Azure AI Search のインデクサーは、テキスト データをクラウド データ ソースから抽出し、ソース データと検索インデックス間のフィールド間マッピングを検索インデックスに設定するクローラーです。 この方法は、インデックスにデータを追加するコードを記述することなく、検索サービスがデータをプルするため、「プル モデル」と呼ばれることもあります。
インデクサーはスキルセットの実行と AI エンリッチメントを推進し、インデックスに移行中のコンテンツに対する追加処理を統合するようにスキルを構成できます。 いくつかの例として、画像ファイルの OCR、データのチャンクに対するテキスト分割スキル、ベクトル検索のベクトルを生成するための埋め込みモデルの呼び出しなどが挙げられます。
インデクサーはサポートされるデータ ソースを対象とします。 インデクサーの構成では、データ ソース (配信元) と検索インデックス (宛先) を指定します。 Azure Blob Storage など、いくつかのソースには、そのコンテンツの種類に固有の追加のインデクサー構成プロパティがあります。
インデクサーは、オンデマンドで実行することも、5 分ごとに実行される定期的なデータ更新スケジュールで実行することもできます。 更新頻度が高くなるとインデクサーを使用できなくなり、同期のために Azure AI Search と外部データ ソースの両方にデータを同時にプッシュする 'プッシュ モデル' を実装する必要があります。
検索サービスは、検索ユニットごとに 1 つのインデクサー ジョブを実行します。 同時処理が必要な場合は、十分なレプリカがあることをご確認ください。 インデクサーはバックグラウンドで実行されないため、サービスに負荷がかかっている場合は、通常よりも多くのクエリ調整を検出する可能性があります。
インデクサーのシナリオとユース ケース
インデクサーは、データ インジェストの唯一の手段として、または他の手法と組み合わせて使用できます。 次の表に主なシナリオをまとめています。
| シナリオ | 戦略 |
|---|---|
| 単一のデータ ソース | このパターンは最も単純です。1 つのデータ ソースが検索インデックス用の唯一のコンテンツ プロバイダーです。 サポートされているほとんどのデータソースで何らかの形式の変更が検出されるため、ソースでコンテンツが追加または更新されたときに、後続のインデクサーの実行によって差分が取得されます。 |
| 複数のデータ ソース | インデクサーの仕様で指定できるデータソースは 1 つだけですが、検索インデックス自体は複数のソースからのコンテンツを受け入れることができます。この場合、各インデクサー ジョブによって、別のデータ プロバイダーから新しいコンテンツが取り込まれます。 各ソースは、完全なドキュメントの共有を投稿したり、各ドキュメントで選択したフィールドを設定したりできます。 このシナリオの詳細については、複数のデータ ソースからのインデックスのチュートリアルを参照してください。 |
| 複数のインデクサー | 実行時のパラメーター、スケジュール、またはフィールド マッピングを変更する必要がある場合、複数のデータ ソースは通常、複数のインデクサーとペアになります。 Azure AI Search のリージョン間スケールアウトは、このシナリオのバリエーションです。 同じ検索インデックスのコピーが異なるリージョンに存在する場合があります。 検索インデックスのコンテンツを同期するには、同じデータ ソースからプルする複数のインデクサーを作成できます。この場合、各インデクサーのターゲットはリージョンごとに異なる検索インデックスです。非常に大きなデータセットの 並列インデックスでも、各インデクサーがデータのサブセットをターゲットとするマルチインデクサー戦略が必要です。 |
| コンテンツの変換 | インデクサーはスキルセットの実行と AI エンリッチメントを推進します。 コンテンツの変換は、インデクサーにアタッチするスキルセットで定義されます。 スキルを使用し、データのチャンクとベクター化を組み込めます。 |
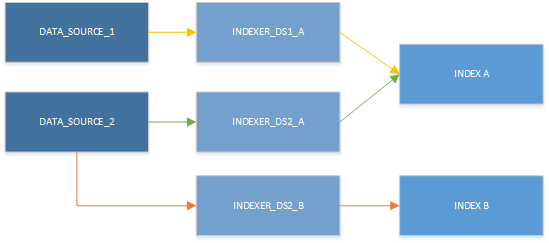
ターゲット インデックスとデータ ソースの組み合わせごとにインデクサーを 1 つ作成するように設計する必要があります。 複数のインデクサーが同じインデックスに書き込みできます。複数のインデクサーに同じデータ ソースを再利用できます。 ただし、インデクサーが 1 回に利用できるデータ ソースは 1 つだけです。そして、書き込めるインデックスは 1 つだけです。 次の図に示すように、1 つのデータ ソースが 1 つのインデクサーに入力を提供し、1 つのインデックスを設定します:

一度に使用できるインデクサーは 1 つだけですが、リソースはさまざまな組み合わせで使用できます。 次の図の主なポイントは、データ ソースを複数のインデクサーと組み合わせることができ、複数のインデクサーが同じインデックスに書き込むことができる点です。
サポートされるデータ ソース
インデクサーは、Azure および Azure 外部でデータ ストアをクロールします。
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure Table Storage の
- Azure SQL Managed Instance
- Azure Virtual Machines 上の SQL Server
- Azure Files (プレビュー段階)
- Azure MySQL (プレビュー段階)
- Microsoft 365 での SharePoint (プレビュー段階)
- Azure Cosmos DB for MongoDB (プレビュー段階)
- Azure Cosmos DB for Apache Gremlin (プレビュー段階)
- OneLake (プレビュー段階)
Azure Cosmos DB for Cassandra はサポートされていません。
インデクサーは、テーブルやビューなどのフラット化された行セット、またはコンテナーまたはフォルダー内の項目を受け入れます。 ほとんどの場合、行、レコード、または項目ごとに 1 つの検索ドキュメントが作成されます。
共有プライベート リンクを使用するときは、標準のインターネット接続 (パブリック) または暗号化されたプライベート接続を使用して、リモート データ ソースへのインデクサーの接続を行うことができます。 また、マネージド ID を使用して認証を行うように、接続を設定することもできます。 セキュリティで保護された接続の詳細については、Azure ネットワーク セキュリティ機能によって保護されたコンテンツへのインデクサーのアクセスと、マネージド ID を使用したデータ ソースへの接続に関するページを参照してください。
インデックス作成のステージ
最初の実行時に、インデックスが空の場合、テーブルまたはコンテナーで提供されるすべてのデータがインデクサーによって読み取られます。 その後の実行では、通常、変更されたデータのみがインデクサーによって検出され取得されます。 BLOB データの場合、変更の検出は自動で行われます。 Azure SQL や Azure Cosmos DB などの他のデータ ソースで、変更の検出を有効にする必要があります。
受信したドキュメントごとに、インデクサーによって、ドキュメントの取得からインデックス付けのための最終的な検索エンジンの "ハンドオフ" までの、複数のステップが実装または調整されます。 また、インデクサーを使用すると、スキルセットが定義されている場合に、スキルセットの実行と出力も促進されます。

ステージ 1: ドキュメント解析
ドキュメント解析は、ファイルを開いてコンテンツを抽出するプロセスです。 テキスト ベースのコンテンツは、サービスのファイル、テーブルの行、またはコンテナーやコレクションの項目から抽出できます。
また、 追加料金でドキュメントの解読中に画像抽出を有効にすることもできます。 これは既定で無効になっており、imageActionの プロパティを使用して有効にすることができます。 インデクサー のイメージ 処理に関するいくつかのイメージ シナリオを確認します。
データ ソースに応じて、インデックス付けが可能なコンテンツを抽出するために、インデクサーによってさまざまな操作が試行されます。
ドキュメントが PDF などの画像が埋め込まれたファイルである場合、インデクサーはテキスト、画像、メタデータを抽出します。 インデクサーは、Azure Blob Storage、Azure Data Lake Storage Gen2、SharePoint からファイルを開くことができます。
ドキュメントが Azure SQL のレコードの場合は、インデクサーによって各レコードの各フィールドからバイナリ以外のコンテンツが抽出されます。
ドキュメントが Azure Cosmos DB 内のレコードの場合は、インデクサーによって Azure Cosmos DB ドキュメントのフィールドとサブフィールドからバイナリ以外のコンテンツが抽出されます。
ドキュメントクラッキング プロセスは、データ変換にスキルセットを使用して、オプションの スキルセット実行 ステージで後でトリガーすることもできます。 画像スキルを持つスキルセットを追加すると、ドキュメントクラッキングで画像を抽出し、処理のためにキューに入れることが可能になります。
ステージ 2: フィールド マッピング
インデクサーによって、ソース フィールドからテキストが抽出され、インデックスまたはナレッジ ストアの送信先フィールドにそれが送信されます。 フィールド名とデータ型が一致すると、パスは明確になります。 ただし、出力には異なる名前または型が必要な場合があります。その場合は、フィールドをマップする方法をインデクサーに指示する必要があります。
フィールド マッピングを指定するには、インデクサー定義に、ソース フィールドと宛先フィールドを入力します。
フィールド マッピングは、ドキュメント解析の後、変換前に、インデクサーがソース ドキュメントから読み取るときに行われます。 フィールド マッピングを定義するときに、ソース フィールドの値は変更されずにそのまま送信先フィールドに送信されます。
ステージ 3: スキルセットの実行
スキルセットの実行は、組み込みまたはカスタムの AI 処理を呼び出す省略可能なステップです。 スキルセットでは、コンテンツがバイナリの場合、光学式文字認識 (OCR) またはその他の形式の画像分析を追加できます。 スキルセットで自然言語処理を追加することもできます。 たとえば、テキスト翻訳やキー フレーズ抽出を追加できます。
変換が何であれ、スキルセットの実行は、エンリッチメントが発生する場所です。 インデクサーがパイプラインの場合、スキルセットを "パイプライン内のパイプライン" として考えることができます。
ステージ 4: 出力フィールドマッピング
スキルセットを含める場合は、インデクサー定義で出力フィールド マッピングを指定する必要があります。 スキルセットの出力は、エンリッチされたドキュメントと呼ばれるツリー構造として内部的に示されます。 出力フィールド マッピングを使用すると、このツリーの部分を選択してインデックス内のフィールドにマップすることができます。
名前が類似しているにもかかわらず、出力フィールド マッピングとフィールド マッピングは、異なるソースから関連付けを構築します。 フィールド マッピングでは、ソース フィールドの内容を検索インデックスの宛先フィールドに関連付けます。 出力フィールド マッピングでは、内部のエンリッチされたドキュメント (スキル出力) の内容をインデックス内の宛先フィールドに関連付けます。 省略可能と見なされるフィールド マッピングとは異なり、インデックスに存在する必要がある変換されたすべてのコンテンツには、出力フィールド マッピングが必要になります。
次の図は、インデクサーのステージ (ドキュメント解析、フィールド マッピング、スキルセットの実行、出力フィールド マッピング) のサンプル インデクサーのデバッグ セッション表現を示しています。

の基本的なワークフロー
インデクサーで実行できる機能は、データ ソースごとに異なります。 そのためインデクサーやデータ ソースの構成には、インデクサーの種類ごとに異なる点があります。 しかし基本的な成り立ちと要件は、すべてのインデクサーに共通です。 以降、すべてのインデクサーに共通の手順について取り上げます。
手順 1:データ ソースを作成する
インデクサーには、接続文字列と必要に応じて資格情報を提供する、"データ ソース" オブジェクトが必要です。 データ ソースは独立したオブジェクトです。 複数のインデクサーは、同じデータ ソース オブジェクトを使用して、一度に複数のインデックスを読み込むことができます。
次のいずれかの方法を使用してデータ ソースを作成できます。
- Azure portal を使用し、検索サービス ページの [データ ソース] タブで [データ ソースの追加] を選択して、データ ソースの定義を指定します。
- Azure portal を使用して、[データのインポート] ウィザードでデータ ソースを出力します。
- REST API を使用して、[データ ソースの作成] を呼び出します。
- Azure SDK for .NET を使用して、SearchIndexerDataSourceConnection クラスを呼び出します
手順 2:インデックスを作成する
インデクサーは、データ インジェストに関連したいくつかのタスクを自動化しますが通常、そこにはインデックスの作成は含まれていません。 前提条件として、お使いの外部データ ソース内のすべてのソース フィールドの対応するターゲット フィールドが含まれた定義済みインデックスが必要になります。 各フィールドでは、名前とデータ型が一致する必要があります。 そうでない場合は、フィールド マッピングを定義して関連付けを確立できます。
詳細については、「インデックスの作成」を参照してください。
手順 3: インデクサーを作成して実行 (またはスケジュール) する
インデクサーの定義は、インデクサーを一意に識別するプロパティ、使用するデータ ソースとインデックスを指定するプロパティ、実行時の動作に影響する他の構成オプションを提供するプロパティ (インデクサーをオンデマンドで実行するか、スケジュールに基づき実行するかなど) で構成されます。
データ アクセスまたはスキルセットの検証に関するエラーまたは警告は、インデクサーの実行中に発生します。 インデクサーの実行が開始されるまで、データ ソース、インデックス、スキルセットなどの依存オブジェクトは、検索サービスでパッシブになります。
詳細については、「インデクサーの作成」を参照してください
インデクサーの初回実行の後、オンデマンドで再実行することや、スケジュールを設定することができます。
インデクサーの状態は、Azure portal か Get Indexer Status API を使用して監視できます。 また、インデックスのクエリを実行し、期待した結果が得られるかどうかを確認する必要もあります。
インデクサーには専用の処理リソースがありません。 これに基づき、インデクサーの状態が (キュー内の他のジョブに応じて) 実行される前にアイドル状態として表示され、実行時間が予測できない場合があります。 インデクサーのパフォーマンスは、ドキュメント サイズ、ドキュメントの複雑さ、画像分析などのその他の要因によっても定義されます。
次のステップ
インデクサーの概要がわかったので、次のステップは、インデクサーのプロパティとパラメーター、スケジュール、およびインデクサーの監視について確認することです。 また、サポートされているデータ ソースの一覧に戻り、特定のソースの詳細を確認することもできます。