適用対象: Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
バッチ エンドポイントを使用すると、大量のデータに対して推論を実行するモデルをデプロイできます。 これらのエンドポイントを使用すると、バッチ スコアリング用のホスティング モデルが簡略化されるため、インフラストラクチャではなく機械学習に集中できます。
バッチ エンドポイントを使用して、次の場合にモデルをデプロイします。
- 推論の実行に時間がかかるコストの高いモデルを使用します。
- 複数のファイルに分散された大量のデータに対して推論を実行します。
- 待機時間を短くする必要はありません。
- 並列化を利用します。
この記事では、バッチ エンドポイントを使用して、従来の MNIST (米国標準技術研究所) の数字認識の問題を解決する機械学習モデルをデプロイする方法について説明します。 デプロイされたモデルは、画像ファイルなどの大量のデータに対してバッチ推論を実行します。 プロセスは、Torch を使用して構築されたモデルのバッチ デプロイの作成から始まります。 このデプロイは、エンドポイントの既定値になります。 その後、TensorFlow (Keras) で構築されたモデルの 2 つ目のデプロイを作成 し、2 つ目のデプロイをテストし、エンドポイントの既定のデプロイとして設定します。
前提条件
この記事の手順を実行する前に、次の前提条件が満たされていることをご確認ください。
Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
Azure Machine Learning ワークスペース。 準備できていない場合は、ワークスペースの管理方法に関する記事の手順を使用して作成します。
次のタスクを実行するには、ワークスペースで次のアクセス許可を持っている必要があります。
バッチ エンドポイントおよびデプロイを作成または管理する場合: 所有者ロール、共同作成者のロール、または
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*を許可するカスタム ロールを使用します。ワークスペース リソース グループに ARM デプロイを作成する場合: 所有者ロール、共同作成者ロール、またはワークスペースがデプロイされているリソース グループで
Microsoft.Resources/deployments/writeを許可するカスタム ロールを使用します。
Azure Machine Learning を使用するには、次のソフトウェアをインストールする必要があります。
examples リポジトリをクローンします
この記事の例は、azureml-examples リポジトリに含まれているコード サンプルを基にしています。 YAML などのファイルをコピーして貼り付けることなくコマンドをローカルで実行するには、最初にリポジトリを複製してから、ディレクトリをそのフォルダーに変更します。
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
システムを準備する
ワークスペースに接続する
まず、作業している Azure Machine Learning ワークスペースに接続します。
まだ Azure CLI の既定値を設定していない場合は、既定の設定を保存する必要があります。 サブスクリプション、ワークスペース、リソース グループ、場所の値を複数回入力しないようにするには、次のコードを実行します。
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
コンピューティングを作成する
バッチ エンドポイントはコンピューティング クラスターで実行され、Azure Machine Learning コンピューティング クラスター (AmlCompute) と Kubernetes クラスターの両方をサポートします。 クラスターは共有リソースであるため、1 つのクラスターで 1 つまたは多数のバッチ デプロイ (必要に応じてほかのワークロードと一緒に) をホストすることができます。
次のコードに示されているように、batch-cluster という名前のコンピューティングを作成します。 必要に応じて調整し、azureml:<your-compute-name>を使用して計算を参照してください。
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Note
バッチ エンドポイントが呼び出され、バッチ スコアリング ジョブが送信されるまでクラスターは 0 ノードのままであるため、この時点ではコンピューティングに対して課金されません。 コンピューティング コストの詳細については、AmlCompute のコストの管理と最適化に関する記事を参照してください。
バッチ エンドポイントを作成する
バッチ エンドポイントは、クライアントが呼び出してバッチ スコアリング ジョブをトリガーする HTTPS エンドポイントです。 バッチ スコアリング ジョブは、複数の入力をスコア付けします。 バッチ デプロイは、バッチ スコアリング (またはバッチ推論) を実行するモデルをホストする一連のコンピューティング リソースです。 1 つのバッチ エンドポイントに複数のバッチ デプロイを割り当てることができます。 バッチ エンドポイントの詳細については、「バッチ エンドポイントとは 」を参照してください。
ヒント
バッチ デプロイのうちの 1 つが、エンドポイントの既定のデプロイとして機能します。 エンドポイントが呼び出されると、既定のデプロイでバッチ スコアリングが実行されます。 バッチ エンドポイントとデプロイの詳細については、 バッチ エンドポイントとバッチデプロイに関する説明を参照してください。
エンドポイントに名前を付けます。 エンドポイントの名前はエンドポイントの URI に含まれているため、Azure リージョン内で一意である必要があります。 たとえば、
mybatchendpointに存在できるwestus2という名前のバッチ エンドポイントは 1 つだけです。バッチ エンドポイントを構成する
次の YAML ファイルは、バッチ エンドポイントを定義します。 このファイルは、 バッチ エンドポイントの作成に CLI コマンドと共に使用します。
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learning次の表では、エンドポイントの主要なプロパティについて説明します。 完全なバッチ エンドポイント YAML スキーマについては、 CLI (v2) バッチ エンドポイント YAML スキーマを参照してください。
鍵 説明 nameバッチ エンドポイントの名前。 Azure リージョン レベルで一意である必要があります。 descriptionバッチ エンドポイントの説明。 このプロパティは省略可能です。 tagsエンドポイントに含めるタグ。 このプロパティは省略可能です。 エンドポイントを作成します。
バッチ デプロイを作成する
モデル デプロイは、実際の推論を実行するモデルをホストするのに必要なリソースのセットです。 バッチ モデル デプロイを作成するには、次の項目が必要です。
- ワークスペースに登録済みのモデル
- モデルをスコアリングするコード
- モデルの依存関係がインストールされている環境
- 事前に作成されたコンピューティングとリソースの設定
まず、デプロイするモデルを登録します。これは、一般的な数字認識問題 (MNIST) 用の Torch モデルです。 バッチ デプロイでは、ワークスペースに登録されているモデルのみをデプロイできます。 デプロイするモデルが既に登録されている場合は、この手順をスキップできます。
ヒント
モデルは、エンドポイントではなくデプロイに関連付けられます。 つまり、異なるモデル (またはモデル バージョン) がデプロイごとに展開されている限り、同じ単一のエンドポイントで、異なるモデル (またはモデル バージョン) にサービスを提供できます。
次に、スコアリング スクリプトを作成します。 バッチ デプロイには、指定のモデルの実行方法と入力データの処理方法を示すスコアリング スクリプトが必要です。 バッチ エンドポイントでは、Python で作成されたスクリプトがサポートされます。 今回は、数字が表示された画像ファイルを読み込んで、対応する数字を出力するモデルをデプロイします。 スコアリング スクリプトは次のようになります。
Note
MLflow モデルの場合、このスコアリング スクリプトは Azure Machine Learning によって自動的に生成されるため、必要ありません。 モデルが MLflow モデルの場合は、この手順をスキップできます。 バッチ エンドポイントが MLflow モデルでどのように動作するかの詳細については、「バッチ デプロイで MLflow モデルを使用する」の記事を参照してください。
警告
自動機械学習 (AutoML) モデルをバッチ エンドポイントの下にデプロイする場合、AutoML が提供するスコアリング スクリプトはオンライン エンドポイントでのみ機能することと、バッチ実行用には設計されていないことに注意してください。 スコアリング スクリプトを作成する方法については、「バッチ デプロイ用のスコアリング スクリプトを作成する」を参照してください。
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)バッチ デプロイを実行する環境を作成します。 この環境では、バッチ エンドポイントで必要なパッケージ
azureml-coreとazureml-dataset-runtime[fuse]、およびコードの実行に必要な依存関係を含める必要があります。 この場合、依存関係はconda.yamlファイルにキャプチャされています。deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]重要
パッケージ
azureml-coreとazureml-dataset-runtime[fuse]はバッチ デプロイに必要であり、環境の依存関係に含める必要があります。次のように環境を指定します。
サイド メニューの [ 環境 ] タブに移動します。
[ カスタム環境>作成] を選択します。
環境の名前 (この例では
torch-batch-env) を入力します。[環境ソースの選択] で、[オプションの Conda ファイルとともに既存の Docker イメージを使用する] を選択します。
[コンテナー レジストリ イメージ パス] に、「
mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04」と入力します。[次へ] を選択し、[カスタマイズ] セクションに進みます。
GitHub リポジトリからポータルに deployment-torch/environment/conda.yaml ファイルの内容をコピーします。
[Review page]\(レビュー ページ\) に到達するまで [ 次へ ] を選択します。
[ 作成] を選択し、環境の準備が整うのを待ちます。
警告
キュレーションされた環境は、バッチ デプロイではサポートされていません。 独自の環境を指定する必要があります。 プロセスを簡略化するために、キュレーションされた環境の基本イメージをいつでも自分のイメージとして使用できます。
デプロイの定義を作成する
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: info次の表では、バッチ デプロイの主要なプロパティについて説明します。 完全なバッチ デプロイの YAML スキーマについては、「CLI (v2) バッチ デプロイの YAML スキーマ」を参照してください。
鍵 説明 nameデプロイの名前。 endpoint_nameデプロイを作成するエンドポイントの名前。 modelバッチ スコアリングに使用するモデル。 この例では、 pathを使用してインラインでモデルを定義しています。 この定義により、自動的にモデル ファイルをアップロードし、自動生成された名前とバージョンで登録できるようになります。 その他のオプションについては、モデル スキーマに関する記事を参照してください。 運用シナリオのベスト プラクティスとして、モデルを個別に作成し、ここで参照します。 既存のモデルを参照するには、azureml:<model-name>:<model-version>構文を使用します。code_configuration.codeモデルをスコアリングするためのすべての Python ソース コードを格納するローカル ディレクトリ。 code_configuration.scoring_scriptcode_configuration.codeディレクトリ内の Python ファイル。 このファイルには、init()関数とrun()関数が記述されている必要があります。init()関数は、コストのかかる、または一般的な準備を行うときに使用します (たとえば、メモリにモデルを読み込むなど)。init()は、プロセスの開始時に 1 回だけ呼び出されます。 各エントリをスコアリングするには、run(mini_batch)を使用します。mini_batchの値は、ファイル パスのリストです。run()関数からは、Pandas の DataFrame または配列が返されます。 返された要素はそれぞれ、mini_batch内で成功した入力要素の 1 回の実行を示します。 スコアリング スクリプトを作成する方法の詳細については、「スコアリング スクリプトについて」を参照してください。environmentモデルをスコアリングする環境。 この例では、 conda_fileとimageを使用して環境をインラインで定義しています。conda_fileの依存関係は、imageの上部にインストールされます。 環境は自動生成された名前とバージョンを使用し、自動的に登録されます。 その他のオプションについては、環境スキーマに関する記事を参照してください。 運用シナリオのベスト プラクティスとして、環境を別途作成し、ここで参照することをお勧めします。 既存の環境を参照するには、azureml:<environment-name>:<environment-version>構文を使用します。computeバッチ スコアリングを実行するコンピューティング。 この例では、最初に作成した batch-clusterを使用し、azureml:<compute-name>構文を使用してそれを参照します。resources.instance_count各バッチ スコアリング ジョブに使用されるインスタンスの数。 settings.max_concurrency_per_instanceインスタンスあたりの scoring_scriptの並列実行の最大数。settings.mini_batch_sizescoring_scriptが 1 回のrun()呼び出しで処理できるファイルの数。settings.output_action出力ファイルで出力を整理する方法。 append_rowは、run()が返す出力結果を、すべてoutput_file_nameという名前の単一のファイルにマージします。summary_onlyを使用すると、出力結果はマージされず、error_thresholdの計算だけが行われます。settings.output_file_nameappend_rowoutput_actionのバッチ スコアリング出力ファイルの名前。settings.retry_settings.max_retriesscoring_scriptrun()が失敗した場合の最大再試行回数。settings.retry_settings.timeoutミニ バッチをスコアリングするための scoring_scriptrun()のタイムアウト (秒単位)。settings.error_threshold無視する必要がある入力ファイルのスコアリング エラーの数。 入力全体でのエラーの数がこの値を超えると、ジョブは終了します。 この例では -1を使用しています。これは、バッチ スコアリング ジョブを終了することなく、任意の数のエラーが許容されることを示します。settings.logging_levelログの詳細。 値は詳細度が低い順に WARNING、INFO、DEBUG です。 settings.environment_variablesバッチ スコアリング ジョブごとに設定される環境変数の名前と値のペアの辞書。 サイド メニューの [ エンドポイント ] タブに移動します。
[バッチ エンドポイント]>[作成] の順に選択します。
エンドポイントに名前を付けます (この例では
mnist-batch)。 残りのフィールドは、構成してもよいですし、空白のままにすることもできます。[次へ] を選択して、[モデル] セクションに進みます。
モデル mnist-classifier-torch を選択します。
[次へ] を選択して、[デプロイ] ページに進みます。
デプロイに名前を付けます。
[出力] アクションで、[行の追加] が選択されていることを確認します。
[出力ファイル名] で、バッチ スコアリング出力ファイルが必要なものであることを確認します。 既定値は
predictions.csvです。[ミニ バッチ サイズ] で、各ミニバッチに含めるファイルのサイズを調整します。 このサイズは、スコアリング スクリプトがバッチごとに受け取るデータの量を制御します。
[スコアリング タイムアウト (秒)] では、デプロイでファイルのバッチをスコアリングするのに十分な時間が確保されていることを確認してください。 ファイルの数を増やす場合は、通常、タイムアウト値も増やす必要があります。 コストのより高い (ディープ ラーニングに基づくもののような) モデルでは、このフィールドに高い値が必要になる場合があります。
[インスタンスごとの最大コンカレンシー] で、デプロイで取得する各コンピューティング インスタンスごとに必要な Executor の数を構成します。 この数値を大きくすると、並列処理の度合いが高くなりますが、コンピューティング インスタンスのメモリ負荷も増加します。 この値は、[ミニ バッチ サイズ] と合わせて調整するようにします。
完了したら、[次へ] を選択して、[コード + 環境] ページに進みます。
[Select a scoring script for inferencing]\(推論用のスコアリング スクリプトの選択\) で、deployment-torch/code/batch_driver.py スコアリング スクリプト ファイルを検索して選択します。
[環境の選択] セクションで、以前に torch-batch-env を作成した環境を選択します。
[次へ] を選択して、[コンピューティング] ページに進みます。
前の手順で作成したコンピューティング クラスターを選択します。
警告
Azure Kubernetes クラスターでは、バッチ デプロイがサポートされていますが、Azure Machine Learning CLI または Python SDK を使用して作成された場合にのみ有効です。
[インスタンス数] に、デプロイに必要なコンピューティング インスタンスの数を入力します。 この場合は、2 を使用します。
[次へ]を選択します。
デプロイを作成します。
次のコードを実行して、バッチ エンドポイントの下にバッチ デプロイを作成し、それを既定のデプロイとして設定します。
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultヒント
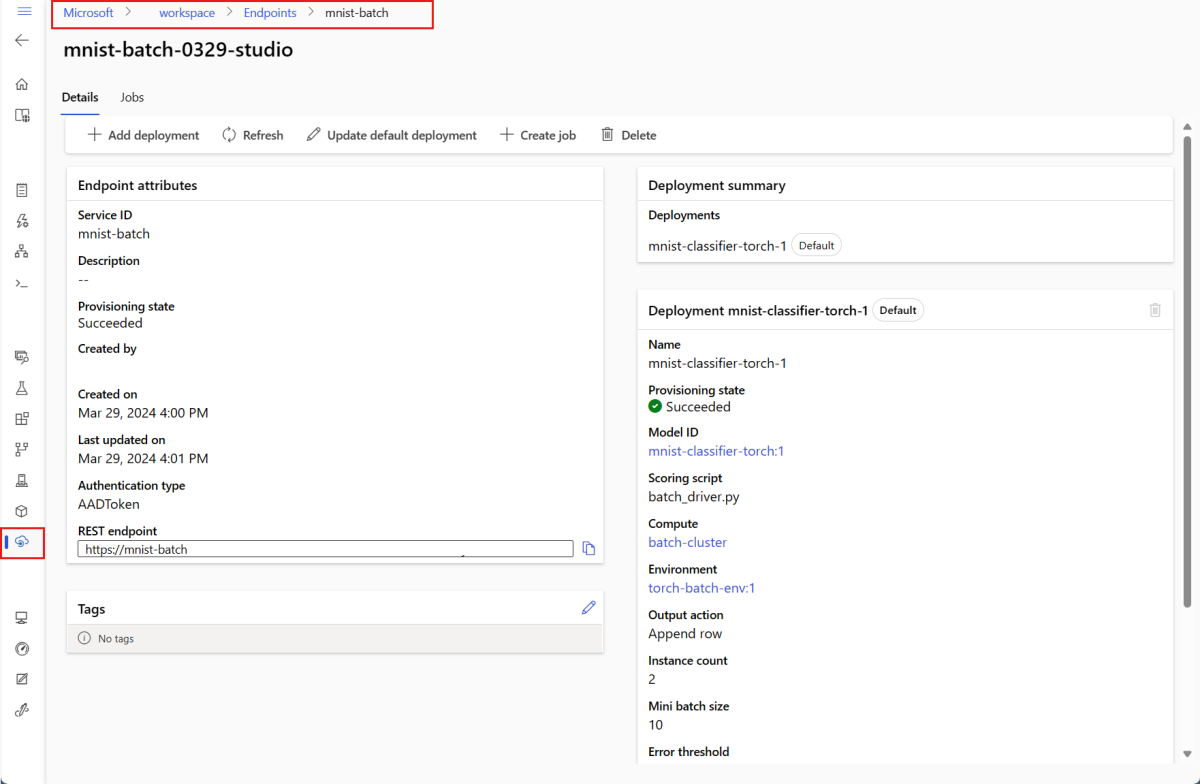
--set-defaultは、新しく作成したデプロイをエンドポイントの既定のデプロイとして設定するパラメーターです。 これは、特に最初のデプロイを作成する場合に、エンドポイントの新しい既定のデプロイを作成する便利な方法です。 運用シナリオのベスト プラクティスとして、新しいデプロイを既定として設定せずに作成することをお勧めします。 デプロイが期待どおりに動作することを確認し、後で既定のデプロイを更新します。 このプロセスの実装の詳細については、「新しいモデルをデプロイする」セクションを参照してください。バッチ エンドポイントとデプロイの詳細を確認します。
[ Batch エンドポイント ] タブを選択します。
表示するバッチ エンドポイントを選択します。
エンドポイントの [詳細] ページには、エンドポイントの詳細と、エンドポイントで使用可能なすべてのデプロイが表示されます。

バッチ エンドポイントを実行して結果にアクセスする
データ フローを理解する
バッチ エンドポイントを実行する前に、データがシステムを通過する方法を理解してください。
入力: 処理するデータ (スコア付け)。 これには次のものが含まれます。
- Azure Storage (BLOB ストレージ、データ レイク) に保存されているファイル
- 複数のファイルを含むフォルダー
- Azure Machine Learning に登録されたデータセット
処理: デプロイされたモデルは、入力データをバッチ (ミニバッチ) で処理し、予測を生成します。
出力: モデルからの結果。Azure Storage にファイルとして格納されます。 既定では、出力はワークスペースの既定の BLOB ストレージに保存されますが、別の場所を指定することもできます。
バッチ エンドポイントを呼び出す
バッチ エンドポイントを呼び出すと、バッチ スコアリング ジョブがトリガーされます。 ジョブ name は呼び出し応答で返され、バッチ スコアリングの進行状況を追跡します。 エンドポイントがスコア付けするデータを検索できるように、入力データ パスを指定します。 次の例は、Azure Storage アカウントに格納されている MNIST データセットのサンプル データに対して新しいジョブを開始する方法を示しています。
Azure CLI、Azure Machine Learning SDK、REST エンドポイントを使用して、バッチ エンドポイントを呼び出して実行することができます。 これらのオプションの詳細については、「バッチ エンドポイントのジョブと入力データの作成」を参照してください。
Note
並列処理のしくみ
バッチデプロイは、ファイル レベルで作業を分散します。 たとえば、100 個のファイルと 10 個のファイルのミニ バッチを含むフォルダーでは、それぞれ 10 個のファイルから 10 個のバッチが生成されます。 これは、ファイル サイズに関係なく発生します。 ミニバッチで処理するにはファイルが大きすぎる場合は、小さなファイルに分割して並列処理を増やすか、ミニバッチあたりのファイル数を減らします。 現在、バッチ デプロイでは、ファイル サイズの分散のずれは考慮されていません。
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)
![バッチ スコアリングを開始する [ジョブの作成] オプションのスクリーンショット。](media/how-to-use-batch-model-deployments/create-batch-job.png?view=azureml-api-2#lightbox)


バッチ エンドポイントでは、さまざまな場所にあるファイルやフォルダーの読み取りがサポートされています。 サポートされているタイプとその指定方法の詳細については、「バッチ エンドポイント ジョブからのデータへのアクセス」を参照してください。
バッチ ジョブ実行の進行状況を監視する
バッチ スコアリング ジョブでは、すべての入力の処理に時間がかかります。
次のコードは、ジョブの状態を確認し、詳細が記載された Azure Machine Learning スタジオへのリンクを出力します。
az ml job show -n $JOB_NAME --web

バッチ スコアリングの結果を確認する
ジョブの出力は、クラウド ストレージに格納されます。これはワークスペースの既定の BLOB ストレージか指定したストレージのいずれかです。 既定値を変更する方法については、「出力の場所を構成する」を参照してください。 次の手順を実行すると、ジョブが完了したときに Azure Storage Explorer でスコアリング結果を表示できます。
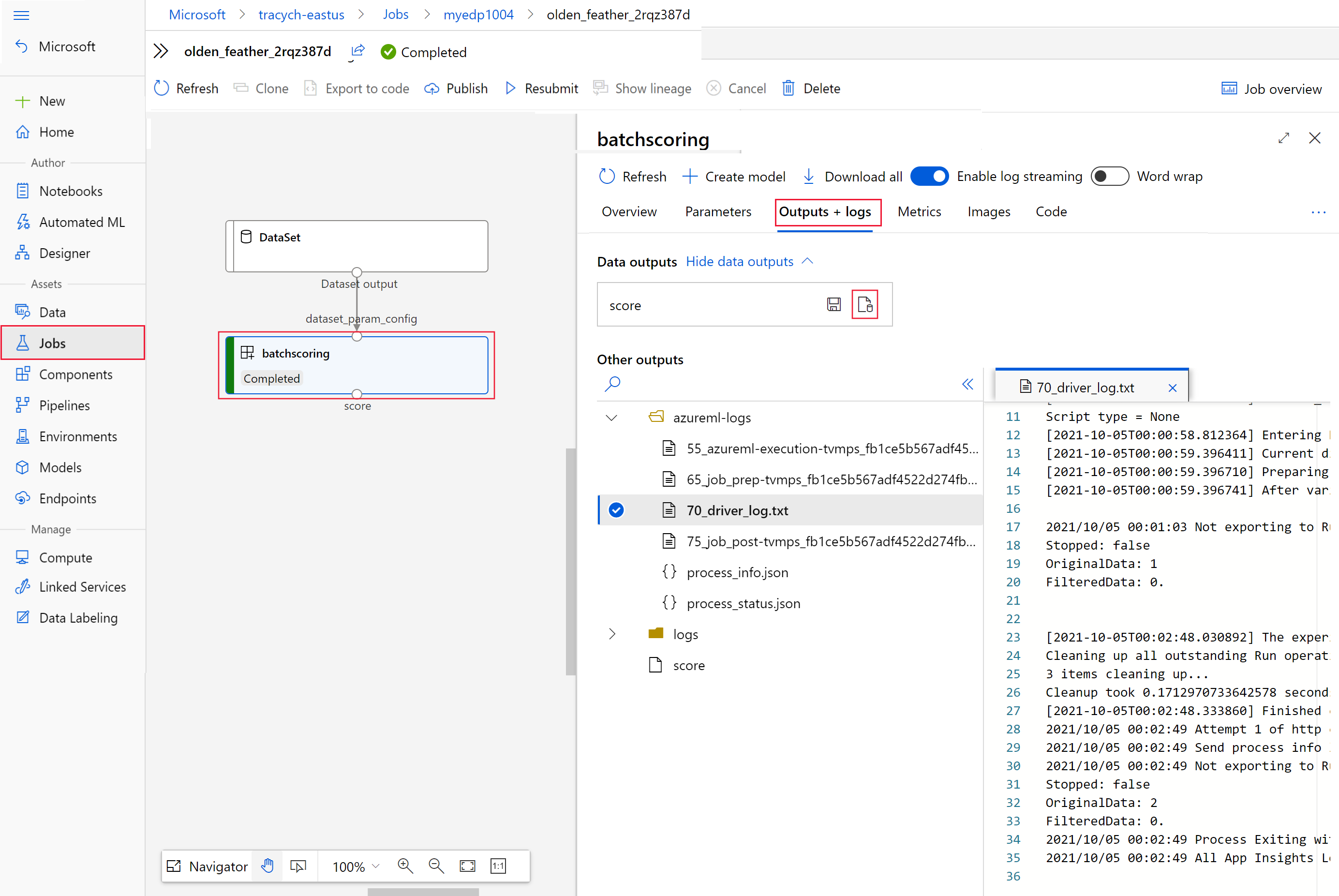
次のコードを実行して、Azure Machine Learning スタジオでバッチ スコアリング ジョブを開きます。 ジョブのスタジオ リンクは、
invokeの応答にもinteractionEndpoints.Studio.endpointの値として含まれています。az ml job show -n $JOB_NAME --webジョブのグラフで、
batchscoringステップを選択します。[出力 + ログ] タブを選択し、[Show data outputs]\(データ出力の表示\) を選択します。
[Data outputs]\(データ出力\) で、Storage Explorer を開くアイコンを選択します。
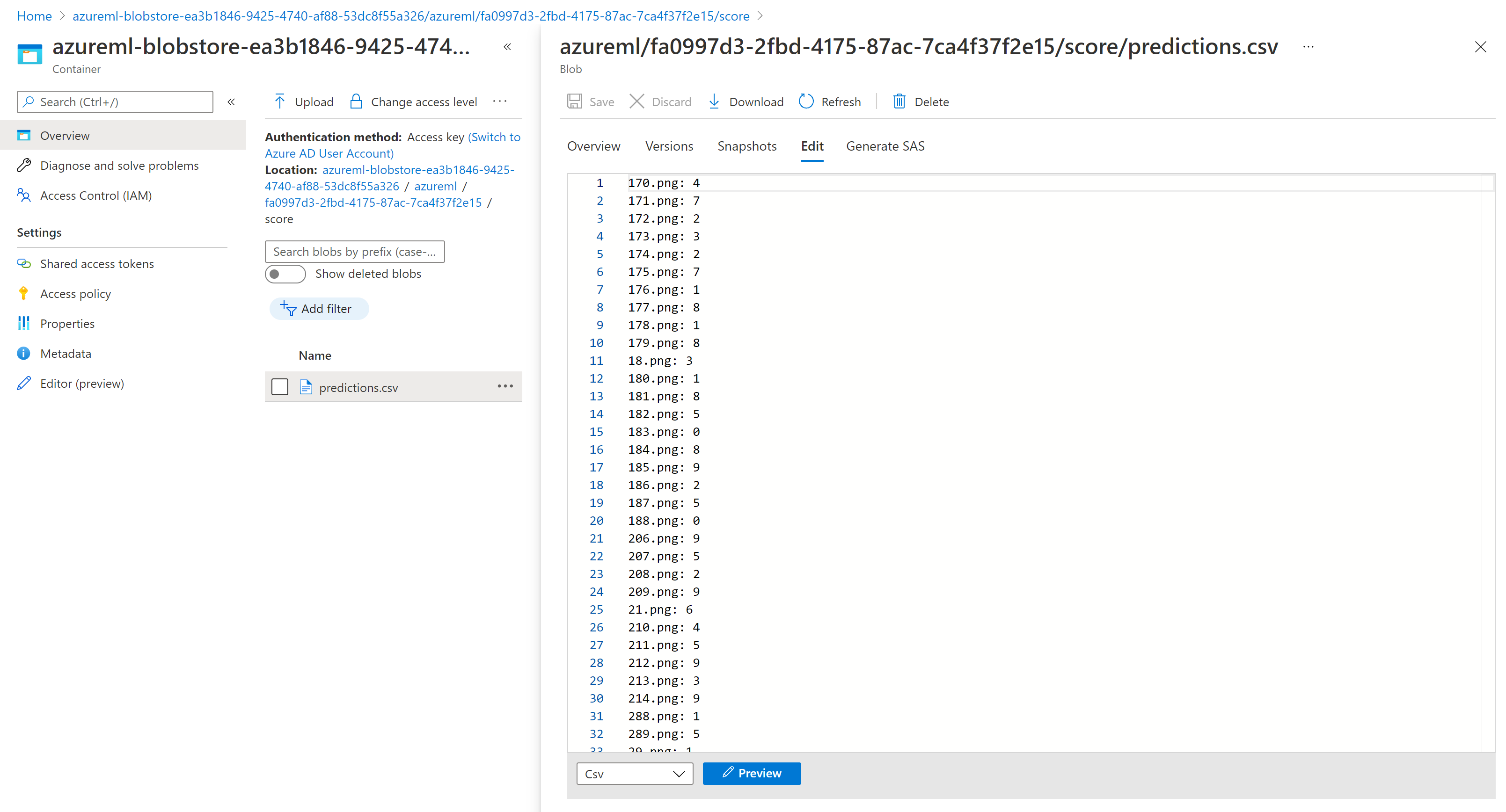
Storage Explorer のスコアリング結果は、次のサンプル ページのようになります。


出力の場所を構成する
既定では、バッチ スコアリングの結果は、ワークスペースの既定の BLOB ストアに、ジョブ (システム生成 GUID) にちなんだフォルダーに格納されます。 バッチ エンドポイントを呼び出すときの出力場所を構成します。
Azure Machine Learning の登録済みデータストア内でフォルダーを構成するには、output-path を使用します。
--output-path の構文は、フォルダーを指定する場合は --input と同じです。つまり、azureml://datastores/<datastore-name>/paths/<path-on-datastore>/ となります。 新しい出力ファイル名を構成するには、--set output_file_name=<your-file-name> を使用します。
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

警告
一意の出力場所を使用する必要があります。 出力ファイルが存在する場合、バッチ スコアリング ジョブは失敗します。
重要
入力とは異なり、出力は BLOB ストレージ アカウントで実行される Azure Machine Learning データ ストアにのみ格納できます。
各ジョブごとにデプロイ構成を上書きする
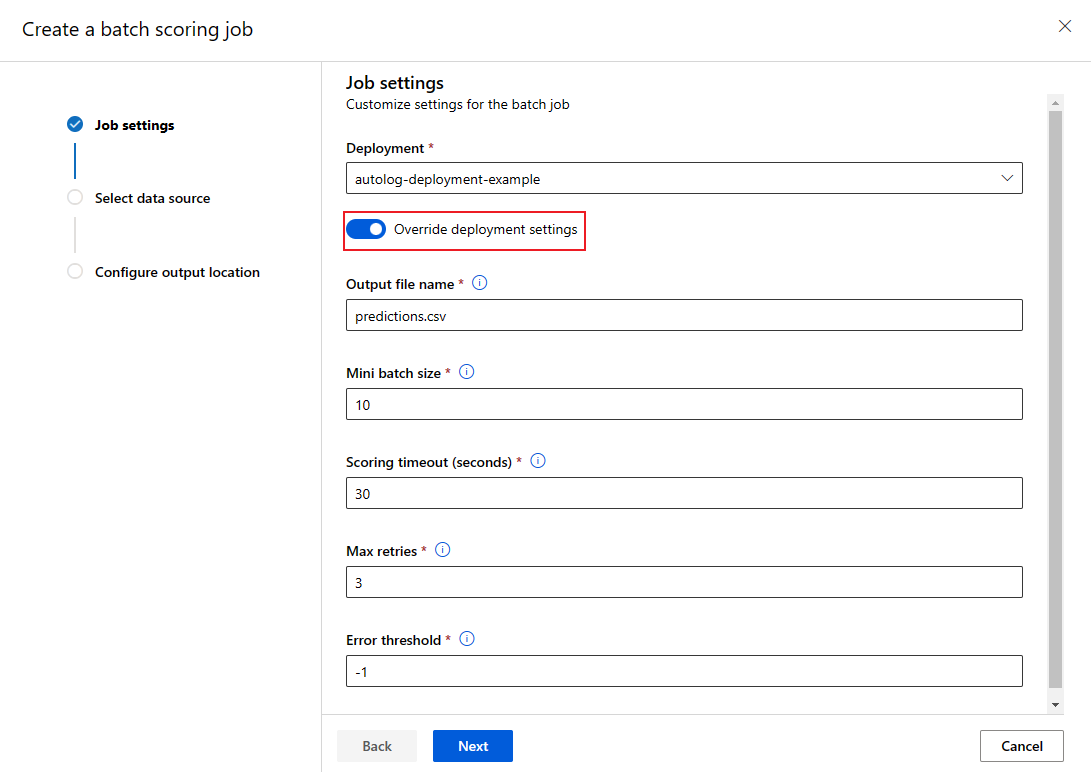
バッチ エンドポイントを呼び出すときに、一部の設定を上書きしてコンピューティング リソースを最大限に活用し、パフォーマンスを向上させることができます。 この機能は、デプロイを完全に変更せずに、ジョブごとに異なる設定が必要な場合に便利です。
オーバーライドできる設定はどれですか?
次の設定は、ジョブごとに構成することができます。
| 設定 | いつ使用するか | サンプル シナリオ |
|---|---|---|
| インスタンス数 | さまざまなデータ ボリュームがある場合 | 大規模なデータセットには、より多くのインスタンスを使用します (100 万ファイルの場合は 10 インスタンス、100,000 ファイルの場合は 2 インスタンス)。 |
| ミニ バッチ サイズ | スループットとメモリ使用量のバランスを取る必要がある場合 | 大きな画像には小さなバッチ (10 ~ 50 ファイル) を、小さなテキスト ファイルには大きなバッチ (100 ~ 500 ファイル) を使用します。 |
| 最大再試行回数 | データ品質が異なる場合 | ノイズの多いデータに対しては再試行回数を多く (5 から 10)、クリーンなデータに対しては再試行回数を少なく (1 から 3) |
| タイムアウト | データ型によって処理時間が異なる場合 | 複雑なモデルに対してはタイムアウトを長く (300 秒)、単純なモデルに対してはタイムアウトを短く (30 秒) |
| エラーのしきい値 | 異なる障害許容レベルが必要な場合 | 重大なジョブに対しては厳密なしきい値 (-1)、試験的ジョブに対しては寛容なしきい値 (10%) |
設定をオーバーライドする方法
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
デプロイをエンドポイントに追加する
バッチ エンドポイントにデプロイを追加した後も、引き続きモデルを改良して、新しいデプロイを追加できます。 ユーザーが新しいモデルを開発して同じエンド ポイントの下にデプロイする間、バッチ エンドポイントは引き続き、既定のデプロイに対応し続けます。 デプロイが相互に影響することはありません。
この例では、同じ MNIST の問題を解決するために、Keras と TensorFlow で構築されたモデルを使用する 2 つ目のデプロイを追加します。
2 つめのデプロイを追加する
バッチデプロイ用の環境を作成します。 コードで実行する必要がある依存関係を含めます。 バッチデプロイに必要なライブラリ
azureml-coreを追加します。 次の環境定義には、TensorFlow でモデルを実行するために必要なライブラリが含まれています。GitHub リポジトリからポータルに deployment-keras/environment/conda.yaml ファイルの内容をコピーします。
[概要] ページが表示されるまで [次へ] を選択します。
[作成] を選択し、環境が使用できる状態になるまで待ちます。
使用した conda ファイルは次のようになります。
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]モデルのスコアリング スクリプトを作成します。
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)デプロイの定義を作成する
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv[ 次へ ] を選択して、[コード + 環境] ページに進みます。
[Select a scoring script for inferencing]\(推論用のスコアリング スクリプトの選択\) で、deployment-keras/code/batch_driver.py スコアリング スクリプト ファイルを検索して選択します。
[環境の選択] で、前の手順で作成した環境を選択します。
[次へ]を選択します。
[コンピューティング] ページで、前の手順で作成したコンピューティング クラスターを選択します。
[インスタンス数] に、デプロイに必要なコンピューティング インスタンスの数を入力します。 この場合は、2 を使用します。
[次へ]を選択します。
デプロイを作成します。
![[新しいデプロイの追加] オプションのスクリーンショット。](media/how-to-use-batch-model-deployments/add-deployment-option.png?view=azureml-api-2)
既定以外のバッチ デプロイをテストする
既定以外の新しいデプロイをテストするには、実行するデプロイの名前を把握している必要があります。
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)
--deployment-name を使用して実行するデプロイを指定していることに注意してください。 このパラメーターを使用すると、バッチ エンドポイントの既定のデプロイは更新せずに、既定以外のデプロイをinvokeことができます。
既定のバッチ デプロイを更新する
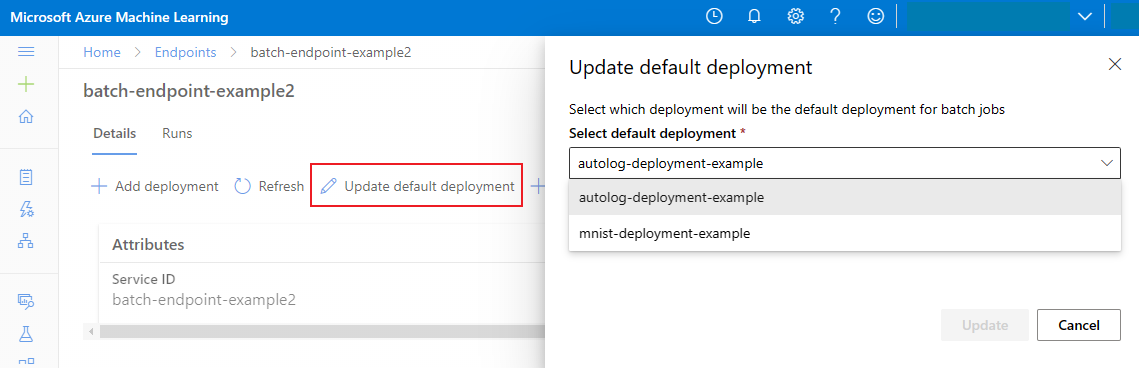
エンドポイント内で特定のデプロイを呼び出すこともできますが、通常はエンドポイント自体を呼び出し、使用するデプロイはエンドポイントで決定されるようにします。 エンドポイントを呼び出すユーザーとの契約を変更することなく、既定のデプロイを変更する (その結果として、デプロイを提供するモデルが変更される) ことができます。 既定のデプロイを更新するには、次のコードを使用します。
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
バッチ エンドポイントとデプロイを削除する
古いバッチデプロイが不要な場合は、次のコードを実行して削除します。
--yes フラグによって削除が確認されます。
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
次のコードを実行して、バッチ エンドポイントとその基になるデプロイを削除します。 バッチ スコアリング ジョブは削除されません。
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes