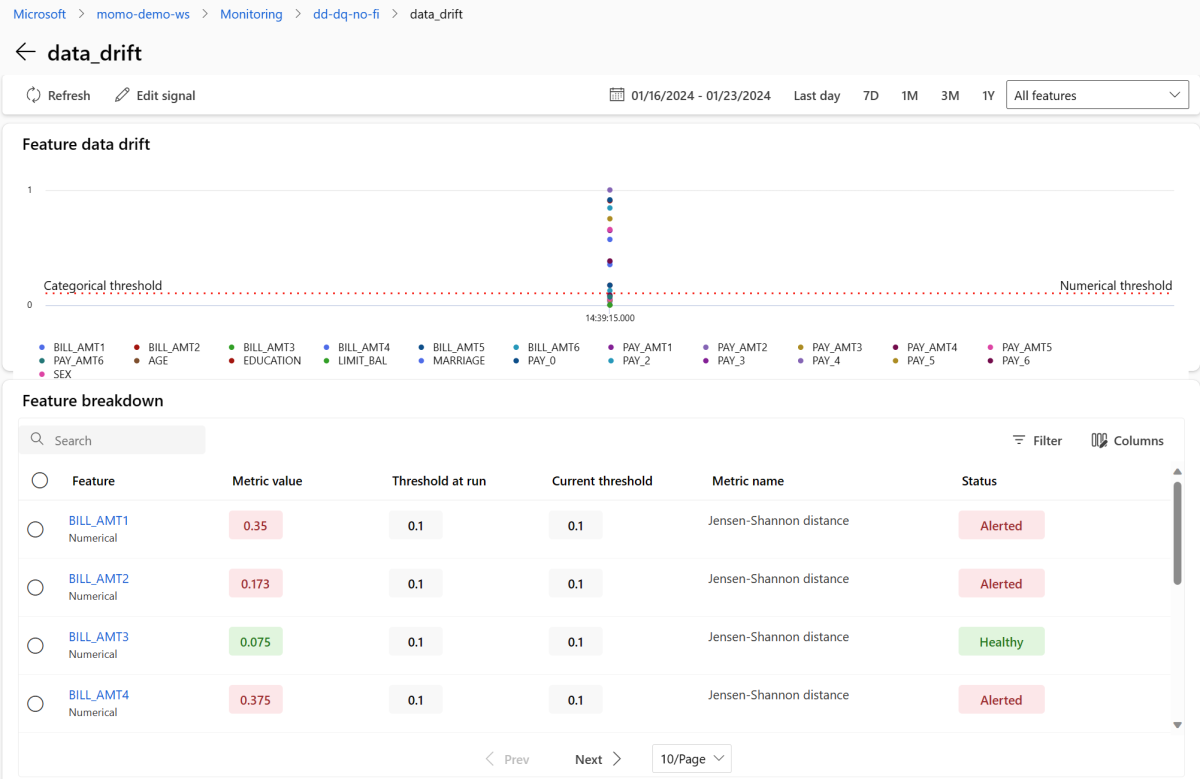
[ 信号 ]セクションで data_drift を選択すると、データドリフト信号に関する詳細情報が表示されます。 詳細ページでは、監視構成に含まれる各数値およびカテゴリの特徴のデータ ドリフト メトリック値を確認できます。 モニターに複数の実行がある場合は、各機能の傾向線が表示されます。
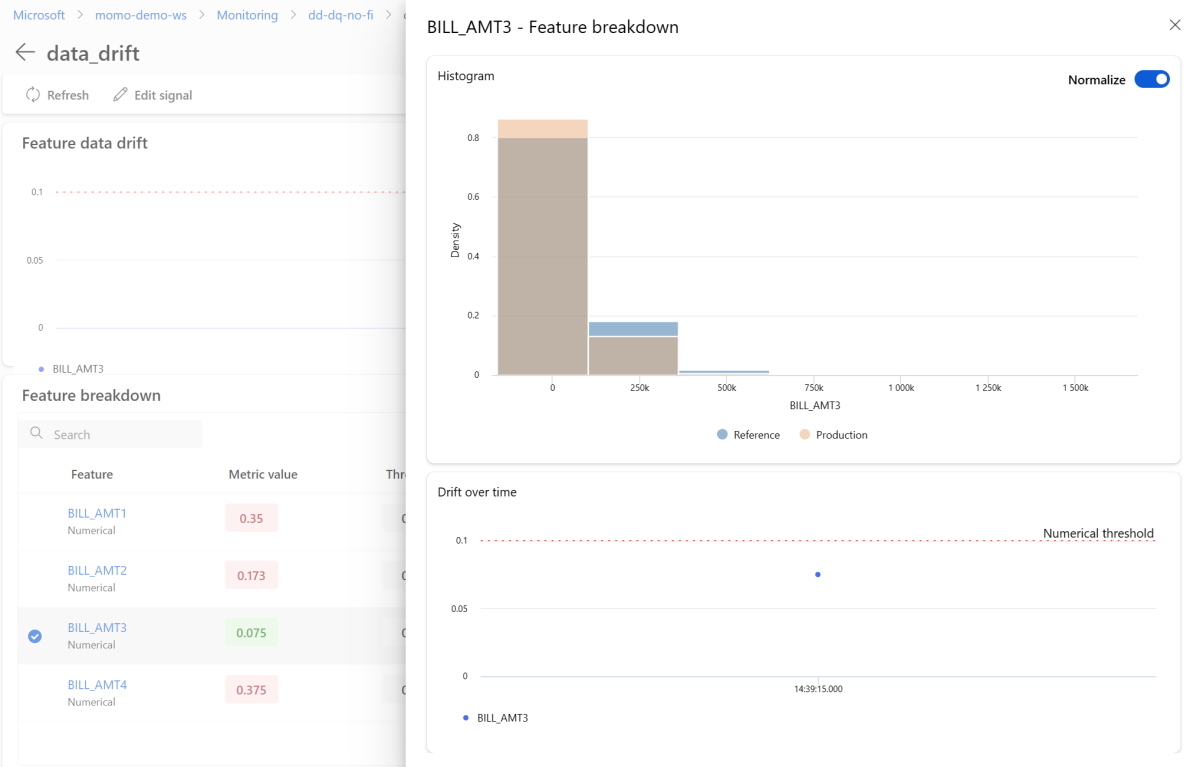
詳細ページで、個々の機能の名前を選択します。 参照分布と比較した運用ディストリビューションを示す詳細ビューが開きます。 このビューを使用して、機能の時間の経過に伴うドリフトを追跡することもできます。
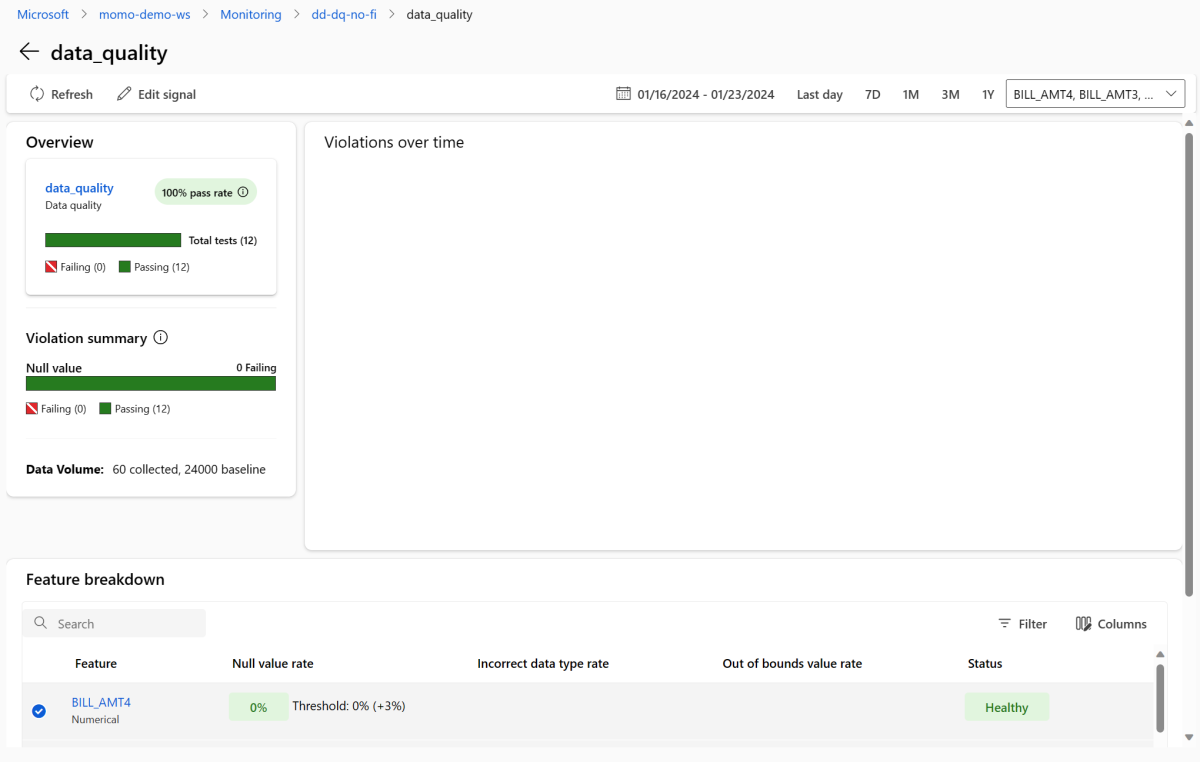
監視の概要ページに戻ります。 [ シグナル ] セクションで 、data_quality を選択して、このシグナルに関する詳細情報を表示します。 このページでは、監視する各機能の null 値率、範囲外レート、データ型エラー率を確認できます。
![[監視] が強調表示されている、モデルの監視ページのスクリーンショット。失敗率と合格率に関する情報は、2 つの信号に対して表示されます。](media/how-to-monitor-models/monitoring-dashboard.png?view=azureml-api-2#lightbox)



モデルモニタリングは継続的なプロセスです。 Azure Machine Learning モデルの監視を使用する場合は、複数の監視シグナルを構成して、運用環境のモデルのパフォーマンスを幅広く確認できます。
Azure Machine Learning モデルの監視を Event Grid と統合する
Event Grid を使用する場合は、Azure Machine Learning モデルの監視によって生成されるイベントを構成して、アプリケーション、プロセス、CI/CD ワークフローをトリガーできます。 Azure Event Hubs、Azure Functions、Azure Logic Apps など、さまざまなイベント ハンドラーを介してイベントを使用できます。 モニターがドリフトを検出すると、機械学習パイプラインを実行してモデルを再トレーニングして再デプロイするなど、プログラムによってアクションを実行できます。
Azure Machine Learning モデルの監視を Event Grid と統合するには、次のセクションの手順を実行します。
システム トピックを作成する
監視に使用する Event Grid システム トピックがない場合は、作成します。 手順については、 Azure portal での Event Grid システム トピックの作成、表示、管理に関するページを参照してください。
イベント サブスクリプションの作成
Azure portal で、Azure Machine Learning ワークスペースに移動します。
[イベント] を選択し、次に [イベント サブスクリプション] を選択します。
![Azure Machine Learning ワークスペースの [イベント] ページを示すスクリーンショット。イベントとイベント サブスクリプションが強調表示されています。](media/how-to-monitor-models/add-event-subscription.png?view=azureml-api-2)
[ 名前] の横に、 MonitoringEvent などのイベント サブスクリプションの名前を入力します。
[ イベントの種類] で、[ 実行の状態が変更されました] のみを選択します。
警告
イベントの種類に対して [実行の状態が変更されました ] のみを選択します。 検出されたデータセットドリフトは選択しないでください。それはAzure Machine Learning モデルの監視ではなく、データ ドリフト v1 に適用されます。
[ フィルター ] タブを選択します。[ 詳細フィルター] で [ 新しいフィルターの追加] を選択し、次の値を入力します。
- キーの下にdata.RunTags.azureml_modelmonitor_threshold_breachedを入力します。
- [ 演算子] で、[ 文字列を含む] を選択します。
- [ 値] で、 1 つ以上の機能がメトリックのしきい値に違反したため、入力に失敗しました。
![Azure portal の [イベントの説明の作成] ページのスクリーンショット。[フィルター] タブと[キー]、[演算子]、[値] の下の値が強調表示されています。](media/how-to-monitor-models/add-advanced-filter.png?view=azureml-api-2)
このフィルターを使用すると、Azure Machine Learning ワークスペース内のモニターの実行状態が変わると、イベントが生成されます。 実行状態は、完了から失敗、または失敗から完了に変わる可能性があります。
監視レベルでフィルター処理するには、もう一度 [新しいフィルターの追加] を選択し、次の値を入力します。
- キーの下にdata.RunTags.azureml_modelmonitor_threshold_breachedを入力します。
- [ 演算子] で、[ 文字列を含む] を選択します。
-
[値] に、credit_card_fraud_monitor_data_drift などの、イベントをフィルター処理するモニター シグナルの名前を入力します。 入力する名前は、監視シグナルの名前と一致している必要があります。 フィルター処理で使用するシグナルには、モニター名とシグナルの説明を含む
<monitor-name>_<signal-description>形式の名前が必要です。
[ 基本 ] タブを選択します。イベント ハンドラーとして機能するエンドポイント (Event Hubs など) を構成します。
[作成] を選び、イベント サブスクリプションを作成します。
![Azure portal の [イベントの説明の作成] ページのスクリーンショット。[フィルター] タブと[キー]、[演算子]、[値] の下の値が強調表示されています。](media/how-to-monitor-models/add-advanced-filter.png?view=azureml-api-2#lightbox)
イベントの表示
イベントをキャプチャした後は、イベント ハンドラーのエンドポイント ページでイベントを表示できます。

Azure Monitor メトリック タブでイベントを表示することもできます。
![[メトリックの監視] ページのスクリーンショット。折れ線グラフには、過去 1 時間の合計 3 つのイベントが表示されます。](media/how-to-monitor-models/events-in-azure-monitor-metrics-tab.png?view=azureml-api-2#lightbox)