このクイック スタートでは、 データのインポート ウィザード と、Microsoft がホストする架空のホテル データの組み込みサンプルを使用して、初めての Azure AI Search インデックスを作成します。 ウィザードではインデックスを作成するためのコードは必要なく、数分で興味深いクエリを記述できます。
ウィザードは、検索 可能なインデックス、 インデクサー、データ ソース接続を含む複数のオブジェクトを検索サービスに作成して、データの自動取得を行います。 このクイックスタートの最後に、各オブジェクトを確認します。
注
[データのインポート] ウィザードには、OCR、テキスト翻訳、その他の AI エンリッチメントのオプションが含まれていますが、このクイックスタートでは説明しません。 応用 AI に焦点を当てた同様のチュートリアルについては、「クイックスタート: Azure portal でスキルセットを作成する」を参照してください。
前提条件
アクティブなサブスクリプションが含まれる Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 サービスを作成 するか 、現在の サブスクリプションで既存のサービスを検索します。 このクイック スタート用には、無料のサービスを使用できます。
ウィザードに関する知識。 Azure portal のデータのインポート ウィザードを参照してください。
ネットワーク アクセスを確認する
組み込みのサンプル データを使用するこのクイック スタートでは、検索サービスに ネットワーク アクセス制御がないことを確認します。 Azure portal コントローラーは、パブリック エンドポイントを使用して、Microsoft がホストするデータ ソースからデータとメタデータを取得します。 詳細については、インポート ウィザードでの安全な接続に関するページを参照してください。
領域の確認
多くのお客様は、3 つのインデックス、3 つのインデクサー、3 つのデータ ソースに制限されている無料の検索サービスから始めます。 このクイック スタートでは、それぞれ 1 つを作成するため、開始する前に、追加のオブジェクト用のスペースがあることを確認してください。
[ 概要 ] タブで、[ 使用状況 ] を選択して、現在使用しているインデックス、インデクサー、データ ソースの数を確認します。
![Azure portal の Azure AI 検索サービス インスタンスの [概要] ページのスクリーンショット。インデックス、インデクサー、データ ソースの数が表示されています。](media/search-get-started-portal/overview-quota-usage.png#lightbox)
ウィザードを起動する
Azure portal にサインインします。
検索サービスに移動します。
[ 概要 ] タブで、[ データのインポート ] を選択してウィザードを開始します。
![Azure portal で [データのインポート] ウィザードを開く方法を示すスクリーンショット。](media/search-import-data-portal/import-data-cmd.png)
検索インデックスを作成して読み込む
このセクションでは、次の 4 つの手順でインデックスを作成して読み込みます。
データ ソースへの接続
ウィザードは、Microsoft が Azure Cosmos DB でホストするサンプル データへのデータ ソース接続を作成します。 サンプル データはパブリック エンドポイントを介してアクセスされるため、この手順に Azure Cosmos DB アカウントまたはソース ファイルは必要ありません。
サンプル データに接続するには:
[データへの接続] で、[データ ソース] ドロップダウン リストを展開し、[サンプル] を選択します。
組み込みサンプルの一覧から hotels-sample を選択します。
[次: コグニティブ スキルを追加します (省略可能)] を選択して続行します。
![[データのインポート] ウィザードで [hotels-sample] データ ソースを選ぶ方法を示すスクリーンショット。](media/search-get-started-portal/import-hotels-sample.png)
コグニティブ スキルの構成をスキップする
ウィザードでは、インデックス作成中のスキルセットの作成と AI エンリッチメント がサポートされますが、コグニティブ スキルはこのクイック スタートの範囲外です。
ウィザードでこの手順をスキップするには:
[ コグニティブ スキルの追加] で、AI エンリッチメント構成オプションを無視します。
[次へ: ターゲット インデックスをカスタマイズして続行する] を選択します。
![[データのインポート] ウィザードで [Customize target index] (対象インデックスをカスタマイズ) タブにスキップする方法を示すスクリーンショット。](media/search-get-started-portal/skip-cognitive-skills.png)
ヒント
AI エンリッチメントの概要については、「 クイック スタート: Azure portal でスキルセットを作成する」を参照してください。
インデックスの構成
ウィザードは、hotels-sample インデックスのスキーマを推論します。 インデックスを構成するには:
システムによって生成された インデックス名 (hotels-sample-index) と Key (HotelId) の値を受け入れます。
システムによって生成された値をすべてのフィールド属性にそのまま使用します。
[次: インデクサーの作成] を選択して続行します。
![[データのインポート] ウィザードで生成された [hotels-sample] データ ソースのインデックス定義を示すスクリーンショット。](media/search-get-started-portal/hotels-sample-generated-index.png)
少なくとも、検索インデックスには名前とフィールドのコレクションが必要です。 ウィザードは、一意の文字列フィールドをスキャンし、1 つをドキュメント キーとしてマークし、インデックス内の各ドキュメントを一意に識別します。
各フィールドには、名前、データ型、およびインデックスでのフィールドの使用方法を制御する属性があります。 チェックボックスを使用して、次の属性を有効または無効にします。
| 特性 | 説明 | 適用可能なデータ型 |
|---|---|---|
| 取得可能 | クエリ応答で返されるフィールド。 | 文字列と整数 |
| フィルターの適用 | フィルター式を指定できるフィールド。 | 整数 |
| 並べ替え可能 | orderby 式を指定できるフィールド。 | 整数 |
| ファセット可能 | ファセット ナビゲーション構造で使用されるフィールド。 | 整数 |
| 検索可能 | フルテキスト検索で使用されるフィールド。 文字列は検索可能ですが、多くの場合、数値フィールドとブール型フィールドは検索不可としてマークされます。 | ストリングス |
属性は、さまざまな方法でストレージに影響します。 たとえば、フィルター可能なフィールドは追加のストレージを使用しますが、取得可能なフィールドは使用しません。 詳細については、「属性と suggester がストレージに与える影響を示す例」を参照してください。
オートコンプリートやクエリ候補が必要な場合は、言語アナライザーまたはサジェスターを指定できます。
インデクサーを構成して実行する
最後に、実行可能プロセスを定義するインデクサーを構成して実行します。 この手順では、データ ソースとインデックスも作成されます。
インデクサーを構成して実行するには:
システムによって生成された値を [Indexer name] (インデクサー名) (hotels-sample-indexer) にそのまま使用します。
このクイック スタートでは、既定のオプションを使用して、インデクサーをすぐに 1 回だけ実行します。 サンプル データは静的であるため、変更の追跡を有効にすることはできません。
[送信] を選択して、インデクサーを同時に作成して実行します。
![[データのインポート] ウィザードで [hotels-sample] データ ソースのインデクサーを構成する方法を示すスクリーンショット。](media/search-get-started-portal/hotels-sample-indexer.png)
インデクサーの進行状況を監視する
Azure portal でインデクサーとインデックスの作成を監視できます。 [ 概要 ] タブには、検索サービスで作成されたリソースへのリンクが表示されます。
インデクサーの進行状況を監視するには:
Azure portal で、Search サービスに移動します。
左側のウィンドウで、[ インデクサー] を選択します。
![Azure portal でインデクサー作成の [実行中] の進行状況を示すスクリーンショット。](media/search-get-started-portal/indexers-status.png)
結果が更新されるまで数分かかる場合があります。 新しく作成されたインデクサーの状態が [進行中] または [成功] であることがわかります。 一覧には、インデックスが作成されたドキュメントの数も表示されます。
検索インデックスの結果をチェックする
Azure portal で、Search サービスに移動します。
左側のウィンドウで、[ インデックス] を選択します。
[hotels-sample-index] を選びます。 インデックスにドキュメントまたはストレージが 0 個ある場合は、Azure portal が更新されるまで待ちます。
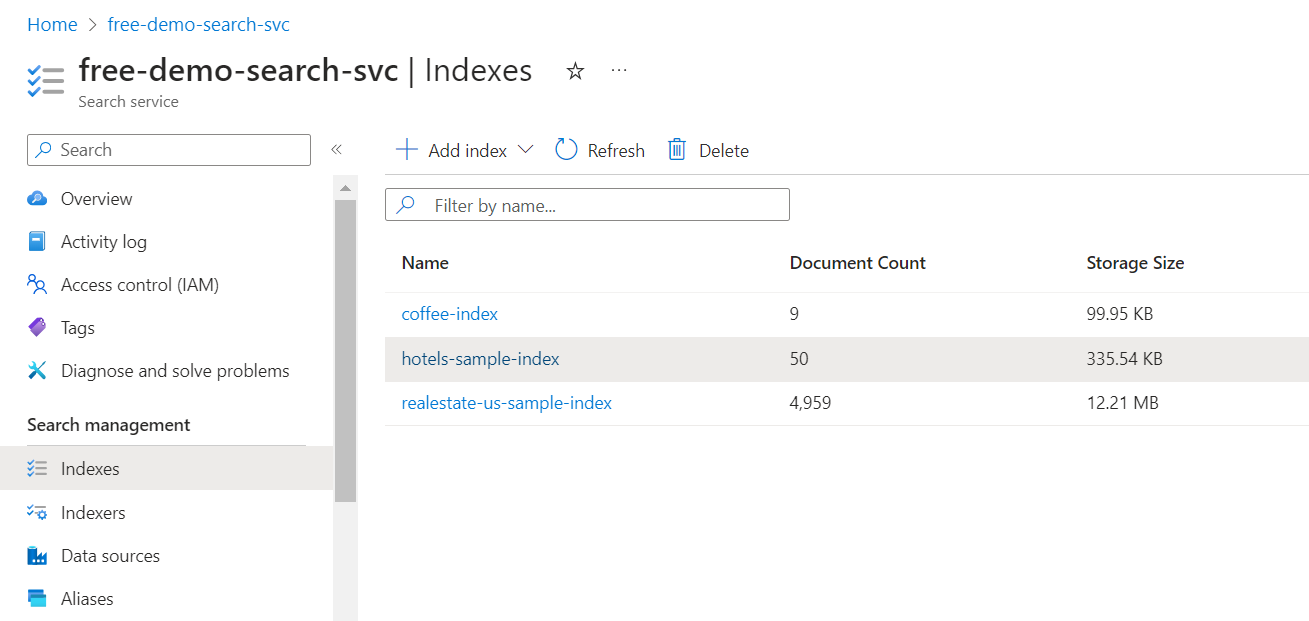
[フィールド] タブを選択して、インデックス スキーマを表示します。
書き込むクエリがわかるように、 フィルター可能 または 並べ替え可能な フィールドを確認します。
フィールドを追加または変更する
[フィールド] タブでは、[フィールドの追加] を選択し、名前、サポートされているデータ型、および属性を指定することで、フィールドを作成できます。
既存のフィールドを変更することはより困難です。 既存のフィールドには検索インデックスに物理的な表現があるため、コード内でも変更できません。 既存のフィールドを根本的に変更するには、元のフィールドを置き換える新しいフィールドを作成する必要があります。 スコアリング プロファイルや CORS オプションなどの他のコンストラクトは、いつでもインデックスに追加できます。
インデックス定義オプションを確認して、インデックスの設計時に編集できる内容と編集できないことを理解します。 オプションが淡色表示の場合、変更や削除はできません。
検索エクスプローラーを使用したクエリ実行
検索 エクスプローラーを使用してクエリを実行できる検索インデックスが作成されました。これにより、 Search POST REST API に準拠する REST 呼び出しが送信されます。 このツールでは、 単純なクエリ構文 と 完全な Lucene クエリ構文がサポートされています。
検索インデックスに対してクエリを実行するには:
[Search エクスプローラー] タブで、検索するテキストを入力します。
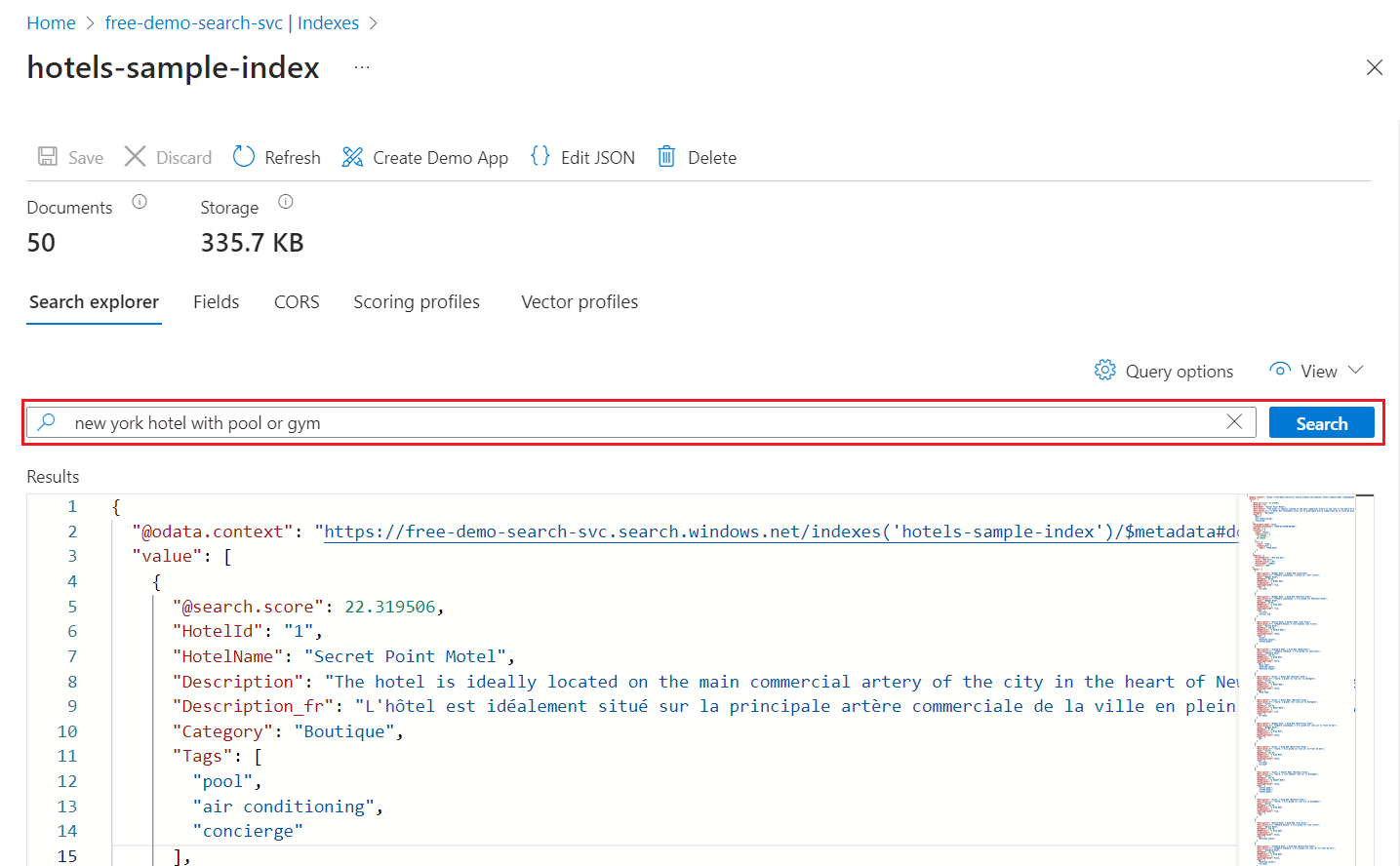
出力の非表示領域にジャンプするには、ミニ マップを使用します。
構文を指定するには、JSON ビューに切り替えます。
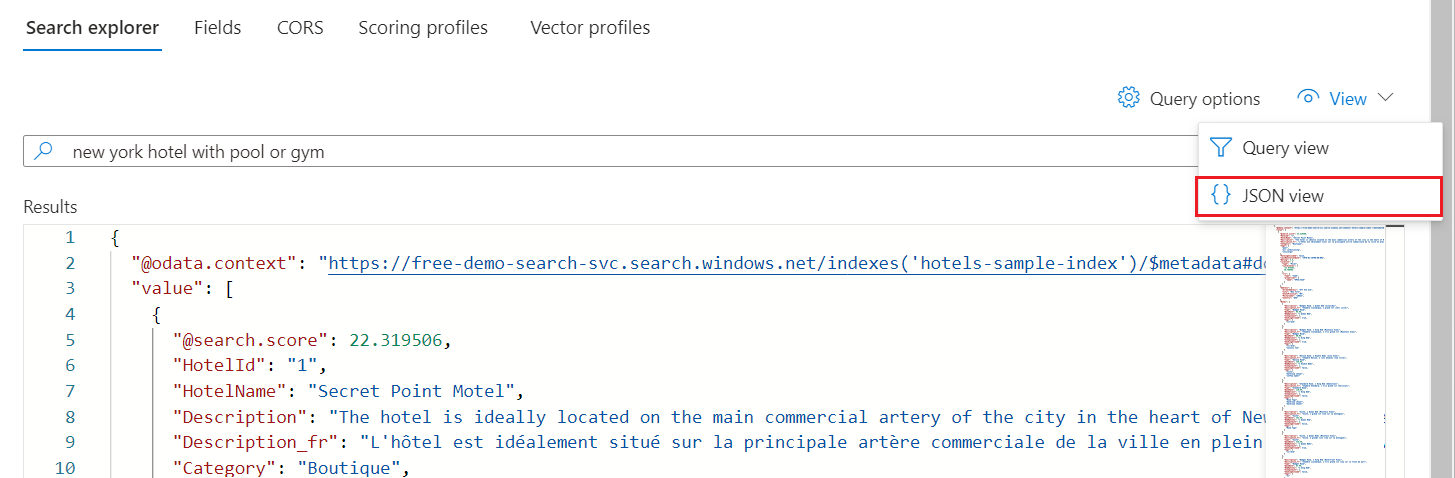
hotels-sample インデックスのクエリ例
以下の例では、JSON ビューと 2024-05-01-preview REST API バージョンを想定しています。
ヒント
JSON ビューでは、パラメーター名を補完する IntelliSense がサポートされています。 JSON ビュー内にカーソルを置き、スペース文字を入力して、すべてのクエリ パラメーターの一覧を表示します。 "s" などの文字を入力して、その文字で始まるクエリ パラメーターのみを表示することもできます。 Intellisense では無効なパラメーターが除外されないため、最適な判断を使用してください。
フィルターの例
Parking、Tags、Renovation Date、Rating、Location はフィルター可能です。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "Rating gt 4"
}
ブール値のフィルターは、既定では "true" を想定します。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "ParkingIncluded"
}
地理空間検索はフィルターベースです。 geo.distance 関数は、指定した Location と geography'POINT の各座標に基づいて位置データのすべての結果をフィルター処理します。 このクエリでは、緯度と経度の座標 -122.12 47.67から 5 km 以内のホテルを検索します。これは "Redmond, Washington, USA" です。クエリには、ホテル名と住所の場所に &$count=true 一致する合計数が表示されます。
{
"search": "*",
"select": "HotelName, Address/City, Address/StateProvince",
"count": true,
"top": 10,
"filter": "geo.distance(Location, geography'POINT(-122.12 47.67)') le 5"
}
完全な Lucene 構文の例
既定の構文は 単純な構文ですが、あいまい検索、用語ブースト、または正規表現が必要な場合は、 完全な構文を指定します。
{
"queryType": "full",
"search": "seatle~",
"select": "HotelId, HotelName,Address/City, Address/StateProvince",
"count": true
}
Seattleの代わりにseatleなどのクエリ用語のスペルが間違っている場合、一般的な検索では一致が返されません。 queryType=full パラメーターは、チルダ (~) オペランドをサポートする完全な Lucene クエリ パーサーを呼び出します。 これらのパラメーターを使用すると、クエリは指定されたキーワードのあいまい検索を実行し、類似しているが完全一致ではない用語に一致します。
インデックスに対してこれらのサンプル クエリを試すには、少し時間がかかります。 クエリについて詳しくは、「Azure AI Search でのクエリ実行」を参照してください。
リソースをクリーンアップする
独自のサブスクリプションを使用する場合は、プロジェクトの最後に、作成したリソースがまだ必要かどうかを確認することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースを個別に削除するか、リソース グループを削除してリソースのセット全体を削除することができます。
Azure portal では、左側のウィンドウの [すべての リソース] または [ リソース グループ ] で、サービスのリソースを見つけて管理できます。
注
無料の検索サービスを使用している場合、制限は 3 つのインデックス、3 つのインデクサー、3 つのデータ ソースです。 Azure portal で個々のオブジェクトを削除して、制限を超えないようにすることができます。
次のステップ
Azure portal のウィザードで、ブラウザーで動作するすぐに使用できる Web アプリを生成してみましょう。 このクイック スタートで作成した小さなインデックスでこのウィザードを使用するか、組み込みのサンプル データセットの 1 つを使用して、より豊富な検索エクスペリエンスを実現します。