このクイック スタートでは、Web ツールを使用して Azure Synapse でサーバーレス Apache Spark プールを作成する方法について説明します。 その後、Apache Spark プールに接続し、ファイルとテーブルに対して Spark SQL クエリを実行する方法について説明します。 Apache Spark を使用すると、インメモリ処理を使用した高速なデータ分析とクラスター コンピューティングが可能になります。 Azure Synapse の Spark の詳細については、「 概要: Azure Synapse 上の Apache Spark」を参照してください。
重要
Spark インスタンスの課金は、使用しているかどうかに関係なく、分単位で日割り計算されます。 Spark インスタンスの使用が完了したら、必ずシャットダウンするか、短いタイムアウトを設定してください。 詳細については、この記事の「 リソースのクリーンアップ 」セクションを参照してください。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
- Azure サブスクリプションが必要です。 必要に応じて、 無料の Azure アカウントを作成します
- Synapse Analytics ワークスペース
- サーバーレス Apache Spark プール
Azure portal にサインインする
Azure portal にサインインします。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料の Azure アカウントを作成してください。
ノートブックを作成する
ノートブックは、さまざまなプログラミング言語をサポートする対話型環境です。 ノートブックを使用すると、データを操作したり、コードとマークダウン、テキストを組み合わせたり、簡単な視覚化を実行したりできます。
使用する Azure Synapse ワークスペースの Azure portal ビューで、[ Launch Synapse Studio]\(Synapse Studio の起動\) を選択します。
Synapse Studio が起動したら、[ 開発] を選択します。 次に、"+" アイコンを選択して新しいリソースを追加します。
そこから[ノートブック]を選択 します。 新しいノートブックが作成され、自動的に生成された名前で開かれます。

[ プロパティ ] ウィンドウで、ノートブックの名前を指定します。
ツール バーの [ 発行] をクリックします。
ワークスペースに Apache Spark プールが 1 つしかない場合は、既定で選択されます。 何も選択されていない場合は、ドロップダウンを使用して適切な Apache Spark プールを選択します。
[ コードの追加] をクリックします。 既定の言語は
Pysparkです。 Pyspark と Spark SQL を組み合わせて使用するため、既定の選択肢は問題ありません。 サポートされているその他の言語は、Spark 用の Scala と .NET です。次に、操作する単純な Spark DataFrame オブジェクトを作成します。 この場合は、コードから作成します。 3 つの行と 3 つの列があります。
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()次に、次のいずれかの方法を使用してセルを実行します。
Shift キーを押しながら Enter キーを押します。
セルの左側にある青い再生アイコンを選択します。
ツール バーの [ すべて実行 ] ボタンを選択します。
Apache Spark プール インスタンスがまだ実行されていない場合は、自動的に開始されます。 実行中のセルの下の Apache Spark プール インスタンスの状態と、ノートブックの下部にある状態パネルを確認できます。 プールのサイズに応じて、開始には 2 ~ 5 分かかります。 コードの実行が完了すると、セルの下に、実行にかかった時間とその実行時間を示す情報が表示されます。 出力セルに出力が表示されます。
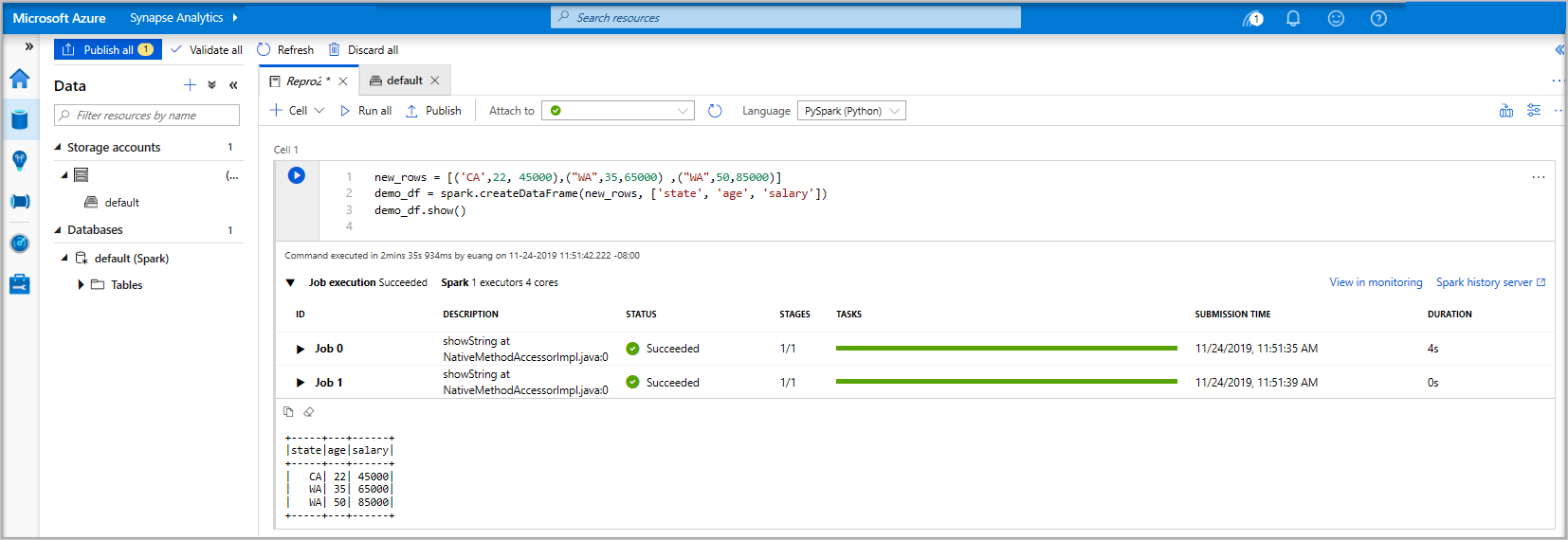
そこから DataFrame にデータが存在し、さまざまな方法でデータを使用できるようになりました。 このクイックスタートの残りの部分では、異なる形式でそれが必要になります。
次のコードを別のセルに入力して実行すると、Spark テーブル、CSV、Parquet ファイルがすべてデータのコピーと共に作成されます。
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')ストレージ エクスプローラーを使用する場合は、上記で使用したファイルを記述する 2 つの異なる方法の影響を確認できます。 ファイル システムが指定されていない場合は、既定値が使用されます。この場合は
default>user>trusted-service-user>demo_df。 データは、指定されたファイル システムの場所に保存されます。"csv" 形式と "parquet" 形式の両方で、書き込みプロセス中に、多数のパーティションに分割されたファイルでディレクトリが作成されることに注目してください。


Spark SQL ステートメントを実行する
構造化クエリ言語 (SQL) は、データのクエリと定義に最も一般的で広く使用されている言語です。 Spark SQL は、使い慣れた SQL 構文を使用して、構造化データを処理するための Apache Spark の拡張機能として機能します。
次のコードを空のセルに貼り付け、コードを実行します。 このコマンドは、プール上のテーブルを一覧表示します。
%%sql SHOW TABLESAzure Synapse Apache Spark プールで Notebook を使用すると、Spark SQL を使用してクエリを実行するために使用できるプリセット
sqlContextが得られます。%%sqlは、プリセットsqlContextを使用してクエリを実行するようにノートブックに指示します。 このクエリは、既定ですべての Azure Synapse Apache Spark プールに付属するシステム テーブルから上位 10 行を取得します。別のクエリを実行して、
demo_df内のデータを確認します。%%sql SELECT * FROM demo_dfこのコードでは、2 つの出力セルが生成されます。1 つはデータ結果を含み、もう 1 つはジョブ ビューを示しています。
既定では、結果ビューにはグリッドが表示されます。 ただし、グリッドの下にビュー スイッチャーがあり、ビューでグリッド ビューとグラフ ビューを切り替えることができます。

ビュー スイッチャーで、[グラフ] を選択します。
右端から [表示オプション ] アイコンを選択します。
[ グラフの種類 ] フィールドで、[横棒グラフ] を選択します。
[X 軸の列] フィールドで、[状態] を選択します。
[Y 軸の列] フィールドで、[給与] を選択します。
[ 集計 ] フィールドで、[AVG] を選択します。
を選択してを適用します。

SQL の実行と同じエクスペリエンスを得ることができますが、言語を切り替える必要はありません。 これを行うには、上記の SQL セルをこの PySpark セルに置き換えます。 表示 コマンドが使用されるため、出力エクスペリエンスは同じです。
display(spark.sql('SELECT * FROM demo_df'))以前に実行した各セルには、 履歴サーバー と 監視に移動するオプションがありました。 リンクをクリックすると、ユーザー エクスペリエンスのさまざまな部分に移動します。
注
一部の Apache Spark 公式ドキュメント では、Synapse Spark では使用できない Spark コンソールの使用に依存しています。 代わりに ノートブック または IntelliJ エクスペリエンスを使用してください。
リソースをクリーンアップする
Azure Synapse は、データを Azure Data Lake Storage に保存します。 Spark インスタンスが使用されていない場合は、安全にシャットダウンできます。 サーバーレス Apache Spark プールは、使用中でない場合でも、実行されている限り課金されます。
プールの料金はストレージの料金よりも何倍も多いため、Spark インスタンスが使用されていないときにシャットダウンすることは経済的に理にかなっています。
Spark インスタンスがシャットダウンされるようにするには、接続されているセッション (ノートブック) を終了します。 プールは、Apache Spark プールに指定されているアイドル時間に達したときにシャットダウンされます。 ノートブックの下部にあるステータス バーから セッションの終了 を選択することもできます。
次のステップ
このクイック スタートでは、サーバーレス Apache Spark プールを作成し、基本的な Spark SQL クエリを実行する方法について説明しました。