Microsoft Purview でのスキャンとインジェスト
この記事では、Microsoft Purview のスキャン機能とインジェスト機能の概要について説明します。 これらの機能は、Microsoft Purview アカウントをソースに接続してデータ マップとデータ カタログを設定するため、Microsoft Purview を使用してデータの探索と管理を開始できます。
- スキャンは、データ ソースからメタデータをキャプチャし、Microsoft Purview に移動します。
- インジェスト はメタデータを処理し、両方からデータ カタログに格納します。
- データ ソース スキャン - スキャンされたメタデータがMicrosoft Purview データ マップに追加されます。
- 系列接続 - 変換リソースは、ソース、出力、アクティビティに関するメタデータをMicrosoft Purview データ マップに追加します。
スキャン
データ ソースが Microsoft Purview アカウントに 登録されたら 、次の手順としてデータ ソースをスキャンします。 スキャン プロセスでは、データ ソースへの接続が確立され、名前、ファイル サイズ、列などの技術的なメタデータがキャプチャされます。 また、構造化データ ソースのスキーマを抽出し、スキーマに分類を適用し、Microsoft Purview データ マップがMicrosoft Purview コンプライアンス ポータルに接続されている場合は秘密度ラベルを適用します。 スキャン プロセスは、すぐに実行するようにトリガーすることも、Microsoft Purview アカウントを最新の状態に保つために定期的に実行するようにスケジュールすることもできます。
スキャンごとに、ソース全体ではなく、必要な情報のみをスキャンできるように、適用できるカスタマイズがあります。
スキャンの認証方法を選択する
Microsoft Purview は既定でセキュリティで保護されています。 パスワードやシークレットは Microsoft Purview に直接保存されないため、ソースの認証方法を選択する必要があります。 Microsoft Purview アカウントを認証する方法はいくつかありますが、データ ソースごとにすべての方法がサポートされているわけではありません。
- マネージド ID
- サービス プリンシパル
- SQL 認証
- Windows 認証
- ロール ARN
- 委任された認証
- コンシューマー キー
- アカウント キーまたは基本認証
可能な限り、マネージド ID は、個々のデータ ソースの資格情報を格納および管理する必要がないため、推奨される認証方法です。 これにより、スキャンの認証の設定とトラブルシューティングに費やす時間を大幅に短縮できます。 Microsoft Purview アカウントのマネージド ID を有効にすると、ID が Azure Active Directory に作成され、アカウントのライフサイクルに関連付けられます。
スキャンのスコープを設定する
ソースをスキャンするときは、データ ソース全体をスキャンするか、スキャンする特定のエンティティ (フォルダー/テーブル) のみを選択するかを選択できます。 使用可能なオプションは、スキャンするソースによって異なります。また、1 回限りのスキャンとスケジュールされたスキャンの両方に対して定義できます。
たとえば、Azure SQL データベースのスキャンを作成して実行する場合、スキャンするテーブルを選択したり、データベース全体を選択したりできます。
エンティティ (フォルダー/テーブル) ごとに、3 つの選択状態があります。完全に選択され、部分的に選択され、選択されていません。 次の例では、フォルダー階層で [部署 1] を選択すると、"部署 1" が完全に選択されていると見なされます。 "Company" や "example" などの "Department 1" の親エンティティは、同じ親の下に他のエンティティが選択されていないため、部分的に選択されていると見なされます (例: "Department 2")。 選択状態が異なるエンティティの UI では、さまざまなアイコンが使用されます。
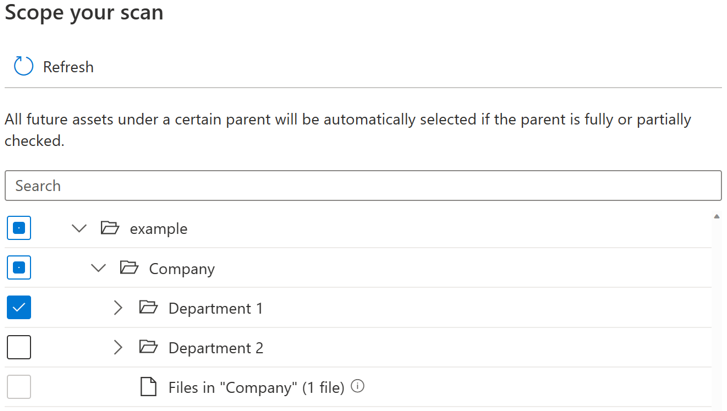
スキャンを実行すると、ソース システムに新しい資産が追加される可能性があります。 既定では、スキャンを再実行するときに親が完全または部分的に選択されている場合、特定の親の下の将来の資産が自動的に選択されます。 上の例では、"部署 1" を選択してスキャンを実行した後、スキャンを再実行すると、フォルダー "Department 1" または "Company" と "example" の下に新しい資産が含まれます。
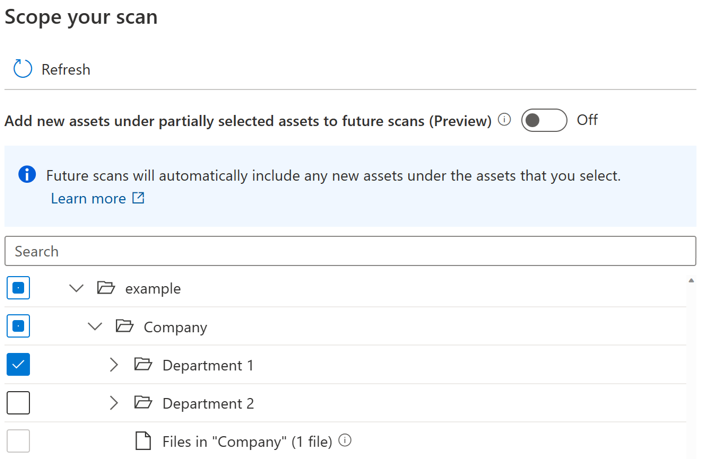
部分的に選択された親の下の新しい資産の自動包含をユーザーが制御するためのトグル ボタンが導入されました。 既定では、トグルはオフになり、部分的に選択された親の自動包含動作は無効になります。 トグルがオフになっている同じ例では、"Company" や "example" などの部分的に選択された親の新しい資産は、スキャンを再実行しても含まれず、"Department 1" の下の新しい資産のみが将来のスキャンに含まれます。
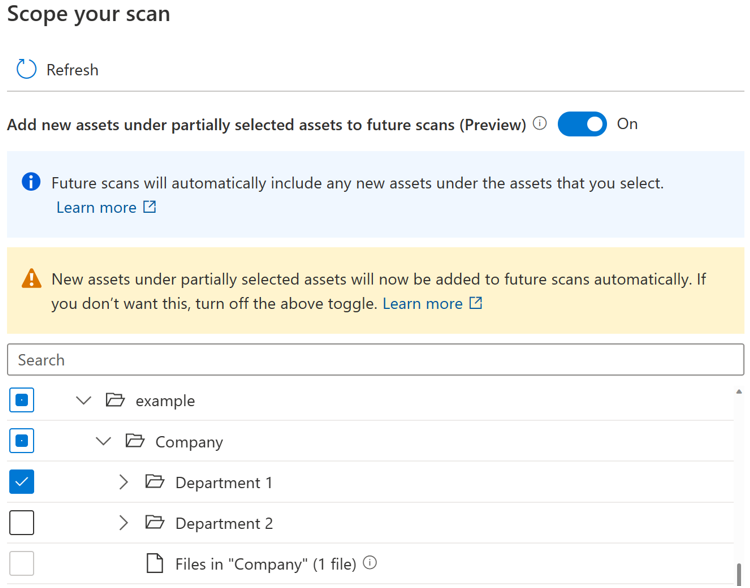
切り替えボタンがオンになっている場合、スキャンを再度実行するときに親が完全または部分的に選択されている場合、特定の親の下の新しいアセットが自動的に選択されます。 包含動作は、トグル ボタンが導入される前と同じになります。
注:
- トグル ボタンの可用性は、データ ソースの種類によって異なります。 現在、Azure Blob Storage、Azure Data Lake Storage Gen 1、Azure Data Lake Storage Gen 2、Azure Files、Azure Dedicated SQL プール (旧称 SQL DW) を含むソースのパブリック プレビューで使用できます。
- 切り替えボタンが導入される前に作成またはスケジュールされたスキャンの場合、トグル状態はオンに設定され、変更できません。 トグル ボタンが導入された後に作成またはスケジュールされたスキャンの場合、スキャンの保存後にトグル状態を変更することはできません。 トグル状態を変更するには、新しいスキャンを作成する必要があります。
- 切り替えボタンをオフにすると、Gen 2 などのストレージの種類のソースAzure Data Lake Storageスキャン ジョブが完了した後、ソースの種類による参照エクスペリエンスが完全に使用できるようになるまで最大で 4 時間かかることがあります。
既知の制限
トグル ボタンがオフになっている場合:
- 部分的に選択された親の下のファイル エンティティはスキャンされません。
- 親の下にあるすべての既存のエンティティが明示的に選択されている場合、親は完全に選択されたと見なされ、スキャンを再実行すると親の下の新しい資産が含まれます。
スキャン ルール セット
スキャン ルール セットは、スキャンがソースのいずれかに対して実行されているときに検索する情報の種類を決定します。 使用可能なルールは、スキャンするソースの種類によって異なりますが、スキャンするファイルの 種類 や必要な 分類 の種類などが含まれます。
多くのデータ ソースの種類で既に使用できるシステム スキャン ルール セットがありますが、スキャンをorganizationに合わせて調整するために独自のスキャン ルール セットを作成することもできます。
スキャンをスケジュールする
Microsoft Purview では、選択した特定の時刻に毎週または毎月のスキャンを選択できます。 毎週のスキャンは、開発中または頻繁に変更される構造を持つデータ ソースに適している場合があります。 月単位のスキャンは、変更頻度の低いデータ ソースに適しています。 ベスト プラクティスは、スキャンするソースの管理者と連携して、ソースに対するコンピューティング需要が低い時刻を特定することです。
スキャンで削除された資産を検出する方法
Microsoft Purview カタログは、スキャンの実行時にのみデータ ストアの状態を認識します。 カタログは、ファイル、テーブル、またはコンテナーが削除されたかどうかを把握するために、最後のスキャン出力と現在のスキャン出力を比較します。 たとえば、最後にAzure Data Lake Storage Gen2 アカウントをスキャンした場合、folder1 という名前のフォルダーが含まれていたとします。 同じアカウントが再度スキャンされると、 folder1 が見つかりません。 そのため、カタログはフォルダーが削除されていることを前提としています。
削除されたファイルの検出
不足しているファイルを検出するためのロジックは、同じユーザーと異なるユーザーによる複数のスキャンに対して機能します。 たとえば、ユーザーがフォルダー A、B、C のData Lake Storage Gen2 データ ストアで 1 回限りのスキャンを実行するとします。その後、同じアカウント内の別のユーザーが、同じデータ ストアのフォルダー C、D、E で異なる 1 回限りのスキャンを実行します。 フォルダー C が 2 回スキャンされたため、カタログによって削除の可能性がチェックされます。 ただし、フォルダー A、B、D、E は 1 回だけスキャンされ、カタログは削除された資産をチェックしません。
削除されたファイルをカタログから除外するには、定期的なスキャンを実行することが重要です。 カタログは、別のスキャンが実行されるまで削除された資産を検出できないため、スキャン間隔は重要です。 そのため、特定のストアで月に 1 回スキャンを実行した場合、カタログは、1 か月後に次のスキャンを実行するまで、そのストア内の削除されたデータ資産を検出できません。
Data Lake Storage Gen2のような大きなデータ ストアを列挙する場合、情報を見逃す方法は複数あります (列挙エラーや破棄されたイベントを含む)。 特定のスキャンでは、ファイルが作成または削除されたことが見逃される可能性があります。 そのため、カタログが特定のファイルが削除されていない限り、カタログから削除されることはありません。 この方法は、スキャンされたデータ ストアに存在しないファイルがまだカタログに存在する場合にエラーが発生する可能性があることを意味します。 場合によっては、削除された特定の資産をキャッチする前に、データ ストアを 2 回または 3 回スキャンする必要がある場合があります。
注:
- 削除対象としてマークされた資産は、スキャンが成功した後に削除されます。 削除された資産は、処理および削除される前に、カタログにしばらくの間表示され続ける可能性があります。
- 現在、ソース削除検出は、Azure Databricks、Amazon Redshift、Cassandra、DB2、Erwin、Google BigQuery、Hive メタストア、Looker、MongoDB、MySQL、Oracle、PostgreSQL、Salesforce、SAP BW、SAP ECC、SAP HANA、SAP S/4HANA、Snowflake、Teradata ではサポートされていません。 オブジェクトがデータ ソースから削除された場合、後続のスキャンでは、Microsoft Purview の対応する資産は自動的に削除されません。
摂取
インジェストは、さまざまなプロセスを通じて収集されたメタデータをデータ マップに設定するプロセスです。
スキャンからのインジェスト
スキャン プロセスによって識別される技術的なメタデータまたは分類は、インジェストに送信されます。 インジェストは、スキャンからの入力を分析し、 リソース セット パターンを適用し、使用可能な 系列 情報を設定してから、データ マップを自動的に読み込みます。 アセット/スキーマは、インジェストが完了した後にのみ検出またはキュレーションできます。 そのため、スキャンが完了しても、データ マップまたはカタログに資産が表示されていない場合は、インジェスト プロセスが完了するまで待つ必要があります。
系列接続からのインジェスト
Azure Data FactoryやAzure Synapseなどのリソースを Microsoft Purview に接続して、データ ソースと系列情報をMicrosoft Purview データ マップに取り込むことができます。 たとえば、Microsoft Purview に接続されているAzure Data Factoryでコピー パイプラインが実行されると、入力ソース、アクティビティ、出力ソースに関するメタデータが Microsoft Purview に取り込まれると、情報がデータ マップに追加されます。
スキャンによってデータ ソースが既にデータ マップに追加されている場合は、アクティビティに関する系列情報が既存のソースに追加されます。 データ ソースがまだデータ マップに追加されていない場合、系列インジェスト プロセスによって、系列情報を含むルート コレクションに追加されます。
使用可能な系列接続の詳細については、 系列ユーザー ガイドを参照してください。
次の手順
詳細については、またはソースのスキャンに関する具体的な手順については、以下のリンクを参照してください。
- リソース セットについては、リソース セットに関する 記事を参照してください。
- Azure SQL データベースを管理する方法
- Microsoft Purview の系列
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示