右シフト は、DevOps プロセスの後で運用環境で テストするためにいくつかのテストを移動する方法です。 運用環境でのテストでは、実際のデプロイを使用して、運用環境でのアプリケーションの動作とパフォーマンスを検証および測定します。
DevOps チームが速度を向上させる 1 つの方法は、 シフト左 のテスト戦略です。 Shift Left は、DevOps パイプラインのほとんどのテストを前にプッシュして、新しいコードが運用環境に到達して確実に動作するまでの時間を短縮します。
ただし、単体テストなど、多くの種類のテストは簡単に左にシフトできますが、一部またはすべてのソリューションをデプロイしないと、一部のクラスのテストを実行できません。 QA またはステージング サービスにデプロイすると、同等の環境をシミュレートできますが、運用環境に完全に代わるものはありません。 Teams では、運用環境で特定の種類のテストを行う必要があることがわかります。
運用環境でのテストでは、次の機能が提供されます。
- 運用環境の広さと多様性。
- 顧客トラフィックの実際のワークロード。
- 生産需要が時間の経過と同時に進化するにつれて、プロファイルと動作が変化します。
運用環境は変化し続けます。 アプリが変更されない場合でも、アプリが依存するインフラストラクチャは常に変更されます。 運用環境でのテストでは、特定の運用環境のデプロイの正常性と品質、および絶えず変化する運用環境の正常性と品質が検証されます。
運用環境でテストする権利のシフトは、次のシナリオで特に重要です。
マイクロサービスのデプロイ
マイクロサービス ベースのソリューションには、個別に開発、デプロイ、管理される多数のマイクロサービスを含めることができます。 異なるバージョンや構成がさまざまな方法で運用環境に到達する可能性があるため、これらのプロジェクトではテスト権限のシフトが特に重要です。 運用前のテスト カバレッジに関係なく、運用環境での互換性をテストする必要があります。
デプロイ後の品質の確保
運用環境へのリリースは、ソフトウェアの提供の半分にすぎません。 残りの半分は、運用環境で実際のワークロードを使用して大規模な品質を確保することです。 環境は変化し続けるので、チームは運用環境でのテストを行うことはありません。
運用環境からのテスト データは、実際の顧客ワークロードからのテスト結果です。 運用環境でのテストには、監視、フェールオーバー テスト、および障害挿入が含まれます。 このテストでは、エラー、例外、パフォーマンス メトリック、およびセキュリティ イベントを追跡します。 テスト テレメトリは、異常の検出にも役立ちます。
デプロイ層
運用環境を保護するために、チームは 階層ベースのデプロイ と 機能フラグを使用して、段階的かつ制御された方法で変更をロールアウトできます。 たとえば、すべての顧客を一度に切り替えた後よりも、1% 未満の顧客がそのデプロイ レベルにいる場合に、買い物客が購入を完了できないバグをキャッチすることをお勧めします。 障害が検出された機能の値は、特定のビジネスにとって意味のある方法で測定された、これらの障害の純損失を超える必要があります。
最初のレベルは、標準統合スイートを実行するために必要な最小サイズである必要があります。 テストは、他の環境に対してパイプラインで既に実行されているものと似ていますが、テストでは運用環境で動作が同じであることを検証します。 このレベルでは、顧客に影響を与える前に、構成ミスなどの明らかなエラーを特定します。
初期レベルが検証されると、次のレベルが広がり、テストの実行に実際のユーザーのサブセットが含まれる可能性があります。 すべてが問題なく見える場合は、すべてのユーザーが使用するまで、デプロイをさらに階層化してテストを進めることができます。 完全なデプロイは、テストが終わったことを意味するわけではありません。 テレメトリの追跡は、運用環境でのテストで非常に重要です。
フォールト挿入
多くの場合、Teams は 障害の挿入 と カオス エンジニアリング を使用して、障害条件下でのシステムの動作を確認します。 これらのプラクティスは、次の場合に役立ちます。
- 実装されている回復性メカニズムが実際に機能することを検証します。
- 1 つのサブシステムの障害がそのサブシステム内に含まれており、大規模な停止を発生させるために連鎖していないことを検証します。
- 前のインシデントの修復作業が、別のインシデントが発生するのを待たずに望ましい効果があることを証明します。
- ライブ サイト エンジニア向けのより現実的なトレーニング訓練を作成して、インシデントに対処するための準備を強化します。
障害挿入実験は、絶えず変化するシステムで実行する必要がある高価なテストであるため、自動化することをお勧めします。
カオス エンジニアリング は効果的なツールですが、お客様にほとんどまたはまったく影響を与える カナリア環境 に限定する必要があります。
フェールオーバー テスト
障害挿入の 1 つの形式は、ビジネス継続性とディザスター リカバリー (BCDR) をサポートするための フェールオーバー テストです。 Teams には、すべてのサービスとサブシステムのフェールオーバー計画が必要です。 プランには次のものが含まれている必要があります。
- サービスがダウンした場合のビジネスへの影響を明確に説明します。
- プラットフォーム、テクノロジ、BCDR プランを考案するユーザーに関するすべての依存関係のマップ。
- ディザスター リカバリー手順の正式なドキュメント。
- ディザスター リカバリー訓練を定期的に実行する頻度。
サーキット ブレーカーの障害テスト
サーキット ブレーカー メカニズムは、通常、そのコンポーネントの障害が境界の外に広がらないように、特定のコンポーネントを大きなシステムから切り離します。 サーキット ブレーカーを意図的にトリガーして、次のシナリオをテストできます。
サーキット ブレーカーが開いたときにフォールバックが機能するかどうか。 フォールバックは単体テストで機能する可能性がありますが、運用環境で想定どおりに動作するかどうかを知る唯一の方法は、障害を挿入してトリガーすることです。
サーキット ブレーカーが必要なときに開く適切な感度しきい値を持っているかどうか。 障害の挿入により、待機時間や依存関係の切断が強制され、ブレーカーの応答性が観察されます。 正しい動作が発生するだけでなく、十分に迅速に発生することを確認することが重要です。
例: Redis Cache サーキット ブレーカーのテスト
Redis Cache では、一般的に使用されるデータへのアクセスが高速化され、製品のパフォーマンスが向上します。 Redis に重大ではない依存関係を持つシナリオについて考えてみましょう。 Redis がダウンした場合、システムは要求に元のデータ ソースを使用するようにフォールバックできるため、引き続き動作する必要があります。 Redis 障害によってサーキット ブレーカーがトリガーされ、フォールバックが運用環境で動作することを確認するには、これらの動作に対して定期的にテストを実行します。
次の図は、Redis サーキット ブレーカーのフォールバック動作のテストを示しています。 目標は、ブレーカーが開いたときに、呼び出しが最終的に SQL に移動することを確認することです。
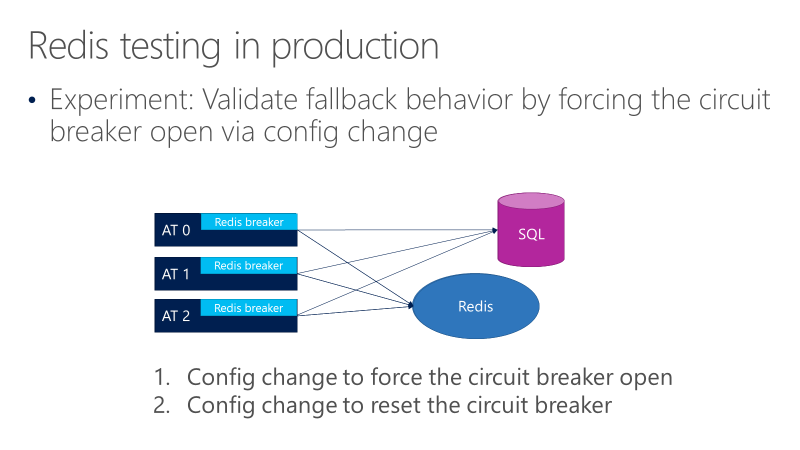
上の図は、Redis の呼び出しの前にブレーカーがある 3 つの AT を示しています。 1 つのテストで、構成の変更によってサーキット ブレーカーが強制的に開き、呼び出しが SQL に移行するかどうかを確認します。 別のテストでは、サーキット ブレーカーを閉じて、呼び出しが Redis に戻っていることを確認することで、反対の構成変更を確認します。
このテストでは、ブレーカーが開いたときにフォールバック動作が動作することを検証しますが、必要に応じてサーキット ブレーカー構成によってブレーカーが開かれることを検証しません。 その動作をテストするには、実際のエラーをシミュレートする必要があります。
障害エージェントは、Redis への呼び出しでエラーを発生させる可能性があります。 次の図は、フォールト インジェクションを使用したテストを示しています。
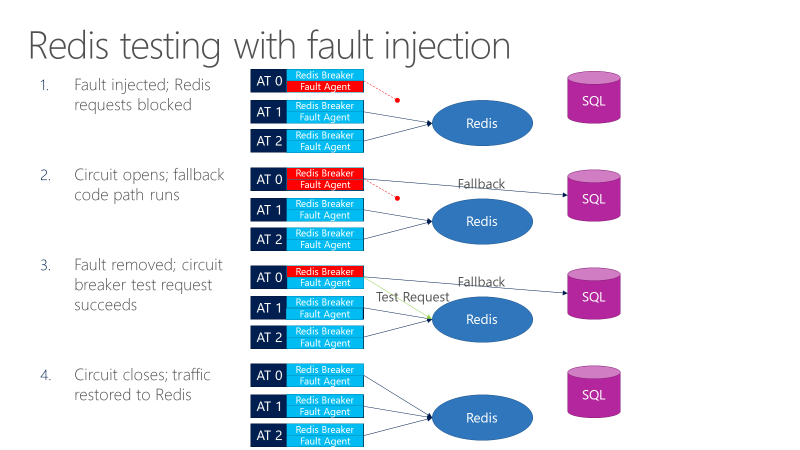
- 障害インジェクタは Redis 要求をブロックします。
- サーキット ブレーカーが開き、フォールバックが機能するかどうかをテストで確認できます。
- 障害が削除され、サーキット ブレーカーによって Redis にテスト要求が送信されます。
- 要求が成功すると、呼び出しは Redis に戻ります。
さらに手順を実行すると、ブレーカーの感度、しきい値が高すぎるか低すぎるか、他のシステム タイムアウトがサーキット ブレーカーの動作に干渉するかどうかをテストできます。
この例では、ブレーカーが予期したとおりに開いたり閉じたりしない場合、 ライブ サイト インシデント (LSI) が発生する可能性があります。 障害挿入テストがないと、ラボ環境でこの種のテストを行うのが難しいため、問題が検出されない可能性があります。