Tip
Microsoft Fabric Data Warehouse は、将来のアーキテクチャ、組み込みの AI、および新機能を備えた、Data Lake 基盤上のエンタープライズ 規模のリレーショナル ウェアハウスです。 データ ウェアハウスを初めて使用する場合は、Fabric Data Warehouseから始めます。 既存の dedicated SQL プール ワークロードは、Fabric にアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
- Fabric Data Warehouse 用マイグレーションアシスタント
このチート シートでは、専用 SQL プール (旧称 SQL DW) ソリューションを構築するためのヒントとベスト プラクティスを紹介します。
次の図は、専用 SQL プール (旧称 SQL DW) を使用してデータ ウェアハウスを設計するプロセスを示しています。
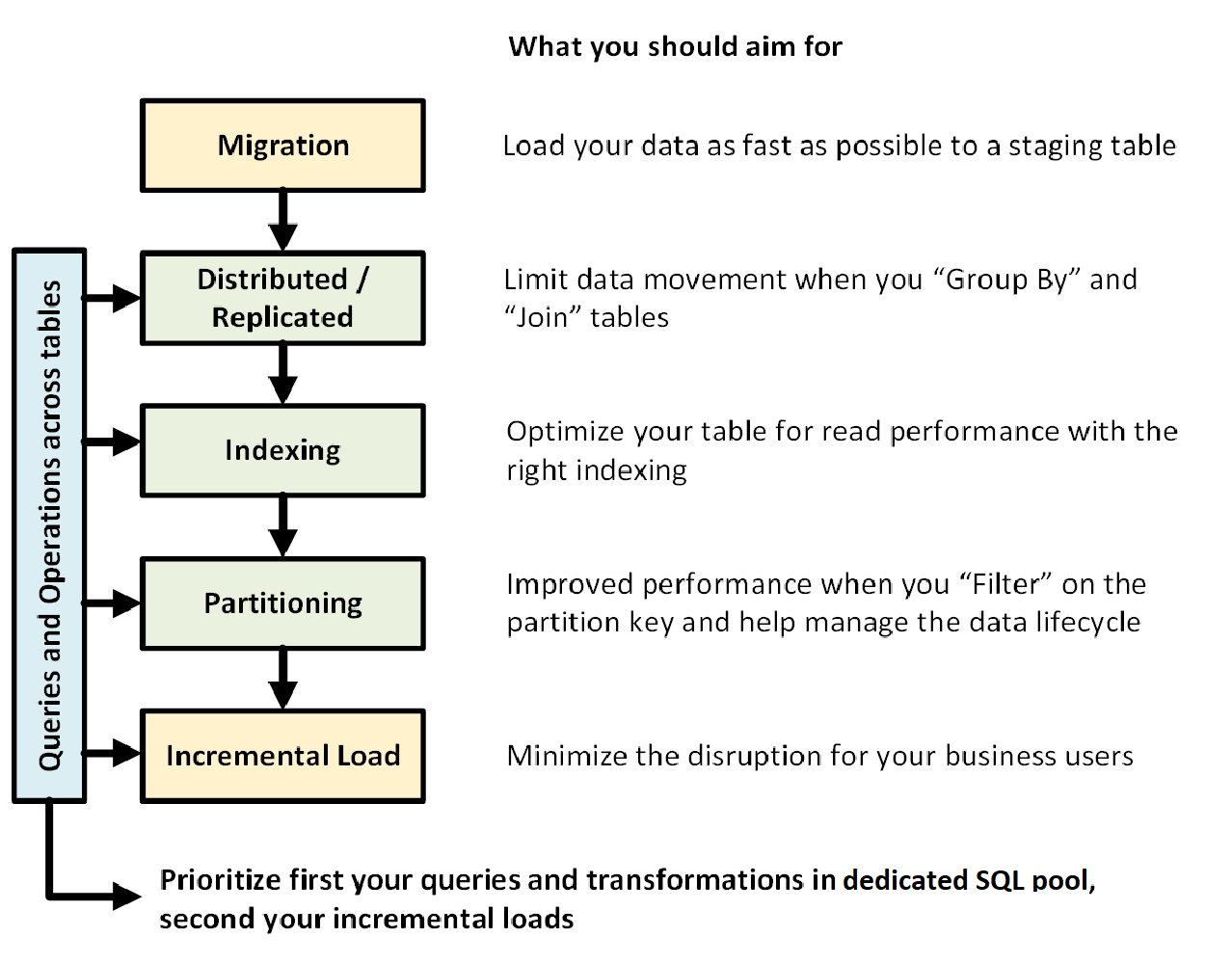
テーブル間のクエリと操作
データ ウェアハウスで実行する主要な操作とクエリを事前に把握している場合は、それらの操作のデータ ウェアハウス アーキテクチャに優先順位を付けることができます。 これらのクエリと操作には、次のものが含まれます。
- 1 つまたは 2 つのファクト テーブルをディメンション テーブルと結合し、結合されたテーブルをフィルター処理し、結果をデータ マートに追加します。
- ファクト テーブルに対して大きな更新または小さな更新を行う。
- テーブルにデータのみを追加する。
操作の種類を事前に把握しておくと、テーブルの設計を最適化するのに役立ちます。
データ移行
まず、Azure Data Lake StorageまたはAzure Blob Storageにデータを読み込みます。 次に、 COPY ステートメント を使用して、ステージング テーブルにデータを読み込みます。 次の構成を使用します。
| 設計 | レコメンデーション |
|---|---|
| 流通 | ラウンド ロビン |
| インデックス作成 | ヒープ |
| パーティション分割 | None |
| リソース クラス | largerc または xlargerc |
データの移行、データの読み込み、抽出、読み込み、変換 (ELT) プロセスの詳細について説明します。
分散テーブルまたはレプリケート テーブル
テーブルのプロパティに応じて、次の方法を使用します。
| タイプ | 非常に適しています... | もし〜なら気をつけてください |
|---|---|---|
| レプリケート済 | * 圧縮後のストレージが 2 GB 未満のスター スキーマ内の小さなディメンション テーブル (最大 5 倍の圧縮) | * 多くの書き込みトランザクションがテーブル上にあります (挿入、アップサート、削除、更新など) * Data Warehouse ユニット (DWU) のプロビジョニングを頻繁に変更する * 使用する列は 2 ~ 3 列のみですが、テーブルには多数の列があります * レプリケートされたテーブルのインデックスを作成する |
| ラウンド ロビン (既定) | * 一時およびステージング テーブル * 明確な結合キーまたは適切な候補列はありません |
* データ移動が原因でパフォーマンスが低下する |
| ハッシュ | * ファクト テーブル * 大きな次元テーブル |
* 配布キーを更新できません |
ヒント:
- ラウンド ロビンから始めますが、超並列アーキテクチャを利用するためのハッシュ分散戦略を目指します。
- 共通ハッシュ キーのデータ形式が同じであることを確認します。
- varchar 形式では配布しないでください。
- 頻繁に結合操作を行うファクト テーブルに共通のハッシュ キーを持つディメンション テーブルをハッシュ分散できます。
- データの歪度を分析するには 、sys.dm_pdw_nodes_db_partition_stats を使用します。
- sys.dm_pdw_request_stepsを使用して、クエリの背後にあるデータ移動を分析し、ブロードキャスト時間を監視し、シャッフル操作にかかる時間を監視します。 これは、配布戦略を確認するのに役立ちます。
レプリケート テーブルと分散テーブルの詳細について説明します。
テーブルのインデックスを作成する
インデックス作成は、テーブルをすばやく読み取る場合に役立ちます。 ニーズに基づいて使用できる固有のテクノロジのセットがあります。
| タイプ | 非常に適しています... | もし〜なら気をつけてください |
|---|---|---|
| ヒープ | * ステージング/一時テーブル *小さな検索を持つ小さなテーブル |
*すべてのルックアップは、完全なテーブルをスキャンします |
| クラスター化したインデックス | * 最大 1 億行のテーブル * 1 から 2 列しか頻繁に使用しない大きなテーブル (1 億行を超える) |
* レプリケートされたテーブルで使用されます * 複数の結合操作とグループ化操作を含む複雑なクエリがある * インデックス付き列に対して更新を行います。メモリが必要です |
| クラスター化列ストア インデックス (CCI) (既定) | * 大きなテーブル (1 億行を超える) | * レプリケートされたテーブルで使用されます *あなたのテーブルに大規模な更新操作を行います * テーブルをパーティション分割しすぎ:行グループが異なるディストリビューション ノードとパーティションにまたがらない |
ヒント:
- クラスター化インデックスの上に、フィルター処理に頻繁に使用される非クラスター化インデックスを列に追加できます。
- CCI を使用してテーブルのメモリを管理する方法に注意してください。 データを読み込むときに、ユーザー (またはクエリ) に大規模なリソース クラスを利用させる必要があります。 トリミングを避け、多数の小さな圧縮行グループを作成してください。
- Gen2 では、パフォーマンスを最大化するために、CCI テーブルがコンピューティング ノードにローカルにキャッシュされます。
- CCI の場合、行グループの圧縮率が低いため、パフォーマンスが低下する可能性があります。 この場合は、CCI をリビルドまたは再構成します。 圧縮された行グループごとに少なくとも 100,000 行が必要です。 理想は、行グループ内の 100 万行です。
- 増分読み込みの頻度とサイズに基づいて、インデックスを再構成または再構築するときに自動化する必要があります。 春の清掃は常に役立ちます。
- 行グループをトリミングする場合は、戦略的に行います。 開いている行グループの大きさはどのくらいですか? 今後数日間にどのくらいのデータが読み込まれると予想されますか?
インデックスについてさらに詳しく知る。
パーティション分割
大きなファクト テーブル (10 億行を超える) がある場合は、テーブルをパーティション分割できます。 99% の場合、パーティション キーは日付に基づく必要があります。
ELT を必要とするステージング テーブルを活用することで、パーティション分割のメリットを得ることができます。 データ ライフサイクル管理が容易になります。 ファクトまたはステージング テーブルをパーティション分割しすぎないように注意してください (特に、クラスター化列ストア インデックスの場合)。
パーティションの詳細について知る。
増分読み込み
データを段階的に読み込む場合は、まず、データの読み込みに大きなリソース クラスを割り当てるようにします。 これは、クラスター化列ストア インデックスを持つテーブルに読み込む場合に特に重要です。 詳細については、 リソース クラス を参照してください。
データ ウェアハウスへの ELT パイプラインを自動化するには、PolyBase と ADF V2 を使用することをお勧めします。
履歴データに大量の更新が含まれる場合は、INSERT、UPDATE、DELETE を使用するのではなく、 CTAS を使用してテーブルに保持するデータを書き込む方法を検討してください。
統計の管理
データに 重大な 変更が発生した場合は、統計を更新することが重要です。 重要な変更が発生したかどうかを判断するには、更新統計を参照してください。 更新された統計によって、クエリ プランが最適化されます。 すべての統計を維持するのに時間がかかりすぎる場合は、統計を持つ列をより選択的に選択してください。
更新の頻度を定義することもできます。 たとえば、日単位で新しい値が追加される日付列を更新できます。 結合に関係する列、WHERE 句で使用される列、および GROUP BY で見つかった列に関する統計を取得することで、最もメリットが得られます。
リソース クラス
リソース グループは、クエリにメモリを割り当てる方法として使用されます。 クエリまたは読み込み速度を向上させるためにメモリを増やす必要がある場合は、より高いリソース クラスを割り当てる必要があります。 逆に、大規模なリソース クラスを使用すると、コンカレンシーに影響します。 すべてのユーザーを大規模なリソース クラスに移動する前に、この点を考慮する必要があります。
クエリに時間がかかりすぎる場合は、ユーザーが大規模なリソース クラスで実行していないことを確認してください。 大規模なリソース クラスでは、多くのコンカレンシー スロットが使用されます。 他のクエリがキューに追加される原因となる可能性があります。
最後に、 専用 SQL プールの Gen2 (以前の SQL DW) を使用すると、各リソース クラスは Gen1 の 2.5 倍のメモリを取得します。
リソース クラスとコンカレンシーを操作する方法について説明します。
コストを削減する
Azure Synapseの主な機能は、コンピューティング リソースを<>管理する機能です。 専用 SQL プール (以前の SQL DW) は、使用していないときに一時停止できます。これによって、コンピューティング リソースの課金が停止されます。 パフォーマンスの需要に合わせてリソースをスケーリングできます。 一時停止するには、Azure ポータル または PowerShell を使用します。 スケーリングするには、Azure portal、PowerShell、T-SQL、または REST API を使用します。
Azure Functionsを使用して、必要な時点で自動スケーリングを行います。

パフォーマンスのためにアーキテクチャを最適化する
ハブ アンド スポーク アーキテクチャでは、SQL Database とAzure Analysis Servicesを検討することをお勧めします。 このソリューションでは、SQL Database と Azure Analysis Services の高度なセキュリティ機能を使用しながら、さまざまなユーザー グループ間でワークロードを分離できます。 これは、ユーザーに無限のコンカレンシーを提供する方法でもあります。
Azure Synapse Analytics の専用 SQL プール (旧称 SQL DW) を利用する
専用 SQL プール (旧称 SQL DW) から SQL データベースにスポークをデプロイします。