ヒント
このコンテンツは、Azure 用のクラウド ネイティブ .NET アプリケーションの設計に関する電子ブックからの抜粋であり、.NET Docs またはオフラインで読み取ることができる無料のダウンロード可能な PDF として入手できます。

防御の最初の行は、アプリケーションの回復性です。
独自の回復性フレームワークの作成にはかなりの時間を費やしてもかまいませんが、そのような製品は既に存在します。
Polly は、開発者が流暢でスレッド セーフな方法で回復性ポリシーを表現できるようにする、包括的な .NET 回復性と一時的な障害処理ライブラリです。 Polly は、.NET Framework または .NET 7 で構築されたアプリケーションを対象としています。 次の表では、Polly ライブラリで使用できる、 policiesと呼ばれる回復性機能について説明します。 個別に適用することも、グループ化することもできます。
| ポリシー | エクスペリエンス |
|---|---|
| [再試行] | 指定された操作に対する再試行操作を構成します。 |
| サーキット ブレーカー | 障害が構成されたしきい値を超えた場合に、事前に定義された期間、要求された操作をブロックします |
| 時間切れ | 呼び出し元が応答を待機できる期間に制限を設定します。 |
| バルクヘッド | リソースが失敗した呼び出しで圧倒されないように、アクションを固定サイズのリソースプールに制限します。 |
| キャッシュ | 応答を自動的に格納します。 |
| フォールバック | 障害発生時の構造化された動作を定義します。 |
前の図の回復性ポリシーが要求メッセージに適用される方法に注意してください。外部クライアントまたはバックエンド サービスのどちらから送信されるかに注意してください。 目標は、一時的に利用できない可能性があるサービスの要求を補正することです。 これらの有効期間の短い中断は、通常、次の表に示す HTTP 状態コードを使用して現れます。
| HTTP ステータス コード | 原因 |
|---|---|
| 404 | 見つかりません |
| 4:08 | 要求タイムアウト |
| 429 | 要求が多すぎます (おそらく調整されている可能性があります) |
| 502 | ゲートウェイが正しくありません |
| 503 | Service unavailable (サービス利用不可) |
| 504 | ゲートウェイ タイムアウト |
質問: HTTP 状態コード 403 - 禁止を再試行しますか? いいえ。 ここでは、システムは正常に機能していますが、要求された操作の実行が承認されていないことを呼び出し元に通知します。 障害が原因で発生した操作のみを再試行するように注意する必要があります。
第 1 章で推奨されているように、クラウドネイティブ アプリケーションを構築する Microsoft 開発者は、.NET プラットフォームをターゲットにする必要があります。 バージョン 2.1 では、URL ベースのリソースと対話するための HTTP クライアント インスタンスを作成するための HTTPClientFactory ライブラリが導入されました。 元の HTTPClient クラスを超えたファクトリ クラスでは、多くの強化された機能がサポートされています。そのうちの 1 つは Polly 回復性ライブラリとの 緊密な統合 です。 これを使用すると、アプリケーションの Startup クラスで回復性ポリシーを簡単に定義して、部分的な障害や接続の問題を処理できます。
次に、再試行パターンとサーキットブレーカーパターンについて詳しく述べます。
再試行パターン
分散型クラウドネイティブ環境では、サービスとクラウド リソースの呼び出しは、一時的な (有効期間が短い) 障害が原因で失敗する可能性があります。これは通常、短時間の後に自分自身を修正します。 再試行戦略を実装すると、クラウドネイティブ サービスがこれらのシナリオを軽減するのに役立ちます。
再試行パターンを使用すると、サービスは失敗した要求操作を、指数関数的に増加する待機時間で (構成可能な) 回数だけ再試行できます。 図 6-2 は、再試行の動作を示しています。
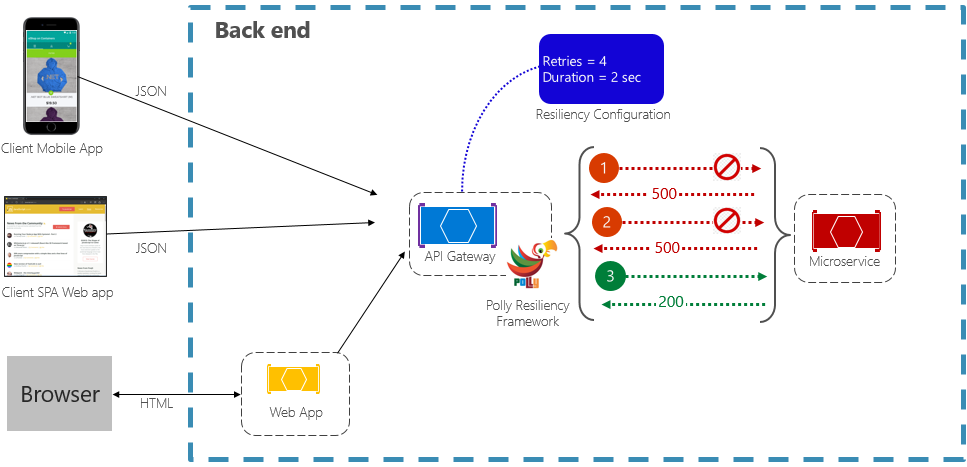
図 6-2 動作中の再試行パターン
前の図では、要求操作の再試行パターンが実装されています。 2 秒から始まるバックオフ間隔 (待機時間) で失敗する前に最大 4 回の再試行を許可するように構成されています。これは、後続の試行ごとに指数関数的に 2 倍になります。
- 最初の呼び出しは失敗し、HTTP 状態コード 500 が返されます。 アプリケーションは 2 秒間待機し、呼び出しを再試行します。
- 2 回目の呼び出しも失敗し、HTTP 状態コード 500 が返されます。 これで、アプリケーションはバックオフ間隔を 4 秒に倍にし、呼び出しを再試行します。
- 最後に、3 番目の呼び出しは成功します。
- このシナリオでは、呼び出しに失敗する前にバックオフ期間を 2 倍にしながら、再試行操作で最大 4 回の再試行が試行されます。
- 4 回目の再試行が失敗した場合は、問題を適切に処理するためのフォールバック ポリシーが呼び出されます。
呼び出しを再試行する前にバックオフ期間を長くして、サービス時間を自己修正できるようにすることが重要です。 指数関数的に増加するバックオフ (各再試行の期間を 2 倍にする) を実装して、適切な修正時間を確保することをお勧めします。
サーキット ブレーカー パターン
再試行パターンは、部分的な障害に巻き込まれた要求の復旧に役立ちますが、予期しないイベントが原因でエラーが発生する可能性があり、解決に時間がかかる場合があります。 このような障害の重大度は、部分的な接続の損失からサービスの完全な不具合まで多岐にわたります。 このような状況では、成功する可能性が低い操作をアプリケーションが継続的に再試行するのは無意味です。
さらに悪いことに、応答しないサービスに対して継続的な再試行操作を実行すると、メモリ、スレッド、データベース接続などのリソースを使い果たす継続的な呼び出しでサービスがあふれ、同じリソースを使用するシステムの無関係な部分でエラーが発生する、サービス拒否シナリオに移行する可能性があります。
このような状況では、操作がすぐに失敗し、成功する可能性がある場合にのみサービスの呼び出しを試みることをお勧めします。
サーキット ブレーカー パターンを使用すると、失敗する可能性のある操作をアプリケーションが繰り返し実行することを防ぐことができます。 事前に定義された失敗した呼び出しの数が発生すると、サービスへのすべてのトラフィックがブロックされます。 定期的に、試用呼び出しで障害が解決されたかどうかを判断できます。 図 6-3 は、動作中のサーキット ブレーカー パターンを示しています。
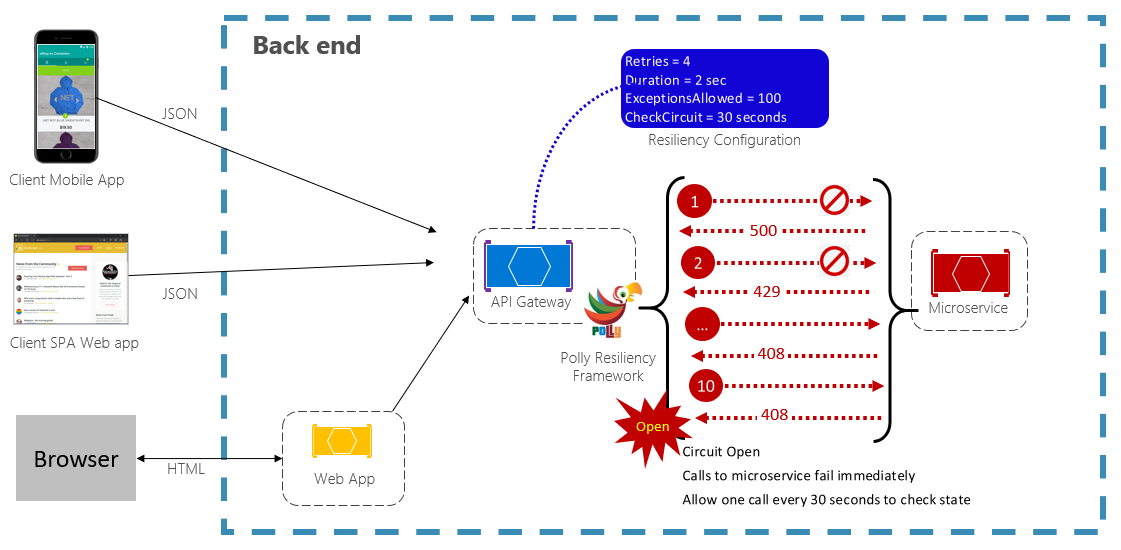
図 6-3 動作中のサーキット ブレーカー パターン
前の図では、サーキット ブレーカー パターンが元の再試行パターンに追加されています。 要求が 100 件失敗した後、サーキット ブレーカーが開き、サービスへの呼び出しが許可されなくなったことに注意してください。 30 秒に設定された CheckCircuit 値は、ライブラリが 1 つの要求をサービスに進める頻度を指定します。 その呼び出しが成功すると、回線が閉じられ、サービスが再度トラフィックで使用できるようになります。
サーキット ブレーカー パターンの意図は、再試行パターンの意図 とは異なる 点に注意してください。 再試行パターンを使用すると、アプリケーションは成功を期待して操作を再試行できます。 サーキット ブレーカー パターンを使用すると、アプリケーションが失敗する可能性のある操作を実行できなくなります。 通常、アプリケーションは、再試行パターンを使用してサーキット ブレーカーを介して操作を呼び出すことによって、これら 2 つのパターンを 組み合わせます 。
回復性のテスト
回復性のテストは、(単体テストや統合テストなどを実行して) アプリケーション機能をテストするのと同じ方法で常に実行できるわけではありません。 代わりに、断続的にしか発生しない障害条件下でエンド ツー エンドのワークロードがどのように実行されるかをテストする必要があります。 たとえば、プロセスのクラッシュ、証明書の期限切れ、依存サービスの利用不可などによってエラーを挿入します。 chaos-monkey のようなフレームワークは、このようなカオス テストに使用できます。
アプリケーションの回復性は、問題のある要求された操作を処理するために必要です。 しかし、それは物語の半分にすぎません。 次に、Azure クラウドで利用できる回復性機能について説明します。
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET