ユーザーは、Azure Synapse Analytics で Spark プールを作成し、分析ワークロードの要件に基づいてそのサイズを設定します。 エンタープライズ チームが複数のデータ エンジニアリング プロセスに Spark プールを使うのは一般的なことであり、プールの使用は、データ インジェスト率、データ量、その他の要因によって異なる場合があります。 Spark プールは、コンピューティング集中型のデータ変換やデータ探索プロセスの実行にも使われることがあり、このような場合、ユーザーは自動スケーリング オプションを有効にして、ノードの最小数と最大数を指定できます。プラットフォームは、需要に基づいて、これらの制限内でアクティブなノードの数をスケーリングします。
さらに進んでアプリケーション レベルの Executor の要件を見ると、Executor の構成は Spark ジョブ実行プロセスのさまざまなステージで大きく異なるので、ユーザーがそれを調整するのは難しいことがわかります。これは、随時変化する処理対象のデータ量にも依存します。 ユーザーは、プール構成の一部として Executor の動的割り当てオプションを有効にできます。これにより、Spark プールで使用可能なノードに基づく Spark アプリケーションへの Executor の自動割り当てが有効になります。
動的割り当てオプションを有効にすると、送信されるすべての Spark アプリケーションについて、システムは、正常な自動スケーリング シナリオをサポートするためにユーザーが指定した最大ノード数に基づいて、ジョブの送信ステップの間に Executor を "予約" します。
Note
この控えめなアプローチにより、プラットフォームは容量を使い切ることなくたとえば 3 ノードから 10 ノードにスケーリングでき、ユーザーに対するジョブの実行の信頼性が向上します。
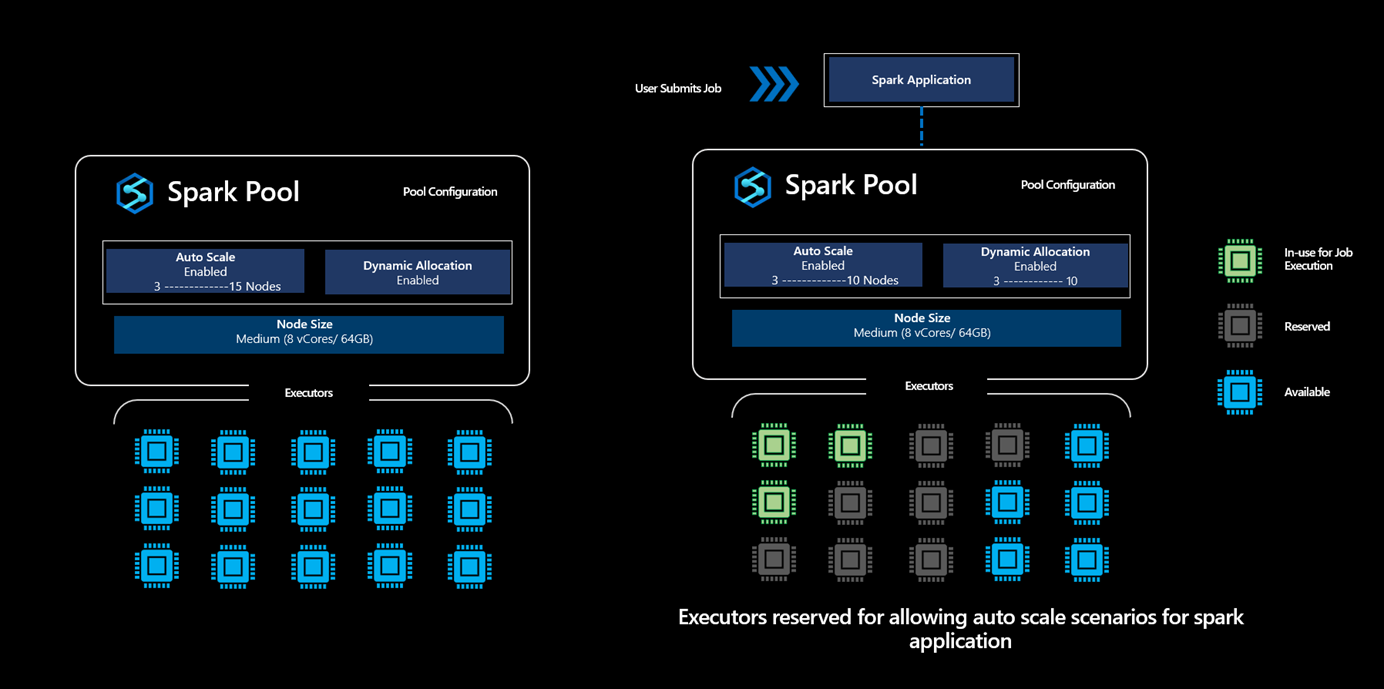
Executor の予約の意味
Synapse Spark プールで動的割り当てオプションが有効になっているシナリオでは、プラットフォームは、送信される Spark アプリケーションに対してユーザーが指定した上限に基づいて Executor の数を予約します。 ユーザーによって送信された新しいジョブは、使用可能な Executor の数が予約された Executor の最大数より多い場合にのみ受け付けられます。
重要
ただし、ユーザーは予約状態のコア数ではなく、使われたコア数に対してのみ課金されるため、この予約アクティビティが課金に影響を与えることはありません。
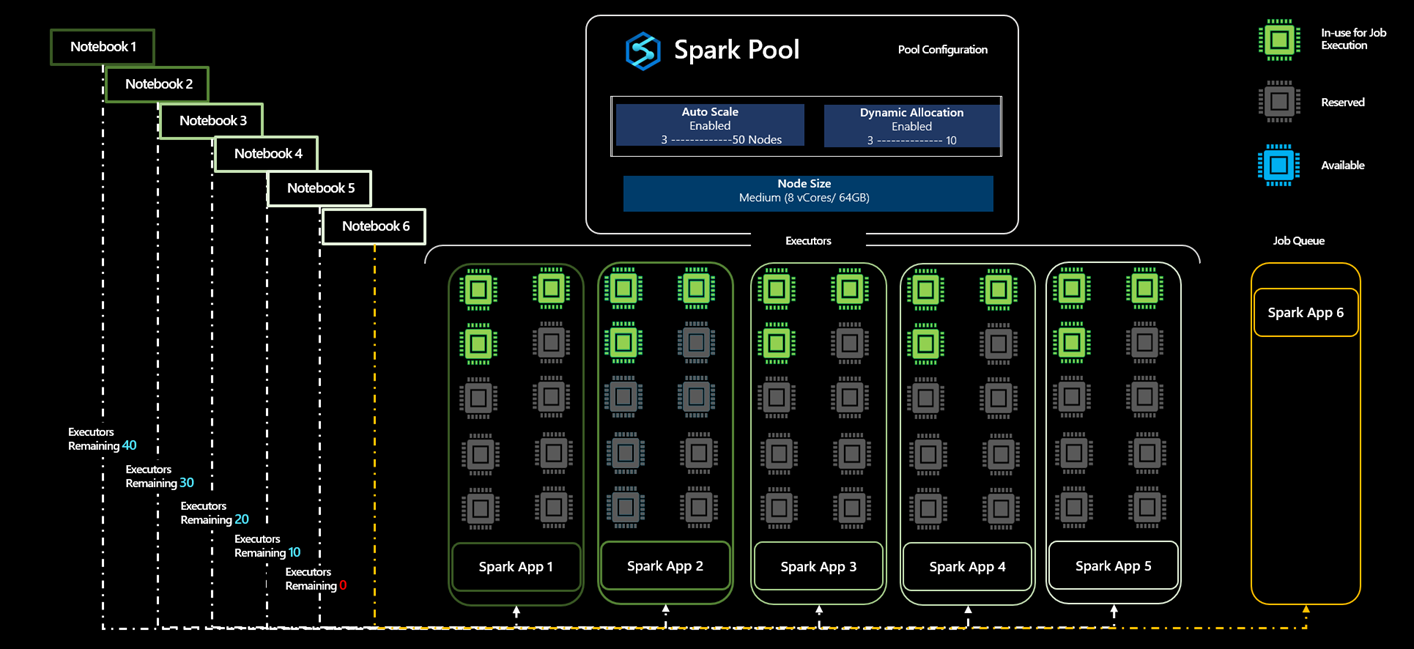
Spark プールに対して複数のジョブが送信されたときの、この動的割り当ての動作
最小 5 ノードから最大 50 ノードで自動スケーリングが有効にされた Spark プール A を作成する 1 人のユーザーのシナリオ例を見てみましょう。 ユーザーは、Spark ジョブで必要なコンピューティング量がわからないため、動的割り当てを有効にして、Executor のスケーリングを許可します。
- ユーザーは、最初にアプリケーション App1 を送信します。それは、3 個の Executor で開始し、3 から 10 個の範囲で Executor をスケーリングできます。
- Spark プールに割り当てられるノードの最大数は 50 です。 App1 を送信すると 10 個の Executor が予約されるため、Spark プール内の使用可能な Executor の数は 40 に減ります。
- ユーザーは、App1 と同じコンピューティング構成を持つ別の Spark アプリケーション App2 を送信します。そのアプリケーションは 3 個で始まり、最大 10 個の Executor までスケールアップできます。それにより、Spark プールで使用可能な合計 Executor からさらに 10 個の Executor が予約されます。
- Spark プールで使用可能な Executor の総数は 30 に減っています。
- ユーザーは、他のアプリケーションと同じアプリケーション App3、App4、App5 を送信します。アプリケーションが受け付けられるとプールで使用可能な Executor のセットから 10 個の Executor が予約されるため、App3 が受け付けられると使用可能な Executor は 20 個に減り、同じように 10 個に減り、App5 が受け付けられると 0 になるため、6 番目のジョブはキューに入れられます。
- 使用可能なコアが存在しない場合、App6 はこれらの他のアプリケーションの実行が完了するまでキューに入れられ、プールで使用可能な Executor の数が 0 から 10 に増えると受け付けられます。
Note
- Executor の予約が行われても、すべての Executor が使われるわけではなく、これらのアプリケーションの自動スケーリングのシナリオをサポートするために予約されています。
- App1、App2、App3、App4、App5 のすべてのアプリケーションが最小ノード容量で実行できた場合、この実行に使われる Executor は合計 15 個ですが、これらのアプリケーションの実行中に Executor を 3 個から 10 個にスケールアウトできるように、残りの 35 個の Executor が予約の一部として追加されます。
- 35 個の Executor が予約されますが、ユーザーに請求されるのは使われた 15 個の Executor についだけであり、予約状態の 35 個の Executor については課金されません。
- 動的割り当てが無効にされているとき: ユーザーが動的割り当てを無効にしたシナリオでの Executor の予約は、ユーザーが指定した Executor の最小数と最大数に基づいて行われます。
- 上の例のユーザーが Executor の数を 5 に指定した場合、送信されるすべてのアプリケーションで 5 個の Executor が予約され、ユーザーは App6 を送信でき、キューに登録されません。
Synapse ワークスペースの Spark プールに同時実行ジョブが送信されるシナリオ
ユーザーは、1 つの Synapse Analytics ワークスペースに複数の Spark プールを作成し、分析ワークロードの要件に基づいてそれらのサイズを設定できます。 作成されるこれらの Spark プールでユーザーが動的割り当てを有効にした場合、特定の時点に特定のワークスペースで使用可能なコアの合計数は次のようになります
ワークスペースで使用可能なコアの合計数 = すべての Spark プールの合計コア数 - Spark プールで実行されているアクティブなジョブに使用または予約されているコアの数
ワークスペースで使用可能な合計コア数が 0 のときにユーザーがジョブを送信すると、ワークスペース容量超過エラーを受け取ります。
マルチユーザー シナリオでのコアの動的割り当てと予約
複数のユーザーが特定の Synapse ワークスペースで複数の Spark ジョブを実行しようとするシナリオでは、動的割り当てが有効になっている Spark プールに User1 がジョブを送信した場合、プールで使用可能なすべてのコアが使されます。 User1 によって送信されたジョブの実行でのアクティブな使用と、実行をサポートするための予約により、Spark プールに使用可能なコアがない状態で、User2 がジョブを送信した場合、User2 はワークスペース容量超過エラーを受け取ります。
ヒント
ユーザーは、コアの数を増やすことによって、使用可能なコアの合計数を増やし、ワークスペース容量超過エラーを回避できます。