この記事では、Apache Spark MLlib を使用して、Azure オープン データセットに対して単純な予測分析を行う機械学習アプリケーションを作成する方法について説明します。 Spark には、組み込みの機械学習ライブラリが用意されています。 この例では、ロジスティック回帰による 分類 を使用します。
SparkML と MLlib は、機械学習タスクに役立つ多くのユーティリティを提供するコア Spark ライブラリです。これには、次に適したユーティリティが含まれます。
- Classification
- Regression
- Clustering
- トピックのモデリング
- 特異値分解 (SVD) と主成分分析 (PCA)
- 仮説検定とサンプル統計の計算
分類とロジスティック回帰について
機械学習の一般的なタスクである分類は、入力データをカテゴリに並べ替えるプロセスです。 指定した入力データに ラベル を割り当てる方法を見極めるのは、分類アルゴリズムの仕事です。 たとえば、株式情報を入力として受け入れ、株式を 2 つのカテゴリに分割する機械学習アルゴリズムを考えることができます。つまり、販売する必要がある株式と保持する必要がある株式です。
ロジスティック回帰 は、分類に使用できるアルゴリズムです。 Spark のロジスティック回帰 API は、 二項分類、または入力データを 2 つのグループのいずれかに分類する場合に役立ちます。 ロジスティック回帰の詳細については、 Wikipedia を参照してください。
要約すると、ロジスティック回帰のプロセスによって ロジスティック関数 が生成されます。この関数を使用して、入力ベクターが一方または他方のグループに属する確率を予測できます。
NYC タクシー データの予測分析の例
この例では、Spark を使用して、ニューヨークからのタクシー乗車チップ データに対して予測分析を実行します。 データは、 Azure Open Datasets を通じて使用できます。 データセットのこのサブセットには、各乗車に関する情報、開始時刻と終了時刻と場所、コスト、その他の興味深い属性など、黄色のタクシー乗車に関する情報が含まれています。
Important
このデータをストレージの場所からプルする場合、追加料金が発生する可能性があります。
次の手順では、特定の乗車にチップが含まれているかどうかを予測するモデルを開発します。
Apache Spark 機械学習モデルを作成する
PySpark カーネルを使用してノートブックを作成します。 手順については、「 ノートブックの作成」を参照してください。
このアプリケーションに必要な型をインポートします。 次のコードをコピーして空のセルに貼り付け、Shift キーを押しながら Enter キーを押します。 または、コードの左側にある青い再生アイコンを使用してセルを実行します。
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorPySpark カーネルのため、コンテキストを明示的に作成する必要はありません。 最初のコード セルを実行すると、Spark コンテキストが自動的に作成されます。
入力 DataFrame を構築する
生データは Parquet 形式であるため、Spark コンテキストを使用して、ファイルを DataFrame として直接メモリにプルできます。 次の手順のコードでは既定のオプションを使用しますが、必要に応じて、データ型とその他のスキーマ属性のマッピングを強制することができます。
次の行を実行して、新しいセルにコードを貼り付けて Spark DataFrame を作成します。 この手順では、Open Datasets API を使用してデータを取得します。 このデータをすべてプルすると、約 15 億行が生成されます。
サーバーレス Apache Spark プールのサイズによっては、生データが大きすぎるか、操作に時間がかかりすぎる場合があります。 このデータをフィルター処理して、より小さなデータに絞り込むことができます。 次のコード例では、
start_dateとend_dateを使用して、1 か月分のデータを返すフィルターを適用します。from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())単純なフィルター処理の欠点は、統計的な観点からは、データに偏りが生じる可能性があるということです。 もう 1 つの方法は、Spark に組み込まれているサンプリングを使用することです。
次のコードは、前のコードの後に適用されている場合、データセットを約 2,000 行に減らします。 このサンプリング 手順は、単純なフィルターの代わりに使用することも、単純なフィルターと組み合わせて使用することもできます。
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)データを見て、読み取られた内容を確認できるようになりました。 通常は、データセットのサイズに応じて、完全なセットではなくサブセットでデータを確認することをお勧めします。
次のコードは、データを表示する 2 つの方法を提供します。 最初の方法は基本的なものです。 2 つ目の方法では、データをグラフィカルに視覚化する機能と共に、より豊富なグリッド エクスペリエンスが提供されます。
#sampled_taxi_df.show(5) display(sampled_taxi_df)生成されたデータセットのサイズと、ノートブックを何度も実験または実行する必要に応じて、データセットをワークスペースにローカルにキャッシュすることができます。 明示的なキャッシュを実行するには、次の 3 つの方法があります。
- DataFrame をファイルとしてローカルに保存します。
- DataFrame を一時テーブルまたは一時ビューとして保存します。
- DataFrame を永続的なテーブルとして保存します。
これらの方法の最初の 2 つは、次のコード例に含まれています。
一時テーブルまたはビューを作成すると、データへの異なるアクセス パスが提供されますが、これは Spark インスタンス セッションの期間中のみ続きます。
sampled_taxi_df.createOrReplaceTempView("nytaxi")
データを準備する
生形式のデータは、多くの場合、モデルに直接渡すには適していません。 データをモデルが使用できる状態にするには、データに対して一連のアクションを実行する必要があります。
次のコードでは、4 つのクラスの操作を実行します。
- フィルター処理による外れ値または正しくない値の削除。
- 不要な列の削除。
- モデルをより効果的に機能させるために生データから派生した新しい列の作成。 この操作は、特徴付けと呼ばれることもあります。
- ラベリング。 二項分類を行うため (特定の乗車にチップがあるかどうか)、チップの金額を 0 または 1 の値に変換する必要があります。
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
次に、データを 2 回目に渡して、最終的な特徴を追加します。
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
ロジスティック回帰モデルを作成する
最後のタスクは、ラベル付けされたデータをロジスティック回帰を使用して分析できる形式に変換することです。 ロジスティック回帰アルゴリズムへの入力は、 ラベルと特徴ベクトルのペアのセットである必要があります。 特徴ベクトル は、入力ポイントを表す数値のベクトルです。
そのため、カテゴリ列を数値に変換する必要があります。 具体的には、 trafficTimeBins 列と weekdayString 列を整数表現に変換する必要があります。 変換を実行するには、複数の方法があります。 次の例では、一般的な OneHotEncoder アプローチを使用します。
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
このアクションにより、モデルをトレーニングするための適切な形式のすべての列を含む新しい DataFrame が作成されます。
ロジスティック回帰モデルをトレーニングする
最初のタスクは、データセットをトレーニング セットとテストまたは検証セットに分割することです。 ここでの分割は任意です。 異なる分割設定を試して、それらがモデルに影響するかどうかを確認します。
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
これで 2 つの DataFrame が作成されたので、次のタスクはモデル式を作成し、トレーニング DataFrame に対して実行することです。 その後、テストデータフレームに対して検証できます。 さまざまなバージョンのモデル式を試して、さまざまな組み合わせの影響を確認します。
注
モデルを保存するには、 ストレージ BLOB データ共同作成者 ロールを Azure SQL Database サーバー リソース スコープに割り当てます。 詳細な手順については、「Azure portal を使用して Azure ロールを割り当てる」を参照してください。 この手順を実行できるのは、所有者特権を持つメンバーだけです。
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
このセルからの出力は次のとおりです。
Area under ROC = 0.9779470729751403
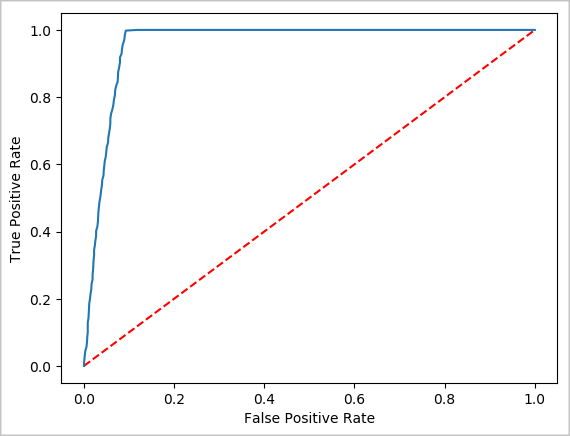
予測の視覚的表現を作成する
これで、このテストの結果に関する理由を理解するのに役立つ最終的な視覚化を構築できるようになりました。 ROC 曲線は、結果を確認する 1 つの方法です。
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Spark インスタンスをシャットダウンする
アプリケーションの実行が完了したら、タブを閉じてノートブックをシャットダウンしてリソースを解放します。または、ノートブックの下部にある状態パネルから [ セッションの終了 ] を選択します。