Microsoft Purview スキャンのベスト プラクティス
Microsoft Purview ガバナンス ソリューション は、オンプレミス、マルチクラウド、およびサービスとしてのソフトウェア (SaaS) データ ソースの自動スキャンをサポートします。
スキャンを実行すると、登録されたデータ ソースからメタデータを取り込むプロセスが呼び出されます。 スキャンとキュレーション プロセスの最後にキュレーションされたメタデータには、技術的なメタデータが含まれます。 このメタデータには、テーブル名やファイル名、ファイル サイズ、列、データ系列などのデータ資産名を含めることができます。 スキーマの詳細は、構造化データ ソースについてもキャプチャされます。 リレーショナル データベース管理システムは、この種類のソースの例です。
キュレーション プロセスは、構成されたスキャン ルール セットに基づいて、スキーマ属性に自動分類ラベルを適用します。 秘密度ラベルは、Microsoft Purview アカウントがMicrosoft Purview コンプライアンス ポータルに接続されている場合に適用されます。
重要
ストレージ アカウントの更新を妨げる Azure ポリシーがある場合は、Microsoft Purview のスキャン プロセスにエラーが発生します。 Microsoft Purview 例外タグ ガイドに従って、Microsoft Purview アカウントの例外を作成します。
データ ソースを管理するためにベスト プラクティスが必要な理由
ベスト プラクティスを使用すると、次の機能を利用できます。
- コストを最適化します。
- オペレーショナル エクセレンスを構築します。
- セキュリティ コンプライアンスを向上させます。
- パフォーマンス効率を向上させます。
ソースを登録し、接続を確立する
次の設計上の考慮事項と推奨事項は、ソースを登録して接続を確立するのに役立ちます。
設計上の考慮事項
- コレクションを使用して、地理的、ビジネス機能、データソースなど、organizationの戦略に合わせた階層を作成します。 階層は、登録およびスキャンするデータ ソースを定義します。
- 設計上、同じ Microsoft Purview アカウントにデータ ソースを複数回登録することはできません。 このアーキテクチャは、同じデータ ソースに異なるアクセス制御を割り当てるリスクを回避するのに役立ちます。
設計に関する推奨事項
同じデータ ソースのメタデータが複数のチームによって使用される場合は、親コレクションでデータ ソースを登録および管理できます。 その後、各サブコレクションの下に対応するスキャンを作成できます。 このようにして、関連する資産が各子コレクションの下に表示されます。 親を持たないソースは、マップ ビューの点線のボックスにグループ化されます。 矢印は両親にリンクしません。
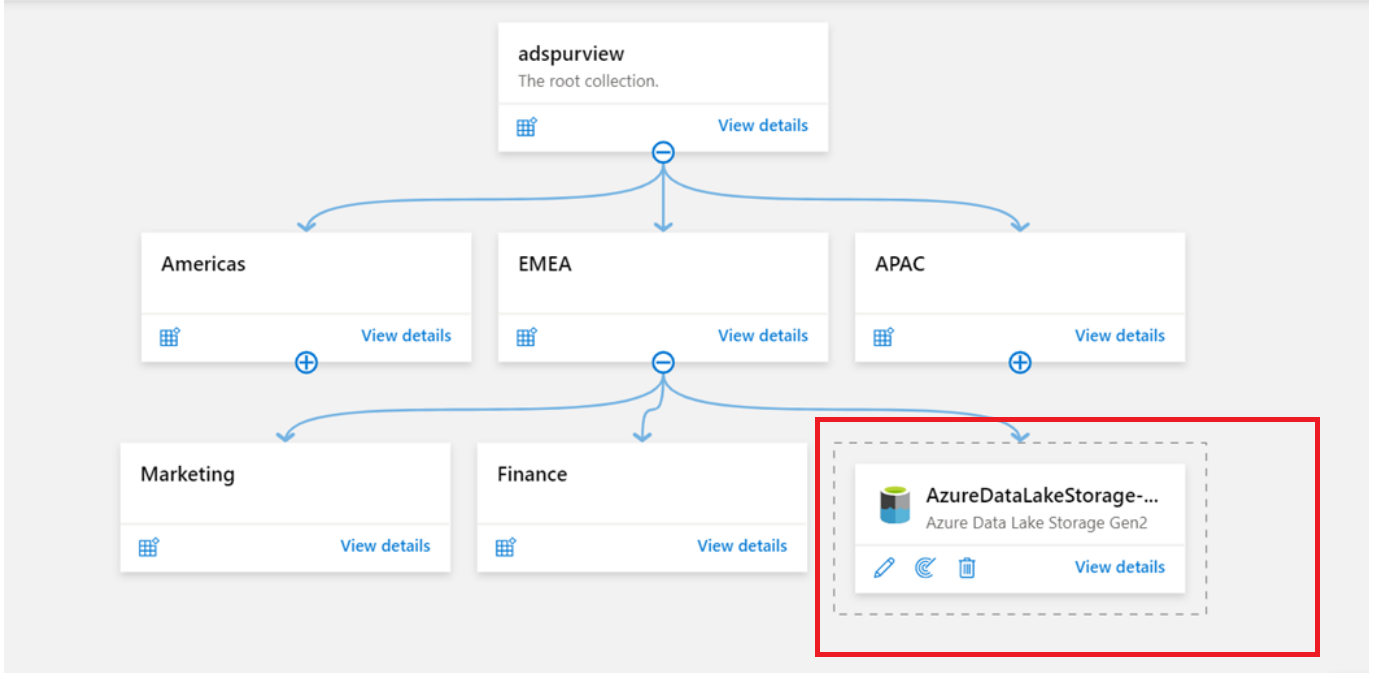
Azure サブスクリプションやリソース グループなどの複数のソースをクラウドに登録する必要がある場合は、Azure Multiple オプションを使用します。 詳細については、次のドキュメントを参照してください。
データ ソースが登録されると、同じソースがさまざまなチームまたは部署によって異なる方法で使用されている場合に備えて、同じソースを複数回スキャンできます。
データ ソースを登録するための階層を定義する方法の詳細については、「 コレクション アーキテクチャのベスト プラクティス」を参照してください。
スキャン
次の設計上の考慮事項と推奨事項は、スキャン プロセスに関連する重要な手順に基づいて編成されています。
設計上の考慮事項
- データ ソースが登録されたら、自動でセキュリティで保護されたメタデータのスキャンとキュレーションを管理するためのスキャンを設定します。
- スキャンのセットアップには、スキャンの名前、スキャンのスコープ、統合ランタイム、スキャン トリガーの頻度、スキャン ルール セット、およびリソース セットの構成が、スキャン頻度ごとにデータ ソースごとに一意に行われます。
- 資格情報を作成する前に、データ ソースの種類とネットワーク要件を検討してください。 この情報は、シナリオに必要な認証方法と統合ランタイムを決定するのに役立ちます。
設計に関する推奨事項
関連する コレクションにソースを登録したら、スキャンを設定するときにここに示されている順序を計画して従います。 このプロセス順序は、予期しないコストとやり直しを回避するのに役立ちます。

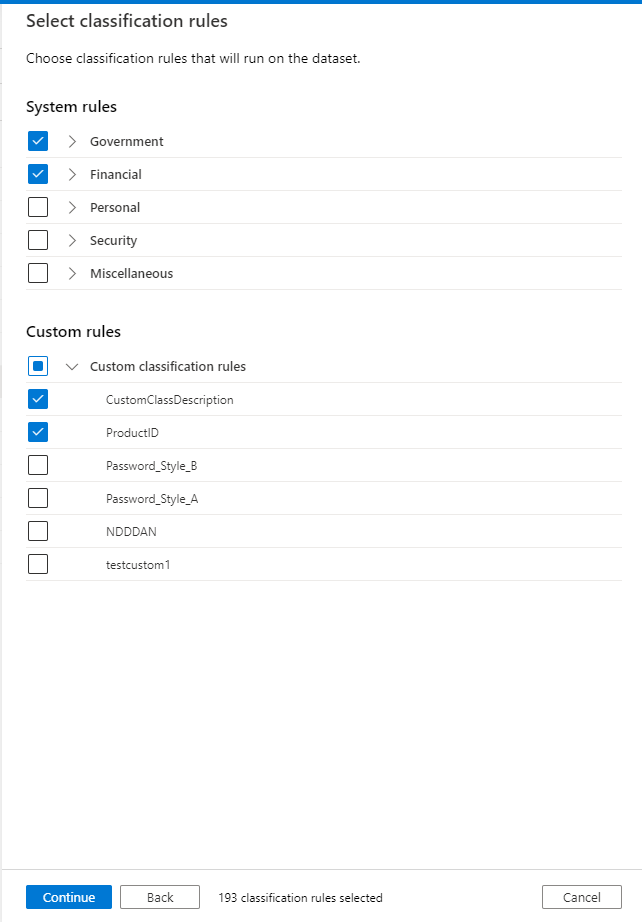
システムの組み込みの分類規則から分類要件を特定します。 または、必要に応じて、特定のカスタム分類ルールを作成することもできます。 特定の業界、ビジネス、または地域の要件に基づいて作成します。この要件は、すぐには使用できません。
- 分類の ベスト プラクティスを参照してください。
- カスタム分類と分類ルールを作成する方法を参照してください。
スキャンを構成する前に、スキャン ルール セットを作成します。
![[データ マップ] の [スキャン ルール セット] を示すスクリーンショット。](media/concept-best-practices/scanning-create-scan-rule-set.png)
スキャン ルール セットを作成するときは、次の点を確認します。
スキャンするデータ ソースに対して、システムの既定のスキャン 規則セットで十分かどうかを確認します。 それ以外の場合は、カスタム スキャン ルール セットを定義します。
カスタム スキャン ルール セットには、システムの既定値とカスタムの両方を含めることができるため、スキャン対象のデータ資産に関連しないオプションをクリアします。
必要に応じて、不要な分類ラベルを除外するカスタム ルール セットを作成します。 たとえば、システム ルール セットには、米国だけでなく、惑星の一般的な政府コード パターンが含まれています。 データは、"ベルギーの運転免許証番号" など、他の種類のパターンと一致する場合があります。
煩雑にならないように、カスタム分類ルールを 最も重要 で 関連する ラベルに制限します。 アセットにタグ付けされたラベルが多すぎないようにします。
カスタム分類またはスキャン ルール セットを変更すると、フル スキャンがトリガーされます。 再作業やコストのかかるフル スキャンを回避するために、分類とスキャン ルール セットを適切に構成します。
注:
ストレージ アカウントをスキャンすると、Microsoft Purview は、定義されたパターンのセットを使用して、資産のグループがリソース セットを形成するかどうかを判断します。 リソース セット パターン ルールを使用して、Microsoft Purview がリソース セットとしてグループ化されている資産を検出する方法をカスタマイズまたはオーバーライドできます。 また、ルールによって、カタログ内での資産の表示方法も決定されます。 詳細については、「 リソース セット パターン ルールの作成」を参照してください。 この機能にはコストに関する考慮事項があります。 詳細については、 価格に関するページを参照してください。
登録済みデータ ソースのスキャンを設定します。
スキャン名: 既定では、Microsoft Purview では SCAN -[A-Z][a-z][a-z] という名前付け規則が使用されます。これは、実行したスキャンを特定する場合には役に立ちません。 意味のある名前付け規則を使用してください。 たとえば、スキャン 環境-source-frequency-time に DEVODS-Daily-0200 という名前を付けます。 この名前は、0200 時間の毎日のスキャンを表します。
認証: Microsoft Purview では、ソースの種類に応じて、データ ソースをスキャンするためのさまざまな認証方法が提供されます。 Azure クラウド、オンプレミス、サード パーティのソースを使用できます。 認証方法の最小特権原則に従って、次の優先順位に従います。
- Microsoft Purview MSI - マネージド サービス ID (Azure Data Lake Storage Gen2 ソースなど)
- ユーザー割り当てマネージド ID
- サービス プリンシパル
- SQL 認証 (たとえば、オンプレミスまたはAzure SQL ソースの場合)
- アカウント キーまたは基本認証 (SAP S/4HANA ソースなど)
詳細については、 資格情報を管理するためのハウツー ガイドを参照してください。
注:
ストレージ アカウントに対してファイアウォールが有効になっている場合は、スキャンを設定するときにマネージド ID 認証方法を使用する必要があります。 新しい資格情報を設定する場合、資格情報名には 文字、数字、アンダースコア、ハイフンのみを含めることができます。
統合ランタイム
- 詳細については、「 ネットワーク アーキテクチャのベスト プラクティス」を参照してください。
- セルフホステッド統合ランタイム (SHIR) が削除された場合、それに依存する進行中のスキャンは失敗します。
- SHIR を使用する場合は、スキャンするデータ ソースのメモリで十分であることを確認します。 たとえば、SAP ソースのスキャンに SHIR を使用すると、"メモリ不足エラー" と表示される場合は、次のようになります。
- SHIR マシンに十分なメモリがあることを確認します。 推奨される量は 128 GB です。
- スキャン設定で、使用可能な最大メモリを適切な値 (100 など) として設定します。
- 詳細については、「 SAP ECC Microsoft Purview のスキャンと管理」の前提条件を参照してください。
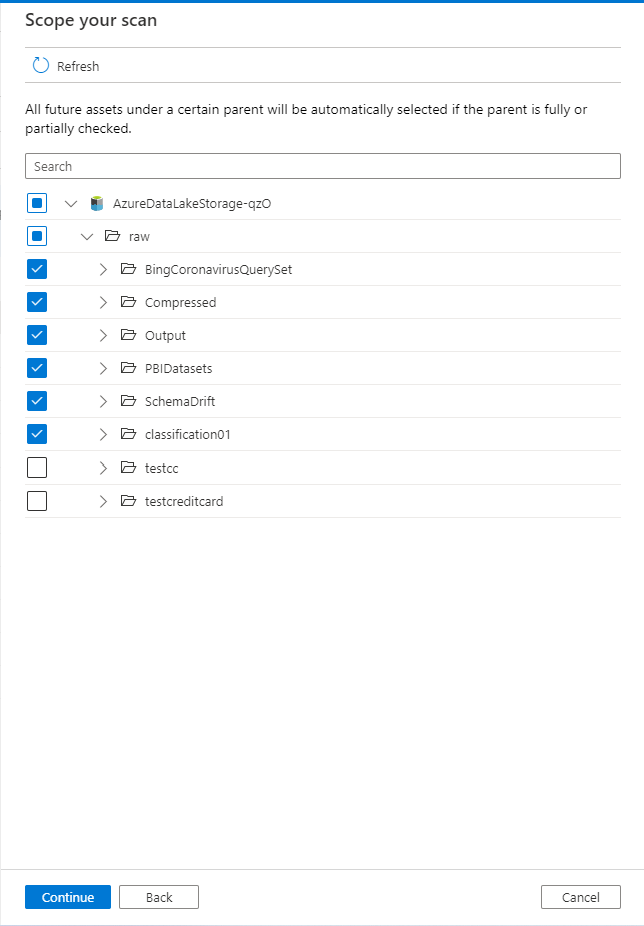
スコープ スキャン
スキャンのスコープを設定する場合は、詳細レベルまたは親レベルで関連する資産のみを選択します。 この方法により、スキャン コストが最適であり、パフォーマンスが効率的になります。 親が完全または部分的にチェックされている場合、特定の親の下のすべての将来の資産が自動的に選択されます。
一部のデータ ソースの例を次に示します。
- データベースまたはData Lake Storage Gen2 Azure SQLの場合は、データ ソースの特定の部分にスキャンのスコープを設定できます。 フォルダー、サブフォルダー、コレクション、スキーマなど、リスト内の適切な項目を選択します。
- Oracle、Hive メタストア データベース、Teradata ソースの場合、エクスポートするスキーマの特定のリストは、SQL LIKE 式を使用してセミコロンで区切られた値またはスキーマ名パターンを使用して指定できます。
- Google Big クエリでは、エクスポートするデータセットの特定のリストをセミコロンで区切って指定できます。
- AWS アカウント全体のスキャンを作成する場合は、スキャンする特定のバケットを選択できます。 特定の AWS S3 バケットのスキャンを作成するときに、スキャンする特定のフォルダーを選択できます。
- Erwin の場合は、Erwin モデル ロケーター文字列のセミコロン区切りのリストを指定することで、スキャンのスコープを設定できます。
- Cassandra の場合、エクスポートするキースペースの特定のリストは、セミコロンで区切られた値または SQL LIKE 式を使用してキースペースの名前パターンを使用して指定できます。
- Looker の場合、スキャンの範囲を指定するには、セミコロンで区切られた Looker プロジェクトの一覧を指定します。
- Power BI テナントの場合は、個人用ワークスペースを含めるか除外するかを指定するだけです。
一般に、ワイルドカード (データ レイクなど) に基づいてサポートされている "無視パターン" を使用して、一時、構成ファイル、RDBMS システム テーブル、バックアップテーブルまたは STG テーブルを除外します。
ドキュメントや非構造化データをスキャンする場合は、そのようなドキュメントの膨大な数をスキャンしないようにします。 スキャンでは、このようなドキュメントの最初の 20 MB が処理され、スキャン期間が長くなる可能性があります。
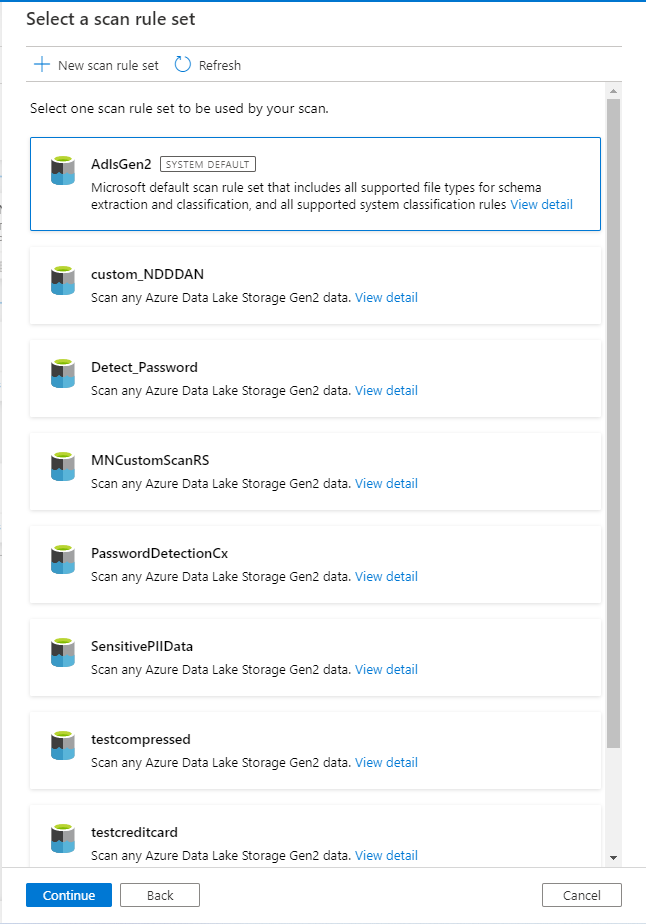
スキャン ルール セット
- スキャン ルール セットを選択するときは、先ほど作成した関連システムまたはカスタム スキャン ルール セットを必ず構成してください。
- カスタム ファイルタイプを作成し、それに応じて詳細を入力できます。 現在、Microsoft Purview では、カスタム区切り記号でサポートされている文字は 1 つだけです。 実際のデータで ~などのカスタム区切り記号を使用する場合は、新しいスキャン ルール セットを作成する必要があります。
スキャンの種類とスケジュール
- スキャン プロセスは、完全スキャンまたは増分スキャンを実行するように構成できます。
- ビジネス以外またはピーク時以外の時間帯にスキャンを実行して、ソースに対する処理オーバーロードを回避します。
- で繰り返しを開始 するには、 スケジュール スキャン時間より少なくとも 1 分短くする必要があります。それ以外の場合は、次回の繰り返しでスキャンがトリガーされます。
- 初期スキャンはフル スキャンであり、後続のスキャンはすべて増分です。 後続のスキャンは、定期的な増分スキャンとしてスケジュールできます。
- スキャンの頻度は、データ ソースまたはビジネス要件の変更管理スケジュールと一致している必要があります。 例:
- ソース構造が毎週変更される可能性がある場合は、スキャン頻度を同期する必要があります。変更には、追加、変更、または削除された資産内の新しい資産またはフィールドが含まれます。
- 分類ラベルまたは秘密度ラベルが、規制上の理由から、週単位で最新であることが予想される場合は、スキャン頻度を毎週にする必要があります。 たとえば、パーティション ファイルがソース データ レイクに毎週追加される場合は、毎月のスキャンをスケジュールできます。 メタデータに変更がないため、毎週のスキャンをスケジュールする必要はありません。 この提案では、新しい分類シナリオがないことを前提としています。
- スキャンが作成された日と同じ日に実行されるようにスケジュールする場合、開始時刻は少なくとも 1 分前のスキャン時刻である必要があります。
- スキャンを実行できる最大期間は 7 日間です。メモリの問題が原因である可能性があります。 この期間は、インジェスト プロセスを除外します。 7 日後に進行状況が更新されていない場合、スキャンは失敗としてマークされます。 現在、インジェスト (カタログへの) プロセスにはそのような制限はありません。
スキャンの取り消し
- 現在、スキャンをキャンセルまたは一時停止できるのは、スキャンをトリガーした後にスキャンの状態が "キューに入っている" 状態に移行した場合のみです。
- 個々の子スキャンの取り消しはサポートされていません。
注意すべき点
- スキャンの実行後にフィールドまたは列、テーブル、またはファイルがソース システムから削除された場合、次にスケジュールされた完全スキャンまたは増分スキャンの後にのみ Microsoft Purview に反映 (削除) されます。
- 資産は、資産の名前の下にある [削除 ] アイコンを使用して、Microsoft Purview カタログから削除できます。 このアクションでは、ソース内のオブジェクトは削除されません。 同じソースでフル スキャンを実行すると、カタログに再び取り込まれます。 代わりに週単位または月単位のスキャン (増分) をスケジュールした場合、オブジェクトがソースで変更されない限り、削除された資産は選択されません。 たとえば、列がテーブルに追加または削除された場合です。
- Microsoft Purview ガバナンス ポータルを使用してデータ資産または基になるスキーマを 手動で 編集した後の後続のスキャンの動作を理解するには、「 カタログ資産の詳細」を参照してください。
- 詳細については、 資産を表示、編集、削除する方法に関するチュートリアルを参照してください。
次の手順
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示