この記事では、Azure Machine Learning データセットと Azure Open Datasets を使用して、ローカルまたはリモートの機械学習の実験にキュレーションされたエンリッチメント データを取り込む方法について説明します。
Azure Machine Learning データセットを使用すると、データ ソースの場所への参照とそのメタデータのコピーを作成できます。 データセットは遅延評価されるため、またデータは既存の場所に残るため:
- 元のデータ ソースが意図せず変更されるリスクはありません
- 追加のストレージ コストは発生しません。
- ML ワークフローのパフォーマンスが向上します
Azure Machine Learning のデータ アクセス ワークフロー全体にデータセットが適合する場合の詳細については、データへの安全なアクセスに関する記事を参照してください。
Azure Open Datasets は、シナリオ固有の機能を追加して予測ソリューションを強化し、それらのソリューションの精度を向上させることができる、キュレーションされたパブリック データセットです。 機械学習モデルのトレーニングに役立つパブリックドメイン データについては、Open Datasets カタログ リソースを参照してください。次に例を示します。
Open Dataset は、Microsoft Azure 上のクラウドでホストされます。 これらは、Azure Machine Learning Python SDK と Azure Machine Learning スタジオの両方に含まれています。
前提条件
必要なもの:
Azure サブスクリプション。 まだ持っていない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
Azure Machine Learning SDK for Python がインストール済み (これには
azureml-datasetsパッケージが含まれています)。- Azure Machine Learning コンピューティング インスタンスを作成します (これは、統合ノートブックと SDK が既にインストールされている、完全に構成および管理された開発環境です)。
OR
- ご自分の Python 環境で作業し、こちらの手順に従って SDK をインストールします。
Note
一部の Dataset クラスは、azureml-dataprep パッケージに依存しています。 このパッケージは 64 ビット Python とのみ互換性があります。 Linux ユーザーの場合、これらのクラスは次の Linux ディストリビューションでのみサポートされています。
- Debian (8、9)
- Fedora (27、28)
- Red Hat Enterprise Linux (7、8)
- Ubuntu (14.04、16.04、18.04)
SDK を使用してデータセットを作成する
Python SDK の Azure Open Datasets クラスを使用して Azure Machine Learning データセットを作成するには、pip install azureml-opendatasets でパッケージがインストールされていることを確認します。 SDK では、各個別データ セットのクラスがそのクラスを表し、一部のクラスは Azure Machine Learning FileDataset データ型、Azure Machine Learning TabularDataset データ型、またはその両方として使用できます。 opendatasets クラスの完全な一覧については、リファレンス ドキュメントを参照してください。
一部の opendatasets クラスは TabularDataset または FileDataset リソースとして取得できます。 その後、ファイルを直接操作したりダウンロードしたりすることができます。 他のクラスは、Python SDK のDataset クラスの get_tabular_dataset() または get_file_dataset() 関数を使用して、データセットのみを取得できます。
このコードは、MNIST opendatasets クラスで TabularDataset または FileDataset のいずれかを返すことができることを示しています。
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
この例では、Diabetes opendatasets クラスは TabularDataset としてのみ使用できます。 これには、get_tabular_dataset() を使用する必要があります。
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
データセットを登録する
Azure Machine Learning データセットをワークスペースに登録すると、他のユーザーとデータセット共有したり、ワークスペース内の実験間で再利用したりすることができます。 Open Datasets から作成された Azure Machine Learning データセットを登録すると、データはすぐにはダウンロードされませんが、後で中央の保存場所から要求したとき (たとえばトレーニング中に) にデータにアクセスできます。
データセットをワークスペースに登録するには、register() メソッドを使用します。
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Studio を使用してデータセットを作成する
Azure Machine Learning スタジオを使用して、Azure Open Datasets から Azure Machine Learning データセットを作成することもできます。 この統合 Web インターフェイスには、あらゆるスキル レベルのデータ サイエンス実務者がデータ サイエンス シナリオを実行するための機械学習ツールが含まれています。
Note
Azure Machine Learning Studio を介して作成されたデータセットは、自動的にワークスペースに登録されます。
ワークスペースの左側のナビゲーションで [データ] を選択します。 次のスクリーンショットに示すように、[データ資産] タブで [作成] を選択します。
![[データ資産] タブの [作成] コントロールを示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/data-assets-tab.png)
次の画面で、新しいデータ資産の名前と省略可能な説明を追加します。 次に、このスクリーンショットに示すように、[種類] ドロップダウンで [表形式] を選択します。
![[種類] ドロップダウンでの [表形式] オプションの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/select-tabular-dropdown-option.png)
次の画面で、このスクリーンショットに示すように、[Azure Open Datasets から] を選択してから、[次へ] を選択します。
![[Azure Open Datasets から] オプションの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/select-from-azure-open-datasets.png)
次の画面で、使用できる Azure Open Dataset を選択します。 このスクリーンショットでは、San Francisco Safety Data データセットを選択しました。
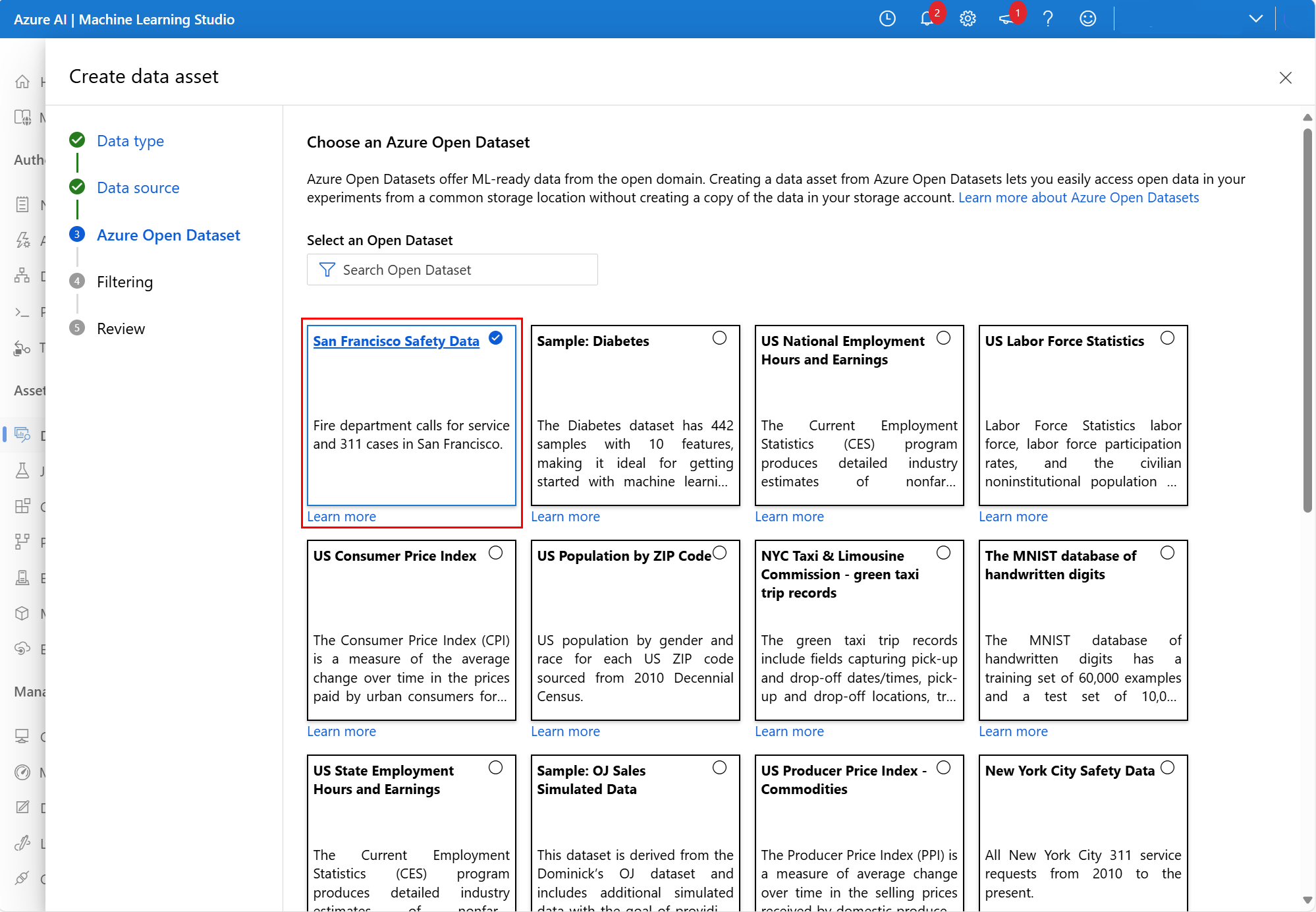
必要に応じて下にスクロールし、次のスクリーンショットに示すように [次へ] を選択します。
![[次へ] ボタンの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/select-next.png)
必要に応じて、選択したデータセットに適した使用できるフィルターを使用してデータをフィルター処理します。 San Francisco Safety Data データセットの場合、フィルター処理された日付範囲を開始日 2024 年 7 月 1 日から 2024 年 7 月 17 日までに設定します。 次のスクリーンショットに示すように、[次へ] を選択します。
![フィルター値の選択と [次へ] ボタンの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/data-asset-filter-example.png)
次の画面で、新しいデータ資産の設定を確認し、必要な変更を加えます。 問題ないと思われる場合は、次のスクリーンショットに示すように、[作成] を選択します。
![選択した設定の確認と [次へ] ボタンの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/create-the-data-asset.png)
San Francisco Safety Data データセットのフィールドの説明と日付範囲の詳細については、「San Francisco Safety Data」リソースを参照してください。 その他のデータセットの詳細については、Azure Open Datasets カタログ リソースを参照してください。
![[データ資産] タブの [作成] コントロールを示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/data-assets-tab.png#lightbox)
![[種類] ドロップダウンでの [表形式] オプションの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/select-tabular-dropdown-option.png#lightbox)
![[Azure Open Datasets から] オプションの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/select-from-azure-open-datasets.png#lightbox)

![[次へ] ボタンの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/select-next.png#lightbox)
![フィルター値の選択と [次へ] ボタンの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/data-asset-filter-example.png#lightbox)
![選択した設定の確認と [次へ] ボタンの選択を示すスクリーンショット。](media/how-to-create-dataset-from-open-dataset/create-the-data-asset.png#lightbox)
この時点で、データセットはワークスペース内の [データセット] の下で利用できます。 これを、自分で作成した他のデータセットと同じ方法で使用できます。
実験用のデータセットにアクセスする
ML モデルのトレーニングのために、機械学習の実験でデータセットを使用します。 詳細については、データセットを使用してトレーニングする方法の詳細の記事を参照してください。
サンプルの Notebook
Open Datasets 機能の例とデモについては、これらのサンプル ノートブックを参照してください。