責任ある AI (RAI) ダッシュボードには、機械学習モデルの分析やデータ ドリブンのビジネスの意思決定に役立つ、視覚化と機能が含まれています。 RAI ダッシュボードを表示および構成する手順は、どのシナリオでも似ていますが、一部の機能は画像シナリオに固有です。 この記事では、RAI 画像ダッシュボードのコンポーネントと機能にアクセスして構成する方法について説明します。
責任ある AI 画像ダッシュボードは、Azure Machine Learning に登録されたコンピューター ビジョン モデルにリンクされます。 Responsible AI Vision Insights コンポーネントは、画像分類と物体検出のシナリオをサポートします。
重要
責任ある AI 画像ダッシュボードは、現在パブリック プレビュー段階です。 このプレビュー版はサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
前提条件
Azure サブスクリプションと Azure Machine Learning ワークスペース。
実行中の接続済みコンピューティング リソースを使用して作成された、責任ある AI 画像ダッシュボードを持つ登録済みの機械学習モデル。
責任ある AI 画像ダッシュボードは、次を使用して作成できます。
- Azure Machine Learning スタジオ UI
- パイプライン ジョブを介した YAML と Python
- RAI ダッシュボードを使用した画像分類シナリオや RAI ダッシュボードを使用した物体検出シナリオなど、構成済みのサンプル Jupyter Notebook。
RAI 画像ダッシュボードの一部の機能では、動的、オン ザ フライ、リアルタイムの計算が必要です。 画像シナリオの完全な機能を実現するには、実行中のコンピューティング リソースをダッシュボードに接続する必要があります。
- 物体検出の場合、IOU (Intersection over Union) しきい値の設定は既定では無効になっており、コンピューティング リソースが接続された場合にのみ有効になります。
- Distributed Parallel Version 2 (DPv2) ジョブを送信する際、コンピューティング リソースを接続すると、オンデマンドで説明を読み込む代わりに、すべてのモデルの説明を事前計算できます。
詳細については、「責任ある AI ダッシュボードのすべての機能を有効にする」を参照してください。
Machine Learning スタジオで責任ある AI 画像ダッシュボードを開くには、[モデル] 一覧で登録済みのモデルを選択し、モデル ページの上部にある [責任ある AI] を選択し、一覧から責任ある AI 画像ダッシュボードの名前を選択します。
コーホート
RAI 画像ダッシュボードでは、データ コーホートを選択または作成できます。これは、フィルターを手動で追加するか、選択したデータを保存することによって作成されるデータのサブセットです。 コーホートは、表示、作成、編集、複製、削除できます。
既定のダッシュボード ビューには、すべてのデータを表すグローバル コーホートが表示されます。 ダッシュボードの上部にある [コーホートの切り替え] を選択して別のコーホートを選択したり、[新しいコーホート] を選択して新しいコーホートを作成できます。 [設定] アイコンを選択し、サイド パネルを開いてすべてのコーホートの名前と詳細を一覧表示したり、切り替えたり、新しいコーホートを作成したりすることもできます。

RAI 画像ダッシュボードのコンポーネント
次のセクションでは、責任ある AI 画像ダッシュボードのコンポーネントについて説明します。 使用可能なコンポーネントと機能は、画像分類と物体検出のシナリオによって異なります。
画像分類モデルとマルチラベル分類モデルの場合、責任ある AI 画像ダッシュボードには、エラー分析、Vision データ エクスプローラー、モデルの概要、データ分析のコンポーネントが含まれます。
エラー分析
エラー分析ツールは、画像分類タスクとマルチ分類タスクで使用できます。 これらのツールを使用すると、公平性エラーの検出が高速化され、データセット内の過小/過剰表現が特定されます。
表形式データを渡す代わりに、メタデータを追加の列として mltable データセットに含めることで、指定された画像メタデータの特徴に対してエラー分析を実行できます。 エラー分析の詳細については、「機械学習モデルでエラーを評価する」を参照してください。

Vision データ エクスプローラー
Vision データ エクスプローラー コンポーネントには、データセットに関するさまざまな視点を提供するいくつかのビューがあります。 コンポーネントの上部にあるタブのいずれかを選択することで、画像エクスプローラー ビュー、テーブル ビュー、またはクラス ビューのいずれかを選択できます。
画像エクスプローラー ビュー
画像エクスプローラー ビューには、モデル予測の画像インスタンスが表示されます。正しいラベルが付けられた予測と誤ったラベルが付けられた予測別に自動的に分類されます。 このビューは、データ内の大まかなエラー パターンをすばやく特定し、より詳細に調べるインスタンスを選択するのに役立ちます。
- [探索するデータセットのコーホートを選択] を使用すると、表示するユーザー定義のデータセット コーホートを選択または検索できます。
- [サムネイル サイズの設定] スライダーは、ページ上の画像カードのサイズを調整します。

画像分類と複数分類の場合、誤った予測とは、予測クラス ラベルがグランド トゥルースと異なる画像を意味します。 各画像カードには、画像、予測されたクラス ラベル、グラウンド トゥルース クラス ラベルが表示されます。

画像カードを選択すると、ポップアップが開き、モデル予測分析をサポートする次の情報が表示されます。
- 選択したインスタンス: 画像の予測されたグランド トゥルース結果を表示します。
- 説明: SHAP (Shapley Additive explanations) 機能の属性の視覚化を表示して、コンピューター ビジョン タスクの実行につながるモデル動作に関する分析情報を取得します。
- 情報: 選択したインスタンスの画像メタデータ値を表示します。




テーブル ビュー
テーブル ビューには、データセットが表示されます。行はデータセット内の各画像インスタンスを表し、列は対応するインデックス、グランド トゥルース クラス ラベル、予測クラス ラベル、メタデータ特徴を表します。

- [探索するデータセットのコーホートを選択] を使用すると、表示するユーザー定義のデータセット コーホートを選択または検索できます。
- [コーホートを保存する] を使用すると、手動で画像を選択して作成した新しいデータセット コーホートを保存できます。
画像行にマウス ポインターを合わせ、チェック ボックスをオンにして、新しいコーホートに画像を含めます。 インデックス、メタデータ値、分類結果別にデータセットをフィルター処理できます。 フィルターをさらに追加し、フィルター処理の結果として得られたデータを新しいコーホート名で保存し、自動的に切り替えて新しいコーホートを表示することができます。


クラス ビュー
クラス ビューは、モデル予測をクラス ラベル別に分類します。 クラスごとのエラー パターンを特定して、公平性に関する懸念を診断し、データセット内の過少および過大表現を評価できます。
- [探索するデータセットのコーホートを選択] で、表示するユーザー定義のデータセット コーホートを選択または検索できます。
- [サムネイル サイズの設定] スライダーは、ページ上の画像カードのサイズを調整します。
- [行] は、ビューをスクロールする前に表示する画像行の数を選択します。
画像はラベルごとに表示され、データセット内の各ラベルの分布が表示されます。 10/120 件の例というクラス ラベルは、データセット内の 120 個の画像のうち、そのクラスの画像が 10 個あることを意味します。 成功インスタンスには緑色のアンダースコア、エラー インスタンスには赤いアウトライン アンダースコアが付きます。
- [ラベルの種類の選択] で、予測ラベルまたはグランド トゥルース ラベル別に画像を選択して表示します。
- [表示するラベルの選択] で、1 つ以上のクラス ラベルを選択して、それらのラベルを含む画像インスタンスを表示します。
![マルチクラス分類の [クラス ビュー] タブのビジョン データ エクスプローラーを示すスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/class-view-multiclass.png?view=azureml-api-2#lightbox)
![物体検出の [クラス ビュー] タブのビジョン データ エクスプローラーを示すスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/class-view-object.png?view=azureml-api-2#lightbox)
モデルの概要
[モデルの概要] コンポーネントは、コンピューター ビジョン モデルを評価するための包括的なパフォーマンス メトリックのセットと、データセット コーホートの主要なパフォーマンス不均衡メトリックを提供します。 コンポーネントの上部にあるタブを選択して、[データセットのコーホート] または [特徴コーホート] ビューのいずれかを選択できます。
[データセットのコーホート] ビュー
[データセットのコーホート] ビューには、グローバル コーホート全体で選択されたメトリックと、ダッシュボード内のすべてのユーザー定義コーホートが表示されます。
![[データセットのコーホート] ビューのスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/dataset-cohorts-top.png?view=azureml-api-2#lightbox)
ドロップダウン リストから [メトリック] を選択するか、[メトリックの選択に関するヘルプ] を選択して、説明や推奨事項を確認したり、表示するメトリックを選択できるサイドバー画面を開きます。 表示するメトリックを調整するには、複数選択ドロップダウン リストを使用してパフォーマンス メトリックを選択および選択解除します。
表示されたデータについて、[ヒートマップの表示] を選択することもできます。
注
パフォーマンス メトリックは、初期状態時およびメトリック計算の読み込み中は N/A と表示されます。
![[データセット コーホート] ペインの [モデルの概要] のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/dataset-cohorts.png?view=azureml-api-2#lightbox)

[特徴コーホート] ビュー
[特徴コーホート] ビューでは、ユーザーが指定した機密性の高い特徴と高くない特徴の間でモデルのパフォーマンスを比較することで、モデルを調査できます。 たとえば、性別、人種、収入などのさまざまな画像メタデータ値でコーホートのパフォーマンスを比較します。
このビューには、差異や比率のパリティなどの公平性メトリックも表示されます。 特徴コーホートの詳細については、「特徴コーホート」を参照してください。


視覚化
[モデルの概要] コンポーネントの下半分では、[メトリックの視覚化] またはデータの [混同行列] ビューのいずれかを選択できます。
[メトリックの視覚化] には、選択したデータセット コーホートで集計されたパフォーマンス メトリックを比較する棒グラフが表示されます。
- [コーホートの選択] を選択すると、適用するデータセットと特徴コーホートを選択できるサイドバーが開きます。
- [メトリックの選択] を選択すると、表示するメトリックを選択できるサイドバーが開きます。
![[モデルの概要] コンポーネントにある、分類タスクの [メトリックの視覚化] のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/visualizations-class.png?view=azureml-api-2)
[混同行列] には、選択したデータセット コーホートとクラスで選択されたモデル パフォーマンス メトリックが表示されます。
- [データセット コーホートの選択] を選択すると、表示するデータセット コーホートをドロップダウン リストから選択できます。
- [クラスの選択] を選択すると、表示するクラスをドロップダウン リストから選択できます。
![[モデルの概要] コンポーネントにある、分類タスクの [混同行列] のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/confusion-matrix.png?view=azureml-api-2)
![[モデルの概要] コンポーネントにある、分類タスクの [メトリックの視覚化] のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/visualizations-class.png?view=azureml-api-2#lightbox)
![[モデルの概要] コンポーネントにある、分類タスクの [混同行列] のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/confusion-matrix.png?view=azureml-api-2#lightbox)
![[モデルの概要] コンポーネントにある、物体検出タスクの [メトリックの視覚化] のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/visualizations-object.png?view=azureml-api-2#lightbox)
データ分析
[データ分析] コンポーネントは、データセット コーホートを作成して、予測された結果、データセットの特徴、エラー グループなどのフィルターに基づいてデータセットの統計情報を分析します。 コンポーネントの上部にあるタブを選択して、テーブル ビューまたはグラフ ビューのいずれかを選択できます。
テーブル ビュー
![画像分類モデルの [テーブル ビュー] タブにあるデータ分析のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/data-analysis-table-class.png?view=azureml-api-2#lightbox)
![物体検出モデルの [テーブル ビュー] タブにあるデータ分析のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/data-analysis-table-object.png?view=azureml-api-2#lightbox)
グラフ ビュー
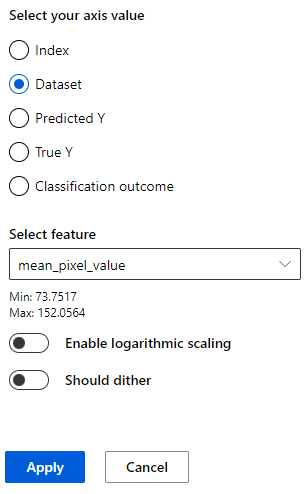
グラフ ビューの X 軸と Y 軸は、水平方向と垂直方向にプロットされている値を示します。
グラフ ビューでは、カスタマイズした集計とローカル データの探索のどちらかを選択できます。 [グラフの種類] で、値を集計するか、個々のデータポイントを表示するかを選択できます。
[集計プロット] では、ビンまたはカテゴリのデータが X 軸に沿って表示されます。
![物体検出モデルの [グラフ ビュー] タブにある、集計データ分析のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/data-analysis-chart-aggregate-object.png?view=azureml-api-2)
[個々のデータ ポイント] には、非集計データのビューが表示されます。
![画像分類モデルの [グラフ ビュー] タブにある、非集計データ分析のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/data-analysis-chart-scatter-class.png?view=azureml-api-2)
![物体検出モデルの [グラフ ビュー] タブにある、集計データ分析のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/data-analysis-chart-aggregate-object.png?view=azureml-api-2#lightbox)
![画像分類モデルの [グラフ ビュー] タブにある、非集計データ分析のスクリーンショット。](media/how-to-responsible-ai-dashboard-vision-insights/data-analysis-chart-scatter-class.png?view=azureml-api-2#lightbox)
どちらのグラフでも、軸ラベルを選択するとサイドバー ペインが開き、特徴を選択して軸を構成できます。 [個々のデータポイント] グラフの場合、[色の値] でラベルを選択すると、サイドバー ペインが開き、データポイントのグループ化に使用する値を選択できます。
サイドバー ペインでは、グラフと値の種類に応じて、[データにビン分割を適用する]、[ビンの数]、[対数スケールを有効にする] などのオプションを構成できます。 [ディザーが必要] は、散布図の点の重なりを避けるために、データに任意のノイズを追加します。
モデルの解釈可能性
AutoML 画像分類モデルでは、次の 4 種類の説明可能性方法がサポートされています。
説明は、予測クラスについてのみ生成されます。 マルチラベル分類の場合、説明を生成するクラスを選択するには、信頼度スコアのしきい値が必要です。 パラメーター名については、パラメーターの一覧を参照してください。
これら 4 つの方法は AutoML 画像分類のみに固有であり、物体検出やインスタンスのセグメント化などの他のタスクの種類では機能しません。 AutoML 以外の画像分類モデルでは、モデルの解釈可能性に SHAP ビジョンを使用できます。 AutoML と AutoML 以外のどちらの物体検出でも、D-RISE を使用して、モデル予測のビジュアル説明を生成できます。
4 つの説明可能性方法の詳細については、「予測の説明を生成する」を参照してください。 ビジョン モデルの解釈可能性手法と、モデル動作のビジュアル説明を解釈する方法の詳細については、「モデルの解釈可能性」を参照してください。
関連するコンテンツ
- 責任ある AI ダッシュボードの背後にある概念と手法の詳細について確認します。
- YAML または Python を使用して責任ある AI ダッシュボードを生成するには、サンプルの YAML と Python のノートブックをご覧ください。
- 責任ある AI 画像ダッシュボードを使用して画像データとモデルをデバッグし、より良い意思決定を行うための情報を提供する方法について詳しくは、こちらの技術コミュニティのブログ投稿を参照してください。
- 責任ある AI ダッシュボードが Clearsight でどのように使用されたかについては、実際の顧客事例を参照してください。