フルテキスト検索は、インデックスに格納されているプレーン テキストと照合する情報取得のアプローチです。 たとえば、クエリ文字列 "hotels in San Diego on the beach" を指定すると、検索エンジンはそれらの用語に基づいてトークン化された文字列を検索します。 スキャンを効率化するために、クエリ文字列の字句解析が行われます。つまり、すべての用語の小文字化、"the" などのストップ ワードの削除、プリミティブな原形への用語の単純化が行われます。 一致する語句が見つかると、検索エンジンにより、ドキュメントが取得され、関連度の順でドキュメントがランク付けされて上位の結果が返されます。
クエリの実行は複雑な場合があります。 この記事は、Azure AI Search におけるフルテキスト検索のしくみについて理解を深める必要がある開発者を対象としています。 テキスト クエリに関して、Azure AI Search はほとんどの状況で速やかに適切な結果を返します。しかし一見、間違っているのではないか、と思うような結果が返されることも皆無ではありません。 このような状況では、Lucene による 4 段階から成るクエリ実行 (クエリ解析、字句解析、文書のマッチング、スコア付け) についての背景知識があると、具体的にどのような変更をクエリ パラメーターやインデックス構成に加えれば目的の結果が生成されるかが特定しやすくなります。
Note
Azure AI Search では、フルテキスト検索に Apache Lucene が使われていますが、Lucene の機能がそのままの形で統合されているわけではありません。 Microsoft は、Azure AI Search にとって重要なシナリオを実現する Lucene の機能を選んで公開、拡張しています。
アーキテクチャの概要と図
クエリの実行には次の 4 つの段階があります。
- クエリ解析
- 字句解析
- 文書検索
- ポイントの計算
フルテキスト検索クエリは、クエリ テキストを解析して検索語と演算子を抽出することから始まります。 2 つのパーサーがあり、速度と複雑さを選択できます。 次に分析段階では、個々の検索語がしばしば分解され、新しい形に再構築されます。 この手順では、できるだけ広い範囲から "一致と見なす候補" が得られます。 検索エンジンは、インデックスをスキャンして、一致する語句を持つドキュメントを検索し、各一致をスコア付けします。 その後、一致する個々の文書に割り当てられた関連度スコアに基づいて結果セットが並べ替えられます。 このようにランク順に並んだリストの先頭の結果が、呼び出し元のアプリケーションに返されます。
以下の図は、検索要求の処理に使用されるコンポーネントを示しています。
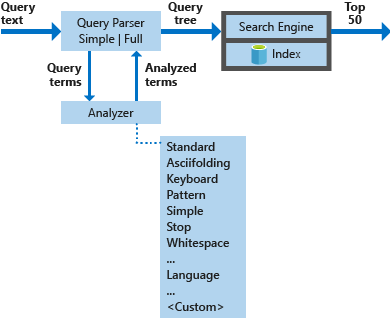
| 主要コンポーネント | 機能の説明 |
|---|---|
| クエリ パーサー | クエリ演算子から検索語を切り離し、検索エンジンに送るクエリ構造 (クエリ ツリー) を作成します。 |
| アナライザー | 検索語に対する字句解析を実行します。 このプロセスには、検索語の変換、削除、拡大が伴う場合があります。 |
| インデックス | 索引付けの対象文書から抽出した検索可能な語句を効率よく体系的に格納するデータ構造です。 |
| 検索エンジン | 転置インデックスの内容に基づいて、一致する文書を検索してスコア付けします。 |
検索要求の構造
検索要求は、結果セットで返すべき内容を詳細に規定した仕様です。 最も単純な形式は、どのような種類の条件も含まれていない空のクエリです。 しかしより現実的な例では、パラメーターや複数の検索語を伴うのが一般的です。場合によっては、検索範囲を特定のフィールドに限定したり、フィルター式や並べ替え規則が使われたりすることもあります。
次の例は、REST API を使用して Azure AI Search に送信できる検索要求です。
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
この要求に対して、検索エンジンは次の操作を実行します。
価格が $60 以上 $300 未満の文書を検索します。
クエリを実行します。 この例では、検索クエリが
"Spacious, air-condition* +\"Ocean view\""という語句で構成されています (通常はユーザーが句読点を入力することはありませんが、この例では、アナライザーによる処理を説明するためにあえて含めています)。このクエリの場合、検索エンジンは、"searchFields" に指定された説明フィールドとタイトル フィールドをスキャンして、
"Ocean view"を含む文書、さらに"spacious"という語句、または"air-condition"というプレフィックスで始まる語句を探します。 明示的に必須指定 (+) されていない語句に関して、マッチング対象を任意 (既定) とするか、すべてとするかが、"searchMode" パラメーターで指定されています。結果として得られた一連のホテルを特定の地理的位置に近い順に並べ替え、結果を呼び出し元のアプリケーションに返します。
この記事では主に、検索クエリ: "Spacious, air-condition* +\"Ocean view\""の処理について取り上げています。 フィルター処理と並べ替えについては取り上げません。 詳細については、Search API のリファレンス ドキュメントを参照してください。
第 1 段階: クエリ解析
前出のとおり、検索要求の最初の行がクエリ文字列です。
"search": "Spacious, air-condition* +\"Ocean view\"",
クエリ パーサーは、検索語から演算子 (この例の * や +) を切り離し、検索クエリを "サブクエリ" に分解します。次の種類のサブクエリがサポートされています。
- "単語検索": 独立した語を検索 (spacious など)
- "フレーズ検索": 引用符で囲まれた語句を検索 (ocean view など)
- "プレフィックス検索": 語句 + プレフィックス演算子
*を検索 (air-condition など)
サポートされているクエリの種類すべての一覧については、Lucene のクエリ構文に関するページを参照してください
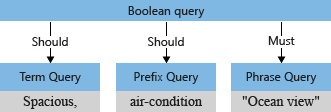
文書が一致していると見なされるために検索条件との一致が "必須 (must)" であるのか "勧告 (should be)" であるのかは、サブクエリに関連付けられている演算子によって決まります。 たとえば、+"Ocean view" は + 演算子が指定されているので検索条件との一致が "必須" となります。
クエリ パーサーは、サブクエリを "クエリ ツリー" (クエリを表す内部的な構造) に再構築して検索エンジンに渡します。 クエリ解析の第 1 段階で、クエリ ツリーは次のようになります。
サポートされるパーサー: Simple と Full Lucene
Azure AI Search では、simple (既定) と full の 2 種類のクエリ言語が使用されます。 どちらのクエリ言語を使うかは、検索要求で queryType パラメーターの設定で指定します。その指定に基づいて、クエリ パーサーが演算子と構文を解釈します。
Simple クエリ言語は直感的で安定しており、多くの場合、クライアント側の処理を行わなくてもユーザー入力をそのまま解釈するのに適しています。 Web 検索エンジンで多く使われているクエリ演算子がサポートされます。
Full Lucene クエリ言語は、
queryType=fullを設定することによって利用できます。より多くの演算子やクエリの種類 (ワイルドカード、あいまい一致、正規表現、フィールド指定検索など) がサポートされることで、既定の Simple クエリ言語が拡張されます。 たとえば、Simple クエリ構文で送信された正規表現は、式としてではなくクエリ文字列と解釈されます。 この記事で紹介している要求の例では、Full Lucene クエリ言語を使用しています。
searchMode がパーサーに及ぼす影響
解析方法に作用する検索要求パラメーターとしては、他にも "searchMode" パラメーターがあります。 これは、ブール クエリの既定の演算子、つまり any (既定) または all を制御します。
"searchMode=any" とした場合 (既定)、spacious と air-condition との間に区切り記号として置かれた空白は OR (||) の働きをするため、サンプル クエリ テキストは次のクエリ テキストに相当します。
Spacious,||air-condition*+"Ocean view"
ブール クエリの構造において、明示的な演算子 (+"Ocean view" の + など) の意味ははっきりしています。つまり検索条件との一致は "必須 (must)" です。 それに比べて、残りの語句 (spacious と air-condition) の解釈はあいまいです。 検索エンジンが探すべきなのは、ocean view と spacious と air-condition の "すべて" との一致でしょうか。 それとも、ocean view に加えて、残りの 2 つの語句のうち、"どちらか一方" のみが含まれていればよいのでしょうか。
既定 ("searchMode=any") では、検索エンジンはより広い解釈を想定します。 どちらか一方のフィールドが一致していればよい (should) の意味、つまり "or" のセマンティクスで解釈されます。 先ほど例に挙げた、2 つの "should" 演算を含んだクエリ ツリーは既定の動作を示しています。
では、"searchMode=all" と設定したらどうなるでしょうか。 この場合は、空白文字が "and" 演算と解釈されます。 残りの 2 つの語句が両方とも文書に存在したときに初めて一致と見なされます。 最終的にサンプル クエリは次のように解釈されます。
+Spacious,+air-condition*+"Ocean view"
変更後のクエリ ツリーは次のようになり、一致する文書は 3 つすべてのサブクエリの積集合となります。

Note
"searchMode=all" より "searchMode=any" を選ぶ場合は、代表的なクエリを実行したうえで判断することをお勧めします。 普段から演算子を指定するユーザー (ドキュメント ストアを検索するときなど) は、"searchMode=all"で得られるブール クエリの構造の方が直感的にわかりやすいかもしれません。 "searchMode" と演算子の相互作用について詳しくは、「Simple クエリ構文」に関するページをご覧ください。
第 2 段階: 字句解析
クエリ ツリーが構築された後、"単語検索" と "フレーズ検索" のクエリがアナライザーによって加工されます。 アナライザーは、パーサーから渡されたテキスト入力を受け取ってそのテキストを加工してから、トークン化した語句をクエリ ツリーに組み入れます。
最も一般的な字句解析は、特定の言語に固有の規則に従って検索語を変換する *言語分析です。
- 検索語を単語の原形にします。
- ストップワード、つまり検索上の重要性がさほど高くない単語 (英語であれば "the" や "and") を削除します
- 複合語をその構成要素に分解します。
- 単語の大文字を小文字に変換します。
通常はこれらの操作をひととおり適用することで、ユーザーによって入力されたテキストと、インデックスに格納されている語句との相違点が取り除かれます。 こうした操作はテキスト処理の範囲を超えており、言語そのものに対する深い知識が必要となります。 この言語知識のレイヤーを追加するために、Azure AI Search は、Lucene と Microsoft から提供されているさまざまな言語アナライザーに対応しています。
Note
解析要件は、実際のシナリオによって大きく異なります。ごく最低限で済む場合もあれば、膨大な作業が必要となる場合もあります。 字句解析の難易度は、あらかじめ定義されているいずれかのアナライザーを選択するか、カスタム アナライザーを独自に作成するかによって決まります。 アナライザーは、検索可能なフィールドにその適用対象が限定されており、フィールド定義の一環として指定されます。 これにより、フィールドごとに多様な字句解析を行うことができます。 指定されなかった場合は、"標準" の Lucene アナライザーが使用されます。
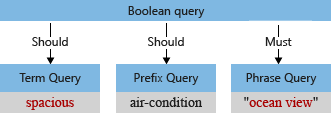
この例では、解析前の最初のクエリ ツリーに "Spacious," という語句があり、大文字の "S" とコンマはクエリ パーサーによって検索語の一部として解釈されています (コンマはクエリ言語の演算子とは見なされません)。
既定のアナライザーは、この語句を加工する際、"ocean view" と "spacious" に含まれている大文字を小文字に変換し、さらにコンマを削除します。 変更後のクエリ ツリーは次のようになります。
アナライザーの動作テスト
アナライザーの動作は、Analyze API を使ってテストすることができます。 解析したいテキストを入力すると、指定したアナライザーからどのような語句が生成されるかを確認できます。 たとえば、標準アナライザーで "air-condition" というテキストがどのように加工されるかを確認するには、次のように要求します。
{
"text": "air-condition",
"analyzer": "standard"
}
標準アナライザーは、入力テキストを次の 2 つのトークンに分解します。その際、開始オフセットと終了オフセット (一致部分の強調表示に使用される) やその位置 (フレーズの照合に使用される) など、各種の属性を使ってそれらに注釈を付けます。
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
字句解析の例外
字句解析が適用されるのは、語句全体を必要とする種類の検索 (単語検索とフレーズ検索) だけです。 語句全体を必要としない種類の検索 (プレフィックス検索、ワイルドカード検索、正規表現検索など) やあいまい検索には適用されません。 前出の例の air-condition* という語を使ったプレフィックス検索も含め、こうした種類の検索は、解析段階を経ずに直接クエリ ツリーに追加されます。 こうした種類の検索語に対して適用される変換は、大文字から小文字への変換だけです。
第 3 段階: 文書検索
ここでいう文書検索とは、一致する語句がインデックスに存在する文書を見つけることです。 この段階は、例を使用するとよくわかります。 まず、次のような単純なスキーマを使用した hotels というインデックスを考えてみましょう。
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
さらに、このインデックスには、以下の 4 つの文書が追加されているとします。
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
語句のインデックス作成方法
検索を理解するには、インデックス作成の基本をいくつかを把握しておくと役立ちます。 保存の単位は転置インデックスで、検索可能なフィールドごとに 1 つ存在します。 転置インデックス内には、全文書から抽出されたすべての語句を並べ替えたリストが存在します。 それぞれの語句は、それが出現する一連の文書に対応付けられています (以下の例を参照)。
転置インデックスに含める語句を得るために、検索エンジンは、クエリの加工時と同様の字句解析を文書の内容に対して実行します。
- "テキスト入力" はアナライザーに渡され、小文字への変換や句読点の削除など、アナライザーの構成に応じた処理が行われます。
- "トークン" は字句解析の出力です。
- "用語" はインデックスに追加されます。
検索語の体裁をインデックスに登録されている語句の体裁と合わせるために、通常は検索操作とインデックス作成操作に同じアナライザーが使用されますが、必ずしも同じである必要はありません。
Note
Azure AI Search では、追加の indexAnalyzer および searchAnalyzer フィールド パラメーターを使用して、インデックス作成と検索に別々のアナライザーを指定することができます。 指定しなかった場合、analyzer プロパティで設定されたアナライザーが、インデックス作成と検索の両方に使用されます。
文書サンプルの転置インデックス
もう一度先ほどの例を見てみましょう。title フィールドの転置インデックスは、次のようになります。
| 任期 | ドキュメント リスト |
|---|---|
| atman | 1 |
| beach | 2 |
| hotel | 1、3 |
| ocean | 4 |
| playa | 3 |
| resort | 3 |
| retreat | 4 |
title フィールドの場合、hotel だけが 2 つの文書 (1 と 3) に出現します。
description フィールドのインデックスは次のようになっています。
| 任期 | ドキュメント リスト |
|---|---|
| air | 3 |
| and | 4 |
| beach | 1 |
| conditioned | 3 |
| comfortable | 3 |
| distance | 1 |
| island | 2 |
| kauaʻi | 2 |
| located | 2 |
| north | 2 |
| ocean | 1, 2, 3 |
| of | 2 |
| on | 2 |
| 通知の停止 | 4 |
| 会議室 | 1、3 |
| secluded | 4 |
| shore | 2 |
| spacious | 1 |
| the | 1、2 |
| to | 1 |
| 表示 | 1, 2, 3 |
| walking | 1 |
| with | 3 |
インデックスが作成された語句に対する検索語の照合
上記の転置インデックスを踏まえてサンプル クエリに戻り、一致する文書がどのように検索されるかを見ていきましょう。 最終的なクエリ ツリーは、次のようになっていたことを思い出してください。
クエリの実行中、検索可能なフィールドに対して個々の検索が別々に実行されます。
単語検索 "spacious" と一致する文書は 1 件です (Hotel Atman)。
プレフィックス検索 "air-condition*" と一致する文書はありません。
これは、場合によっては開発者の混乱を招く動作です。 "air-conditioned" という語句はこの文書内に存在しますが、既定のアナライザーによって 2 つの単語に分割されています。 部分的な語句を含むプレフィックス クエリは、解析されないことに注意してください。 そのため、転置インデックスで、"air-condition" というプレフィックスを含む語句を検索しても見つかりません。
フレーズ検索 "ocean view" では、"ocean" と "view" という 2 つの語句が検索され、元の文書内で両者が近いかどうかがチェックされます。 文書 1、2、3 の description フィールドに、この検索との一致が見つかります。 文書 4 の title には ocean という語が存在しますが、一致とは見なされないことに注意してください。検索対象は "ocean view" というフレーズであって、個々の単語ではありません。
Note
特定のフィールドを searchFields パラメーター (検索要求の例を参照) で指定しない限り、検索クエリは、Azure AI Search インデックス内の検索可能なすべてのフィールドに対して個別に実行されます。 選択したフィールドのいずれかで一致する文書が返されます。
全体として、この例のクエリの場合、一致する文書は 1、2、3 です。
第 4 段階: スコア付け
検索結果セット内のすべての文書には、関連度スコアが割り当てられます。 関連度スコアの機能は、ユーザーからの問い合わせ (検索クエリ) に対して最適解となる文書に対し、相対的に高いランクを与えることです。 このスコアは、一致した語句の統計学的な特性に基づいて計算されます。 スコア付けの式の核となるのは TF/IDF (Term Frequency-Inverse Document Frequency) です。 TF/IDF は、出現頻度の低い語句と高い語句を含んだ検索において、出現頻度の低い語句を含んだ結果に、より高いランクを与えます。 たとえば、Wikipedia の記事をすべて含んだ架空のインデックスでは、the president というクエリに一致した文書のうち、president で一致した文書の方が the で一致した文書よりも関連性が高いと見なされます。
スコア付けの例
冒頭のサンプル クエリで見つかった 3 つの文書を思い出してください。
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
文書 1 は、クエリに対して最も高い関連度で一致しています。なぜなら、spacious という単語と ocean view という必須のフレーズの両方が description フィールドに出現するためです。 その他の 2 つの文書は、ocean view しか一致していません。 しかし文書 2 と文書 3 は、クエリに対して同じように一致しているにもかかわらず、関連度スコアが異なるのはなぜでしょうか。 これは、スコア付けの式の構成要素が TF/IDF だけではないためです。 この場合、文書 3 の方が、description が短いために、少しだけ高いスコアが割り当てられています。 フィールドの長さやその他の要因が関連度スコアに与える影響については、Lucene の実際に役立つスコア付けの式に関するページを参照してください。
一部の検索の種類 (ワイルドカード、プレフィックス、正規表現) は、文書全体のスコアに対して常に一定のスコアをもたらします。 これによって、ランクには影響を与えずに、クエリ拡張によって見つかった一致を結果に反映することができます。
このことが重要である理由を例で説明します。 ワイルドカード検索 (プレフィックス検索を含む) は、本質的に解釈があいまいです。入力されるのは文字列の一部であり、まったく異なる、膨大な数の語句と一致する可能性があるからです ("tour*" と入力した場合、"tours"、"tourettes"、"tourmaline" などとの一致が検出されます)。 こうした結果の性質上、用語の相対的な重みを適切に推測することができません。 そのため、ワイルドカード検索、プレフィックス検索、正規表現検索では、結果のスコア付けを行う際に、語句の出現頻度が無視されます。 部分的な語句と完全な語句とを含んだ複数の構成要素から成る検索要求では、予期しない一致が偏重されないよう、部分的な入力から得られた結果については、定数スコアを割り当てたうえで反映されます。
関連性のチューニング
Azure AI Search の関連度スコアは、次の 2 とおりの方法でチューニングできます。
スコアリング プロファイル: ランク付けされた結果リストにおいて、一連のルールに基づく重みを文書に与えます。 このページの例では、title フィールドに一致の見つかった文書の方が、description フィールドに一致の見つかった文書よりも関連性が高いと見なすことができます。 加えて、仮にホテルごとの料金フィールドをインデックスに含めた場合、料金の低い方の文書に高い重みを与えることも可能です。 スコアリング プロファイルを検索インデックスに追加する方法の詳細について学習します。
項目ブースト (Full Lucene クエリ構文のみで使用可能): クエリ ツリーの任意の構成要素に適用できるブースト演算子
^が用意されています。 このページの例では、air-condition* というプレフィックスで検索する代わりに、air-condition^2||air-condition* のように単語検索にブーストを適用することもできます。そうすれば、air-condition で完全一致する語句と、プレフィックスで一致する語句との両方を検索したうえで、完全一致の語句で一致した文書の方に、より高いランクを与えることができます。 クエリでの語句ブーストの詳細について学習します。
分散されたインデックスにおけるスコア付け
Azure AI Search のすべてのインデックスは自動的に複数のシャードに分割されます。これにより、Microsoft は、サービスのスケールアップまたはスケールダウンの間に、複数のノードにインデックスをすばやく分散することができます。 検索要求は送信されると、各シャードに対して別々に送られます。 その後、各シャードから得られた結果がマージされ、スコア順に並べ替えられます (他に並べ替えが定義されていない場合)。 スコアリング関数は、シャード内のすべてのドキュメントで逆ドキュメント頻度に対して検索語頻度を重み付けするものであり、すべてのシャードで重み付けするものではないことを知ることが重要です。
つまり、まったく同じ文書でも、それらが異なるシャードに存在していれば、関連度スコアが異なる "可能性がある" ということです。 さいわい、インデックス内の文書数が増えるにつれて語句の分布が平準化され、そのような差異は総じて消失します。 文書がどのシャードに配置されるかを推測することは不可能です。 しかし文書は、そのキーが変化しなければ、常に同じシャードに割り当てられます。
一般に、順序の不変性が重要となる場合、文書を並べ替えるための特性として、文書のスコアはあまり適していません。 たとえば、まったく同じスコアの文書が 2 つあるとして、同一クエリを繰り返し実行したときに、どちらの文書が上位にランク付けされるかを毎回確実に予測することができません。 文書スコアは、検索結果群における特定の文書の相対的な関連度の高さを測る、おおよその目安としてのみ使用してください。
まとめ
商用検索エンジンが多くの人々の支持を得たことで、プライベート データに対するフルテキスト検索への期待が高まってきました。 ほぼすべての検索について言えることですが、語句の綴りが間違っていたり不完全であったりしても自分の意図がきちんと反映されるほどの利便性を、私たちは検索エンジンに求めるようになっています。 指定してもいない同義語やほぼ同等の語句に基づいた検索結果が得られることさえ、当然のように感じてしまうほどです。
技術的な観点でいえばフルテキスト検索はきわめて複雑で、洗練された言語分析と検索語の加工 (関連性の高い結果を得るために検索語を抽出、展開、変換する処理) への秩序立ったアプローチとが要求されます。 そうした本質的な複雑さもあって、検索結果はさまざまな要因によって左右されます。 フルテキスト検索のメカニズムをしっかり理解しておけば、予期しない結果に対処しようとする際に、はっきりとその効果を実感できるでしょう。
この記事では、Azure AI Search の観点からフルテキスト検索について詳しく見てきました。 ここで身に付けた知識が、検索時に遭遇しやすい問題の原因や解決策を判断するうえでの一助となればさいわいです。
次のステップ
サンプル インデックスを構築し、さまざまな検索を試してその結果を確認します。 手順については、Azure portal でのインデックスの構築とクエリに関する記事をご覧ください。
ドキュメントの検索に関する記事の例のセクションや、単純なクエリ構文に関する記事で説明されている他のクエリ構文を、Azure portal の検索エクスプローラーで試します。
検索アプリケーションにおけるランク付けをチューニングする方法については、スコアリング プロファイルに関するページを参照してください。
言語に固有の字句解析器を適用する方法について書かれた記事を参照します。
特定のフィールドに対して最小限の処理または特殊な処理を適用するためのカスタム アナライザーを構成します。