Azure AI Searchでのスキルセットの概念
この記事は、スキルセットの概念と構成について理解を深める必要がある開発者を対象としています。ここでは、Azure AI 検索の Applied AI に関する高度な概念に精通していることを前提としています。
スキルセットは、インデクサーにアタッチされている Azure AI 検索の再利用可能なオブジェクトです。 これには、外部のデータ ソースから取得したドキュメントに対して、組み込みの AI や外部カスタム処理を呼び出す 1 つ以上のスキルが含まれています。
次の図は、スキルセット実行の基本的なデータ フローを示しています。
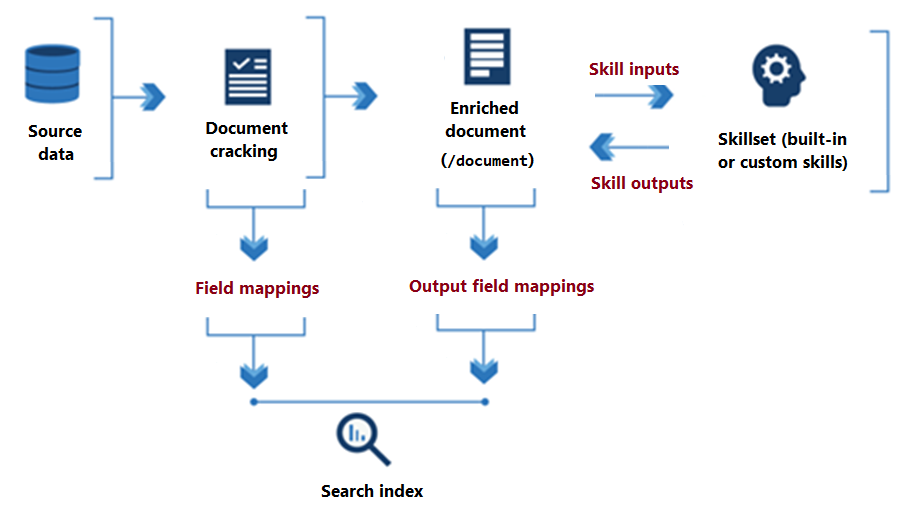
スキルによって行われるのは、スキルセット処理の開始から終了まで、メモリに存在する "エンリッチされたドキュメント" に対する読み取りと書き込みです。 最初は、エンリッチされたドキュメントは、データ ソースから抽出された生コンテンツだけです ("/document" ルート ノードとして明確に表現されています)。 スキルが実行されるたびに、それぞれのスキルによってその出力がグラフのノードとして書き込まれるため、エンリッチされたドキュメントは、構造と実質的な内容を取得していきます。
スキルセットの実行が完了すると、エンリッチされたドキュメントの出力は、ユーザー定義の "出力フィールド マッピング" を介してインデックスに組み込まれます。 ソースからインデックスにそのまま転送する生コンテンツは、"フィールド マッピング" によって定義されます。
Applied AI を構成するには、スキルセットとインデクサーで設定を指定します。
スキルセットの定義
スキルセットとは、画像ファイル上のテキストや 光学式文字認識 (OCR) の翻訳など、エンリッチメントを実行する 1 つ以上の "スキル" の配列です。 スキルは、Microsoft の組み込みスキル、または外部でホストするロジックを処理するためのカスタム スキルのいずれかになります。 スキルセットにより、インデックスを付けるときに使用される、またはナレッジ ストアにプロジェクションされるエンリッチされたドキュメントが生成されます。
スキルには、コンテキスト、入力、出力があります。
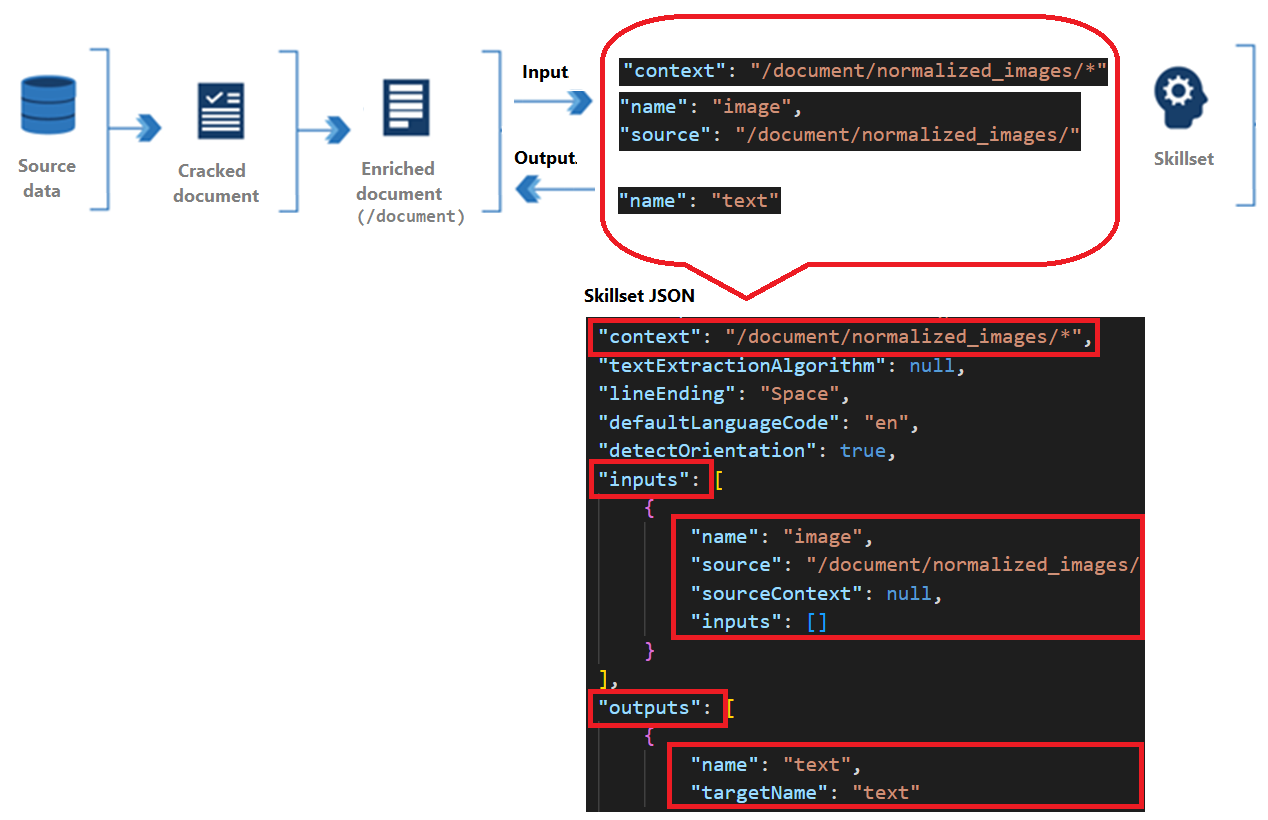
コンテキストは、ドキュメントごとに 1 回、またはコレクション内のアイテムごとに 1 回の操作のスコープを指します。
入力はエンリッチされたドキュメント内のノードから発信されます。ここで、"source" と "name" は特定のノードを識別します。
出力は、エンリッチされたドキュメントに新しいノードとして返送されます。 値は、ノードの "name" とノードの内容です。 ノード名が重複している場合は、あいまいさを解消するためにターゲット名を設定できます。
スキル コンテキスト
各スキルにはコンテキストがあります。コンテキストはドキュメント全体 (/document) であったり、ツリー内の下位のノード (/document/countries/*) であったりします。
コンテキストによって次のことが決まります。
1 つの値に対してスキルが実行される回数 (フィールドごと、ドキュメントごとに 1 回)。コレクションの場合、
/*を追加すると、コレクション内のインスタンスごとにスキルが呼び出されます。出力の宣言。スキルの出力が追加される強化ツリー内の場所。 出力は、常にコンテキスト ノードの子としてツリーに追加されます。
入力の形状。 複数レベルのコレクションの場合、コンテキストを親コレクションに設定すると、スキル入力の形状に影響します。 たとえば、国または地域のリストが含まれる強化ツリーがあり、それぞれが郵便番号のリストを含む州のリストでエンリッチメント処理されている場合、コンテキストをどのように設定するかによって、入力がどのように解釈されるかが決まります。
Context 入力 入力の形状 スキルの呼び出し /document/countries/*/document/countries/*/states/*/zipcodes/*国または地域のすべての郵便番号のリスト 国または地域ごとに 1 回 /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*州内の郵便番号のリスト 国または地域と州の組み合わせごとに 1 回
スキルの依存関係
スキルは、独立して並列に実行することも、あるスキルの出力を別のスキルにフィードする場合は順番に実行することもできます。 次の例は、順番に実行される 2 つの組み込みスキルを示しています。
スキル #1 は、"reviews_text" ソース フィールドのコンテンツを入力として受け取り、そのコンテンツを出力として 5,000 文字の "pages" に分割するテキスト分割スキルです。 大きなテキストを小さなチャンクに分割すると、センチメント検出などのスキルの結果が向上する可能性があります。
スキル #2 は、"pages" を入力として受け入れ、センチメント分析の結果が含まれる "Sentiment" という名前の新しいフィールドを作成するセンチメント検出スキルです。
最初のスキル ("pages") の出力が感情分析でどのように使用されているかに注目してください。ここで、"/document/reviews_text/pages/*" はコンテキストと入力の両方です。 パスの構文の詳細については、エンリッチメントを参照する方法に関するページをご覧ください。
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
強化ツリー
エンリッチされたドキュメントは、スキルセットの実行中に作成された一時的なツリー状のデータ構造で、スキルを通じて行われたすべての変更を収集します。 集合的に、エンリッチメントはアドレス指定可能なノードの階層として表されます。 ノードには、外部データ ソースから逐語的に渡されたエンリッチされていないフィールドも含まれます。
エンリッチされたドキュメントが存在するのは、スキルセットの実行中ですが、キャッシュしたり、ナレッジ ストアに送信したりできます。
エンリッチされたドキュメントは、最初は、"ドキュメント解析" 中にデータ ソースから抽出されたコンテンツに過ぎません。ここでテキストやイメージがソースから抽出され、言語解析やイメージ解析に利用できるようになります。
最初のコンテンツはメタデータと "ルート ノード" (document/content) です。 ルート ノードは、通常、ドキュメント全体であるか、ドキュメント解析中にデータ ソースから抽出された正規化されたイメージです。 強化ツリーでの表現方法は、データ ソースの種類によって異なります。 次の表は、サポートされているいくつかのデータ ソースについて、エンリッチメント パイプラインに入ったドキュメントの状態を示しています。
| データ ソース/解析モード | 既定値 | JSON、JSON 行、CSV |
|---|---|---|
| Blob Storage | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
該当なし |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
該当なし |
スキルが実行されると、出力が新しいノードとしてエンリッチメント ツリーに追加されます。 スキルの実行がドキュメント全体に対して行われる場合、ノードはルートの下の最初のレベルに追加されます。
ノードは、ダウンストリーム スキルの入力として使用できます。 たとえば、翻訳された文字列などのコンテンツを作成するスキルは、エンティティを認識したり、キー フレーズを抽出したりするスキルの入力になる可能性があります。
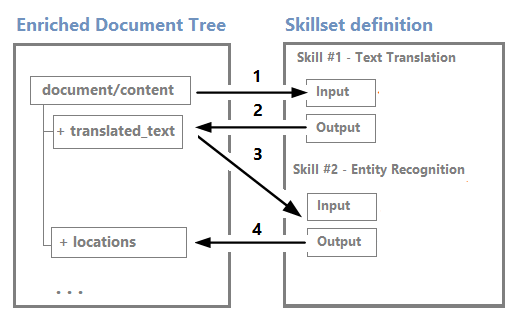
デバッグ セッションのビジュアル エディターを使用してエンリッチメント ツリーを視覚化して操作できますが、ほとんどは内部構造です。
エンリッチメントは変更できません。ノードは一度作成されたら編集できません。 スキルセットや強化ツリーの複雑さが増しても、強化ツリー内のすべてのノードをインデックスやナレッジ ストアにする必要はありません。
エンリッチメント出力のサブセットのみを選択的に保持して、使用する情報のみを保持することができます。 インデクサー定義の出力フィールド マッピングによって、検索インデックスに実際に取り込まれるコンテンツが決まります。 同様に、ナレッジ ストアを作成する場合は、プロジェクションに割り当てられているシェイプに、出力をマップできます。
Note
強化ツリー形式により、エンリッチメント パイプラインでは、メタデータをプリミティブ データ型にもアタッチできます。 メタデータは有効な JSON オブジェクトになりませんが、ナレッジ ストア内のプロジェクション定義で有効な JSON 形式にプロジェクションできます。 詳細については、Shaper スキルに関するページをご覧ください。
インデクサーの定義
インデクサーには、インデクサーの実行を構成するために使用されるプロパティとパラメーターがあります。 これらのプロパティの中には、検索インデックス内のフィールドにデータ パスを設定するマッピングがあります。

マッピングには次の 2 つのセットがあります。
"fieldMappings" は、ソース フィールドを検索フィールドにマップします。
"outputFieldMappings" は、エンリッチされたドキュメント内のノードを検索フィールドにマップします。
"sourceFieldName" プロパティは、データ ソース内のフィールドまたはエンリッチメント ツリー内のノードのいずれかを指定します。 "targetFieldName" プロパティは、コンテンツを受け取るインデックス内の検索フィールドを指定します。
エンリッチメントの例
この例では、ホテル レビュー スキルセットを参照ポイントとして使用し、スキルの実行によって強化ツリーがどのように発展するかを概念図を使って説明します。
また、この例では以下もわかります。
- スキルの実行回数の決定に対して、スキルのコンテキストと入力がどのように働くか
- コンテキストに基づく入力の形状
この例では、CSV ファイルのソース フィールドに、ホテルに関する顧客レビュー ("reviews_text") と評価 ("reviews_rating") が含まれています。 インデクサーによって、BLOB ストレージからメタデータ フィールドが追加され、スキルによって、翻訳されたテキスト、センチメント スコア、キーフレーズ検出が追加されます。
ホテル レビューの例で、エンリッチメント プロセス内の "ドキュメント" は 1 つのホテル レビューを表します。
ヒント
このデータの検索インデックスやナレッジ ストアは、Azure portal またはREST API で作成できます。 デバッグ セッションを使用して、スキルセットの構成、依存関係、強化ツリーへの影響の分析情報を確認することもできます。 この記事のイメージは、デバッグ セッションからプルされます。
概念的には、最初の強化ツリーは次のようになります。

すべての強化のルート ノードは "/document" です。 BLOB インデクサーを使用すると、"/document" ノードに子ノード "/document/normalized_images" と "/document/content" ができます。 この例のように、データが CSV の場合、列名は "/document" の下のノードにマップされます。
スキル #1: 分割スキル
ソース コンテンツが大量のテキストで構成されている場合は、言語、センチメント、キーフレーズ検出の精度を高めるために、より小さいコンポーネントに分割すると便利です。 使用できるグレインは、ページと文の 2 つです。 ページは約 5,000 文字で構成されます。
通常、テキスト分割スキルは、スキルセットにおいて最初に選ばれます。
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
"/document/reviews_text" のスキル コンテキストでは、この分割スキルは reviews_text に対して 1 回実行されます。 スキルの出力はリストであり、reviews_text が 5,000 文字のセグメントに分割されています。 分割スキルからの出力は、pages という名前が付けられ、エンリッチメント ツリーに追加されます。 targetName 機能を使用することで、強化ツリーに追加される前に、スキル出力の名前を変更できます。
これで、強化ツリーのスキルのコンテキストの下に、新しいノードが配置されました。 このノードは、任意のスキル、プロジェクション、または出力フィールド マッピングで使用できます。

スキルによってノードに追加されたいずれかの強化にアクセスするには、強化の完全なパスが必要です。 たとえば、pages ノードのテキストを別のスキルへの入力として使用する場合は、"/document/reviews_text/pages/*" として指定します。 パスの詳細については、エンリッチメントの参照に関するページをご覧ください。
スキル #2: 言語検出
ホテル レビュー ドキュメントには、複数の言語で表される顧客フィードバックが含まれています。 言語検出スキルによって、どの言語が使用されているか判断されます。 結果は、キー フレーズ抽出とセンチメント検出に渡され (非表示)、センチメントと語句を検出するときに言語が考慮されます。
言語検出スキルは、スキルセットで定義されている 3 番目のスキル (スキル #3) ですが、次に実行されるスキルです。 入力は必要ないので、前のスキルと並行して実行されます。 先行する分割スキルと同様に、言語検出スキルもドキュメントごとに 1 回呼び出されます。 強化ツリーには言語用の新しいノードが追加されています。

スキル #3 と #4 (感情分析とキー フレーズ検出)
お客様からのフィードバックには、ポジティブなものからネガティブなものまで、さまざまなエクスペリエンスが反映されています。 フィードバックは、感情分析スキルによって分析され、負数から正数の範囲内で一連のスコアが割り当てられます。センチメントがはっきりしない場合は、中立が割り当てられます。 感情分析と同時に、結果的に重要であると思われる単語と短いフレーズが、キー フレーズ検出によって特定され、抽出されます。
コンテキストとして /document/reviews_text/pages/* が指定された感情分析スキルとキー フレーズ スキルは両方とも、pages コレクション内の項目ごとに 1 回ずつ呼び出されます。 スキルからの出力は、関連付けられている page 要素の下のノードになります。
スキルセットに含まれる残りのスキルを表示し、各スキルの実行によって強化のツリーがどのように成長し続けるかを視覚化できるようになるはずです。 マージ スキルや Shaper スキルなどの一部のスキルでも新しいノードが作成されますが、既存のノードのデータのみが使用され、新しい強化は作成されません。

上のツリーのコネクタの色は、エンリッチメントが異なるスキルで作成されたことを示しています。ノードは個別に指定する必要があり、親ノードを選択したときに返されるオブジェクトの一部にはなりません。
スキル #5: Shaper スキル
出力にナレッジ ストアが含まれる場合は、最後のステップとして Shaper スキルを追加します。 Shaper スキルによって、強化ツリー内のノードからデータ シェイプが作成されます。 たとえば、複数のノードを 1 つのシェイプに統合することができます。 その後、このシェイプをテーブルとして射影し (ノードはテーブル内の列になります)、名前によってシェイプをテーブル プロジェクションに渡します。
整形が 1 つのスキルにまとめられているため、Shaper スキルは簡単に操作できます。 また、個々のプロジェクション内でインライン整形を選ぶこともできます。 Shaper スキルによってエンリッチメント ツリーの加減が行われることはありません。したがって、これは視覚化されません。 代わりに、Shaper スキルは、既にあるエンリッチメント ツリーを再現する手段と考えることができます。 概念的には、これはデータベース内のテーブルからビューを作成するのと似ています。
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
次のステップ
概要と例を参考にしながら、組み込みスキルを使用して、最初のスキルセットを作成してみてください。