このチュートリアルでは、Azure Open Datasets と Apache Spark を使用して探索的データ分析を実行する方法について説明します。 その後、Azure Synapse Analytics の Synapse Studio ノートブックで結果を視覚化できます。
特に、 ニューヨーク市 (NYC) のタクシー データセットを分析します。 データは Azure Open Datasets から入手できます。 このデータセットのサブセットには、イエロー タクシー乗車に関する情報 (各乗車、出発と到着の時刻、場所、料金、その他の関心の高い属性に関する情報) が格納されます。
開始する前に
Apache Spark プールの作成に関するチュートリアルに従って 、Apache Spark プールを作成します。
データのダウンロードと準備
PySpark カーネルを使用してノートブックを作成します。 手順については、「 ノートブックの作成」を参照してください。
注
PySpark カーネルのため、コンテキストを明示的に作成する必要はありません。 最初のコード セルを実行すると、Spark コンテキストが自動的に作成されます。
このチュートリアルでは、データセットの視覚化に役立ついくつかの異なるライブラリを使用します。 この分析を行うために、次のライブラリをインポートします。
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd生データは Parquet 形式であるため、Spark コンテキストを使用して、ファイルを DataFrame として直接メモリにプルできます。 Open Datasets API を使用してデータを取得して Spark DataFrame を作成します。 ここでは、 読み取りプロパティで Spark DataFrame スキーマを使用して、データ型とスキーマを推論します。
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())データが読み取られた後、データセットをクリーンアップするために最初のフィルター処理を行います。 不要な列を削除し、重要な情報を抽出する列を追加する場合があります。 さらに、データセット内の異常を除外します。
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
データを分析する
データ アナリストとして、データからの分析情報の抽出に役立つ幅広いツールを利用できます。 このチュートリアルのこの部分では、Azure Synapse Analytics ノートブック内で使用できる便利なツールをいくつか紹介します。 この分析では、選択した期間にタクシーのチップが高くなる要因を理解したいと考えています。
Apache Spark SQL マジック
まず、Azure Synapse ノートブックを使用して、Apache Spark SQL とマジック コマンドによる探索的データ分析を実行します。 クエリを作成したら、組み込みの chart options 機能を使用して結果を視覚化します。
ノートブック内に新しいセルを作成し、次のコードをコピーします。 このクエリを使用して、選択した期間に平均チップ金額がどのように変化したかを理解したいと考えています。 このクエリは、1 日あたりのチップの最小/最大金額や平均料金など、他の有用な分析情報を特定するのにも役立ちます。
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCクエリの実行が完了したら、グラフ ビューに切り替えることで結果を視覚化できます。 この例では、キーとして
day_of_monthフィールドを、値としてavgTipAmountを指定して、折れ線グラフを作成します。 選択した後、[ 適用 ] を選択してグラフを更新します。
データの視覚化
組み込みのノートブック グラフ作成オプションに加えて、人気のあるオープンソース ライブラリを使用して独自の視覚化を作成することもできます。 次の例では、Seaborn と Matplotlib を使用します。 これらは、データの視覚化に一般的に使用される Python ライブラリです。
注
既定では、Azure Synapse Analytics 内のすべての Apache Spark プールには、一般的に使用されるライブラリと既定のライブラリのセットが含まれています。 ライブラリの完全な一覧は、 Azure Synapse ランタイム のドキュメントで確認できます。 さらに、サードパーティ製またはローカルでビルドされたコードをアプリケーションで使用できるようにするには、いずれかの Spark プールに ライブラリをインストール します。
開発を容易にし、コストを抑えるために、データセットをダウンサンプリングします。 組み込みの Apache Spark サンプリング機能を使用します。 さらに、Seaborn と Matplotlib の両方に、Pandas データフレームまたは Numpy 配列が必要です。 Pandas データフレームを取得するには、
toPandas()コマンドを使用してデータフレームを変換します。# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()データセット内のヒントの分布を理解する必要があります。 Matplotlib を使用して、チップの量と数の分布を示すヒストグラムを作成します。 分布に基づいて、チップが$10以下に偏っていることがわかります。
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()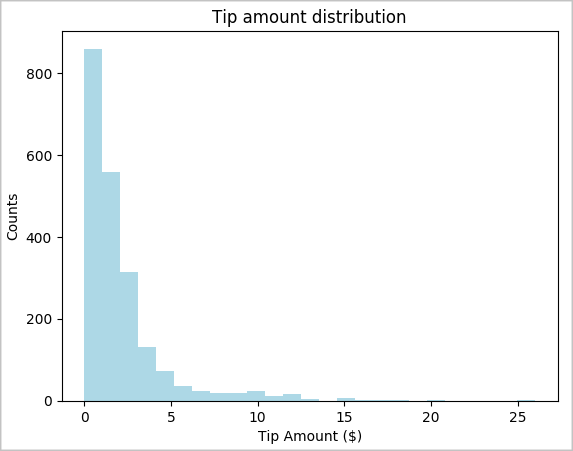
次に、特定の旅行のヒントと曜日の関係を理解したいと考えています。 Seaborn を使用して、各曜日の傾向をまとめた箱ひげ図を作成します。
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()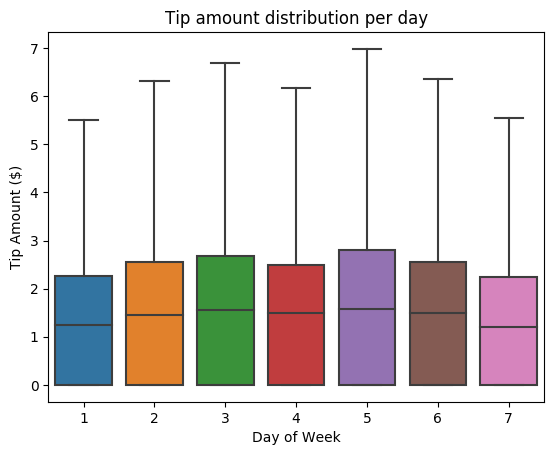
私たちのもう一つの仮説は、乗客数とタクシーチップの合計量の間に肯定的な関係があるということです。 この関係を検証するために、次のコードを実行して、乗客数ごとのチップの分布を示す箱ひげ図を生成します。
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()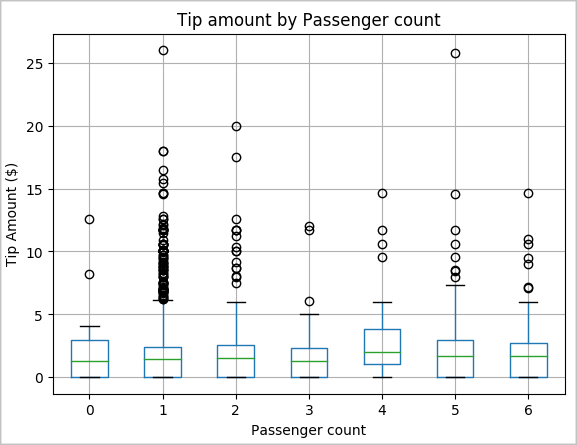
最後に、運賃額とチップ金額の関係を理解したいと考えています。 結果に基づいて、人々がチップを渡さない観察がいくつかあることがわかります。 ただし、運賃全体とチップ金額の間にプラスの関係もあります。
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()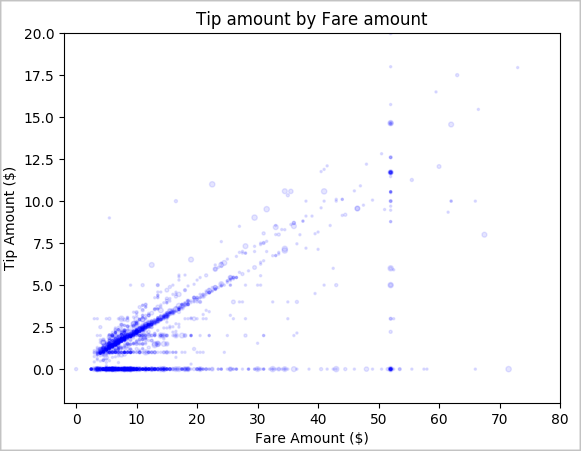
Spark インスタンスをシャットダウンする
アプリケーションの実行が完了したら、ノートブックをシャットダウンしてリソースを解放します。 タブを閉じるか、ノートブックの下部にある状態パネルから [ セッションの終了 ] を選択します。