ヒント
このコンテンツは、Azure 用のクラウド ネイティブ .NET アプリケーションの設計に関する電子ブックからの抜粋であり、.NET Docs またはオフラインで読み取ることができる無料のダウンロード可能な PDF として入手できます。

作業を停止し、同僚に "Cloud Native" という用語を定義するよう依頼します。 複数の異なる回答が得られる可能性は十分にあります。
単純な定義から始めましょう。
クラウドネイティブのアーキテクチャとテクノロジは、クラウドに構築され、クラウド コンピューティング モデルを最大限に活用するワークロードを設計、構築、運用するためのアプローチです。
Cloud Native Computing Foundation には、公式の定義が用意されています。
クラウドネイティブ テクノロジにより、組織は、パブリック、プライベート、ハイブリッド クラウドなどの最新の動的環境でスケーラブルなアプリケーションを構築して実行できます。 コンテナー、サービス メッシュ、マイクロサービス、不変インフラストラクチャ、宣言型 API は、このアプローチを例示します。
これらの手法により、回復性、管理性、監視性に優れた疎結合システムが可能になります。 堅牢な自動化と組み合わせることで、エンジニアは最小限の手間で頻繁かつ予測可能に影響の大きい変更を行うことができます。
クラウド ネイティブは 、速度 と 機敏性に関する情報です。 ビジネス システムは、ビジネス機能の有効化から、ビジネスの速度と成長を加速させる戦略的変革の武器へと進化しています。 新しいアイデアをすぐに市場に投入することが不可欠です。
同時に、ビジネス システムもますます複雑になり、ユーザーはより多くを要求しています。 迅速な応答性、革新的な機能、ダウンタイムゼロが期待されます。 パフォーマンスの問題、繰り返し発生するエラー、高速に移動できない問題は許容されなくなりました。 ユーザーは競合他社を訪問します。 クラウドネイティブ システムは、急速な変化、大規模、回復性を受け入れるように設計されています。
クラウドネイティブ手法を実装した企業をいくつか紹介します。 達成した速度、機敏性、スケーラビリティについて考えてください。
| [会社] | エクスペリエンス |
|---|---|
| Netflix | 運用環境には 600 以上のサービスがあります。 1 日あたり 100 回デプロイします。 |
| Uber | サービスが運用中のものだけでも 1,000 を超えています。 毎週数千回デプロイします。 |
| ウィーチャット | 3,000 を超えるサービスを運用環境で提供しています。 1 日に 1,000 回デプロイします。 |
ご覧のように、Netflix、Uber、WeChat では、多数の独立したサービスで構成されるクラウドネイティブ システムが公開されています。 このアーキテクチャ スタイルにより、市場の状況に迅速に対応できます。 完全に再デプロイすることなく、ライブで複雑なアプリケーションの小さな領域を瞬時に更新します。 必要に応じてサービスを個別にスケーリングします。
クラウド ネイティブの柱
クラウド ネイティブの速度と機敏性は、多くの要因から生まれています。 最も重要なのは 、クラウド インフラストラクチャです。 ただし、他にも、図 1-3 に示す 5 つの基本的な柱が、クラウドネイティブ システムの基盤となります。
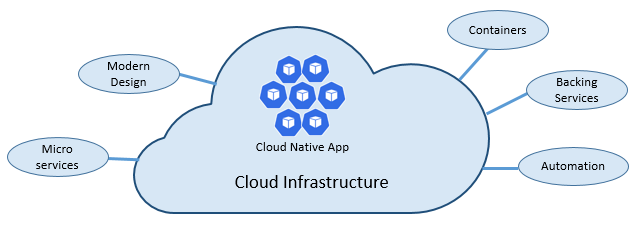
図 1-3 クラウドネイティブの基本的な柱
各柱の重要性をより深く理解するために少し時間を取りましょう。
クラウド
クラウドネイティブ システムは、クラウド サービス モデルを最大限に活用します。
動的で仮想化されたクラウド環境で成功するように設計されたこれらのシステムは、 サービスとしてのプラットフォーム (PaaS) コンピューティング インフラストラクチャとマネージド サービスを幅広く使用します。 基になるインフラストラクチャは、自動化によって、分単位でプロビジョニングされ、必要に応じてサイズ変更、スケーリング、または破棄される 破棄可能 なインフラストラクチャとして扱われます。
ペットと商品の扱い方の違いを考えてみましょう。 従来のデータセンターでは、サーバーはペットのように扱われます。物理的な機器には意味のある名前が与えられ、丁寧に管理されます。 スケーリングするには、同じマシンにリソースを追加します (スケールアップ)。 サーバーが病気になった場合は、正常性に戻します。 サーバーが使用できなくなった場合は、全員が気付きます。
コモディティ サービス モデルは異なります。 各インスタンスは、仮想マシンまたはコンテナーとしてプロビジョニングします。 これらは同一であり、Service-01、Service-02 などのシステム識別子が割り当てられます。 より多くのインスタンスを作成してスケーリングします (スケールアウト)。 インスタンスが使用できなくなったとき、誰も気付かない。
コモディティ モデルには、不変のインフラストラクチャが採用されています。 サーバーは修復または変更されません。 失敗した場合、または更新が必要な場合は破棄され、新しいものがプロビジョニングされます。すべて自動化によって行われます。
クラウドネイティブ システムでは、コモディティ サービス モデルが採用されています。 実行を続ける際に、インフラストラクチャはスケールインまたはスケールアウトしますが、どのマシンで実行しているかは関係ありません。
Azure クラウド プラットフォームでは、自動スケーリング、自己復旧、監視機能を備えた、この種の非常に柔軟なインフラストラクチャがサポートされています。
モダン デザイン
クラウドネイティブ アプリをどのように設計しますか? アーキテクチャはどのようなものですか? どのような原則、パターン、ベスト プラクティスに従いますか? どのようなインフラストラクチャと運用上の懸念事項が重要でしょうか。
Twelve-Factor アプリケーション
クラウドベースのアプリケーションを構築するための広く受け入れられていう手法は 、Twelve-Factor アプリケーションです。 最新のクラウド環境向けに最適化されたアプリケーションを構築するために開発者が従う一連の原則とプラクティスについて説明します。 環境全体の移植性と宣言型の自動化には特に注意が必要です。
Web ベースのアプリケーションに適用できる一方で、多くの実務家 Twelve-Factor クラウド ネイティブ アプリを構築するための強固な基盤であると考えます。 これらの原則に基づいて構築されたシステムは、迅速にデプロイおよびスケーリングでき、市場の変化に迅速に対応する機能を追加できます。
次の表は、Twelve-Factor 手法を示しています。
| 要因 | 説明 |
|---|---|
| 1 - コード ベース | マイクロサービスごとに 1 つのコード ベース。独自のリポジトリに格納されます。 バージョン管理によって追跡され、複数の環境 (QA、ステージング、運用) にデプロイできます。 |
| 2 - 依存関係 | 各マイクロサービスは独自の依存関係を分離してパッケージ化し、システム全体に影響を与えずに変更を反映します。 |
| 3 - 構成 | 構成情報はマイクロサービスから移動され、コードの外部にある構成管理ツールを使用して外部化されます。 同じデプロイは、正しい構成が適用された環境間で伝達できます。 |
| バックエンド サービス | 補助リソース (データ ストア、キャッシュ、メッセージ ブローカー) は、アドレス指定可能な URL を介して公開する必要があります。 これにより、リソースがアプリケーションから切り離され、交換可能になります。 |
| 5 - ビルド、リリース、実行 | 各リリースでは、ビルド、リリース、および実行の各ステージで厳密な分離を適用する必要があります。 それぞれに一意の ID でタグ付けし、ロールバック機能をサポートする必要があります。 最新の CI/CD システムは、この原則を満たすのに役立ちます。 |
| 6 - プロセス | 各マイクロサービスは、他の実行中のサービスから分離された独自のプロセスで実行する必要があります。 必要な状態を、分散キャッシュやデータ ストアなどのバッキング サービスに外部化します。 |
| 7 - ポートのバインド | 各マイクロサービスは、独自のポートで公開されるインターフェイスと機能を備えた自己完結型にする必要があります。 これにより、他のマイクロサービスからの分離が提供されます。 |
| 8 - コンカレンシー | 容量を増やす必要がある場合は、利用可能な最も強力なマシン上の単一の大規模なインスタンスをスケールアップするのではなく、複数の同一プロセス (コピー) にわたってサービスを水平方向にスケールアウトします。 クラウド環境でのスケールアウトをシームレスに同時に行えるようにアプリケーションを開発します。 |
| 9 - 破棄可能性 | サービス インスタンスは破棄可能である必要があります。 高速スタートアップを優先してスケーラビリティの機会を増やし、正常なシャットダウンを行ってシステムを正しい状態のままにします。 Docker コンテナーとオーケストレーターは、本質的にこの要件を満たしている。 |
| 10 - 開発/運用のパリティ | アプリケーションのライフサイクル全体にわたって環境を可能な限り同様に保ち、コストのかかるショートカットを回避します。 ここでは、コンテナーの導入は、同じ実行環境を促進することによって大きく貢献できます。 |
| 11 - ログ記録 | マイクロサービスによって生成されたログをイベント ストリームとして扱います。 イベント アグリゲーターを使用して処理します。 ログ データを Azure Monitor や Splunk などのデータ マイニング/ログ管理ツールに伝達し、最終的には長期的なアーカイブに反映します。 |
| 12 - 管理プロセス | 1 回限りのプロセスとして、データのクリーンアップやコンピューティング分析などの管理/管理タスクを実行します。 独立したツールを使用して、運用環境からこれらのタスクを呼び出しますが、アプリケーションとは別に呼び出します。 |
本では、 Twelve-Factor アプリを超えて、著者ケビン・ホフマンは、元の12の要因(2011年に書かれた)のそれぞれについて詳しく説明しています。 さらに、今日の最新のクラウド アプリケーション設計を反映する 3 つの追加要因について説明します。
| 新しい要素 | 説明 |
|---|---|
| 13 - API First | すべてをサービスにします。 コードがフロントエンド クライアント、ゲートウェイ、または別のサービスによって使用されるとします。 |
| 14 - テレメトリ | ワークステーションでは、アプリケーションとその動作を詳細に把握できます。 クラウドでは、そのようなことはしません。 設計に、監視、ドメイン固有、および正常性/システム データのコレクションが含まれていることを確認します。 |
| 15 - 認証/承認 | 最初から ID を実装します。 パブリック クラウドで使用できる RBAC (ロールベースのアクセス制御) 機能を検討してください。 |
この章と本全体で、12 以上の要因の多くを参照します。
Azure Well-Architected Framework(アジュール ウェルアーキテクテッド フレームワーク)
クラウドベースのワークロードの設計とデプロイは、特にクラウドネイティブ アーキテクチャを実装する場合に困難な場合があります。 Microsoft では、お客様とチームが堅牢なクラウド ソリューションを提供するのに役立つ業界標準のベスト プラクティスを提供しています。
Microsoft Well-Architected Framework には、クラウドネイティブ ワークロードの品質を向上させるために使用できる一連のガイドテネットが用意されています。 フレームワークは、アーキテクチャの卓越性の 5 つの柱で構成されています。
| 基本理念 | 説明 |
|---|---|
| コスト管理 | 増分値を早期に生成することに重点を置く。 Build-Measure-Learn の原則を適用して、資本集約型ソリューションを回避しながら市場投入までの時間を短縮します。 従量課金戦略を採用し、事前に多額の投資を行うのではなく、徐々に拡張するにつれて投資します。 |
| オペレーショナル エクセレンス | 環境と運用を自動化して速度を上げ、人為的ミスを減らします。 問題のアップデートを迅速にロールバックまたは前進させます。 最初から監視と診断を実装します。 |
| パフォーマンス効率 | ワークロードに対する要求を効率的に満たします。 水平スケーリング (スケールアウト) を優先し、システムに設計します。 潜在的なボトルネックを特定するために、パフォーマンスとロード テストを継続的に実施します。 |
| 確実 | 回復性と使用可能な両方のワークロードを構築します。 回復性により、ワークロードは障害から復旧し、機能を継続できます。 可用性により、ユーザーは常にワークロードにアクセスできます。 障害を想定して復旧するようにアプリケーションを設計します。 |
| セキュリティ | 設計と実装からデプロイと運用まで、アプリケーションのライフサイクル全体にわたってセキュリティを実装します。 ID 管理、インフラストラクチャ アクセス、アプリケーション セキュリティ、データ主権と暗号化に細心の注意を払います。 |
まず、Microsoft では、適切に設計された 5 つの柱に対して現在のクラウド ワークロードを評価するのに役立つ一連の オンライン評価 を提供しています。
マイクロサービス
クラウドネイティブ システムには、最新のアプリケーションを構築するための一般的なアーキテクチャ スタイルであるマイクロサービスが採用されています。
共有ファブリックを介して対話する小規模で独立したサービスの分散セットとして構築されたマイクロサービスは、次の特性を共有します。
それぞれが、より大きなドメイン コンテキスト内に特定のビジネス機能を実装します。
それぞれが自律的に開発され、個別にデプロイできます。
それぞれが、独自のデータ ストレージ テクノロジ、依存関係、プログラミング プラットフォームをカプセル化する自己完結型です。
それぞれが独自のプロセスで実行され、HTTP/HTTPS、gRPC、WebSocket、 AMQP などの標準の通信プロトコルを使用して他のユーザーと通信します。
これらは一緒に構成され、アプリケーションを形成します。
図 1-4 は、モノリシック アプリケーションアプローチとマイクロサービス アプローチを比較しています。 モノリスが、1 つのプロセスで実行される階層型アーキテクチャでどのように構成されているかに注意してください。 通常、リレーショナル データベースが使用されます。 ただし、マイクロサービスアプローチでは、独自のロジック、状態、データを持つ独立したサービスに機能を分離します。 各マイクロサービスは、独自のデータストアをホストします。
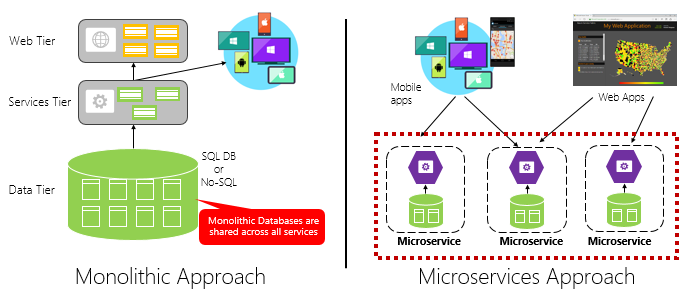
図 1-4. モノリシックアーキテクチャとマイクロサービスアーキテクチャ
マイクロサービスが、前の章で説明した Twelve-Factor アプリケーションからプロセスの原則を昇格させる方法に注意してください。
Factor #6 では、"各マイクロサービスは、他の実行中のサービスから分離された独自のプロセスで実行する必要があります" と指定されています。
マイクロサービスの理由
マイクロサービスは機敏性を提供します。
この章の前半では、モノリスとして構築された e コマース アプリケーションをマイクロサービスと比較しました。 この例では、いくつかの明確な利点を確認しました。
各マイクロサービスには自律的なライフサイクルがあり、個別に進化し、頻繁にデプロイできます。 新しい機能や更新プログラムをデプロイするために、四半期ごとのリリースを待つ必要はありません。 システム全体を中断するリスクが低い、ライブ アプリケーションの小さな領域を更新できます。 更新は、アプリケーションを完全に再デプロイすることなく行うことができます。
各マイクロサービスは個別にスケーリングできます。 アプリケーション全体を 1 つのユニットとしてスケーリングする代わりに、必要なパフォーマンス レベルとサービス レベルアグリーメントを満たすためにより多くの処理能力を必要とするサービスのみをスケールアウトします。 きめ細かいスケーリングにより、システムをより細かく制御でき、システムの一部をスケーリングする際に全体的なコストを削減するのに役立ちます。すべてではありません。
マイクロサービスを理解するための優れたリファレンス ガイドは 、.NET マイクロサービス: コンテナー化された .NET アプリケーションのアーキテクチャです。 本書では、マイクロサービスの設計とアーキテクチャについて詳しく説明します。 これは、Microsoft から無料でダウンロードできる フル スタックマイクロサービス参照アーキテクチャ のコンパニオンです。
マイクロサービスの開発
マイクロサービスは、最新の開発プラットフォームで作成できます。
Microsoft .NET プラットフォームは優れた選択肢です。 無料でオープン ソースであり、マイクロサービス開発を簡略化する多くの組み込み機能があります。 .NET はクロスプラットフォームです。 アプリケーションは、Windows、macOS、およびほとんどの種類の Linux でビルドして実行できます。
.NET はパフォーマンスが高く、Node.js やその他の競合プラットフォームと比較して優れたスコアを獲得しています。 興味深いことに、 TechEmpower は、多くの Web アプリケーション プラットフォームとフレームワークにわたって広範な パフォーマンス ベンチマーク を実施しました。 .NET は上位 10 でスコアを付け、Node.js やその他の競合プラットフォームを大きく上回っています。
.NET は、Microsoft と GitHub の .NET コミュニティによって管理されています。
マイクロサービスの課題
分散クラウドネイティブマイクロサービスは、非常に機敏性とスピードを提供できますが、多くの課題があります。
通信
フロントエンド クライアント アプリケーションは、バックエンド コア マイクロサービスとどのように通信しますか? 直接通信を許可しますか? または、柔軟性、制御、およびセキュリティを提供するゲートウェイ ファサードを使用してバックエンド マイクロサービスを抽象化できますか?
バックエンド コア マイクロサービスは、どのように相互に通信しますか? 結合を向上させ、パフォーマンスと機敏性に影響を与える可能性のある直接 HTTP 呼び出しを許可しますか? または、キューやトピックを利用した非同期メッセージングを検討することもありますか。
通信については、 クラウドネイティブの通信パターンの章で説明します 。
回復性
マイクロサービス アーキテクチャは、システムをインプロセスからアウトプロセス ネットワーク通信に移行します。 分散アーキテクチャでは、サービス B がサービス A からのネットワーク呼び出しに応答していない場合はどうなりますか。 または、サービス C が一時的に使用できなくなり、それを呼び出す他のサービスがブロックされた場合はどうなりますか?
回復性については、 クラウドネイティブの回復性に関 する章で説明されています。
分散データ
設計上、各マイクロサービスは独自のデータをカプセル化し、そのパブリック インターフェイスを介して操作を公開します。 その場合、複数のサービス間でデータのクエリを実行したり、トランザクションを実装したりするにはどうすればよいですか?
分散データについては、「 クラウドネイティブ データ パターン」の章で説明します 。
シークレット
マイクロサービスでは、シークレットと機密性の高い構成データを安全に格納して管理する方法を説明します。
シークレットについては、 クラウドネイティブのセキュリティについて詳しく説明します。
Dapr を使用して複雑さを管理する
Dapr は、分散型のオープン ソース アプリケーション ランタイムです。 プラグ可能なコンポーネントのアーキテクチャにより、分散アプリケーションの背後にある 配管が 大幅に簡素化されます。 これは、Dapr ランタイムの事前構築済みのインフラストラクチャ機能とコンポーネントを使用してアプリケーションをバインドする 動的接着 を提供します。 図 1-5 は、20,000 フィートからの Dapr を示しています。
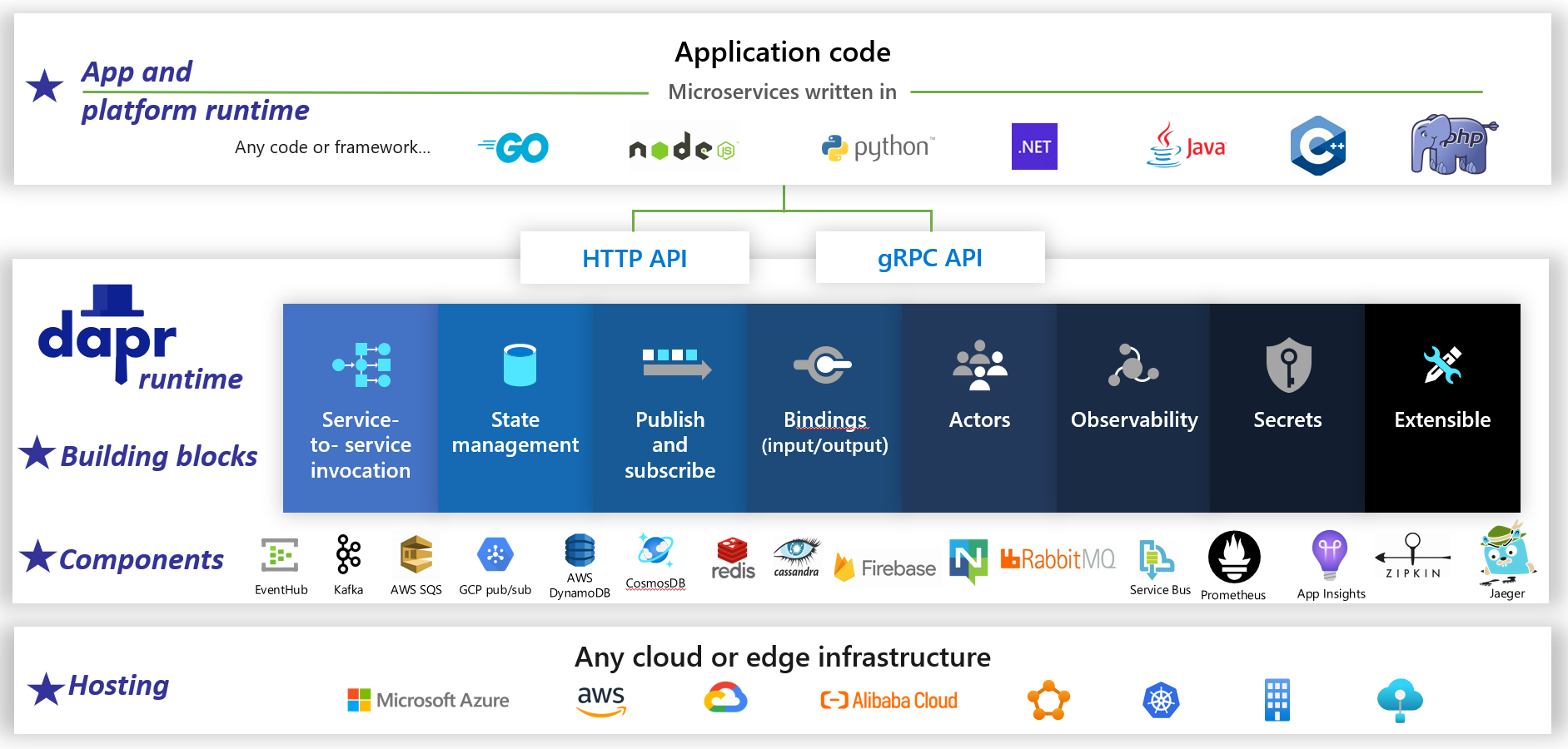 図 1-5。 2 万フィートからの Dapr。
図 1-5。 2 万フィートからの Dapr。
図の一番上の行で、Dapr が一般的な開発プラットフォームに 言語固有の SDK を 提供する方法に注意してください。 Dapr v1 には、.NET、Go、Node.js、Python、PHP、Java、JavaScript のサポートが含まれています。
言語固有の SDK は開発者エクスペリエンスを向上させますが、Dapr はプラットフォームに依存しません。 内部的には、Dapr のプログラミング モデルでは、標準の HTTP/gRPC 通信プロトコルを介して機能が公開されています。 どのプログラミング プラットフォームでも、ネイティブの HTTP API と gRPC API を介して Dapr を呼び出すことができます。
図の中央の青いボックスは、Dapr の構成要素を表しています。 それぞれにより、アプリケーションで使用できる分散アプリケーション機能に事前構築された仕組みコードが公開されます。
コンポーネント行は、アプリケーションで使用できる定義済みのインフラストラクチャ コンポーネントの大規模なセットを表します。 コンポーネントは、記述する必要のないインフラストラクチャ コードと考えてください。
下の行では、Dapr の移植性と、実行できる多様な環境が強調表示されています。
今後、Dapr はクラウドネイティブのアプリケーション開発に大きな影響を与える可能性があります。
Containers
クラウドネイティブな会話でコンテナーという用語を聞くのは自然です。 本の中で、 クラウドネイティブパターン、著者コーネリア・デイビスは、「コンテナーはクラウドネイティブソフトウェアの偉大な実現者です」と観察しています。Cloud Native Computing Foundation は、マイクロサービスコンテナー化を、クラウドネイティブの体験を開始する企業向けの ガイダンスであるCloud-Native Trail Map の最初のステップとして配置します。
{kind=link}
マイクロサービスのコンテナー化は単純で簡単です。 コード、その依存関係、ランタイムは、 コンテナー イメージと呼ばれるバイナリにパッケージ化されます。 イメージは、イメージのリポジトリまたはライブラリとして機能するコンテナー レジストリに格納されます。 レジストリは、開発用コンピューター、データ センター、またはパブリック クラウドに配置できます。 Docker 自体は、 Docker Hub を介してパブリック レジストリを維持します。 Azure クラウドには、コンテナー イメージを実行するクラウド アプリケーションの近くに格納するプライベート コンテナー レジストリ が用意されています。
アプリケーションの起動時またはスケーリング時に、コンテナー イメージを実行中のコンテナー インスタンスに変換します。 インスタンスは、 コンテナー ランタイム エンジンがインストールされている任意のコンピューターで実行されます。 コンテナー化されたサービスのインスタンスは、必要に応じていくつでも作成できます。
図 1-6 は、それぞれ独自のコンテナー内の 3 つの異なるマイクロサービスを示しています。これらはすべて 1 つのホストで実行されています。
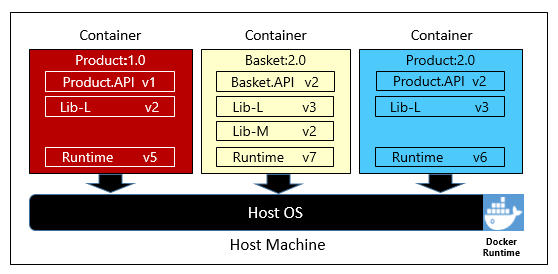
図 1-6 コンテナー ホストで実行されている複数のコンテナー
各コンテナーが依存関係とランタイムの独自のセットを維持する方法に注意してください。これは互いに異なる場合があります。 ここでは、同じホストで実行されている製品マイクロサービスのさまざまなバージョンが表示されます。 各コンテナーは、基になるホスト オペレーティング システム、メモリ、プロセッサのスライスを共有しますが、互いに分離されます。
コンテナー モデルが、Twelve-Factor アプリケーションからの依存関係の原則をどの程度採用しているかに注意してください。
Factor #2 では、"各マイクロサービスは独自の依存関係を分離してパッケージ化し、システム全体に影響を与えずに変更を受け入れる" ことを指定します。
コンテナーでは、Linux ワークロードと Windows ワークロードの両方がサポートされます。 Azure クラウドでは、両方をオープンに受け入れます。 興味深いことに、Azure でより一般的なオペレーティング システムとなっているのは、Windows Server ではなく Linux です。
複数のコンテナー ベンダーが存在する一方で、 Docker は市場のライオンのシェアを獲得しています。 同社は、ソフトウェアコンテナーの動きを推進してきました。 これは、クラウドネイティブ アプリケーションのパッケージ化、デプロイ、実行の事実上の標準となっています。
コンテナーの理由
コンテナーは移植性を提供し、環境間の一貫性を保証します。 すべてを 1 つのパッケージにカプセル化することで、マイクロサービスとその依存関係を基になるインフラストラクチャから 分離 します。
コンテナーは、Docker ランタイム エンジンをホストする任意の環境にデプロイできます。 コンテナー化されたワークロードでは、フレームワーク、ソフトウェア ライブラリ、ランタイム エンジンを使用して各環境を事前に構成するコストも削減されます。
基になるオペレーティング システムとホスト リソースを共有することで、コンテナーのフットプリントは完全な仮想マシンよりもはるかに小さくなります。 サイズが小さいと、特定のホストが一度に実行できる 密度 (マイクロサービスの数) が増加します。
コンテナーのオーケストレーション
Docker などのツールはイメージを作成してコンテナーを実行しますが、それらを管理するためのツールも必要です。 コンテナー管理は、 コンテナー オーケストレーターと呼ばれる特別なソフトウェア プログラムで行われます。 多数の独立した実行中のコンテナーで大規模に動作する場合は、オーケストレーションが不可欠です。
図 1-7 は、コンテナー オーケストレーターが自動化する管理タスクを示しています。
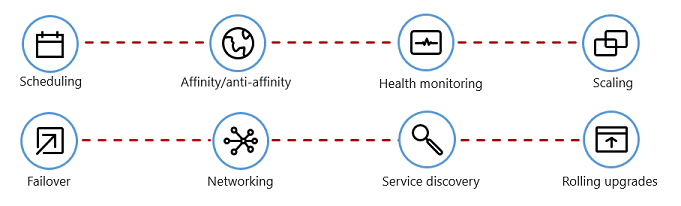
図 1-7 コンテナー オーケストレーターの機能
次の表では、一般的なオーケストレーション タスクについて説明します。
| タスク | 説明 |
|---|---|
| スケジューリング | コンテナー インスタンスを自動的にプロビジョニングします。 |
| 親和性/反親和性 | コンテナーを互いに近くまたは遠く離れた場所にプロビジョニングし、可用性とパフォーマンスを向上させます。 |
| 健康状態の監視 | エラーを自動的に検出して修正します。 |
| フェールオーバー | 失敗したインスタンスを正常なマシンに自動的に再プロビジョニングします。 |
| Scaling | 需要に合わせてコンテナー インスタンスを自動的に追加または削除します。 |
| ネットワーク | コンテナー通信用のネットワーク オーバーレイを管理します。 |
| サービスの検出 | コンテナーが互いを見つけ合えるようにします。 |
| ローリング アップグレード | ダウンタイムなしのデプロイで増分アップグレードを調整します。 問題のある変更を自動的にロールバックします。 |
コンテナー オーケストレーターが、Twelve-Factor アプリケーションからの破棄可能性とコンカレンシーの原則を採用する方法に注意してください。
Factor #9 では、"サービス インスタンスは破棄可能にする必要があり、高速なスタートアップを優先してスケーラビリティの機会を増やし、システムを正しい状態にしておくグレースフル シャットダウン " を指定します。Docker コンテナーとオーケストレーターは、本質的にこの要件を満たしている」
Factor #8 では、"サービスは、使用可能な最も強力なマシン上の単一の大規模なインスタンスをスケールアップするのではなく、多数の小さな同一プロセス (コピー) にわたってスケールアウトする" ことを指定します。
複数のコンテナー オーケストレーターが存在する一方で、 Kubernetes はクラウドネイティブの世界の事実上の標準となっています。 これは、コンテナー化されたワークロードを管理するための移植可能で拡張可能なオープン ソース プラットフォームです。
Kubernetes の独自のインスタンスをホストすることもできますが、そのリソースのプロビジョニングと管理は、複雑になる可能性があります。 Azure クラウドでは、Kubernetes がマネージド サービスとして機能します。 Azure Kubernetes Service (AKS) と Azure Red Hat OpenShift (ARO) の両方を使用すると、Kubernetes の機能と機能をマネージド サービスとして完全に活用できます。インストールして保守する必要はありません。
コンテナー オーケストレーションの詳細については、「 Cloud-Native アプリケーションのスケーリング」を参照してください。
バックエンド サービス
クラウドネイティブ システムは、データ ストア、メッセージ ブローカー、監視、ID サービスなど、さまざまな補助リソースに依存します。 これらのサービスは 、バッキング サービスと呼ばれます。
図 1-8 は、クラウド ネイティブ システムで使用される多くの一般的なバッキング サービスを示しています。
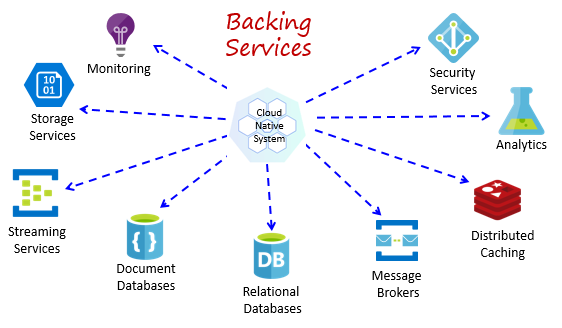
図 1-8 一般的な支援サービス
独自のバッキング サービスをホストすることもできますが、その後、それらのリソースのライセンス、プロビジョニング、管理を行う必要があります。
クラウド プロバイダーは、 豊富なマネージド バッキング サービス を提供します。サービスを所有する代わりに、サービスを使用するだけです。 クラウド プロバイダーは、リソースを大規模に運用し、パフォーマンス、セキュリティ、およびメンテナンスに責任を負います。 監視、冗長性、および可用性は、サービスに組み込まれています。 プロバイダーはサービス レベルのパフォーマンスを保証し、マネージド サービスを完全にサポートします。チケットを開いて問題を解決します。
クラウドネイティブ システムは、クラウド ベンダーからのマネージド バッキング サービスを優先します。 時間と労力の節約は大きな可能性があります。 自分でホストし、問題が発生する運用上のリスクは、コストが高くなる可能性があります。
ベスト プラクティスは、バッキング サービスを アタッチされたリソースとして扱い、外部構成に格納された構成情報 (URL と資格情報) を使用してマイクロサービスに動的にバインドすることです。 このガイダンスは、前の章で説明した Twelve-Factor アプリケーションで説明されています。
要素 4 は、バッキング サービスが"アドレス指定可能な URL を介して公開される必要がある" ことを指定します。 これにより、リソースがアプリケーションから切り離され、交換可能になります。
要素 3 では、"構成情報はマイクロサービスから移動され、コードの外部にある構成管理ツールを使用して外部化される" ことを指定します。
このパターンでは、コードを変更せずにバッキング サービスをアタッチおよびデタッチできます。 QA からステージング環境にマイクロサービスを昇格させる場合があります。 ステージングのバッキング サービスを指すようにマイクロサービス構成を更新し、環境変数を使用して設定をコンテナーに挿入します。
クラウド ベンダーは、独自のバッキング サービスと通信するための API を提供します。 これらのライブラリは、独自の配管と複雑さをカプセル化します。 ただし、これらの API と直接通信すると、その特定のバッキング サービスにコードが密に結合されます。 ベンダー API の実装の詳細を絶縁することは、広く受け入れられたプラクティスです。 仲介層 (中間 API) を導入し、サービス コードに汎用操作を公開し、その中にベンダー コードをラップします。 この疎結合により、メインライン サービス コードを変更することなく、あるバッキング サービスを別のバッキング サービスにスワップアウトしたり、コードを別のクラウド環境に移動したりできます。 前に説明した Dapr は、 事前構築済みの構成要素のセットでこのモデルに従います。
最後に、バッキング サービスは、前の章で説明した Twelve-Factor アプリケーションからのステートレスの原則も促進します。
Factor #6 では、"各マイクロサービスは、他の実行中のサービスから分離された独自のプロセスで実行する必要があります。 必要な状態を分散キャッシュやデータ ストアなどのバッキング サービスに外部化します。
バッキング サービスについては、 クラウドネイティブのデータ パターン と クラウドネイティブの通信パターンで説明します。
Automation
ご覧のように、クラウドネイティブ システムでは、マイクロサービス、コンテナー、最新のシステム設計を採用して、速度と機敏性を実現しています。 しかし、これはストーリーの一部にすぎません。 これらのシステムを実行するクラウド環境をどのようにプロビジョニングしますか? アプリの機能と更新プログラムを迅速にデプロイする方法 全体像を完成させる方法
コードとしてのインフラストラクチャ (IaC) の広く受け入れわれているプラクティスを入力します。
IaC を使用すると、プラットフォームのプロビジョニングとアプリケーションのデプロイを自動化できます。 基本的に、テストやバージョン管理などのソフトウェア エンジニアリング プラクティスを DevOps プラクティスに適用します。 インフラストラクチャとデプロイは自動化され、一貫性があり、反復可能です。
インフラストラクチャの自動化
Azure Resource Manager、Azure Bicep、HashiCorp の Terraform、Azure CLI などのツールを使用すると、必要なクラウド インフラストラクチャを宣言によってスクリプト化できます。 リソース名、場所、容量、シークレットはパラメーター化され、動的です。 スクリプトはバージョン管理され、プロジェクトの成果物としてソース管理にチェックインされます。 このスクリプトを呼び出して、QA、ステージング、運用などのシステム環境間で一貫性のある反復可能なインフラストラクチャをプロビジョニングします。
内部では IaC はべき等です。つまり、同じスクリプトを何度も実行しても副作用がありません。 チームが変更を加える必要がある場合は、スクリプトを編集して再実行します。 更新されたリソースのみが影響を受けます。
記事「 コードとしてのインフラストラクチャとは」の著者 Sam Guckenheimer は、「IaC を実装する Teams は、安定した環境を迅速かつ大規模に提供する方法について説明しています。 環境の手動構成を回避し、コードを使用して環境の望ましい状態を表すことで一貫性を強制します。 IaC を使用したインフラストラクチャのデプロイは繰り返し可能であり、構成の誤差や依存関係の不足によって発生するランタイムの問題を防ぎます。 DevOps チームは、統合された一連のプラクティスとツールと連携して、アプリケーションとそのサポート インフラストラクチャを迅速かつ確実に大規模に提供できます。
デプロイの自動化
既に説明した Twelve-Factor アプリケーションでは、完了したコードを実行中のアプリケーションに変換するときに、個別の手順を呼び出します。
Factor #5 では、"各リリースでは、ビルド、リリース、および実行の各ステージで厳密な分離を適用する必要があります。 それぞれに一意の ID でタグを付け、ロールバックする機能をサポートする必要があります。
最新の CI/CD システムは、この原則を満たすのに役立ちます。 これらは、ユーザーがすぐに使用できる一貫性のある品質のコードを確保するのに役立つ個別のビルドと配信の手順を提供します。
図 1-9 は、デプロイ プロセス間の分離を示しています。
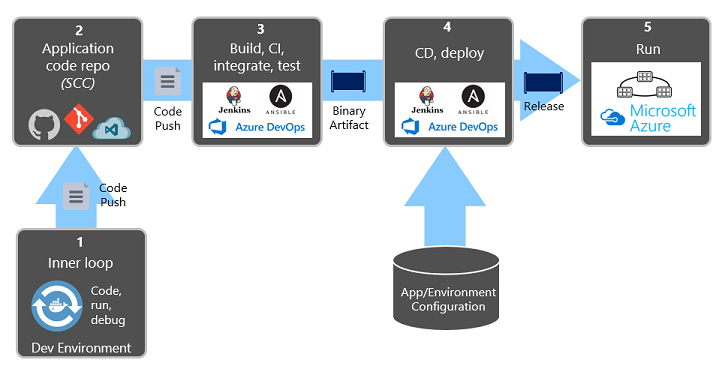
図 1-9 CI/CD パイプラインでのデプロイ手順
前の図では、タスクの分離に特に注意してください。
- 開発者は開発環境で機能を構築し、コード、実行、デバッグの "内部ループ" と呼ばれるものを反復処理します。
- 完了すると、そのコードは GitHub、Azure DevOps、BitBucket などのコード リポジトリに プッシュされます 。
- プッシュによって、コードをバイナリ成果物に変換するビルド ステージがトリガーされます。 この作業は、 継続的インテグレーション (CI) パイプラインを使用して実装されます。 アプリケーションを自動的にビルド、テスト、パッケージします。
- リリース ステージでは、バイナリ成果物を選択し、外部アプリケーションと環境の構成情報を適用して、変更できないリリースを生成します。 リリースは、指定された環境にデプロイされます。 この作業は、 継続的デリバリー (CD) パイプラインを使用して実装されます。 各リリースは識別可能である必要があります。 "このデプロイでは、アプリケーションのリリース 2.1.1 が実行されています" と言うことができます。
- 最後に、リリースされた機能はターゲット実行環境で実行されます。 リリースは不変です。つまり、変更によって新しいリリースを作成する必要があります。
これらのプラクティスを適用することで、組織はソフトウェアの出荷方法を根本的に進化してきました。 多くは、四半期ごとのリリースからオンデマンド更新プログラムに移行しました。 目標は、修正コストが低い開発サイクルの早い段階で問題をキャッチすることです。 統合の間の期間が長いほど、よりコストの高い問題が解決されます。 統合プロセスの一貫性により、チームはコードの変更をより頻繁にコミットでき、コラボレーションとソフトウェアの品質が向上します。
コードとしてのインフラストラクチャとデプロイの自動化、および GitHub および Azure DevOps については、 DevOps で詳しく説明します。
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET