Azure Database for PostgreSQL のビジネス継続性とは、特にコンピューティング インフラストラクチャの中断に直面した場合にビジネスを継続できるメカニズム、ポリシー、および手順を指します。 ほとんどの場合、Azure Database for PostgreSQL は、クラウド環境で発生する可能性のある破壊的なイベントを処理し、アプリケーションとビジネス プロセスの実行を維持します。 ただし、次のようなイベントは自動的に処理できません。
- ユーザーが誤ってテーブルの行を削除または更新した。
- 地震によって停電が発生し、一時的に可用性ゾーンまたはリージョンが使用できなくなった。
- バグまたはセキュリティの問題を修正するために、データベースの修正プログラムを適用する必要がある。
Azure Database for PostgreSQL には、計画的および計画外のダウンタイム イベント中に、データを保護し、ミッション クリティカルなデータベースのダウンタイムを軽減する機能が用意されています。 堅牢な回復性と可用性を提供する Azure インフラストラクチャに基づいて構築された Azure Database for PostgreSQL には、別の障害保護を提供し、復旧時間の要件に対処し、データ損失の露出を減らすビジネス継続性機能があります。 アプリケーションを設計するときは、ダウンタイムの許容範囲 (目標復旧時間 (RTO)) とデータ損失の発生 (目標復旧時点 (RPO)) を考慮する必要があります。 たとえば、ビジネス クリティカルなデータベースでは、テスト データベースよりも厳しいアップタイムが必要になります。
次の表は、Azure Database for PostgreSQL が提供する機能を示しています。
| 機能 | 説明 | 考慮事項 |
|---|---|---|
| 自動バックアップ | Azure Database for PostgreSQL フレキシブル サーバー インスタンスは、データベース ファイルの毎日のバックアップを自動的に実行し、トランザクション ログを継続的にバックアップします。 バックアップは 7 日から最大 35 日まで保持できます。 データベース サーバーは、バックアップの保持期間内の任意の時点に復元できます。 RTO は、復元するデータのサイズとログ復旧を実行する時間によって異なります。 数分から最大で 12 時間かかる可能性があります。 詳細については、バックアップと復元の概念に関するページを参照してください。 | バックアップ データは、リージョン内に保持されます。 |
| ゾーン冗長の高可用性 | Azure Database for PostgreSQL フレキシブル サーバー インスタンスは、リージョン内の 2 つの異なる可用性ゾーンにプライマリ サーバーとスタンバイ サーバーがデプロイされるゾーン冗長高可用性 (HA) 構成でデプロイできます。 この HA 構成を使用すると、データベースがゾーンレベルの障害から保護され、計画的および計画外のダウンタイム イベントの発生時にアプリケーションのダウンタイムを減らすことができます。 プライマリ サーバーからのデータは、同期モードでスタンバイ レプリカにレプリケートされます。 プライマリ サーバーで何らかの障害が発生した場合、サーバーは自動的にスタンバイ レプリカにフェールオーバーされます。 ほとんどの場合、RTO は 120 秒未満と予想されます。 RPO はゼロ (データ損失なし) であると想定されます。 詳細については、[概念 - 高可用性]/azure/reliability/reliability-postgresql-flexible-server を参照してください。 | General Purpose と Memory Optimized のコンピューティング レベルでサポートされます。 複数のゾーンが使用可能なリージョンでのみ利用できます。 |
| 同一ゾーンの高可用性 | Azure Database for PostgreSQL フレキシブル サーバー インスタンスは、プライマリ サーバーとスタンバイ サーバーがリージョン内の同じ可用性ゾーンにデプロイされるのと同じゾーン高可用性 (HA) 構成でデプロイできます。 この HA 構成を使用すると、データベースがノードレベルの障害から保護され、計画的および計画外のダウンタイム イベントの発生時にアプリケーションのダウンタイムを減らすことができます。 プライマリ サーバーからのデータは、同期モードでスタンバイ レプリカにレプリケートされます。 プライマリ サーバーで何らかの障害が発生した場合、サーバーは自動的にスタンバイ レプリカにフェールオーバーされます。 ほとんどの場合、RTO は 120 秒未満と予想されます。 RPO はゼロ (データ損失なし) であると想定されます。 詳細については、[概念 - 高可用性]/azure/reliability/reliability-postgresql-flexible-server を参照してください。 | General Purpose と Memory Optimized のコンピューティング レベルでサポートされます。 |
| Premium マネージド ディスク | データベース ファイルは、耐久性と信頼性に優れた Premium マネージド ストレージに格納されます。 これにより、自動データ復旧機能を備えた可用性ゾーン内に格納されるレプリカの 3 つのコピーを使用してデータの冗長性が提供されます。 詳細については、マネージド ディスクのドキュメントを参照してください。 | 可用性ゾーン内に格納されるデータ。 |
| ゾーン冗長バックアップ | Azure Database for PostgreSQL フレキシブル サーバー インスタンス のバックアップは、リージョンが可用性ゾーンをサポートしている場合、リージョン内のゾーン冗長ストレージに自動的かつ安全に格納されます。 サーバーがプロビジョニングされているゾーンレベルの障害では、サーバーにゾーン冗長が構成されていない場合でも、別のゾーンの最新の復元ポイントを使用してデータベースを復元できます。 詳細については、バックアップと復元の概念に関するページを参照してください。 | 複数のゾーンが使用可能なリージョンにのみ適用されます。 |
| geo 冗長バックアップ | Azure Database for PostgreSQL フレキシブル サーバー インスタンスのバックアップは、リモート リージョンにコピーされます。 これは、プライマリ サーバーのリージョンがダウンした場合のディザスター リカバリーの状況に役立ちます。 | この機能は、現在選択されているリージョンで有効になっています。 復元するデータのサイズと実行する復旧の量によっては、RTO は長くなり、RPO は高くなります。 |
| 読み取りレプリカ | リージョンにまたがる読み取りレプリカをデプロイして、リージョン レベルの障害からデータベースを保護できます。 読み取りレプリカは、PostgreSQL の物理的なレプリケーション テクノロジを使用して非同期的に更新され、プライマリより遅れることがあります。 詳細については、読み取りレプリカの概念に関するページを参照してください。 | General Purpose と Memory Optimized のコンピューティング レベルでサポートされます。 |
次の表は、一般的なワークロード シナリオでの RTO と RPO を比較したものです。
| 機能 | バースト可能 | 運用 SKU (汎用/メモリ最適化) |
|---|---|---|
| バックアップからのポイントインタイム リストア | リテンション期間内の任意の復元ポイント RTO - 変動 RPO < 5 分 |
リテンション期間内の任意の復元ポイント RTO - 変動 RPO < 5 分 |
| Geo レプリケーション バックアップからの geo リストア | RTO - 変動 RPO < 1 時間 |
RTO - 変動 RPO < 1 時間 |
| 読み取りレプリカ | 該当なし | RTO - 分単位* RPO - 通常、30 秒から 5 分* の範囲 |
| 高可用性 | 該当なし | RTO < 120 秒 RPO = 0 |
計画的なダウンタイム イベント
以下では、計画メンテナンスのシナリオをいくつか示します。 これらのイベントでは、通常、最大で数分間のダウンタイムが発生し、データ損失は発生しません。
| シナリオ | 処理 |
|---|---|
| コンピューティングのスケーリング (ユーザーによる開始) | コンピューティングのスケーリング操作の間は、アクティブなチェックポイントの完了が許可され、クライアント接続がドレインされ、コミットされていないトランザクションが取り消され、ストレージがデタッチされてから、サーバー自体がシャットダウンされます。 同じデータベース サーバー名を持つ新しい Azure Database for PostgreSQL フレキシブル サーバー インスタンスが、スケーリングされたコンピューティング構成を使用してプロビジョニングされます。 その後、ストレージが新しいサーバーにアタッチされて、データベースが起動され、クライアント接続を受け入れる前に、必要に応じて復旧が実行されます。 |
| ストレージのスケールアップ (ユーザーによる開始) | ストレージのスケールアップ操作が開始されると、アクティブなチェックポイントの完了が許可され、クライアント接続がドレインされ、コミットされていないトランザクションが取り消されます。 その後、サーバーがシャットダウンされます。 ストレージは、目的のサイズにスケーリングされた後、新しいサーバーにアタッチされます。 必要な場合は、クライアント接続を受け入れる前に、復旧が実行されます。 ストレージ サイズのスケールダウンはサポートされていないことに注意してください。 |
| 新しいソフトウェアのデプロイ (Azure による開始) | 新機能のロールアウトやバグの修正は、サービスの計画メンテナンスの一環として自動的に行われ、ユーザーはそれらのアクティビティがいつ発生するかをスケジュールできます。 詳細については、ポータルを確認してください。 |
| マイナー バージョンのアップグレード (Azure による開始) | Azure Database for PostgreSQL では、Azure によって決定されたマイナー バージョンへの修正プログラムが自動的にデータベース サーバーに適用されます。 これは、サービスの計画的なメンテナンスの一環として行われます。 データベース サーバーは、新しいマイナー バージョンで自動的に再起動されます。 詳細については、こちらのドキュメントを参照してください。 ポータルでも確認できます。 |
Azure Database for PostgreSQL フレキシブル サーバー インスタンスが高可用性で構成されている場合、サーバーにより最初にスタンバイ サーバーでスケーリングとメンテナンスの操作が実行されます。 詳細については、[概念 - 高可用性]/azure/reliability/reliability-postgresql-flexible-server を参照してください。
計画外のダウンタイムの軽減
計画外のダウンタイムは、基になるハードウェアの障害、ネットワークの問題、ソフトウェアのバグなど、予期しない中断の結果として発生する可能性があります。 高可用性が構成されているデータベース サーバーが予期せず停止した場合は、スタンバイ レプリカがアクティブ化され、クライアントは操作を再開できます。 高可用性 (HA) が構成されていない場合は、再起動の試みが失敗すると、新しいデータベース サーバーが自動的にプロビジョニングされます。 計画外のダウンタイムを回避することはできませんが、Azure Database for PostgreSQL は、人間の介入を必要とせずに復旧操作を自動的に実行することで、ダウンタイムを軽減するのに役立ちます。
高可用性の提供に継続的に取り組んでいますが、Azure Database for PostgreSQL で障害が発生し、データベースが使用できなくなるため、アプリケーションに影響を与える場合があります。 サービスの監視によって、接続エラー、障害、パフォーマンスの問題を広範囲にわたって引き起こす問題が検出されると、ユーザーに逐次情報を提供するために、サービスで自動的に停止が宣言されます。
サービス停止
Azure Database for PostgreSQL フレキシブル サーバー インスタンスの停止が発生した場合は、次の場所で停止に関連する詳細を確認できます。
- Azure portal のバナー: サブスクリプションが影響を受けることが確認された場合は、Azure portal の [通知] にサービスに問題があることを知らせる停止アラートが発生します。
![Azure portal の [通知] を示すスクリーンショット。](media/business-continuity/notification-service-issue-example.png)
- [ヘルプとサポート] または [サポートとトラブルシューティング]: [ヘルプとサポート] または [サポートとトラブルシューティング] からサポート チケットを作成すると、お使いのリソースに影響を与える問題に関する情報が表示されます。 影響の詳細と概要を確認するには、[停止の詳細を確認する] を選択します。 アラートは [新しいサポート リクエスト] ページでも確認できます。
![Azure portal の [ヘルプとサポート] 通知を示すスクリーンショット。](media/business-continuity/help-support-service-health-notification.png)
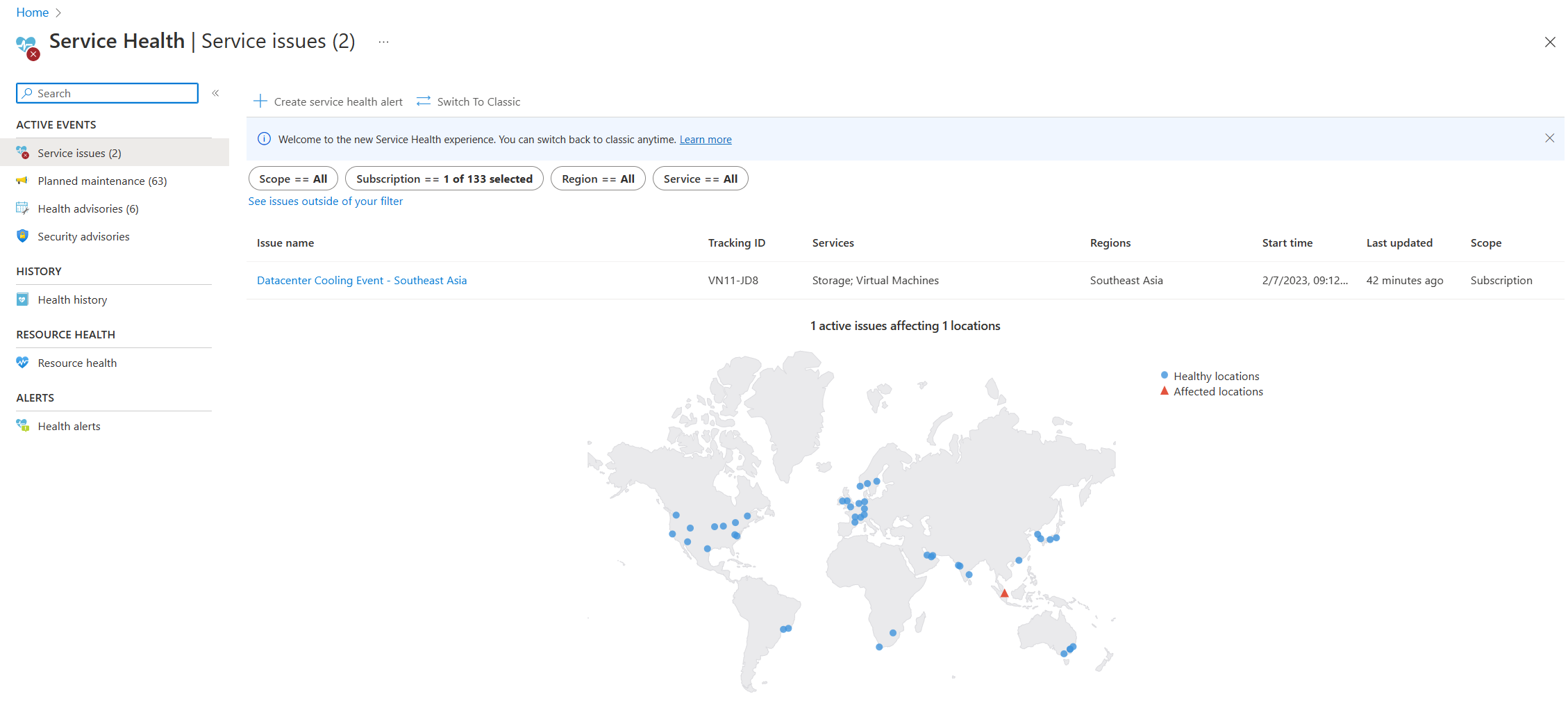
- [サービス ヘルプ]: Azure portal の [サービス正常性] ページでは、Azure データ センターの全体的な状態に関する情報を確認できます。 Azure portal の検索バーで「サービス正常性」を検索し、[有効なイベント] カテゴリの [サービスに関する問題] を表示します。 また、[ヘルプ] メニューの任意のリソースの [リソース正常性] ページで、個々のリソースの正常性を確認することもできます。 次に示すのは [Service Health] ページのサンプル スクリーンショットで、東南アジアでのアクティブなサービスの問題に関する情報が表示されています。
- メール通知: アラートを設定している場合、サービスの停止によりサブスクリプションとリソースが影響を受けると、メール通知が届きます。 メールは "azure-noreply@microsoft.com" から届きます。 メールの本文は、"アクティビティ ログ アラート ... が Azure サブスクリプション ... のサービスの問題によってトリガーされました" で始まります。 サービス正常性のアラートの詳細については、「Azure portal を使用して Azure サービスの通知でアクティビティ ログ アラートを受け取る」を参照してください。
重要
その名前が示すように、PostgreSQL の一時テーブルスペースは一時オブジェクトだけでなく、その他の内部データベース操作 (並べ替えなど) にも使用されます。 そのため、一時テーブルスペース内にユーザー スキーマ オブジェクトを作成することはお勧めできません。サーバーの再起動や HA フェールオーバーなどが発生すると、このようなオブジェクトの持続性は保証されません。
計画外のダウンタイム: 障害シナリオとサービス復旧
計画外の障害シナリオと復旧プロセスを次に示します。
| シナリオ |
復旧プロセス [ゾーン冗長 HA なしで構成されたサーバー] |
復旧プロセス [ゾーン冗長 HA ありで構成されたサーバー] |
|---|---|---|
| データベース サーバーの障害 | データベース サーバーがダウンした場合、Azure によってデータベース サーバーの再起動が試みられます。 それが失敗した場合、データベース サーバーは別の物理ノードで再起動されます。 復旧時間 (RTO) は、障害発生時のアクティビティ (大規模なトランザクションなど) や、データベース サーバーの起動プロセス中に実行される復旧の量などを含め、さまざまな要因によって異なります。 PostgreSQL データベースを使用するアプリケーションは、切断された接続や失敗したトランザクションを検出し、再試行するように構築されている必要があります。 |
データベース サーバーの障害が検出されると、サーバーはスタンバイ サーバーにフェールオーバーされるため、ダウンタイムが短縮されます。 詳細については、[HA 概念ページ]/azure/reliability/reliability-postgresql-flexible-server を参照してください。 RTO は 60 秒から 120 秒で、データ損失はないものと予想されます。 |
| ストレージの障害 | アプリケーションは、ディスク障害や物理ブロックの破損など、ストレージ関連の問題の影響を一切認識しません。 データが 3 つのコピーに格納されるので、データのコピーは存続しているストレージから提供されます。 破損したデータ ブロックは自動的に修復され、データの新しいコピーが自動的に作成されます。 | ストレージ全体にアクセスできなくなるような、まれに発生する復旧不可能なエラーの場合は、ダウンタイムを短縮するため、Azure Database for PostgreSQL フレキシブル サーバー インスタンスがスタンバイ レプリカにフェールオーバーされます。 詳細については、[HA 概念ページ]/azure/reliability/reliability-postgresql-flexible-server を参照してください。 |
| 論理/ユーザー エラー | テーブルの偶発的な削除や、データの誤った更新などの、ユーザー エラーから復旧するには、ポイントインタイム リストア (PITR) を実行する必要があります。 復元操作の実行中に、カスタム復元ポイントとして、エラーが発生した直前の時刻を指定します。 データベース サーバー内のすべてのデータベースではなく、データベースまたは特定のテーブルのサブセットのみを復元する場合は、新しいインスタンスでデータベース サーバーを復元し、pg_dump を使用してテーブルをエクスポートし、pg_restore を使用してそれらのテーブルをデータベースに復元することができます。 |
すべての変更はスタンバイ レプリカに同期的にレプリケートされるため、これらのユーザー エラーは高可用性では保護されません。 このようなエラーから復旧するには、ポイントインタイム リストアを実行する必要があります。 |
| 可用性ゾーンの障害 | ゾーンレベルの障害から復旧するには、バックアップを使用し、復元する最新時刻でカスタム復元ポイントを選択してポイントインタイム リストアを実行し、最新のデータを復元することができます。 新しい Azure Database for PostgreSQL フレキシブル サーバー インスタンスが、影響を受けていない別のゾーンにデプロイされます。 復元にかかる時間は、前回のバックアップと、復旧するトランザクション ログの量によって異なります。 | Azure Database for PostgreSQL フレキシブル サーバー インスタンスは、60 から 120 秒以内にスタンバイ サーバーに自動的にフェールオーバーされ、データ損失は発生しません。 詳細については、[HA 概念ページ]/azure/reliability/reliability-postgresql-flexible-server を参照してください。 |
| リージョンの障害 | サーバーが geo 冗長バックアップを使用して構成されている場合は、ペアになっているリージョンで geo リストアを実行できます。 新しいサーバーがプロビジョニングされ、このリージョンにコピーされた使用可能な最後のデータに復旧されます。 リージョンにまたがる読み取りレプリカも使用できます。 リージョンで障害が発生した場合、読み取りレプリカを昇格させてスタンドアロンの読み取り/書き込み可能サーバーにすることで、ディザスター リカバリー操作を実行できます。 RPO は最長 5 分と予想されます (データ損失の可能性あり)。ただし、重大なリージョン障害が発生した場合を除きます。この場合、RPO は障害発生時のレプリケーション ラグに近くなる可能性があります。 |
同じプロセス。 |
リージョン障害からの復旧後にデータベースを構成する
- geo リストアまたは geo レプリカを使用して停止から復旧する場合は、通常のアプリケーション機能を再開できるように新しいサーバーへの接続が適切に構成されていることを確認する必要があります。 復元後のタスクを進めることができます。
- 以前に元のサーバーで診断設定を設定したことがある場合は、「 Azure Database for PostgreSQL のログの構成とアクセス」で説明されているように、必要に応じてターゲット サーバーで同じ操作を行ってください。
- テレメトリ アラートを設定して、既存のアラート ルールの設定を更新し、新しいサーバーにマップされるようにする必要があります。 アラート ルールの詳細については、「 Azure portal を使用して Azure Database for PostgreSQL のメトリックにアラートを設定する」を参照してください。
重要
削除されたサーバーを復元することはできません。 サーバーを削除した場合は、復旧するために 削除された Azure データベースの復元 に関するガイダンスに従うことができます。 Azure リソース ロックを使用すると、サーバーが誤って削除されるのを防ぐことができます。