適用対象:  Azure Database for PostgreSQL - フレキシブル サーバー
Azure Database for PostgreSQL - フレキシブル サーバー
pg_dump を使用して、PostgreSQL データベースをダンプ ファイルに抽出することができます。 データベースを復元する方法は、選択したダンプの形式によって異なります。 ダンプがプレーン形式 (規定の -Fp であり、特定のオプションを指定する必要がない) で取得される場合、それを復元するための唯一のオプションは、プレーンテキスト ファイルを出力する psql を使用することです。 他の 3 つのダンプ方法 (カスタム、ディレクトリ、tar) では、pg_restore を使用する必要があります。
重要
この記事で説明する手順とコマンドは、bash ターミナルで実行するように設計されています。 これには、Linux 用 Windows サブシステム (WSL)、Azure Cloud Shell、その他の bash と互換性のあるインターフェイスなどの環境が含まれます。 このガイドで説明する手順に従いコマンドを実行する際には、必ず bash ターミナルを使用するようにしてください。 異なる種類のターミナルやシェル環境を使用すると、コマンドの動作が変わる場合があり、意図した結果が得られない可能性があります。
この記事では、プレーン (既定) とディレクトリの形式について説明します。 処理に複数のコアを使用できるディレクトリの形式の場合、効率を大幅に向上できるため、特に大規模なデータベースの場合で便利です。
Azure portal の [接続] ブレードを使用してこのプロセスを効率化することが可能であり、ここから、値がユーザー データに置き換えた状態で提供される、サーバーに合わせて調整された事前構成済みのコマンドを利用できます。 [接続] ブレードは Azure DB for PostgreSQL - フレキシブル サーバーでのみ使用でき、単一サーバーでは使用できないことに注意してください。 この機能を使用する方法を次に示します。
Azure portal にアクセスする: まず、Azure portal に移動して、[接続] ブレードを選択します。
![Azure portal の [接続] ブレードの配置を示すスクリーンショット。](media/how-to-migrate-using-dump-and-restore/portal-connect-blade.png)
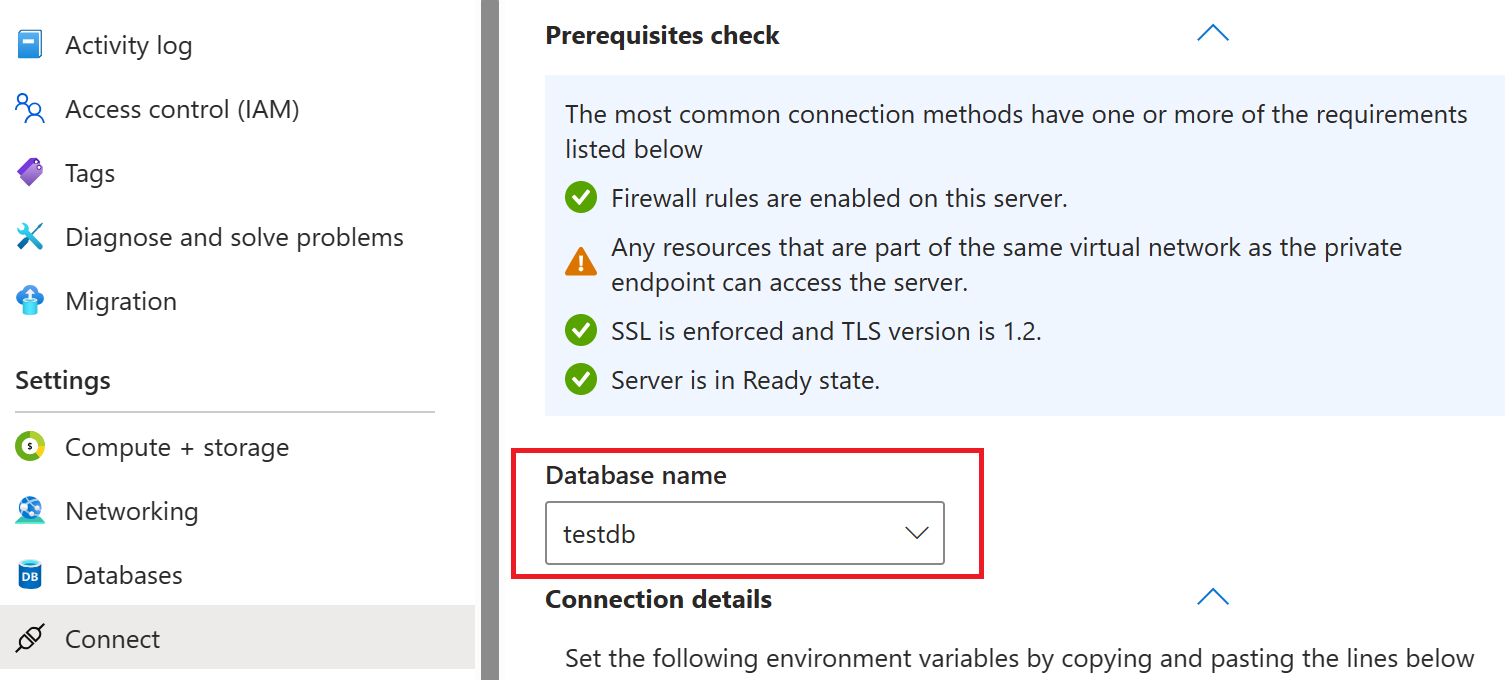
データベースを選択する: [接続] ブレードに、データベースのドロップダウン リストが表示されます。 ダンプを実行するデータベースを選択します。
適切な方法を選択する: データベースのサイズに応じて、次の 2 つの方法から選択できます。
pg_dump&psql- 単一のテキスト ファイルを使用する: 小規模なデータベースに最適です。このオプションでは、ダンプと復元のプロセスに単一のテキスト ファイルを使用します。pg_dump&pg_restore- 複数のコアを使用する: この方法の場合、ダンプと復元のプロセスの処理に複数のコアを使用できるため、大規模なデータベースの場合でより効率的になります。
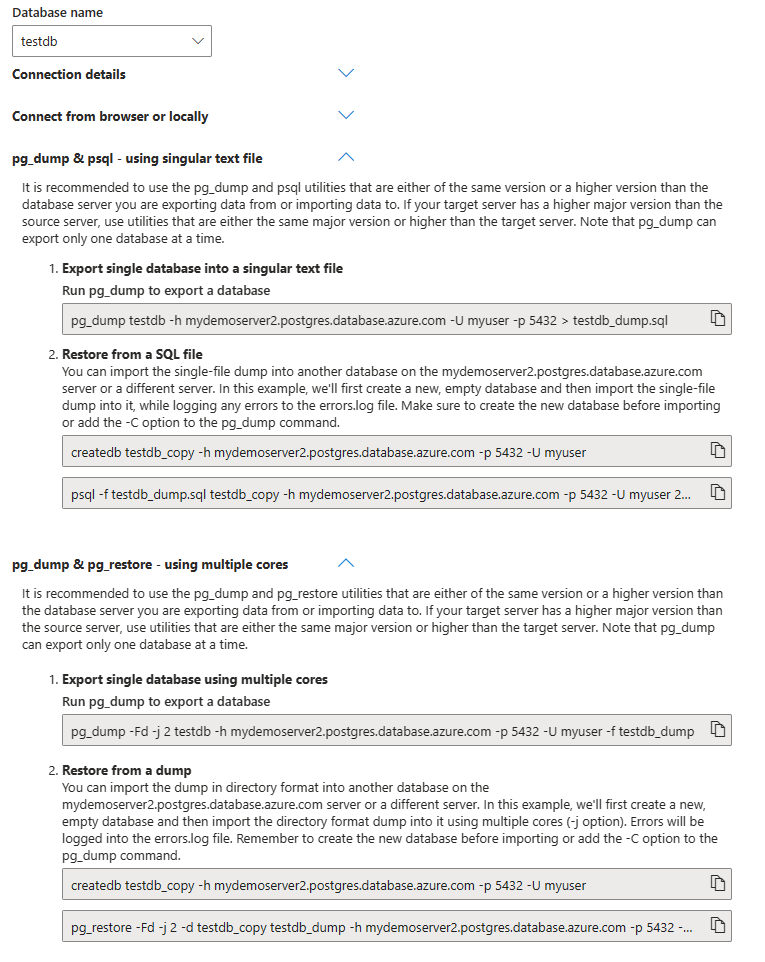
コマンドをコピーして貼り付ける: ポータルには、すぐに使用できる
pg_dumpおよびpsqlコマンド、あるいはpg_restoreコマンドが用意されています。 これらのコマンドには、選択したサーバーとデータベースに応じて置き換えられた後の値が含まれています。 これらのコマンドをコピーして貼り付けます。
![Azure portal の [接続] ブレードの配置を示すスクリーンショット。](media/how-to-migrate-using-dump-and-restore/portal-connect-blade.png#lightbox)


前提条件
単一サーバーを使用している場合、またはフレキシブル サーバー ポータルへのアクセス権がない場合、このドキュメント ページを参照してください。 ポータルのフレキシブル サーバーの [接続] ブレードに表示される情報と似た情報が含まれます。
Note
pg_dump、psql、pg_restore および pg_dumpall ユーティリティはすべて libpq に依存しているため、これが提供するサポートされている環境変数のいずれかを使用するか、パスワード ファイルを使用することで、これらのコマンドを実行するたびにパスワードを求められることを防ぐことができます。
このハウツー ガイドの手順を実行するには、以下が必要です。
- アクセスを許可するファイアウォール規則のある Azure Database for PostgreSQL サーバー。
- pg_dump、psql、pg_restore、pg_dumpall。ロールとアクセス許可、コマンド ライン ユーティリティをインストールした状態で移行する場合。
- ダンプの場所を決定する: ダンプを実行する場所を選択します。 これは、別の VM、 Cloud Shell (コマンド ライン ユーティリティは既にインストールされているものの、適切なバージョンではない可能性があります。そのため、
psql --versionなどを使用してバージョンを常にチェックしてください)、自分のノート PC など、さまざまな場所から実行できます。 PostgreSQL サーバーとダンプや復元を実行する場所との間の距離と待ち時間を、常に考慮するようにしてください。
重要
データのエクスポート元またはデータのインポート先として使用するデータベース サーバーと同じメジャー バージョンまたは上位のメジャー バージョンの pg_dump、psql、pg_restore、pg_dumpall ユーティリティを使用することが重要です。 これを行わないと、データの移行に失敗する可能性があります。 ターゲット サーバーのメジャー バージョンがソース サーバーよりも上位である場合は、ターゲット サーバーと同じメジャー バージョンまたはそれより上のユーティリティを使用します。
Note
pg_dump は、一度に 1 つのデータベースしかエクスポートできないので注意してください。 この制限は、選択した方法に関係なく、単一のファイルまたは複数のコアを使用しているかどうかに関係なく適用されます。
pg_dumpall -r を使用したユーザーとロールのダンプ
pg_dump は、PostgreSQL データベースをダンプ ファイルに抽出するために使用されます。 ただ、pg_dump はロールやユーザー定義をダンプしないため、これを把握することが重要です。これらは、PostgreSQL 環境内のグローバル オブジェクトとみなされます。 ユーザーとロールを含む包括的な移行の場合は、pg_dumpall -r を使用する必要があります。
このコマンドを使用すると、PostgreSQL 環境からすべてのロールとユーザーの情報をキャプチャできます。 同じサーバー上のデータベース内で移行する場合は、この手順を省略して、「新しいデータベースの作成」のセクションに移動してください。
pg_dumpall -r -h <server name> -U <user name> > roles.sql
たとえば、サーバーの名前が mydemoserver で、ユーザーの名前が myuser の場合、次のコマンドを実行します。
pg_dumpall -r -h mydemoserver.postgres.database.azure.com -U myuser > roles.sql
単一サーバーを使用している場合、ユーザー名にはサーバー名コンポーネントが含まれます。 そのため、myuser の代わりに myuser@mydemoserver を使用します。
フレキシブル サーバーからのロールのダンプ
フレキシブル サーバー環境の場合はセキュリティ対策が強化されているため、ユーザーは、ロール パスワードが格納されている pg_authid テーブルにアクセスできません。 標準の pg_dumpall -r コマンドは、このテーブルへのアクセスを試みてパスワードを取得しようとしますが、アクセス許可がないため失敗します。そのため、この制限がどのようにロール ダンプを実行するかに影響します。
フレキシブル サーバーからロールをダンプする場合は、pg_dumpall コマンドに --no-role-passwords オプションを含める必要があります。 このオプションは、セキュリティ制限のために読み取ることができない pg_authid テーブルへのアクセスを pg_dumpall が試みることを防止します。
フレキシブル サーバーからロールを正常にダンプするには、次のコマンドを使用します。
pg_dumpall -r --no-role-passwords -h <server name> -U <user name> > roles.sql
たとえば、サーバーの名前が mydemoserver で、ユーザーの名前が myuser の場合、次のコマンドを実行します。
pg_dumpall -r --no-role-passwords -h mydemoserver.postgres.database.azure.com -U myuser > roles.sql
ロール ダンプのクリーンアップ
移行時、出力ファイル roles.sql には、新しい環境では適用できない、または許容されない特定のロールや属性が含まれている可能性があります。 考慮すべきことを次に示します。
スーパーユーザーによってのみ設定できる属性を削除する: スーパーユーザーの特権がない環境に移行する場合、ロール ダンプから
NOSUPERUSERやNOBYPASSRLSなどの属性を削除します。サービス固有のユーザーを除外する:
azure_superuserやazure_pg_adminなどの単一サーバー サービス ユーザーを除外します。 これらはサービスに固有であり、新しい環境で自動的に作成されます。
次の sed コマンドを使用してロール ダンプをクリーンアップします。
sed -i '/azure_superuser/d; /azure_pg_admin/d; /azuresu/d; /^CREATE ROLE replication/d; /^ALTER ROLE replication/d; /^ALTER ROLE/ {s/NOSUPERUSER//; s/NOBYPASSRLS//;}' roles.sql
このコマンドは、azure_superuser、azure_pg_admin、azuresu を含む行、CREATE ROLE replication、ALTER ROLE replication で始まる行を削除し、NOSUPERUSER および NOBYPASSRLS 属性を ALTER ROLE ステートメントから削除します。
読み込まれるデータを格納するダンプ ファイルを作成する
オンプレミスまたは VM 内にある既存の PostgreSQL データベースを SQL スクリプト ファイルにエクスポートするには、既存の環境で次のコマンドを実行します。
pg_dump <database name> -h <server name> -U <user name> > <database name>_dump.sql
たとえば、サーバーの名前が mydemoserver、ユーザーの名前が myuser、データベースの名前が testdb の場合、次のコマンドを実行します。
pg_dump testdb -h mydemoserver.postgres.database.azure.com -U myuser > testdb_dump.sql
単一サーバーを使用している場合、ユーザー名にはサーバー名コンポーネントが含まれます。 そのため、myuser の代わりに myuser@mydemoserver を使用します。
ターゲット データベースにデータを復元する
ロールとユーザーの復元
データベース オブジェクトを復元する前に、ロールを適切にダンプしてクリーンアップできていることを確認してください。 同じサーバー上のデータベース内で移行する場合、ロールのダンプと復元の両方が必要ない場合があります。 ただし、異なるサーバーまたは環境間での移行の場合、この手順は非常に重要です。
ロールとユーザーをターゲット データベースに復元するには、次のコマンドを使用します。
psql -f roles.sql -h <server_name> -U <user_name>
<server_name> をターゲット サーバーの名前に置き換え、<user_name> をユーザー名に置き換えます。 このコマンドは、psql ユーティリティを使用して roles.sql ファイルに含まれる SQL コマンドを実行し、ロールとユーザーをターゲット データベースに効果的に復元します。
たとえば、サーバーの名前が mydemoserver で、ユーザーの名前が myuser の場合、次のコマンドを実行します。
psql -f roles.sql -h mydemoserver.postgres.database.azure.com -U myuser
単一サーバーを使用している場合、ユーザー名にはサーバー名コンポーネントが含まれます。 そのため、myuser の代わりに myuser@mydemoserver を使用します。
Note
移行元の単一サーバーまたはオンプレミス サーバーとターゲット サーバーに同じ名前のユーザーがすでに存在する場合、この復元プロセスによってこれらのロールのパスワードが変更される可能性があることに注意してください。 そのため、実行する必要がある後続のコマンドを実行するために、更新後のパスワードを使用しなければならなくなる可能性があります。 これは、ソース サーバーがフレキシブル サーバーの場合は適用されません。フレキシブル サーバーでは、セキュリティ対策が強化されているため、ユーザーのパスワードをダンプできません。
新しい データベースを作成します。
データベースを復元する前に、新しい空のデータベースを作成することが必要になる場合があります。 これを行うには、使用しているユーザーに CREATEDB アクセス許可が必要です。 一般的に使用される 2 つの方法を以下に示します。
createdbユーティリティを使用するcreatedbプログラムを使用すると、PostgreSQL にログインしたり、オペレーティング システム環境から離れたりすることなく、bash コマンド ラインから直接データベースを作成できます。 次に例を示します。createdb <new database name> -h <server name> -U <user name>たとえば、サーバーの名前が
mydemoserver、ユーザーの名前がmyuserの場合で、作成する新しいデータベースがtestdb_copyの場合、次のコマンドを実行します。createdb testdb_copy -h mydemoserver.postgres.database.azure.com -U myuser単一サーバーを使用している場合、ユーザー名にはサーバー名コンポーネントが含まれます。 そのため、
myuserの代わりにmyuser@mydemoserverを使用します。SQL コマンドを使用する SQL コマンドを使用してデータベースを作成するには、コマンド ライン インターフェイスまたはデータベース管理ツールを使用して PostgreSQL サーバーに接続する必要があります。 接続したら、次の SQL コマンドを使用して新しいデータベースを作成できます。
CREATE DATABASE <new database name>;
<new database name> は、新しいデータベースに付ける名前に置き換えます。 たとえば、testdb_copy という名前のデータベースを作成する場合、コマンドは次のようになります。
CREATE DATABASE testdb_copy;
ダンプの復元
ターゲット データベースを作成した後、ダンプ ファイルからこのデータベースにデータを復元できます。 復元中にエラーを errors.log ファイルに記録し、復元が完了した後にその内容を確認してエラーを調べます。
psql -f <database name>_dump.sql <new database name> -h <server name> -U <user name> 2> errors.log
たとえば、サーバーの名前が mydemoserver、ユーザーの名前が myuser、新しいデータベースの名前が testdb_copy の場合、次のコマンドを実行します。
psql -f testdb_dump.sql testdb_copy -h mydemoserver.postgres.database.azure.com -U myuser 2> errors.log
復元後のチェック
復元プロセスが完了した後に errors.log ファイルを確認して、エラーが発生しているかを確認することが重要です。 この手順は、復元されたデータの整合性と完全性を確保するために重要です。 データベースの信頼性を維持するために、ログ ファイルで見つかったすべての問題に対処します。
移行プロセスを最適化する
大規模なデータベースを扱う場合で、ダンプと復元のプロセスに時間がかかる場合があり、また、効率性と信頼性を確保するための最適化が必要になることがあります。 これらの操作のパフォーマンスに影響を与える可能性があるさまざまな要因に着目し、それらを最適化するための手順を実行することが重要です。
ダンプと復元のプロセスの最適化に関する詳細なガイダンスについては、「pg_dump と pg_restore のベスト プラクティス」の記事を参照してください。 このリソースでは、大規模なデータベースを扱う際に役立つ可能性のある包括的な情報と戦略を確認できます。
次のステップ
- pg_dump と pg_restore のベスト プラクティス。
- Azure Database for PostgreSQL へのデータベースの移行については、「Database Migration Guide」 (データベースの移行ガイド) を参照してください。